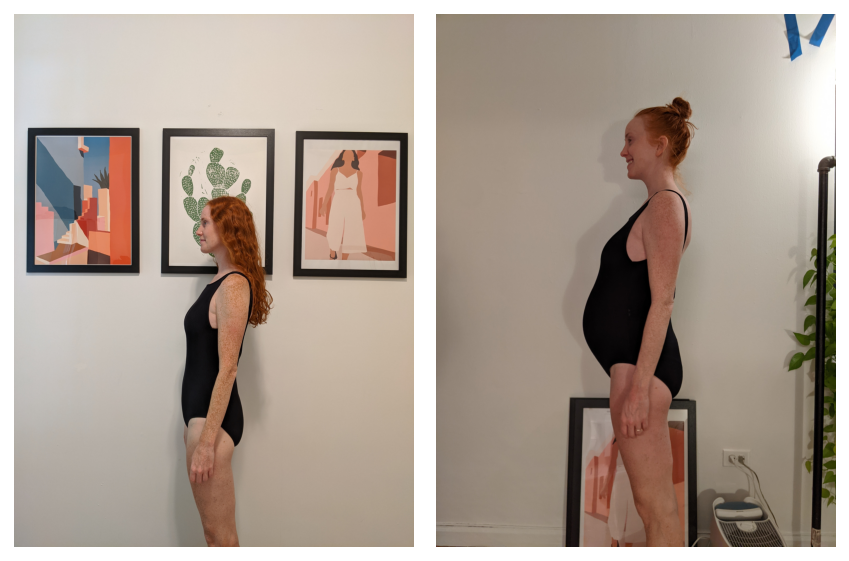
Ich habe Anfang des Jahres ein Type bekommen.
Warten Sie, um Applaus zu erhalten
Na ja, nicht ich persönlich, aber meine Frau schon.
Ich erzähle Ihnen das nur, um Ihnen zu sagen, dass ich jede Woche ein Foto von meiner Frau gemacht habe, als sie schwanger conflict.
Wir dachten, es wäre vielleicht interessant, eines Tages noch einmal auf diese Bilder zurückzublicken. Sie trug das gleiche Outfit und blickte bei jedem Bild in die gleiche Richtung, obwohl sich der Hintergrund gelegentlich änderte. Um den Dingen in meinem Leben weniger neurotisch gegenüberzustehen, habe ich bewusst auf ein Stativ verzichtet und auch nicht versucht, das Bild aus genau demselben Winkel und derselben Entfernung aufzunehmen.
Am Ende wurde ein Type geboren und ich vergaß die besagten Bilder sofort, denn wen interessieren solche Dinge um 4 Uhr morgens?
Nun, es ist einige Zeit vergangen und das Type schläft die ganze Nacht durch.
Warten Sie, um Applaus zu erhalten
Ich habe jetzt etwas Freizeit und dachte, es wäre cool, eine Animation dieser Schwangerschaftsbilder zu machen. Angesichts meiner fotografischen Unvollkommenheit musste ich die Bilder für die Animation zuschneiden, drehen und ausrichten. Natürlich wollte ich das nicht manuell machen. Wie lange könnte es dauern, automatisieren?
…
Offensichtlich hat die Automatisierung viel länger gedauert als die manuelle Durchführung, aber jetzt kann ich darüber sprechen, wie ich dieses Video mithilfe der differenzierbaren, semantischen Bildregistrierung mit Kornia erstellt habe.
Hinweis: Wie die meisten meiner Blogbeiträge habe ich auch diesen in einem Jupiter-Notizbuch geschrieben. Ich werde auf ein Paket namens verweisen Ausrichtung im Code. Dies ist nur eine kleine Bibliothek, die ich erstellt habe, um meinen Code unterzubringen und diesen Weblog-Beitrag lesbarer zu machen.
Fototermine
Um das vorliegende Drawback zu verstehen, schauen wir uns zwei verschiedene Bilder an, die ich ausrichten möchte:
%config InlineBackend.figure_format = 'retina'
from pathlib import Path
import alignimation
import kornia as Okay
import matplotlib.pyplot as plt
import torch
import torch.nn.practical as F
imgs = alignimation.io.load_images(Path("body_pics"))
fig, axs = plt.subplots(1, 2)
axs(0).imshow(Okay.tensor_to_image(imgs(0)))
axs(1).imshow(Okay.tensor_to_image(imgs(22)))
axs(0).axis("off")
axs(1).axis("off")
fig.tight_layout()
None
Das Ziel hier ist, beide Bilder so zu verändern, dass die Körper vorhanden sind Eingetragen miteinander. Man könnte sich mehrere verschiedene vorstellen Operationen Das könnte man am Bild tun, um dies zu erreichen: Man kann das Bild in eine Richtung verschieben, man kann hinein- oder herauszoomen und man kann das Bild drehen. (Sie könnten auch andere believable Dinge tun, wie zum Beispiel das Bild scheren, aber wir werden diese Vorgänge ignorieren.)
Ein Bild ist eine 3D-Matrix (oder Tensor in modernen Begriffen). Für jedes Pixel gibt es eine Höhen- und Breitendimension und dann drei Kanaldimensionen (Rot, Grün und Blau).
print(kind(imgs(0)))
print(imgs(0).form)
<class 'torch.Tensor'>
torch.Dimension((1, 3, 4032, 3024))
In der Welt der linearen Algebra sind die Operationen, die wir gerne durchführen würden, bekannte Matrixtransformationen: Translation, Skalierung und Rotation. Diese können rein in durchgeführt werden numpy oder mit einer Vielzahl anderer Bibliotheken.
Großartig, wir können herausfinden, wie wir die Bilder transformieren, aber wie stark transformieren wir jedes Bild?
Differenzierung durch Differenzierung
Vor ein paar Jahren habe ich eine gegeben sprechen bei SciPy über alle Gründe, warum Deep-Studying-Frameworks spannend sind, wenn es nicht um Deep Studying geht. Einer dieser Gründe ist die automatische Differenzierung: Solange Sie Ihr „Modell“ mithilfe des Deep-Studying-Frameworks ausdrücken können, können Sie alle Arten von Zielfunktionen optimieren, ohne Kalküle schreiben zu müssen.
Wenn ich kann, komme ich noch einmal auf unser Drawback mit der automatischen Bildregistrierung zurück
- Definieren Sie meine Bildtransformationen mithilfe eines Deep-Studying-Frameworks
- Überlegen Sie sich eine Zielfunktion, die beschreibt, wie registriert zwei Bilder sind
Dann kann ich diese Zielfunktion optimieren, um die optimalen Bildtransformationsparameter zu finden.
Gegen Ende meines Vortrags erwähnte ich, dass es großartig wäre, wenn wir alle möglichen Spezialbibliotheken auf der Foundation von Deep-Studying-Frameworks neu aufbauen würden, um neben der automatischen Differenzierung auch alle möglichen anderen Dinge wie eine Beschleunigung der GPU nutzen zu können.
Kornia ist genau eine dieser Bibliotheken, von denen ich gehofft hatte, dass sie gebaut werden würden. kornia bietet viele der Funktionen „klassischer“ Pc-Imaginative and prescient-Bibliotheken wie OpenCV und das MATLAB Bildverarbeitungs-Toolboxaber es ist darauf aufgebaut PyTorch. Entscheidend sind alle Bildtransformationen in kornia sind differenzierbare PyTorch-Module.
Was ist das Ziel?
Eine einfache zu optimierende Zielfunktion wäre die absolute (L1) Differenz zwischen jedem Pixel zweier verschiedener Bilder. Bei der Ausrichtung der Bilder hätten die Pixel vermutlich ähnliche Werte. Somit könnten wir diese Zielfunktion minimieren.
Während ich an diesem Projekt arbeitete, erschien eine neue Model von kornia wurde veröffentlicht, das genau dafür eine Funktionalität hatte: das ImageRegistrator Modul lernt ein Modell für Bildtransformationen, um den L1-Verlust zwischen zwei Bildern zu minimieren.
Während dies für meinen Anwendungsfall funktionieren könnte, hatte ich Angst, dass der Hintergrund meiner Bilder die Optimierung der Ausrichtung meiner Frau beeinträchtigen würde. Zum Glück können wir PyTorch verwenden, da wir es bereits verwenden Fackelvision um den Körper in einem Bild leicht zu erkennen.
from torchvision.fashions.detection import maskrcnn_resnet50_fpn
segmentation_model = maskrcnn_resnet50_fpn(
pretrained=True, progress=False
)
segmentation_model = segmentation_model.eval()
person_index = (
alignimation.constants.COCO_INSTANCE_CATEGORY_NAMES.index("individual")
)
masks = alignimation.base.get_segmentation_masks(
torch.cat((imgs(0), imgs(22))),
segmentation_model,
"cpu",
person_index
)
fig, axs = plt.subplots(1, 2)
axs(0).imshow(Okay.tensor_to_image(imgs(0)))
axs(1).imshow(
Okay.tensor_to_image(masks(0)), cmap=plt.get_cmap("turbo")
)
axs(0).axis("off")
axs(1).axis("off")
fig.tight_layout()
None
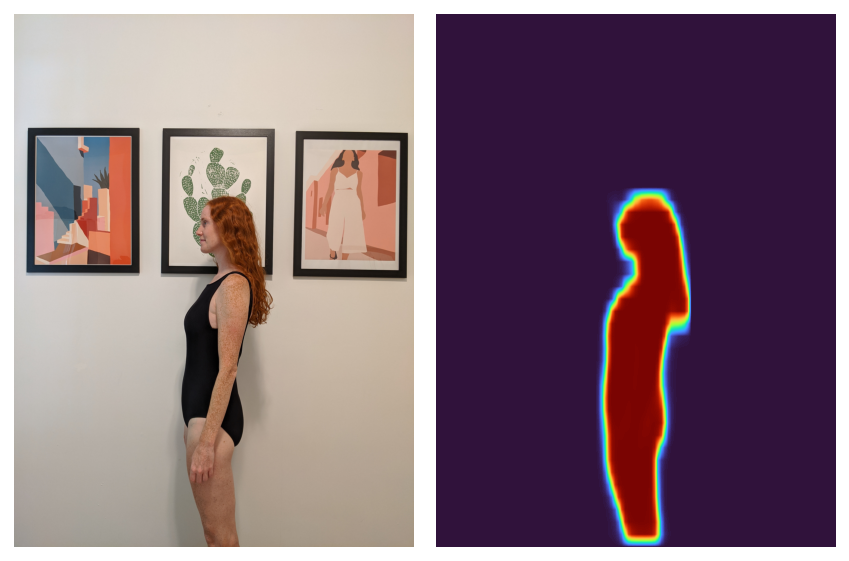
Da wir nun den Körper auswählen können, lautet das Rezept:
- Erstellen Sie die „Segmentierungsmaske“, die dem Körper im Bild entspricht.
- Passen Sie an
ImageRegistratorum die Segmentierungsmasken auszurichten. - Nutzen Sie das Geschulte
ImageRegistratorum das tatsächliche Bild zu registrieren.
Erinnern Sie sich, als ich sagte, ich versuche, weniger neurotisch zu sein? Leider ging das alles verloren, als ich anfing, Code zu schreiben. Ich befürchtete, dass die Veränderung des Körpers meiner Frau die Ausrichtung der Segmentierungsmaske beeinflussen würde, da der Schwerpunkt nach hyperlinks verschoben wird – ich meine, wenn das Child wächst. Außerdem sind die Haare meiner Frau manchmal nach oben und manchmal nach unten gerichtet, und die Segmentierungsmaske umfasst die Haare.
Wie richtet man nur den Körper und weder das Child noch die Haare aus? Wieder, torchvision zur Rettung. Verwendung einer Kernpunkt Modell können wir das linke Ohr, die Schulter und die Hüfte erkennen.
from torchvision.fashions.detection import keypointrcnn_resnet50_fpn
keypoint_model = keypointrcnn_resnet50_fpn(
pretrained=True, progress=False
)
keypoint_model = keypoint_model.eval()
keypoint_names = ("left_ear", "left_shoulder", "left_hip")
keypoint_indices = (
alignimation.constants.BODY_KEYPOINT_NAMES.index(ok)
for ok in keypoint_names
)
keypoints = alignimation.base.get_keypoints(
keypoint_model,
torch.cat((imgs(0), imgs(22))),
"cpu",
1,
keypoint_indices
)
fig, axs = plt.subplots(1, 2)
axs(0).imshow(Okay.tensor_to_image(imgs(0)))
axs(0).scatter(
x=keypoints(0, :, 0),
y=keypoints(0, :, 1),
s=30,
marker="o",
coloration="purple",
)
axs(1).imshow(Okay.tensor_to_image(imgs(22)))
axs(1).scatter(
x=keypoints(1, :, 0),
y=keypoints(1, :, 1),
s=30,
marker="o",
coloration="purple",
)
axs(0).axis("off")
axs(1).axis("off")
fig.tight_layout()
None
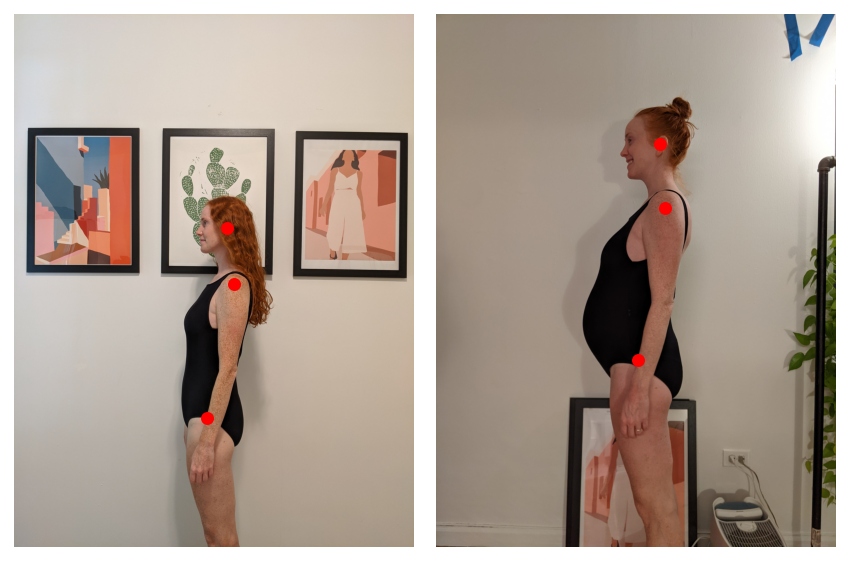
Es kann schwierig sein, die Registrierung von drei einzelnen Punkten zu optimieren. Lassen Sie uns additionally zwischen der Segmentierungsmaske und den Schlüsselpunkten interpolieren: Ich werde 2D-Gauß-Funktionen um jeden Schlüsselpunkt erstellen und diese dann mit der Segmentierungsmaske multiplizieren. Dies alles sollte für eine schöne, reibungslose Optimierung sorgen.
gaussians = alignimation.base.make_keypoint_gaussians(
keypoints, imgs(0).form(-2:)
)
gaussian_masks = masks * gaussians
fig, axs = plt.subplots(1, 2)
axs(0).imshow(
Okay.tensor_to_image(gaussian_masks(0).sum(dim=0, keepdim=True)),
cmap=plt.get_cmap("turbo"),
)
axs(1).imshow(
Okay.tensor_to_image(gaussian_masks(1).sum(dim=0, keepdim=True)),
cmap=plt.get_cmap("turbo"),
)
axs(0).axis("off")
axs(1).axis("off")
fig.tight_layout()
None
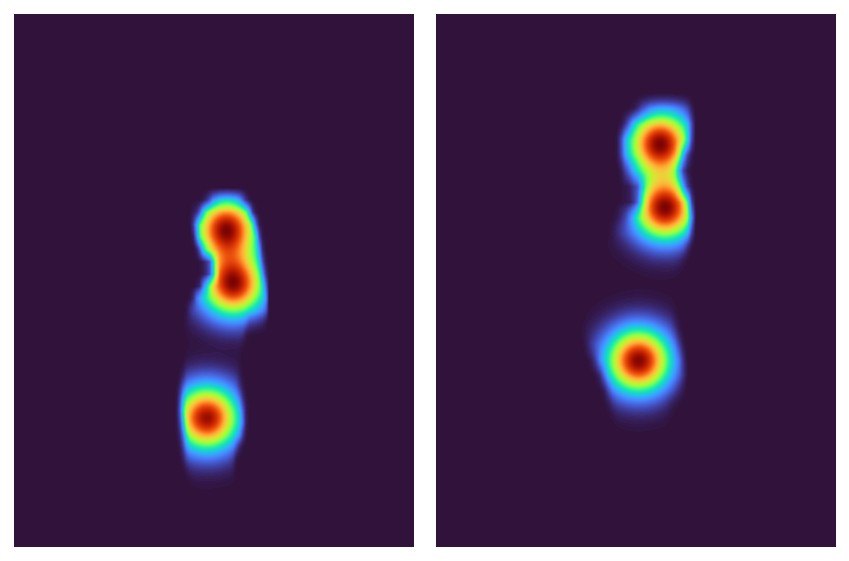
Jetzt müssen nur noch die beiden Masken endlich miteinander registriert werden. Im Einklang mit unserer Richtlinie zur reibungslosen Optimierung verwenden wir einen L2-Verlust.
registrator = Okay.geometry.ImageRegistrator(
"similarity", tolerance=1e-8, loss_fn=F.mse_loss
)
_ = registrator.register(gaussian_masks((1)), gaussian_masks((0)))
Nachdem das Modell zur Registrierung der beiden Masken angepasst wurde, kann es zur Registrierung der beiden Bilder verwendet werden.
with torch.inference_mode():
aligned_mask = registrator.warp_src_into_dst(gaussian_masks((1)))
aligned_img = registrator.warp_src_into_dst(imgs(22))
fig, axs = plt.subplots(2, 2, figsize=(6, 8))
axs = axs.flatten()
axs(0).imshow(
Okay.tensor_to_image(gaussian_masks(0).sum(dim=0, keepdim=True)),
cmap=plt.get_cmap("turbo"),
)
axs(1).imshow(
Okay.tensor_to_image(aligned_mask(0).sum(dim=0, keepdim=True)),
cmap=plt.get_cmap("turbo"),
)
axs(2).imshow(Okay.tensor_to_image(imgs(0)))
axs(3).imshow(Okay.tensor_to_image(aligned_img))
for ax in axs:
ax.axis("off")
fig.tight_layout()
None
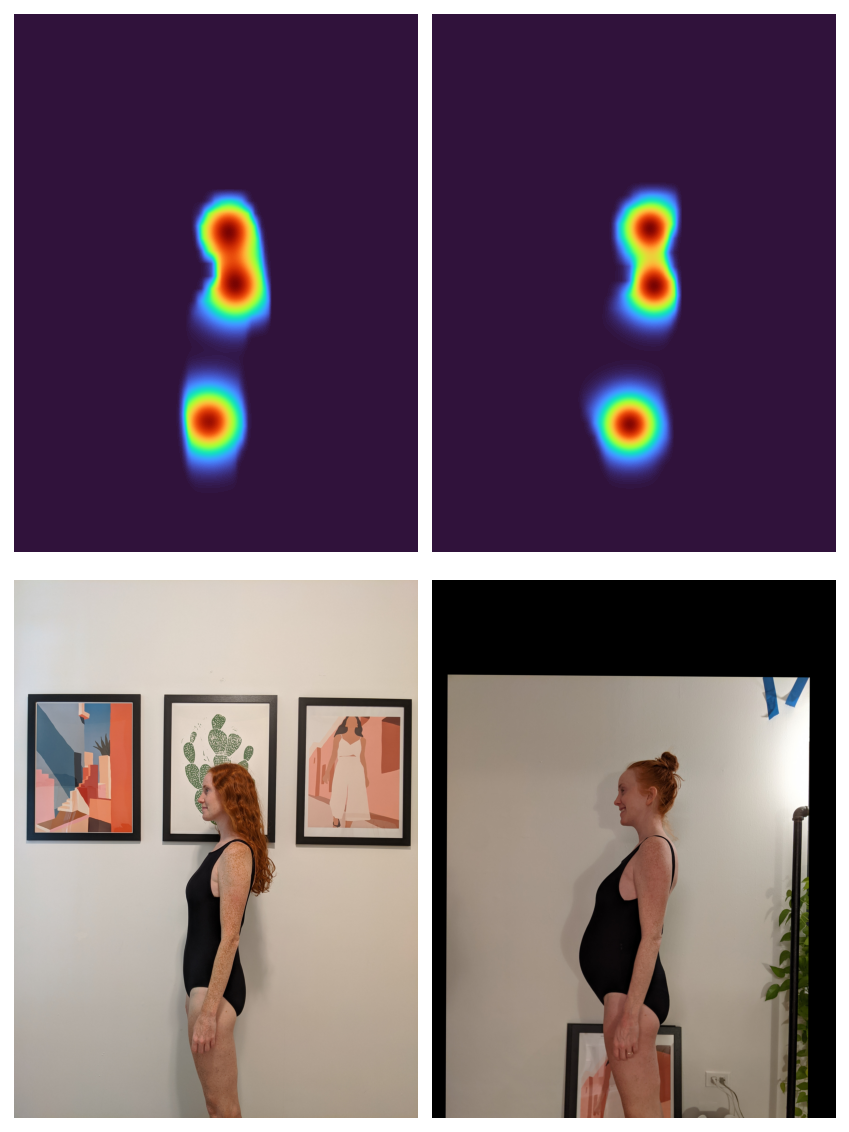
Hurra! Um die „Ausrichtung“ oben in diesem Beitrag vorzunehmen, habe ich für alle meine Fotos das oben beschriebene Verfahren befolgt.
Als Bonus kann ich, da ich bereits die Körpersegmentierungsmaske hatte, den Hintergrund hackenartig entfernen:
Flüchtige Jugend
Während ich daran arbeitete, wurde mir klar, dass dieser Code für jedes Szenario wiederverwendet werden kann, in dem man eine Reihe von Schlüsselpunkten oder Segmentierungsmasken ausrichten möchte. Auch wenn es sehr gruselig und überwachungsmäßig ist, könnte man wichtige Gesichtspunkte heraussuchen und eine Reihe von Bildern derselben Particular person aneinanderreihen.
Apropos Überwachung: Ich speichere alle meine Fotos in Google Fotos. Ich habe nicht nur Bilder gespeichert, die ich mit meinem Telefon aufgenommen habe, sondern auch eine Reihe alter digitaler Bilder hochgeladen, die etwa aus dem Jahr 2000 stammen.
Eine alarmierende, aber praktische Funktion von Google Fotos besteht darin, dass es automatisch die Gesichter verschiedener Personen in Ihren Bildern erkennt und Alben erstellt, die nur Bilder dieser Particular person enthalten. Der Algorithmus ist überraschend intestine und konnte mir durch die Zeit und um Haaresbreite folgen.
Ich habe mehr als 1.000 Bilder von mir heruntergeladen, die 20 Jahre zurückblicken, und beschloss, eine Animation zu erstellen, in der ich mich im Laufe der Jahre altern lasse. Wie üblich erwies sich diese geringfügige Variation der oben genannten Ausrichtungsaufgabe als mehr als nur geringfügig kompliziert.
Gesichtsbewusstsein
Der Vorgang zum Ausrichten meines Gesichts ähnelt dem vorherigen Vorgang:
- Suchen Sie auf den Bildern nach meinem Gesicht
- Wählen Sie Gesichtsschwerpunkte aus.
- Erstellen Sie 2D-Gauß-Masken um die Gesichtsschwerpunkte.
- Registrieren Sie die Gaußschen Masken und transformieren Sie dann das Originalbild.
Da es sich jedoch um Bilder „in freier Wildbahn“ handelte und nicht um Bilder, die ich explizit auf die gleiche Weise aufgenommen hatte, waren die ersten beiden Schritte aufwändiger.
Auffällig fehlt in torchvision Gibt es vorab trainierte Modelle zur Erkennung von Gesichtern oder Gesichts-Schlüsselpunkten (ich gehe davon aus, dass dies Absicht ist?). Stattdessen habe ich verwendet Facenet-Pytorch um alle Gesichter in jedem Bild zu erkennen. Jedes erkannte Gesicht erhält einen Begrenzungsrahmen und eine Reihe von Gesichts-„Landmarken“ (auch Schlüsselpunkte genannt), die beiden Augen, der Nase und beiden Lippenwinkeln entsprechen.

Mit diesem Device in meiner Toolbox sah mein Prozess dann so aus:
- Erkennen Sie alle Gesichter in allen Bildern.
- Markieren Sie auf jedem Bild mein Gesicht.
- Wählen Sie meine wichtigsten Gesichtspunkte aus.
- Werfen Sie Bilder weg, bei denen ich nicht nach vorne schaue.
Ich habe mein Gesicht im Bild ausgewählt, indem ich zunächst mithilfe der letzten Ebene eines vorab trainierten Modells Einbettungen für alle erkannten Gesichter in allen Bildern erstellt habe. Anschließend habe ich eine Einbettung erstellt, um mich selbst darzustellen, indem ich den Durchschnitt aller Einbettungen gebildet habe. Da ich in jedem Bild zu sehen bin, sollte ich den Durchschnitt „dominieren“. Dann schaue ich mir jedes Bild an und finde das eingebettete Gesicht, das meinem am nächsten kommt, und gehe davon aus, dass ich das bin.
Ich bestimme, ob ich nach vorne schaue, indem ich den Abstand zwischen meiner Nase und einem meiner Augen messe. Wenn ein Auge viel näher an meiner Nase ist als das andere, gehe ich davon aus, dass ich seitwärts schaue, und verwerfe das Bild. Ich überprüfe auch den Abstand zwischen meinen Lippenwinkeln und meiner Nase. Diese Heuristik schlägt fehl, wenn ich nach unten oder oben schaue.
Jetzt alle zusammen
Nachdem ich den oben beschriebenen Prozess befolgt habe, um die Schlüsselpunkte meines Gesichts aus jedem Bild zu extrahieren, kann ich die Bilder und Schlüsselpunkte dann in mein ursprüngliches Verfahren zur semantischen Bildregistrierung einspeisen und eine endgültige „Anpassung“ von zwei Jahrzehnten Ethans erhalten.