

Bild vom Autor
LSTMs wurden ursprünglich in den frühen 1990er Jahren von Autoren eingeführt Sepp Hochreiter Und Jürgen Schmidhuber. Das ursprüngliche Modell struggle extrem rechenintensiv und erst Mitte der 2010er Jahre erlangten RNNs und LSTMs Aufmerksamkeit. Da mehr Daten und bessere GPUs verfügbar waren, wurden LSTM-Netzwerke zur Standardmethode für die Sprachmodellierung und zum Rückgrat für das erste große Sprachmodell. Das struggle bis zur Veröffentlichung von so Aufmerksamkeitsbasierte Transformatorarchitektur im Jahr 2017. LSTMs wurden nach und nach von der Transformer-Architektur übertroffen, die heute der Normal für alle neueren großen Sprachmodelle, einschließlich ChatGPT, Mistral und Llama, ist.
Die jüngste Veröffentlichung des xLSTM-Papier vom ursprünglichen LSTM-Autor Sepp Hochreiter hat in der Forschungsgemeinschaft für großes Aufsehen gesorgt. Die Ergebnisse zeigen vergleichbare Ergebnisse vor dem Coaching mit den neuesten LLMs und es stellt sich die Frage, ob LSTMs erneut die Verarbeitung natürlicher Sprache übernehmen können.
Übersicht über die Excessive-Degree-Architektur
Das ursprüngliche LSTM-Netzwerk hatte einige wesentliche Einschränkungen, die seine Verwendbarkeit für größere Kontexte und tiefere Modelle einschränkten. Nämlich:
- LSTMs waren sequentielle Modelle, die es schwierig machten, Coaching und Inferenz zu parallelisieren.
- Sie verfügten über begrenzte Speicherkapazitäten und alle Informationen mussten in einem einzigen Zellenzustand komprimiert werden.
Das jüngste xLSTM-Netzwerk führt neue sLSTM- und mLSTM-Blöcke ein, um diese beiden Mängel zu beheben. Werfen wir einen Blick aus der Vogelperspektive auf die Modellarchitektur und sehen uns den Ansatz der Autoren an.
Kurzer Rückblick auf Authentic LSTM
Das LSTM-Netzwerk nutzte einen verborgenen Zustand und einen Zellenzustand, um dem Drawback des verschwindenden Gradienten in den Vanilla-RNN-Netzwerken entgegenzuwirken. Sie fügten außerdem die Vergessens-, Eingabe- und Ausgabe-Sigmoid-Gatter hinzu, um den Informationsfluss zu steuern. Die Gleichungen lauten wie folgt:
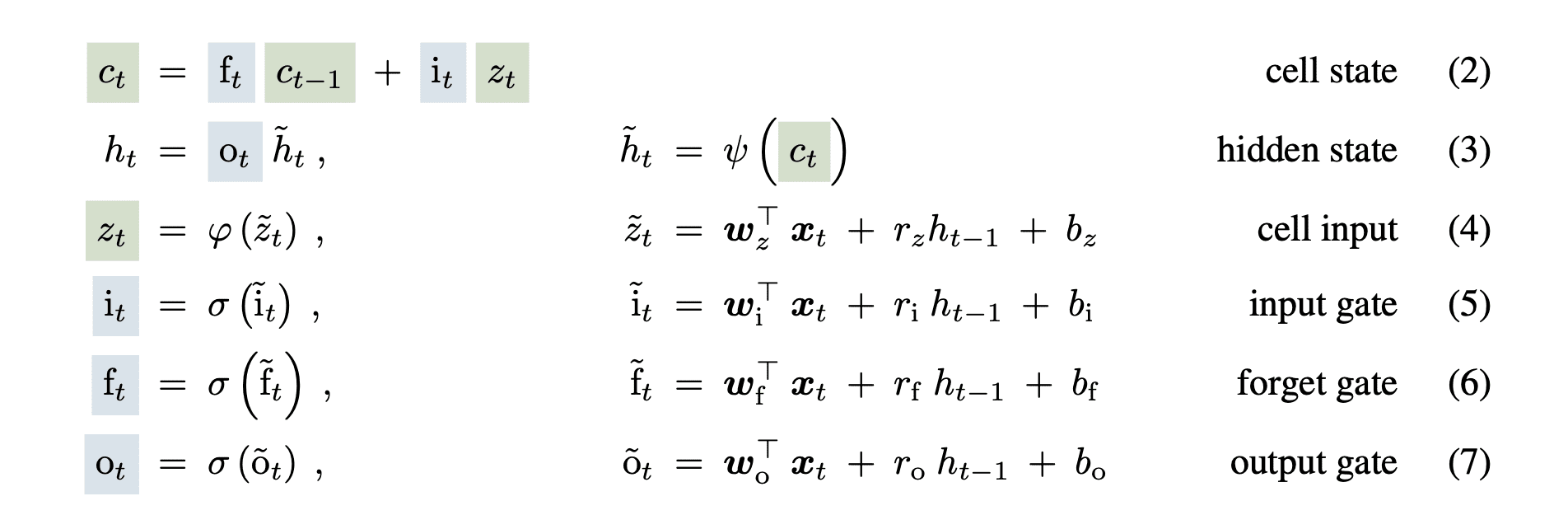
Bild von Papier
Der Zellzustand (ct) durchlief die LSTM-Zelle mit geringfügigen linearen Transformationen, die dazu beitrugen, den Gradienten über große Eingabesequenzen hinweg aufrechtzuerhalten.
Das xLSTM-Modell modifiziert diese Gleichungen in den neuen Blöcken, um die bekannten Einschränkungen des Modells zu beheben.
sLSTM-Block
Der Block modifiziert die Sigmoid-Gatter und verwendet die Exponentialfunktion für das Eingabe- und Vergessen-Gatter. Wie von den Autoren zitiert, kann dies die Speicherprobleme in LSTM verbessern und dennoch mehrere Speicherzellen ermöglichen, die eine Speichermischung innerhalb jedes Kopfes ermöglichen, jedoch nicht kopfübergreifend. Die modifizierte sLSTM-Blockgleichung lautet wie folgt:
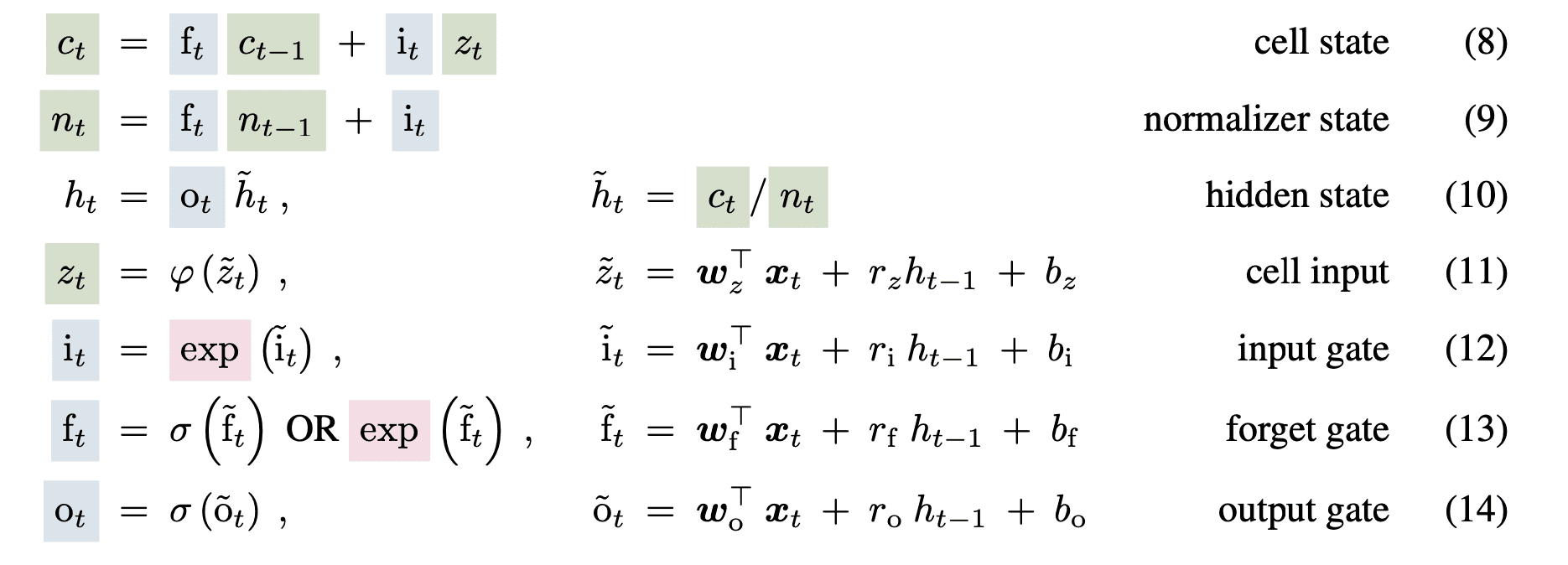
Bild von Papier
Da die Exponentialfunktion außerdem große Werte verursachen kann, werden die Gate-Werte mithilfe von Protokollfunktionen normalisiert und stabilisiert.
mLSTM-Block
Um den Parallelisierbarkeits- und Speicherproblemen im LSTM-Netzwerk entgegenzuwirken, ändert xLSTM den Zellzustand von einem eindimensionalen Vektor in eine zweidimensionale quadratische Matrix. Sie speichern eine zerlegte Model als Schlüssel- und Wertvektoren und verwenden dasselbe exponentielle Gating wie der sLSTM-Block. Die Gleichungen lauten wie folgt:
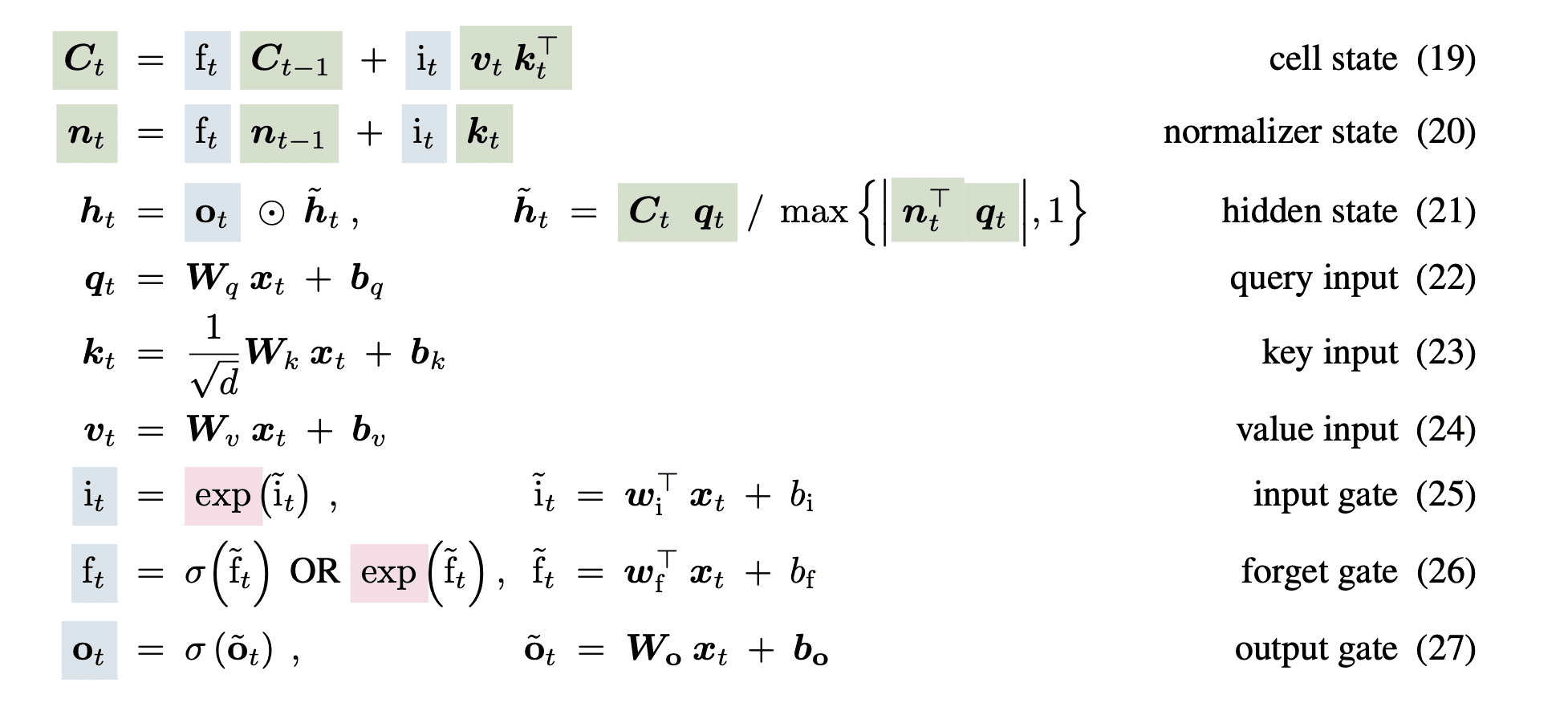
Bild von Papier
Architekturdiagramm
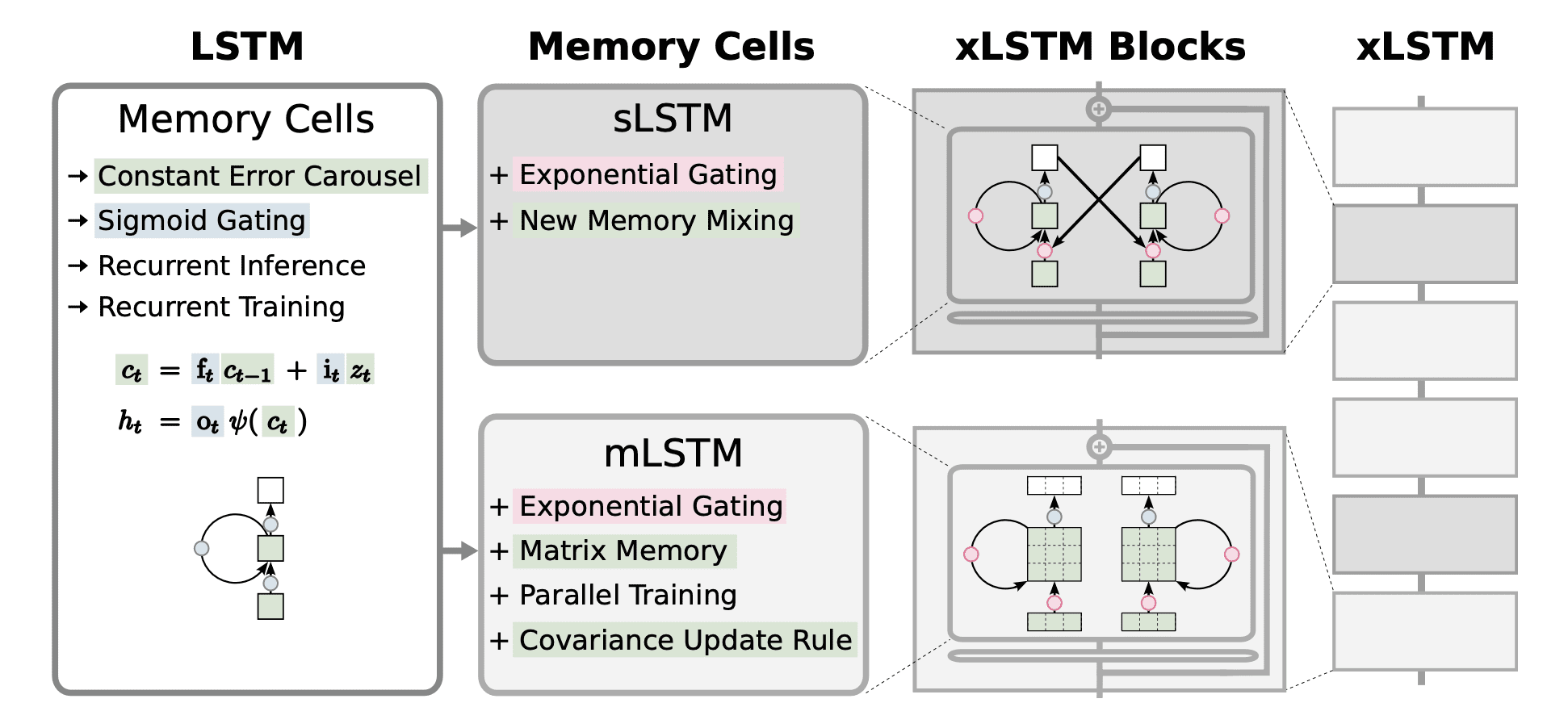
Bild von Papier
Die gesamte xLSTM-Architektur ist eine sequentielle Kombination von mLSTM- und sLSTM-Blöcken in unterschiedlichen Anteilen. Wie das Diagramm zeigt, kann der xLSTM-Block eine beliebige Speicherzelle haben. Die verschiedenen Blöcke werden mit Schichtnormalisierungen zusammengestapelt, um ein tiefes Netzwerk aus Restblöcken zu bilden.
Bewertungsergebnisse und Vergleich
Die Autoren trainieren das xLSTM-Netzwerk auf Sprachmodellaufgaben und vergleichen die Verwirrung (weniger ist besser) des trainierten Modells mit den aktuellen Transformer-basierten LLMs.
Die Autoren trainieren die Modelle zunächst auf 15B-Tokens von SlimPajama. Die Ergebnisse zeigten, dass xLSTM alle anderen Modelle im Validierungssatz mit dem niedrigsten Perplexity-Rating übertrifft.
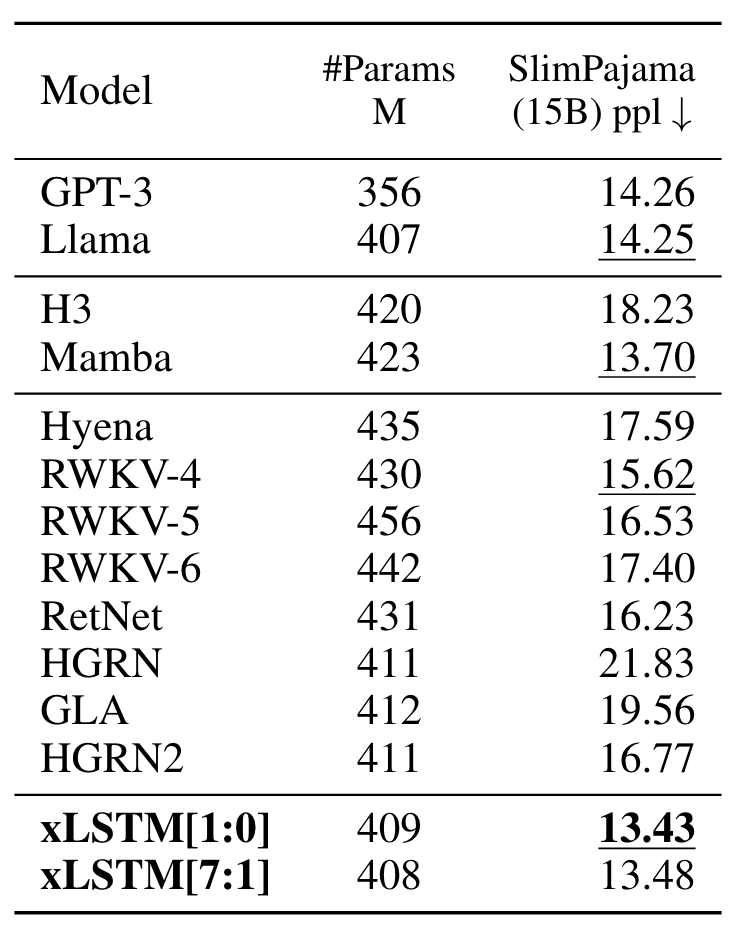
Bild von Papier
Sequenzlängen-Extrapolation
Die Autoren analysieren auch die Leistung, wenn die Länge der Testzeitsequenz die Kontextlänge überschreitet, auf der das Modell trainiert wurde. Sie trainierten alle Modelle auf einer Sequenzlänge von 2048 und die folgende Grafik zeigt die Validierungsschwierigkeiten bei Änderungen der Token-Place:
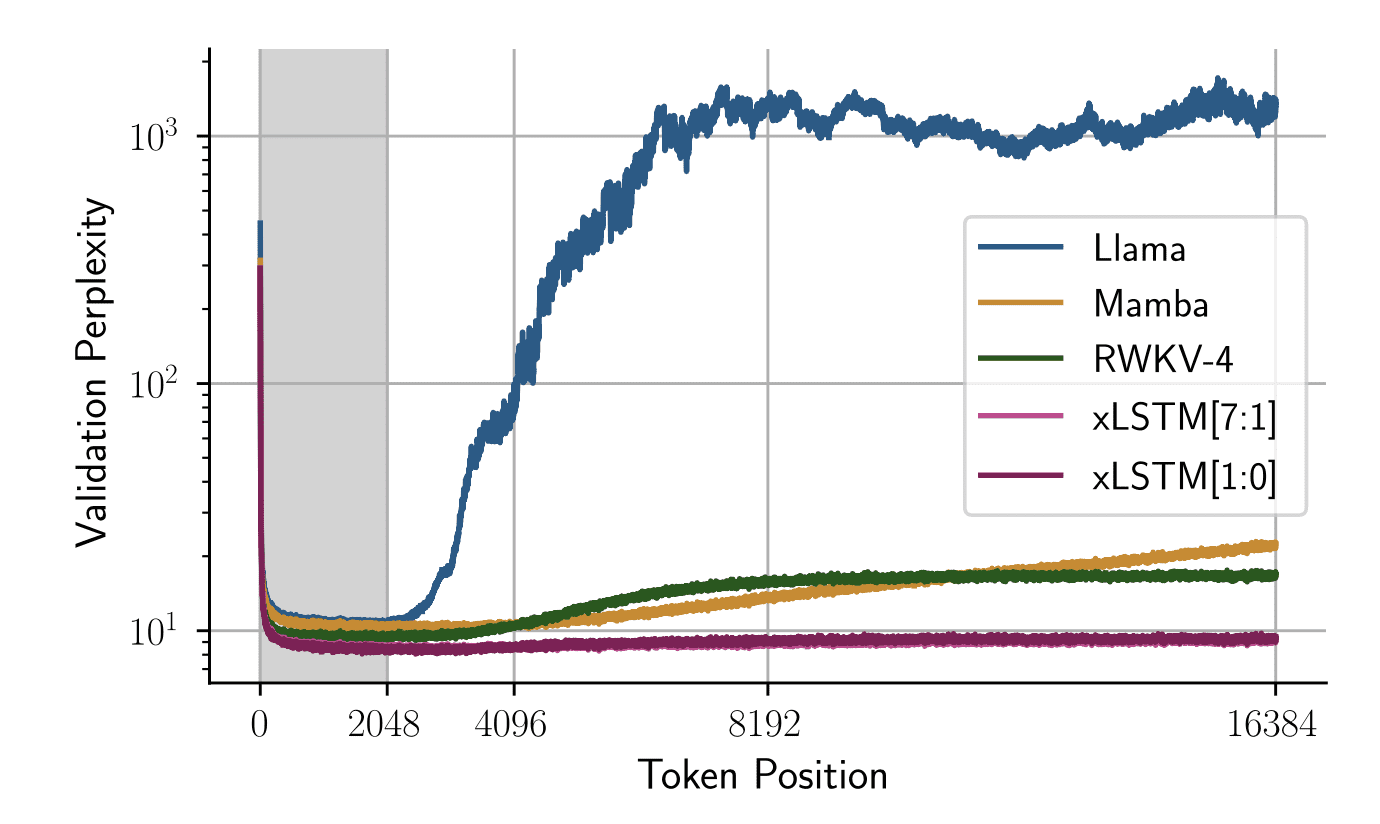
Bild von Papier
Die Grafik zeigt, dass xLSTM-Netzwerke auch bei viel längeren Sequenzen einen stabilen Perplexity-Rating beibehalten und bei viel längeren Kontextlängen eine bessere Leistung als jedes andere Modell erbringen.
Skalierung von xLSMT auf größere Modellgrößen
Die Autoren trainieren das Modell weiter mit 300B-Tokens aus dem SlimPajama-Datensatz. Die Ergebnisse zeigen, dass xLSTM selbst bei größeren Modellgrößen besser skaliert als die aktuelle Transformer- und Mamba-Architektur.
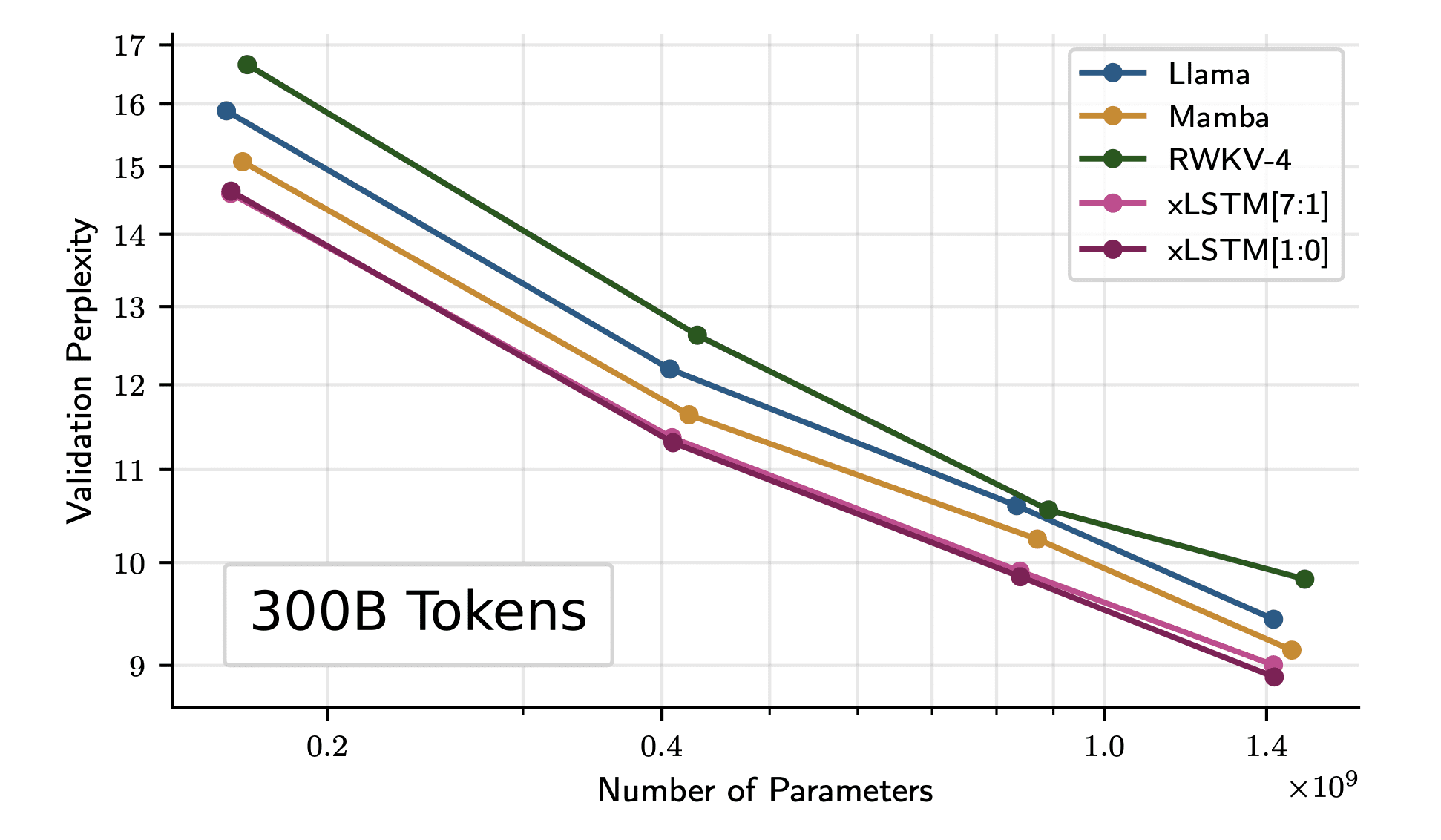
Bild von Papier
Zusammenfassung
Das struggle vielleicht schwer zu verstehen und das ist in Ordnung! Nichtsdestotrotz sollten Sie jetzt verstehen, warum dieser Forschungsbericht in letzter Zeit die ganze Aufmerksamkeit auf sich gezogen hat. Es hat sich gezeigt, dass es mindestens genauso intestine funktioniert wie die jüngsten großen Sprachmodelle, wenn nicht sogar besser. Es ist nachweislich für größere Modelle skalierbar und kann ein ernstzunehmender Konkurrent für alle neueren LLMs sein, die auf Transformers basieren. Nur die Zeit wird zeigen, ob LSTMs ihren Glanz wiedererlangen werden, aber im Second wissen wir, dass die xLSTM-Architektur hier ist, um die Überlegenheit der renommierten Transformers-Architektur herauszufordern.
Kanwal Mehreen Kanwal ist Ingenieur für maschinelles Lernen und technischer Redakteur mit einer großen Leidenschaft für Datenwissenschaft und die Schnittstelle zwischen KI und Medizin. Sie ist Mitautorin des E-Books „Maximizing Productiveness with ChatGPT“. Als Google Technology Scholar 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie ist außerdem als Teradata Variety in Tech Scholar, Mitacs Globalink Analysis Scholar und Harvard WeCode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter von Veränderungen und hat FEMCodes gegründet, um Frauen in MINT-Bereichen zu stärken.