
Im Zeitalter von zunehmend Großsprachige Modelle und komplexe neuronale Netzwerke, die die Optimierung der Modelleffizienz ist, ist von größter Bedeutung geworden. Die Gewichtsquantisierung ist eine entscheidende Technik zur Reduzierung der Modellgröße und zur Verbesserung der Inferenzgeschwindigkeit ohne signifikanten Leistungsabbau. Dieser Leitfaden bietet einen praktischen Ansatz zur Implementierung und Verständnis der Gewichtsquantisierung unter Verwendung von GPT-2 als unser praktisches Beispiel.
Lernziele
- Verstehen Sie die Grundlagen der Gewichtsquantisierung und ihre Bedeutung für die Modelloptimierung.
- Erfahren Sie die Unterschiede zwischen Absmax- und Nullpunkt-Quantisierungstechniken.
- Implementieren Sie Gewichtsquantisierungsmethoden für GPT-2 mithilfe Pytorch.
- Analysieren Sie den Einfluss der Quantisierung auf die Gedächtniseffizienz, die Inferenzgeschwindigkeit und die Genauigkeit.
- Visualisieren Sie quantisierte Gewichtsverteilungen unter Verwendung von Histogrammen für Erkenntnisse.
- Bewerten Sie die Modellleistung nach der Quantisierung durch Textgenerierung und Verwirrungsmetriken.
- Untersuchen Sie die Vorteile der Quantisierung für die Bereitstellung von Modellen auf ressourcenbezogenen Geräten.
Dieser Artikel wurde als Teil der veröffentlicht Knowledge Science Blogathon.
Grundlagen zur Gewichtsquantisierung verstehen
Die Gewichtsquantisierung wandelt hochpräzise Gleitkommagewichte (typischerweise 32-Bit) in Darstellungen mit niedrigerer Präzision (üblicherweise 8-Bit-Ganzzahlen) um. Dieser Prozess reduziert die Modellgröße und den Speicherverbrauch erheblich, während versucht wird, die Modellleistung zu erhalten. Die wichtigste Herausforderung besteht darin, die Modellgenauigkeit aufrechtzuerhalten und gleichzeitig die numerische Präzision zu verringern.
Warum quantisieren?
- Speichereffizienz: Die Reduzierung der Präzision von 32-Bit auf 8-Bit kann die Modellgröße theoretisch um 75% reduzieren
- Schneller Inferenz: Integer-Operationen sind im Allgemeinen schneller als Gleitkommaoperationen
- Niedrigerer Stromverbrauch: Reduzierte Speicherbandbreite und einfachere Berechnungen führen zu Energieeinsparungen
- Flexibilität der Bereitstellung: Kleinere Modelle können auf ressourcenbeschränkten Geräten bereitgestellt werden
Praktische Umsetzung
Lassen Sie uns zwei beliebte Quantisierungsmethoden implementieren: Absmax-Quantisierung und Nullpunktquantisierung.
Einrichten der Umgebung
Zunächst richten wir unsere Entwicklungsumgebung mit notwendigen Abhängigkeiten ein:
import seaborn as sns
import torch
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
from copy import deepcopy
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import seaborn as snsIm Folgenden werden wir uns mit der Implementierung von Quantisierungsmethoden befassen:
Absmax -Quantisierung
Die Absmax Quantisierungsmethode skaliert Gewichte basierend auf dem maximalen Absolutwert im Tensor:
# Outline quantization features
def absmax_quantize(X):
scale = 100 / torch.max(torch.abs(X)) # Adjusted scale
X_quant = (scale * X).spherical()
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequantDiese Methode funktioniert nach:
- Finden Sie den maximalen Absolutwert im Gewichtstensor
- Berechnung eines Skalierungsfaktors, um Werte in den Int8 -Bereich anzupassen
- Skalierung und Rundung der Werte
- Bereitstellung von quantisierten und dequantisierten Versionen
Schlüsselvorteile:
- Einfache Implementierung
- Gute Erhaltung großer Werte
- Symmetrische Quantisierung um Null
Nullpunktquantisierung
Nullpunktquantisierung fügt einen Offset hinzu, um asymmetrische Verteilungen besser zu handhaben:
def zeropoint_quantize(X):
x_range = torch.max(X) - torch.min(X)
x_range = 1 if x_range == 0 else x_range
scale = 200 / x_range
zeropoint = (-scale * torch.min(X) - 128).spherical()
X_quant = torch.clip((X * scale + zeropoint).spherical(), -128, 127)
X_dequant = (X_quant - zeropoint) / scale
return X_quant.to(torch.int8), X_dequantAusgabe:
Utilizing gadget: cudaDiese Methode:
- Berechnet den gesamten Wertebereich
- Bestimmt die Parameter der Skala und der Nullpunkte
- Wendet Skalierung und Verschiebung an
- Clips -Werte, um int8 Grenzen zu gewährleisten
Vorteile:
- Besserer Umgang mit asymmetrischen Verteilungen
- Verbesserte Darstellung von Null-Null-Werten
- Oft führt zu einer besseren Gesamtgenauigkeit
Laden und Vorbereitung des Modells
Wenden wir diese Quantisierungsmethoden auf ein reales Modell an. Wir werden GPT-2 als unser Beispiel verwenden:
# Load mannequin and tokenizer
model_id = 'gpt2'
mannequin = AutoModelForCausalLM.from_pretrained(model_id).to(gadget)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Print mannequin dimension
print(f"Mannequin dimension: {mannequin.get_memory_footprint():,} bytes")Ausgabe:
Quantisierungsprozess: Gewichte und Modell
Tauchen Sie in die Anwendung von Quantisierungstechniken sowohl auf individuelle Gewichte als auch auf das gesamte Modell ein. Dieser Schritt sorgt für den geringeren Speicherverbrauch und die Recheneffizienz bei der Aufrechterhaltung der Leistung.
# Quantize and visualize weights
weights_abs_quant, _ = absmax_quantize(weights)
weights_zp_quant, _ = zeropoint_quantize(weights)
# Quantize your entire mannequin
model_abs = deepcopy(mannequin)
model_zp = deepcopy(mannequin)
for param in model_abs.parameters():
_, dequantized = absmax_quantize(param.information)
param.information = dequantized
for param in model_zp.parameters():
_, dequantized = zeropoint_quantize(param.information)
param.information = dequantizedVisualisierung quantisierter Gewichtsverteilungen
Visualisieren Sie und vergleichen Sie die Gewichtsverteilungen der ursprünglichen, von Absmax quantisierten und null Punkt quantisierten Modelle. Diese Histogramme geben Einblicke in die Auswirkungen der Quantisierung und deren Gesamtverteilung.
# Visualize histograms of weights
def visualize_histograms(original_weights, absmax_weights, zp_weights):
sns.set_theme(type="darkgrid")
fig, axs = plt.subplots(2, figsize=(10, 10), dpi=300, sharex=True)
axs(0).hist(original_weights, bins=100, alpha=0.6, label="Unique weights", colour="navy", vary=(-1, 1))
axs(0).hist(absmax_weights, bins=100, alpha=0.6, label="Absmax weights", colour="orange", vary=(-1, 1))
axs(1).hist(original_weights, bins=100, alpha=0.6, label="Unique weights", colour="navy", vary=(-1, 1))
axs(1).hist(zp_weights, bins=100, alpha=0.6, label="Zero-point weights", colour="inexperienced", vary=(-1, 1))
for ax in axs:
ax.legend()
ax.set_xlabel('Weights')
ax.set_ylabel('Frequency')
ax.yaxis.set_major_formatter(ticker.EngFormatter())
axs(0).set_title('Unique vs Absmax Quantized Weights')
axs(1).set_title('Unique vs Zero-point Quantized Weights')
plt.tight_layout()
plt.present()
# Flatten weights for visualization
original_weights = np.concatenate((param.information.cpu().numpy().flatten() for param in mannequin.parameters()))
absmax_weights = np.concatenate((param.information.cpu().numpy().flatten() for param in model_abs.parameters()))
zp_weights = np.concatenate((param.information.cpu().numpy().flatten() for param in model_zp.parameters()))
visualize_histograms(original_weights, absmax_weights, zp_weights)Der Code enthält eine umfassende Visualisierungsfunktion:
- Diagramm mit Originalgewichten gegen Absmax -Gewichte
- Grafik mit Originalgewichten gegen Nullpunktgewichte
Ausgabe:
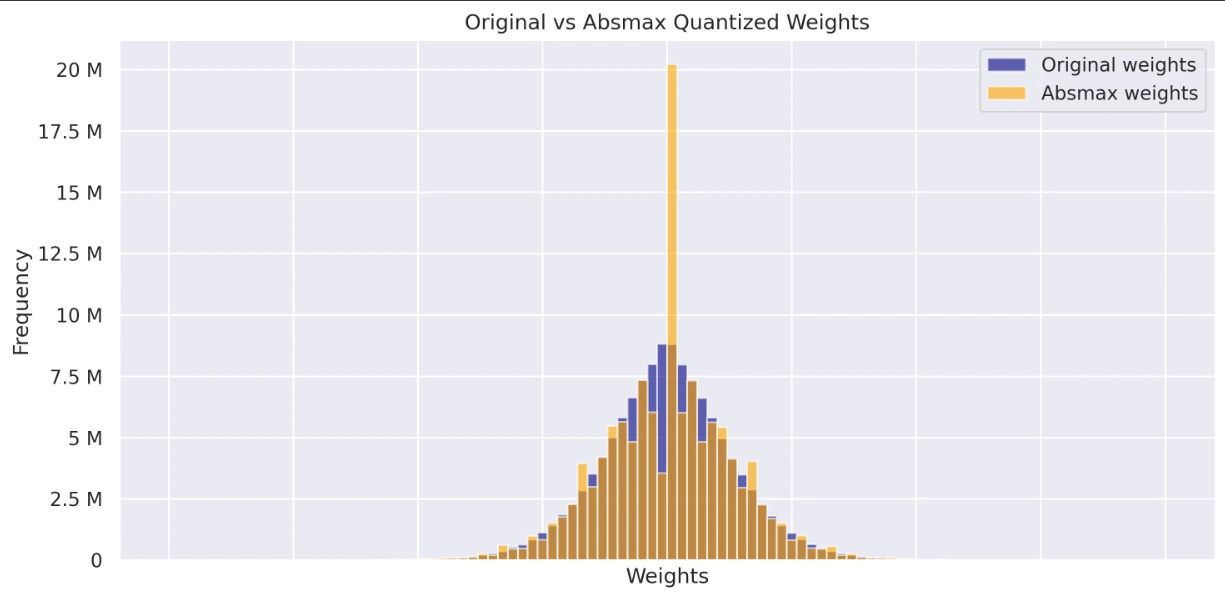
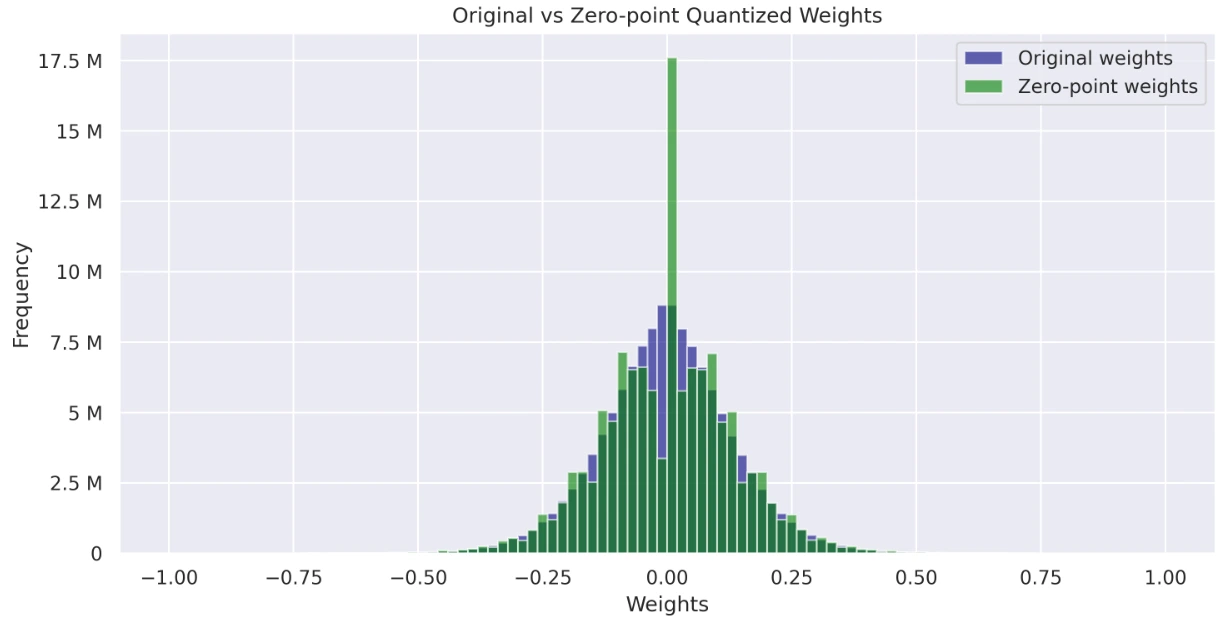
Leistungsbewertung
Die Bewertung der Auswirkungen der Quantisierung auf die Modellleistung ist wichtig, um Effizienz und Genauigkeit zu gewährleisten. Messen wir, wie intestine die quantisierten Modelle im Vergleich zum Unique abschneiden.
Textgenerierung
Erforschen Sie, wie die quantisierten Modelle Textual content generieren, und vergleichen Sie die Qualität der Ausgaben mit den Vorhersagen des Originalmodells.
def generate_text(mannequin, input_text, max_length=50):
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(gadget)
output = mannequin.generate(inputs=input_ids,
max_length=max_length,
do_sample=True,
top_k=30,
pad_token_id=tokenizer.eos_token_id,
attention_mask=input_ids.new_ones(input_ids.form))
return tokenizer.decode(output(0), skip_special_tokens=True)
# Generate textual content with unique and quantized fashions
original_text = generate_text(mannequin, "The way forward for AI is")
absmax_text = generate_text(model_abs, "The way forward for AI is")
zp_text = generate_text(model_zp, "The way forward for AI is")
print(f"Unique mannequin:n{original_text}")
print("-" * 50)
print(f"Absmax mannequin:n{absmax_text}")
print("-" * 50)
print(f"Zeropoint mannequin:n{zp_text}")Dieser Code vergleicht die Ausgaben der Textgenerierung aus drei Modellen: dem Unique, einem quantisierten Modell „Absmax“ und einem quantisierten Modell „Neropoint“. Es verwendet eine Funktion generate_text, um Textual content basierend auf einer Eingabeaufforderung zu generieren, wobei die Abtastung mit einem Prime-Okay-Wert von 30 angewendet wird. Schließlich druckt sie die Ergebnisse aller drei Modelle.
Ausgabe:

# Perplexity analysis
def calculate_perplexity(mannequin, textual content):
encodings = tokenizer(textual content, return_tensors="pt").to(gadget)
input_ids = encodings.input_ids
with torch.no_grad():
outputs = mannequin(input_ids, labels=input_ids)
return torch.exp(outputs.loss)
long_text = "Synthetic intelligence is a transformative know-how that's reshaping industries."
ppl_original = calculate_perplexity(mannequin, long_text)
ppl_absmax = calculate_perplexity(model_abs, long_text)
ppl_zp = calculate_perplexity(model_zp, long_text)
print(f"nPerplexity (Unique): {ppl_original.merchandise():.2f}")
print(f"Perplexity (Absmax): {ppl_absmax.merchandise():.2f}")
print(f"Perplexity (Zero-point): {ppl_zp.merchandise():.2f}")Der Code berechnet die Verwirrung (ein Maß dafür, wie intestine ein Modell Textual content vorhersagt) für eine bestimmte Eingabe unter Verwendung von drei Modellen: dem ursprünglichen, quantisierten „Absmax“ -Modellen und „ZeroPoint“. Eine geringere Verwirrung zeigt eine bessere Leistung an. Es druckt die Verwirrungswerte zum Vergleich.
Ausgabe:

Sie können hier auf Colab Hyperlink zugreifen.
Vorteile der Gewichtsquantisierung
Im Folgenden werden wir uns mit den Vorteilen der Gewichtsquantisierung befassen:
- Speichereffizienz: Die Quantisierung reduziert die Modellgröße um bis zu 75percentund ermöglicht eine schnellere Belastung und Inferenz.
- Schneller Inferenz: Integer-Operationen sind schneller als Gleitkommaoperationen, was zu einer schnelleren Modellausführung führt.
- Niedrigerer Stromverbrauch: Reduzierte Speicherbandbreite und vereinfachte Berechnung führen zu Energieeinsparungen, wesentlich für Edge -Geräte und cellular Bereitstellung.
- Flexibilität der Bereitstellung: Kleinere Modelle sind einfacher zu {Hardware} mit begrenzten Ressourcen (z. B. Mobiltelefone, eingebettete Geräte).
- Minimale Leistungsverschlechterung: Mit der richtigen Quantisierungsstrategie können Modelle trotz der reduzierten Präzision den größten Teil ihrer Genauigkeit behalten.
Abschluss
Die Gewichtsquantisierung spielt eine entscheidende Rolle bei der Verbesserung der Effizienz großer Sprachmodelle, insbesondere wenn es darum geht, sie auf ressourcenbeschränkten Geräten einzusetzen. Durch die Umwandlung hochpräziser Gewichte in Ganzzahldarstellungen mit niedrigerer Präzision können wir den Speicherverbrauch erheblich reduzieren, die Inferenzgeschwindigkeit verbessern und den Stromverbrauch senken, ohne die Leistung des Modells stark zu beeinflussen.
In diesem Leitfaden untersuchten wir zwei beliebte Quantisierungstechniken-Absmax-Quantisierung und Nullpunktquantisierung-mit GPT-2 als praktisches Beispiel. Beide Techniken zeigten die Fähigkeit, den Speicherausdruck und die Rechenanforderungen des Modells zu verringern und gleichzeitig ein hohes Maß an Genauigkeit bei den Aufgaben der Textgenerierung beizubehalten. Die Nullpunkt-Quantisierungsmethode mit seinem asymmetrischen Ansatz führte jedoch im Allgemeinen zu einer besseren Erhaltung der Modellgenauigkeit, insbesondere für nicht symmetrische Gewichtsverteilungen.
Key Takeaways
- Die Absmax-Quantisierung ist einfacher und eignet sich intestine für symmetrische Gewichtsverteilungen, obwohl sie möglicherweise asymmetrische Verteilungen möglicherweise nicht so effektiv wie Nullpunktquantisierung erfasst.
- Die Quantisierung von Nullpunkten bietet einen flexibleren Ansatz, indem ein Offset für asymmetrische Verteilungen eingeführt wird, die häufig zu einer besseren Genauigkeit und einer effizienteren Darstellung von Gewichten führen.
- Quantisierung ist für die Bereitstellung großer Modelle in Echtzeitanwendungen, in denen die Rechenressourcen begrenzt sind, von wesentlicher Bedeutung.
- Trotz des Quantisierungsprozesses, der die Präzision verringert, ist es möglich, die Modellleistung in der Nähe des Originals mit ordnungsgemäßen Stimm- und Quantisierungsstrategien aufrechtzuerhalten.
- Visualisierungstechniken wie Histogramme können Einblicke in die Auswirkungen der Quantisierung und die Verteilung der Werte in den Tensoren geben.
Häufig gestellte Fragen
A. Die Gewichtsquantisierung verringert die Genauigkeit der Gewichte eines Modells, typischerweise von 32-Bit-Gleitkommawerten bis hin zu Ganzzahlen mit niedrigerer Präzision (z. B. 8-Bit-Ganzzahlen), um Speicher und Berechnung zu sparen und gleichzeitig die Leistung aufrechtzuerhalten.
A. Während die Quantisierung den Speicherausdruck und die Inferenzzeit des Modells verringert, kann dies zu einer leichten Genauigkeit führen. Wenn jedoch korrekt erledigt ist, ist der Genauigkeitsverlust minimal.
A. Ja, die Quantisierung kann auf jedes neuronale Netzwerkmodell angewendet werden, einschließlich Sprachmodelle, Visionsmodellen und anderen Architekturen für Deep -Studying -Architekturen.
A. Sie können die Quantisierung implementieren, indem Sie die Gewichte des Modells skalieren und umrunden und dann über alle Parameter hinweg anwenden. Bibliotheken wie Pytorch unterstützen einige Quantisierungstechniken nativ, obwohl benutzerdefinierte Implementierungen, wie im Leitfaden gezeigt, Flexibilität bieten.
A. Die Gewichtsquantisierung ist für große Modelle am effektivsten, bei denen die Reduzierung des Speicherausdrucks und der Berechnung von entscheidender Bedeutung ist. Sehr kleine Modelle profitieren jedoch möglicherweise nicht so stark von der Quantisierung.
Die in diesem Artikel gezeigten Medien sind nicht im Besitz von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Mein Title ist Nilesh Dwivedi und ich freue mich, dieser lebendigen Group von Bloggern und Lesern beizutreten. Ich bin derzeit in meinem ersten Jahr in BTech, der sich auf Datenwissenschaft und künstliche Intelligenz auf IIIT Dharwad spezialisiert hat. Ich bin begeistert von Technologie und Datenwissenschaft und freue mich darauf, mehr Blogs zu schreiben.