
Mit diesem Weblog möchte ich zu Forschungszwecken einen kleinen, mit „LangGraph“ und Google Gemini integrierten Agenten zeigen. Ziel ist es, einen Forschungsagenten (Paper-to-Voice-Assistent) zu demonstrieren, der die Forschungsarbeit zusammenfassen möchte. Dieses Instrument verwendet ein Visionsmodell, um die Informationen abzuleiten. Diese Methode identifiziert nur den Schritt und seine Unterschritte und versucht, die Antwort für diese Aktionselemente zu erhalten. Abschließend werden alle Antworten in Gespräche umgewandelt, in denen zwei Personen über den Beitrag diskutieren. Sie können dies als Mini betrachten NotebookLM von Google.
Um dies näher zu erläutern, verwende ich einen einzelnen unidirektionalen Graphen, in dem die Kommunikation zwischen den Schritten von oben nach unten erfolgt. Ich habe auch bedingte Knotenverbindungen verwendet, um wiederholte Jobs zu verarbeiten.
- Ein Prozess zum Erstellen einfacher Agenten mithilfe von Langgraph
- Multimodale Konversation mit Google Gemini llm

Paper-to-Voice-Assistent: Kartenreduzierung in Agentic AI
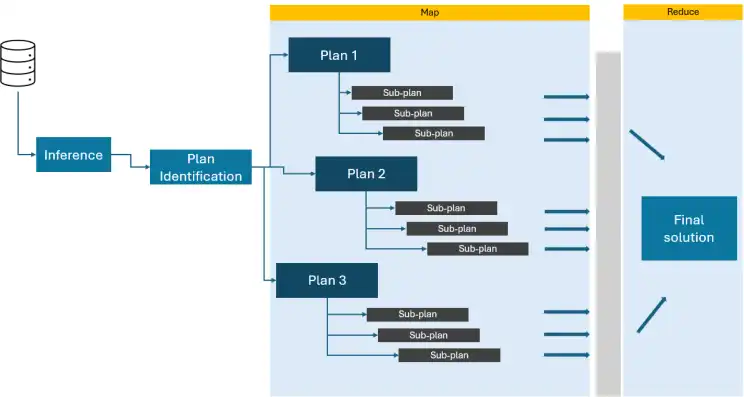
Stellen Sie sich ein riesiges Downside vor, das so groß ist, dass eine einzelne Particular person mehrere Tage/Monate brauchen würde, um es zu lösen. Stellen Sie sich nun ein Crew qualifizierter Mitarbeiter vor, denen jeweils ein bestimmter Aufgabenbereich zugewiesen wird. Sie könnten damit beginnen, die Pläne nach Ziel oder Komplexität zu sortieren und dann nach und nach kleinere Abschnitte zusammenzusetzen. Sobald jeder Löser seinen Abschnitt abgeschlossen hat, kombinieren sie ihre Lösungen zum endgültigen.
Dies ist im Wesentlichen die Funktionsweise der Kartenreduzierung in Agentic AI. Das Hauptproblem wird in Teilproblemaussagen unterteilt. Der „Löser„sind einzelne LLMs, die jeden Teilplan mit unterschiedlichen Solvern abbilden. Jeder Löser arbeitet an seinem zugewiesenen Teilproblem und führt bei Bedarf Berechnungen durch oder leitet Informationen ab. Abschließend werden die Ergebnisse aller „Löser“ zusammengefasst (reduziert).), um die endgültige Ausgabe zu erzeugen.
Von der Automatisierung zur Unterstützung: Die sich entwickelnde Rolle von KI-Agenten
Nach Fortschritten in generative KI, LLM-Agenten sind sehr beliebt und die Leute machen sich ihre Fähigkeiten zunutze. Einige argumentieren, dass Agenten den Prozess durchgängig automatisieren können. Ich betrachte sie jedoch als Produktivitätsförderer. Sie können bei der Problemlösung und der Gestaltung von Arbeitsabläufen helfen und es Menschen ermöglichen, sich auf kritische Teile zu konzentrieren. Beispielsweise können Agenten als automatisierte Beweiser fungieren, die den Raum mathematischer Beweise erkunden. Sie können neue Perspektiven und Denkweisen bieten, die über „von Menschen erstellte“ Beweise hinausgehen.
Ein weiteres aktuelles Beispiel ist das KI-gestütztes Cursor Studio. Der Cursor ist eine kontrollierte Umgebung ähnlich dem VS-Code, die Programmierunterstützung unterstützt.
Agenten werden auch besser in der Lage, zu planen und Maßnahmen zu ergreifen, ähnlich wie Menschen, und – was am wichtigsten ist – sie können ihre Strategien anpassen. Sie verbessern schnell ihre Fähigkeit, Aufgaben zu analysieren, Pläne für deren Erledigung zu entwickeln und ihre Herangehensweise durch wiederholte Selbstkritik zu verfeinern. Bei einigen Techniken geht es darum, Menschen auf dem Laufenden zu halten, wobei Agenten in regelmäßigen Abständen die Führung von Menschen einholen und dann auf der Grundlage dieser Anweisungen fortfahren.

Was ist nicht enthalten?
- Ich habe keine Instruments wie die Suche oder benutzerdefinierte Funktionen integriert, um es komplexer zu machen.
- Es wird kein Routing-Ansatz oder keine umgekehrte Verbindung entwickelt.
- Für die Parallelverarbeitung oder bedingte Jobs werden keine Verzweigungstechniken verwendet
- Ähnliche Dinge können durch das Laden von PDFs und das Parsen von Bildern und Grafiken implementiert werden.
- Spielen mit nur 3 Bildern in einer Eingabeaufforderung.
Verwendete Python-Bibliotheken
- langchain-google-genai : Um Langchain mit generativen KI-Modellen von Google zu verbinden
- python-dotenv: Zum Laden geheimer Schlüssel oder Umgebungsvariablen
- Langgraph: Um die Agenten zu konstruieren
- pypdfium2 & Kissen: Um PDF in Bilder umzuwandeln
- pydub : um den Ton zu segmentieren
- gradio_client : HF 🤗 Modell nennen
Paper-to-Voice-Assistent: Praktische Umsetzung
Hier ist die Implementierung:
Laden Sie die unterstützenden Bibliotheken
from dotenv import dotenv_values
from langchain_core.messages import HumanMessage
import os
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.graph import StateGraph, START, END,MessagesState
from langgraph.graph.message import add_messages
from langgraph.constants import Ship
import pypdfium2 as pdfium
import json
from PIL import Picture
import operator
from typing import Annotated, TypedDict # ,Elective, Record
from langchain_core.pydantic_v1 import BaseModel # ,SubjectUmgebungsvariablen laden
config = dotenv_values("../.env")
os.environ("GOOGLE_API_KEY") = config('GEMINI_API')Derzeit verwende ich in diesem Projekt einen multimodalen Ansatz. Um dies zu erreichen, lade ich eine PDF-Datei und konvertiere jede Seite in ein Bild. Diese Bilder werden dann zu Gesprächszwecken in das Gemini-Visionsmodell eingespeist.
Der folgende Code zeigt, wie Sie eine PDF-Datei laden, jede Seite in ein Bild konvertieren und diese Bilder in einem Verzeichnis speichern.
pdf = pdfium.PdfDocument("./pdf_image/imaginative and prescient.pdf")
for i in vary(len(pdf)):
web page = pdf(i)
picture = web page.render(scale=4).to_pil()
picture.save(f"./pdf_image/vision_P{i:03d}.jpg")Lassen Sie uns die eine Seite als Referenz anzeigen.
image_path = "./pdf_image/vision_P000.jpg"
img = Picture.open(image_path)
imgAusgabe:

Google Imaginative and prescient-Modell
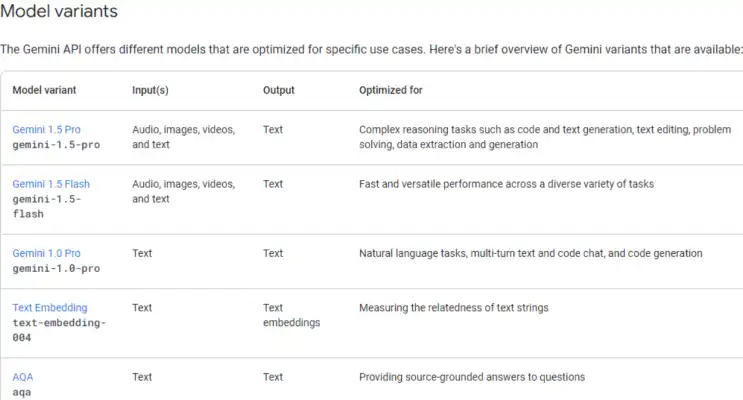
Verbindung des Gemini-Modells über einen API-Schlüssel. Im Folgenden sind die verschiedenen verfügbaren Varianten aufgeführt. Es ist wichtig zu beachten, dass wir das Modell auswählen sollten, das den Datentyp unterstützt. Da ich im Gespräch mit Bildern arbeite, musste ich mich für eines der beiden entscheiden Gemini 1.5 Professional oder Flash-Modelle, da diese Varianten Bilddaten unterstützen.
llm = ChatGoogleGenerativeAI(
mannequin="gemini-1.5-flash-001", # "gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
Fahren wir mit der Erstellung des Schemas fort, um die Ausgabe zu verwalten und Informationen zwischen Knoten zu übertragen. Verwenden Sie den Add-Operator, um alle Schritte und Unterschritte zusammenzuführen, die der Agent erstellt.
class State(TypedDict):
image_path: str # To retailer reference of all of the pages
steps: Annotated(checklist, operator.add) # Retailer all of the steps generated by the agent
substeps: Annotated(checklist, operator.add) # Retailer all of the sub steps generated by the agent for each step
options: Annotated(checklist, operator.add) # Retailer all of the options generated by the agent for every step
content material:str # retailer the content material of the paper
plan:str # retailer the processed plan
Dialog: Annotated(checklist, operator.add)Das Schema zur Steuerung der Ausgabe des ersten Schritts.
class Activity(BaseModel):
process: strSchema speichert die Ausgabe jedes Unterschritts basierend auf den im vorherigen Schritt identifizierten Aufgaben.
class SubStep(BaseModel):
substep: strSchema zur Steuerung der Ausgabe während der Bedingungsschleife.
class StepState(TypedDict):
step: str
image_path: str
options: str
Dialog: strSchritt 1: Aufgaben generieren
In unserem ersten Schritt übergeben wir die Bilder an das LLM und weisen es an, alle Pläne zu identifizieren, die es ausführen möchte, um die Forschungsarbeit vollständig zu verstehen. Ich stelle mehrere Seiten gleichzeitig bereit und bitte das Modell, einen kombinierten Plan basierend auf allen Bildern zu erstellen.
def generate_steps(state: State):
immediate="""
Take into account you're a analysis scientist in synthetic intelligence who's professional in understanding analysis papers.
You may be given a analysis paper and it's worthwhile to determine all of the steps a researcher have to carry out.
Establish every steps and their substeps.
"""
message = HumanMessage(content material=({'kind':'textual content','textual content':immediate},
*({"kind":'image_url','image_url':img} for img in state('image_path'))
)
)
response = llm.invoke((message))
return {"content material": (response.content material),"image_path":state('image_path')}Schritt 2: Parsing planen
In diesem Schritt übernehmen wir den im ersten Schritt identifizierten Plan und weisen das Modell an, ihn in ein strukturiertes Format umzuwandeln. Ich habe das Schema definiert und diese Informationen in die Eingabeaufforderung eingefügt. Es ist wichtig zu beachten, dass externe Analysetools verwendet werden können, um den Plan in eine geeignete Datenstruktur umzuwandeln. Um die Robustheit zu erhöhen, können Sie „Instruments“ verwenden, um die Daten zu analysieren oder auch ein strengeres Schema zu erstellen.
def markdown_to_json(state: State):
immediate ="""
You might be given a markdown content material and it's worthwhile to parse this information into json format. Comply with appropriately key and worth
pairs for every bullet level.
Comply with following schema strictly.
schema:
(
{
"step": "description of step 1 ",
"substeps": (
{
"key": "title of sub step 1 of step 1",
"worth": "description of sub step 1 of step 1"
},
{
"key": "title of sub step 2 of step 1",
"worth": "description of sub step 2 of step 1"
})},
{
"step": "description of step 2",
"substeps": (
{
"key": "title of sub step 1 of step 2",
"worth": "description of sub step 1 of step 2"
},
{
"key": "title of sub step 2 of step 2",
"worth": "description of sub step 2 of step 2"
})})'
Content material:
%s
"""% state('content material')
str_response = llm.invoke((immediate))
return({'content material':str_response.content material,"image_path":state('image_path')})Schritt 3 Textual content an Json
Im 3. Schritt nehmen wir den im 2. Schritt identifizierten Plan und konvertieren ihn in das JSON-Format. Bitte beachten Sie, dass diese Methode möglicherweise nicht immer funktioniert, wenn LLM die Schemastruktur verletzt.
def parse_json(state: State):
str_response_json = json.hundreds(state('content material')(7:-3).strip())
output = ()
for step in str_response_json:
substeps = ()
for merchandise in step('substeps'):
for okay,v in merchandise.objects():
if okay=='worth':
substeps.append(v)
output.append({'step':step('step'),'substeps':substeps})
return({"plan":output})Schritt 4: Lösung für jeden Schritt
Die Lösungsergebnisse jedes Schritts werden in diesem Schritt berücksichtigt. Es wird ein Plan benötigt und alle Unterpläne in einem Paar Fragen und Antworten in einer einzigen Eingabeaufforderung zusammengefasst. Darüber hinaus ermittelt LLM die Lösung für jeden Teilschritt.
In diesem Schritt werden auch die mehreren Ausgaben mithilfe des Annotators und des „Add“-Operators zu einer einzigen zusammengefasst. Im Second funktioniert dieser Schritt mit einigermaßen guter Qualität. Es kann jedoch verbessert werden, indem man Verzweigungen verwendet und jeden Unterschritt in eine richtige Argumentationsaufforderung übersetzt.
Grundsätzlich sollte jeder Teilschritt in eine Gedankenkette übersetzt werden, damit LLM eine Lösung vorbereiten kann. Man kann auch React verwenden.
def sovle_substeps(state: StepState):
print(state)
inp = state('step')
print('fixing sub steps')
qanda=" ".be part of((f'n Query: {substep} n Reply:' for substep in inp('substeps')))
immediate=f""" You may be given instruction to investigate analysis papers. It's essential to perceive the
instruction and resolve all of the questions talked about within the checklist.
Hold the pair of Query and its reply in your response. Your response needs to be subsequent to the key phrase "Reply"
Instruction:
{inp('step')}
Questions:
{qanda}
"""
message = HumanMessage(content material=({'kind':'textual content','textual content':immediate},
*({"kind":'image_url','image_url':img} for img in state('image_path'))
)
)
response = llm.invoke((message))
return {"steps":(inp('step')), 'options':(response.content material)}Schritt 5: Bedingte Schleife
Dieser Schritt ist entscheidend für die Steuerung des Gesprächsflusses. Dabei handelt es sich um einen iterativen Prozess, der die generierten Pläne (Schritte) abbildet und in einer Schleife kontinuierlich Informationen von einem Knoten zum anderen weiterleitet. Die Schleife endet, sobald alle Pläne ausgeführt wurden. Derzeit kümmert sich dieser Schritt um die unidirektionale Kommunikation zwischen Knoten. Wenn jedoch eine bidirektionale Kommunikation erforderlich ist, müssen wir die Implementierung anderer Verzweigungstechniken in Betracht ziehen.
def continue_to_substeps(state: State):
steps = state('plan')
return (Ship("sovle_substeps", {"step": s,'image_path':state('image_path')}) for s in steps)Schritt 6: Stimme
Nachdem alle Antworten generiert wurden, wandelt der folgende Code sie in einen Dialog um und kombiniert dann alles zu einem Podcast, in dem zwei Personen über den Artikel diskutieren. Die folgende Eingabeaufforderung stammt aus Hier.
SYSTEM_PROMPT = """
You're a world-class podcast producer tasked with reworking the supplied enter textual content into an interesting and informative podcast script. The enter could also be unstructured or messy, sourced from PDFs or internet pages. Your objective is to extract essentially the most attention-grabbing and insightful content material for a compelling podcast dialogue.
# Steps to Comply with:
1. **Analyze the Enter:**
Fastidiously study the textual content, figuring out key subjects, factors, and attention-grabbing details or anecdotes that
may drive an interesting podcast dialog. Disregard irrelevant data or formatting points.
2. **Brainstorm Concepts:**
Within the `<scratchpad>`, creatively brainstorm methods to current the important thing factors engagingly. Take into account:
- Analogies, storytelling strategies, or hypothetical situations to make content material relatable
- Methods to make advanced subjects accessible to a normal viewers
- Thought-provoking inquiries to discover in the course of the podcast
- Inventive approaches to fill any gaps within the data
3. **Craft the Dialogue:**
Develop a pure, conversational move between the host (Jane) and the visitor speaker (the writer or an professional on the subject). Incorporate:
- The most effective concepts out of your brainstorming session
- Clear explanations of advanced subjects
- An interesting and vigorous tone to captivate listeners
- A steadiness of data and leisure
Guidelines for the dialogue:
- The host (Jane) all the time initiates the dialog and interviews the visitor
- Embrace considerate questions from the host to information the dialogue
- Incorporate pure speech patterns, together with occasional verbal fillers (e.g., "um," "properly," "you already know")
- Enable for pure interruptions and back-and-forth between host and visitor
- Make sure the visitor's responses are substantiated by the enter textual content, avoiding unsupported claims
- Keep a PG-rated dialog acceptable for all audiences
- Keep away from any advertising or self-promotional content material from the visitor
- The host concludes the dialog
4. **Summarize Key Insights:**
Naturally weave a abstract of key factors into the closing a part of the dialogue. This could really feel like an off-the-cuff dialog somewhat than a proper recap, reinforcing the primary takeaways earlier than signing off.
5. **Keep Authenticity:**
All through the script, attempt for authenticity within the dialog. Embrace:
- Moments of real curiosity or shock from the host
- Cases the place the visitor would possibly briefly wrestle to articulate a posh thought
- Mild-hearted moments or humor when acceptable
- Temporary private anecdotes or examples that relate to the subject (throughout the bounds of the enter textual content)
6. **Take into account Pacing and Construction:**
Make sure the dialogue has a pure ebb and move:
- Begin with a robust hook to seize the listener's consideration
- Progressively construct complexity because the dialog progresses
- Embrace temporary "breather" moments for listeners to soak up advanced data
- Finish on a excessive observe, maybe with a thought-provoking query or a call-to-action for listeners
"""def generate_dialog(state):
textual content = state('textual content')
tone = state('tone')
size = state('size')
language = state('language')
modified_system_prompt = SYSTEM_PROMPT
modified_system_prompt += f"nPLEASE paraphrase the next TEXT in dialog format."
if tone:
modified_system_prompt += f"nnTONE: The tone of the podcast needs to be {tone}."
if size:
length_instructions = {
"Quick (1-2 min)": "Hold the podcast temporary, round 1-2 minutes lengthy.",
"Medium (3-5 min)": "Intention for a average size, about 3-5 minutes.",
}
modified_system_prompt += f"nnLENGTH: {length_instructions(size)}"
if language:
modified_system_prompt += (
f"nnOUTPUT LANGUAGE <IMPORTANT>: The the podcast needs to be {language}."
)
messages = modified_system_prompt + 'nTEXT: '+ textual content
response = llm.invoke((messages))
return {"Step":(state('step')),"Discovering":(state('textual content')), 'Dialog':(response.content material)}def continue_to_substeps_voice(state: State):
print('voice substeps')
options = state('options')
steps = state('steps')
tone="Formal" # ("Enjoyable", "Formal")
return (Ship("generate_dialog", {"step":st,"textual content": s,'tone':tone,'size':"Quick (1-2 min)",'language':"EN"}) for st,s in zip(steps,options))Schritt 7: Diagrammkonstruktion
Jetzt ist es an der Zeit, alle von uns beschriebenen Schritte zusammenzustellen:
- Initialisieren Sie das Diagramm: Beginnen Sie mit der Initialisierung des Diagramms und der Definition aller erforderlichen Knoten.
- Knoten definieren und verbinden: Verbinden Sie die Knoten mithilfe von Kanten und stellen Sie so den Informationsfluss von einem Knoten zum anderen sicher.
- Führen Sie die Schleife ein: Implementieren Sie die Schleife wie in Schritt 5 beschrieben, um eine iterative Verarbeitung der Pläne zu ermöglichen.
- Beenden Sie den Prozess: Verwenden Sie abschließend die END-Methode von LangGraph um den Vorgang ordnungsgemäß abzuschließen und zu beenden.
Es ist Zeit, das Netzwerk zum besseren Verständnis anzuzeigen.
graph = StateGraph(State)
graph.add_node("generate_steps", generate_steps)
graph.add_node("markdown_to_json", markdown_to_json)
graph.add_node("parse_json", parse_json)
graph.add_node("sovle_substeps", sovle_substeps)
graph.add_node("generate_dialog", generate_dialog)
graph.add_edge(START, "generate_steps")
graph.add_edge("generate_steps", "markdown_to_json")
graph.add_edge("markdown_to_json", "parse_json")
graph.add_conditional_edges("parse_json", continue_to_substeps, ("sovle_substeps"))
graph.add_conditional_edges("sovle_substeps", continue_to_substeps_voice, ("generate_dialog"))
graph.add_edge("generate_dialog", END)
app = graph.compile()
Es ist Zeit, das Netzwerk zum besseren Verständnis anzuzeigen.
from IPython.show import Picture, show
strive:
show(Picture(app.get_graph().draw_mermaid_png()))
besides Exception:
print('There appears error')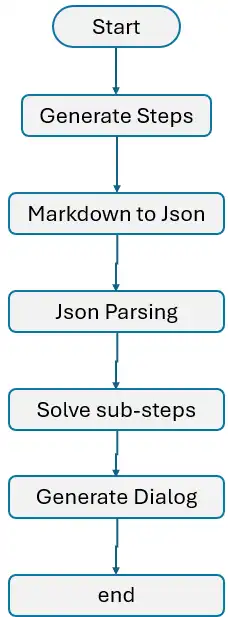
Beginnen wir mit dem Prozess und bewerten wir, wie das aktuelle Framework funktioniert. Im Second teste ich nur mit drei Bildern, obwohl dies auf mehrere Bilder erweitert werden kann. Der Code nimmt Bilder als Eingabe und übergibt diese Daten an den Einstiegspunkt des Diagramms. Anschließend übernimmt jeder Schritt die Eingabe aus dem vorherigen Schritt und gibt die Ausgabe an den nächsten Schritt weiter, bis der Prozess abgeschlossen ist.
output = ()
for s in app.stream({"image_path": (f"./pdf_image/vision_P{i:03d}.jpg" for i in vary(6))}):
output.append(s)
with open('./information/output.json','w') as f:
json.dump(output,f)Ausgabe:
with open('./information/output.json','r') as f:
output1 = json.load(f)print(output1(10)('generate_dialog')('Dialog')(0))Ausgabe:
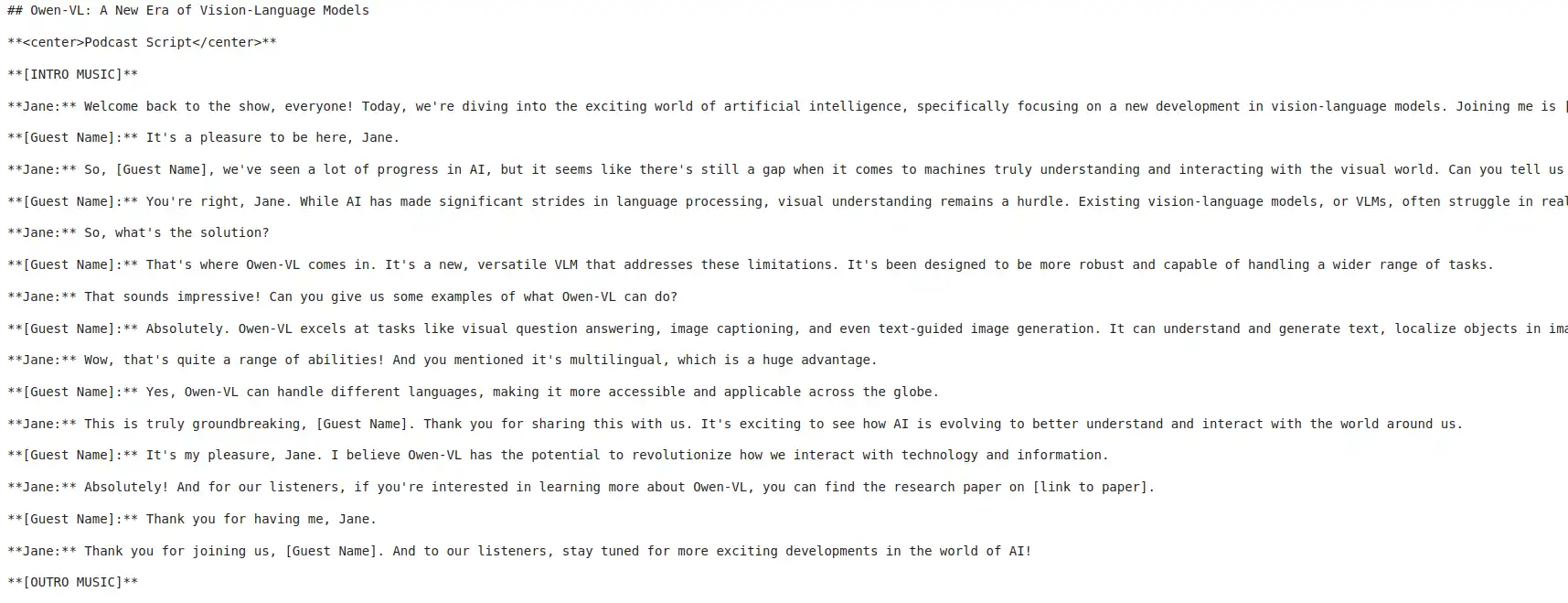
Ich verwende den folgenden Code, um die Ergebnisse nacheinander zu streamen, wobei jeder Plan und Unterplan einer entsprechenden Antwort zugeordnet wird.
import sys
import time
def printify(tx,stream=False):
if stream:
for char in tx:
sys.stdout.write(char)
sys.stdout.flush()
time.sleep(0.05)
else:
print(tx)subjects =()
substeps=()
for idx, plan in enumerate(output1(2)('parse_json')('plan')):
subjects.append(plan('step'))
substeps.append(plan('substeps'))Lassen Sie uns die Antworten der einzelnen Unterschritte trennen
text_planner = {}
stream = False
for subject,substep,responses in zip(subjects,substeps,output1(3:10)):
response = responses('sovle_substeps')
response_topic = response('steps')
if subject in response_topic:
reply = response('options')(0).strip().break up('Reply:')
reply =(ans.strip() for ans in reply if len(ans.strip())>0)
for q,a in zip(substep,reply):
printify(f'Sub-Step : {q}n',stream=stream)
printify(f'Motion : {a}n',stream=stream)
text_planner(subject)={'reply':checklist(zip(substep,reply))}Die Ausgabe von Unterschritten und deren Aktion

Der letzte Knoten im Diagramm wandelt alle Antworten in einen Dialog um. Speichern wir sie in separaten Variablen, damit wir sie in Sprache umwandeln können.
stream = False
dialog_planner ={}
for subject,responses in zip(subjects,output1(10:17)):
dialog = responses('generate_dialog')('Dialog')(0)
dialog = dialog.strip().break up('## Podcast Script')(-1).strip()
dialog = dialog.substitute('(Visitor Title)','Robin').substitute('**Visitor:**','**Robin:**')
printify(f'Dialog: : {dialog}n',stream=stream)
dialog_planner(subject)=dialogDialogausgabe
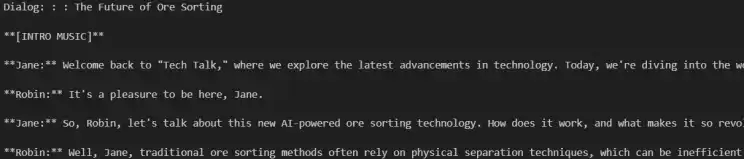
Dialog zur Stimme
from pydantic import BaseModel, Subject
from typing import Record, Literal, Tuple, Elective
import glob
import os
import time
from pathlib import Path
from tempfile import NamedTemporaryFile
from scipy.io.wavfile import write as write_wav
import requests
from pydub import AudioSegment
from gradio_client import Consumer
import json
from tqdm.pocket book import tqdm
import sys
from time import sleepwith open('./information/dialog_planner.json','r') as f:
dialog_planner1 = json.load(f)Lassen Sie uns nun diese Textdialoge in Sprache umwandeln
1. Textual content-to-Speech
Im Second greife ich vom HF-Endpunkt auf das TTS-Modell zu und muss dafür die URL und den API-Schlüssel festlegen.
HF_API_URL = config('HF_API_URL')
HF_API_KEY = config('HF_API_KEY')
headers = {"Authorization": HF_API_KEY}2. Gradio-Consumer
Ich verwende den Gradio-Consumer, um das Modell aufzurufen und den folgenden Pfad festzulegen Gradio-Kunde kann die Audiodaten im angegebenen Verzeichnis speichern. Wenn kein Pfad definiert ist, speichert der Consumer das Audio in einem temporären Verzeichnis.
os.environ('GRADIO_TEMP_DIR') = "path_to_data_dir"
hf_client = Consumer("mrfakename/MeloTTS")
hf_client.output_dir= "path_to_data_dir"
def get_text_to_voice(textual content,pace,accent,language):
file_path = hf_client.predict(
textual content=textual content,
language=language,
speaker=accent,
pace=pace,
api_name="/synthesize",
)
return(file_path)3. Stimmakzent
Um die Konversation für den Podcast zu generieren, weise ich zwei verschiedene Akzente zu: einen für den Moderator und einen anderen für den Gast.
def generate_podcast_audio(textual content: str, language: str) -> str:
if "**Jane:**" in textual content:
textual content = textual content.substitute("**Jane:**",'').strip()
accent = "EN-US"
pace = 0.9
elif "**Robin:**" in textual content: # host
textual content = textual content.substitute("**Robin:**",'').strip()
accent = "EN_INDIA"
pace = 1
else:
return 'Empty Textual content'
for try in vary(3):
strive:
file_path = get_text_to_voice(textual content,pace,accent,language)
return file_path
besides Exception as e:
if try == 2: # Final try
increase # Re-raise the final exception if all makes an attempt fail
time.sleep(1) # Look forward to 1 second earlier than retrying4. Speichern Sie die Stimme in einer MP3-Datei
Jeder Audioclip wird weniger als 2 Minuten lang sein. In diesem Abschnitt wird Audio für jedes kurze Gespräch generiert und die Dateien werden im angegebenen Verzeichnis gespeichert.
def store_voice(topic_dialog):
audio_path = ()
merchandise =0
for subject,dialog in tqdm(topic_dialog.objects()):
dialog_speaker = dialog.break up("n")
for speaker in tqdm(dialog_speaker):
one_dialog = speaker.strip()
language_for_tts = "EN"
if len(one_dialog)>0:
audio_file_path = generate_podcast_audio(
one_dialog, language_for_tts
)
audio_path.append(audio_file_path)
# proceed
sleep(5)
break
return(audio_path)audio_paths = store_voice(topic_dialog=dialog_planner1)5. Kombiniertes Audio
Zum Schluss kombinieren wir alle kurzen Audioclips zu einem längeren Gespräch.
def consolidate_voice(audio_paths,voice_dir):
audio_segments =()
voice_path = (paths for paths in audio_paths if paths!='Empty Textual content')
audio_segment = AudioSegment.from_file(voice_dir+"/light-guitar.wav")
audio_segments.append(audio_segment)
for audio_file_path in tqdm(voice_path):
audio_segment = AudioSegment.from_file(audio_file_path)
audio_segments.append(audio_segment)
audio_segment = AudioSegment.from_file(voice_dir+"/ambient-guitar.wav")
audio_segments.append(audio_segment)
combined_audio = sum(audio_segments)
temporary_directory = voice_dir+"/tmp/"
os.makedirs(temporary_directory, exist_ok=True)
temporary_file = NamedTemporaryFile(
dir=temporary_directory,
delete=False,
suffix=".mp3",
)
combined_audio.export(temporary_file.identify, format="mp3")consolidate_voice(audio_paths=audio_paths,voice_dir="./information")Um die Agent-KI besser zu verstehen, erkunden Sie außerdem Folgendes: Das Agentic AI Pioneer-Programm.
Abschluss
Insgesamt ist dieses Projekt ausschließlich zu Demonstrationszwecken gedacht und erfordert erhebliche Anstrengungen und Prozessänderungen, um einen produktionsbereiten Agenten zu erstellen. Es kann mit minimalem Aufwand als Proof of Idea (POC) dienen. In dieser Demonstration habe ich Faktoren wie Zeitaufwand, Kosten und Genauigkeit nicht berücksichtigt, die in einer Produktionsumgebung entscheidende Faktoren sind. Nachdem dies gesagt ist, komme ich hier zum Schluss. Vielen Dank fürs Lesen. Weitere technische Particulars finden Sie unter GitHub.
Häufig gestellte Fragen
Antwort. Der Paper-to-Voice-Assistent soll den Prozess der Zusammenfassung von Forschungsarbeiten vereinfachen, indem er die extrahierten Informationen in ein Konversationsformat umwandelt und so ein einfaches Verständnis und Zugänglichkeit ermöglicht.
Antwort. Der Assistent verwendet einen Map-Cut back-Ansatz, bei dem er die Forschungsarbeit in Schritte und Unterschritte unterteilt, die Informationen mithilfe von LangGraph und Google Gemini LLMs verarbeitet und die Ergebnisse dann zu einem zusammenhängenden Dialog zusammenfügt.
Antwort. Das Projekt nutzt LangGraph, generative KI-Modelle von Google Gemini, multimodale Verarbeitung (Imaginative and prescient und Textual content) und Textual content-in-Sprache-Konvertierung mit Hilfe von Python-Bibliotheken wie pypdfium2, Pillow, pydub und gradio_client.
Antwort. Ja, der Agent kann PDFs mit Bildern analysieren, indem er jede Seite in Bilder umwandelt und diese in das Imaginative and prescient-Modell einspeist, wodurch visuelle und textliche Informationen extrahiert werden können.
Antwort. Nein, bei diesem Projekt handelt es sich um einen Proof of Idea (POC), der den Arbeitsablauf demonstriert. Um es produktionsreif zu machen, sind weitere Optimierungen, der Umgang mit Zeitkomplexität, Kosten und Genauigkeitsanpassungen erforderlich.