Im letzten Beitrag habe ich beschrieben, wie ich implizite Suggestions-Daten von der Web site gesammelt habe Skizzenfab. Ich habe dann behauptet, ich würde darüber schreiben, wie man mit diesen Daten tatsächlich ein Empfehlungssystem aufbaut. Nun, hier sind wir! Lasst uns bauen.
Ich denke, der beste Ausgangspunkt bei der Untersuchung impliziter Suggestions-Empfehlungen ist das Modell, das in dem klassischen Artikel „Kollaboratives Filtern für implizite Suggestions-Datensätze„“ von Koren et.al. (Warnung: PDF-Hyperlink). Ich habe in der Literatur und in Bibliotheken für maschinelles Lernen viele Namen für dieses Modell gesehen. Ich werde es Weighted Regularized Matrix Factorization (WRMF) nennen, ein Title, der ziemlich oft verwendet wird. WRMF ist wie der Klassiker der impliziten Matrixfaktorisierung. Es ist vielleicht nicht das angesagteste, aber es wird nie aus der Mode kommen. Und jedes Mal, wenn ich es verwende, weiß ich, dass mir das Ergebnis garantiert gefallen wird. Insbesondere ist dieses Modell intuitiv einigermaßen sinnvoll, es ist skalierbar und, was am wichtigsten ist, ich fand es leicht anzupassen. Es gibt viel weniger Hyperparameter als beispielsweise bei stochastischen Gradientenabstiegsmodellen.
Wenn Sie sich an meinen Beitrag erinnern, Explizite Suggestions-Matrix-Faktorisierunghatten wir eine Verlustfunktion (ohne Verzerrungen), die wie folgt aussah:
$$L_{exp} = sumlimits_{u,i in S}(r_{ui} – textbf{x}_{u}^{intercal} cdot{} textbf{y}_{i})^{2} + lambda_{x} sumlimits_{u} leftVert textbf{x}_{u} rightVert^{2} + lambda_{y} sumlimits_{u} leftVert textbf{y}_{i} rightVert^{2}$$
wobei $r_{ui}$ ein Component der Matrix der Benutzerelemente ist Bewertungen$textbf{x}_{u}$ ($textbf{y}_{i}$) sind die latenten Faktoren von Benutzer $u$ (Component $i$) und $S$ warfare die Menge aller Benutzer-Component-Bewertungen. WRMF ist einfach eine Modifikation dieser Verlustfunktion:
$$L_{WRMF} = sumlimits_{u,i}c_{ui} huge( p_{ui} – textbf{x}_{u}^{intercal} cdot{} textbf{y}_{i} huge) ^{2} + lambda_{x} sumlimits_{u} leftVert textbf{x}_{u} rightVert^{2} + lambda_{y} sumlimits_{u} leftVert textbf{y}_{i} rightVert^{2}$$
Hier summieren wir nicht über Elemente von $S$, sondern über unsere gesamte Matrix. Denken Sie daran, dass wir bei implizitem Suggestions keine Bewertungen mehr haben, sondern die Präferenzen der Benutzer für Elemente. In der WRMF-Verlustfunktion wurde die Bewertungsmatrix $r_{ui}$ durch eine Präferenzmatrix $p_{ui}$ ersetzt. Wir gehen davon aus, dass $p_{ui} = 1$ ist, wenn ein Benutzer überhaupt mit einem Component interagiert hat. Andernfalls ist $p_{ui} = 0$.
Der andere neue Time period in der Verlustfunktion ist $c_{ui}$. Wir nennen dies die Konfidenzmatrix und sie beschreibt grob, wie sicher wir sind, dass Benutzer $u$ tatsächlich die Präferenz $p_{ui}$ für Component $i$ hat. In dem Artikel ist eine der Konfidenzformeln, die die Autoren betrachten, linear in der Anzahl der Interaktionen. Wenn wir $d_{ui}$ als die Anzahl der Klicks eines Benutzers auf ein Component auf einer Web site annehmen, dann
$$c_{ui} = 1 + alpha d_{ui}$$
wobei $alpha$ ein durch Kreuzvalidierung ermittelter Hyperparameter ist. Im Fall der Sketchfab-Daten haben wir nur binäre „Likes“, additionally $d_{ui} in {0, 1}$
Um einen Schritt zurückzugehen: WRMF geht nicht davon aus, dass ein Benutzer, der nicht mit einem Artikel interagiert hat, nicht wie der Artikel. tut Nehmen wir an, dass der Benutzer eine destructive Präferenz gegenüber diesem Artikel hat, aber wir können über den Hyperparameter „Vertrauen“ wählen, wie sicher wir uns dieser Annahme sind.
Ich könnte jetzt die ganze Herleitung in blutigem Latex durchgehen, wie man diesen Algorithmus optimiert, wie in meinem vorherigen expliziten MF-Beitrag, aber andere Leute haben das schon viele Male getan. Hier ist ein großartiger StackOverflow Antwortoder, wenn Sie Ihre Ableitungen in Dirac-Notation mögen, dann schauen Sie sich Sudeep Das‘ Publish.
WRMF-Bibliotheken
Es gibt eine Reihe von Orten, an denen man Open-Supply-Code findet, der WRMF implementiert. Die beliebteste Methode zur Optimierung der Verlustfunktion ist die Methode der alternierenden kleinsten Quadrate. Diese Methode ist tendenziell weniger schwierig zu optimieren als der stochastische Gradientenabstieg, und das Modell ist peinlich parallel.
Der erste Code, den ich für diesen Algorithmus sah, stammte von Chris Johnsons repo. Dieser Code ist in Python, nutzt intestine dünn besetzte Matrizen und erledigt im Allgemeinen die Aufgabe. Thierry Bertin-Mahieux nahm dann diesen Code und parallelisiert es unter Verwendung der Python-Multiprocessing-Bibliothek. Dies sorgt für eine ordentliche Beschleunigung ohne Genauigkeitsverlust.
Die Leute bei Quora haben eine Bibliothek namens qmf das parallelisiert und in C++ geschrieben ist. Ich habe es nicht verwendet, aber es ist vermutlich schneller als die Multiprocessing-Python-Model. Schließlich schrieb Ben Frederickson parallelisierten Code in reinem Cython Hier. Dies übertrifft die anderen Python-Versionen in puncto Leistung um Längen und ist irgendwie Schneller als qmf (was seltsam erscheint).
Wie dem auch sei, ich habe für diesen Beitrag letztendlich Bens Bibliothek verwendet, weil (1) ich bei Python bleiben konnte und (2) es superschnell ist. Ich habe die Bibliothek geforkt und eine kleine Klasse geschrieben, um den Algorithmus zu umschließen, damit es einfach ist, Rastersuchen auszuführen und Lernkurven zu berechnen. Sie können sich gerne meinen Fork ansehen. Hierallerdings habe ich keine Assessments geschrieben, additionally verwenden Sie sie auf eigene Gefahr 🙂
Die Daten bearbeiten
Nachdem das nun erledigt ist, trainieren wir ein WRMF-Modell, damit wir endlich einige Sketchfab-Modelle empfehlen können!
Der erste Schritt besteht darin, die Daten zu laden und sie in eine Interaktionsmatrix der Größe „Anzahl der Benutzer“ mal „Anzahl der Elemente“ umzuwandeln. Die Daten werden derzeit als CSV-Datei gespeichert, wobei jede Zeile ein Modell bezeichnet, das einem Benutzer auf der Sketchfab-Web site „gefällt“. Die erste Spalte ist der Title des Modells, die zweite Spalte ist die eindeutige Modell-ID (mid) und die dritte Spalte ist die anonymisierte Benutzer-ID (uid).
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import scipy.sparse as sparse
import pickle
import csv
import implicit
import itertools
import copy
plt.fashion.use('ggplot')
df = pd.read_csv('../information/model_likes_anon.psv',
sep='|', quoting=csv.QUOTE_MINIMAL,
quotechar='')
df.head()
| Modellname | Mitte | Benutzerkennung | |
|---|---|---|---|
| 0 | 3D-Fanart Noel aus Sora no Methodology | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 | 7ac1b40648fff523d7220a5d07b04d9b |
| 1 | 3D-Fanart Noel aus Sora no Methodology | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 | 2b4ad286afe3369d39f1bb7aa2528bc7 |
| 2 | 3D-Fanart Noel aus Sora no Methodology | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 | 1bf0993ebab175a896ac8003bed91b4b |
| 3 | 3D-Fanart Noel aus Sora no Methodology | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 | 6484211de8b9a023a7d9ab1641d22e7c |
| 4 | 3D-Fanart Noel aus Sora no Methodology | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 | 1109ee298494fbd192e27878432c718a |
print('Duplicated rows: ' + str(df.duplicated().sum()))
print('That's bizarre - let's simply drop them')
df.drop_duplicates(inplace=True)
Duplicated rows 155
That is bizarre - let's simply drop them
df = df(('uid', 'mid'))
df.head()
| Benutzerkennung | Mitte | |
|---|---|---|
| 0 | 7ac1b40648fff523d7220a5d07b04d9b | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 |
| 1 | 2b4ad286afe3369d39f1bb7aa2528bc7 | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 |
| 2 | 1bf0993ebab175a896ac8003bed91b4b | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 |
| 3 | 6484211de8b9a023a7d9ab1641d22e7c | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 |
| 4 | 1109ee298494fbd192e27878432c718a | 5dcebcfaedbd4e7b8a27bd1ae55f1ac3 |
n_users = df.uid.distinctive().form(0)
n_items = df.mid.distinctive().form(0)
print('Variety of customers: {}'.format(n_users))
print('Variety of fashions: {}'.format(n_items))
print('Sparsity: {:4.3f}%'.format(float(df.form(0)) / float(n_users*n_items) * 100))
Variety of customers: 62583
Variety of fashions: 28806
Sparsity: 0.035%
Obwohl implizite Empfehlungen bei spärlichen Daten intestine funktionieren, kann es oft hilfreich sein, die Interaktionsmatrix etwas dichter zu gestalten. Wir haben unsere Datensammlung auf Modelle beschränkt, die mindestens 5 Likes hatten. Es ist jedoch nicht unbedingt der Fall, dass jeder Benutzer mindestens 5 Modelle geliked hat. Lassen Sie uns nun Benutzer ausschließen, denen weniger als 5 Modelle gefallen haben. Dies könnte möglicherweise bedeuten, dass einige Modelle weniger als 5 Likes haben, nachdem diese Benutzer ausgeschlossen wurden. Wir müssen additionally abwechselnd Benutzer und Modelle ausschließen, bis sich die Lage stabilisiert hat.
def threshold_likes(df, uid_min, mid_min):
n_users = df.uid.distinctive().form(0)
n_items = df.mid.distinctive().form(0)
sparsity = float(df.form(0)) / float(n_users*n_items) * 100
print('Beginning likes data')
print('Variety of customers: {}'.format(n_users))
print('Variety of fashions: {}'.format(n_items))
print('Sparsity: {:4.3f}%'.format(sparsity))
finished = False
whereas not finished:
starting_shape = df.form(0)
mid_counts = df.groupby('uid').mid.depend()
df = df(~df.uid.isin(mid_counts(mid_counts < mid_min).index.tolist()))
uid_counts = df.groupby('mid').uid.depend()
df = df(~df.mid.isin(uid_counts(uid_counts < uid_min).index.tolist()))
ending_shape = df.form(0)
if starting_shape == ending_shape:
finished = True
assert(df.groupby('uid').mid.depend().min() >= mid_min)
assert(df.groupby('mid').uid.depend().min() >= uid_min)
n_users = df.uid.distinctive().form(0)
n_items = df.mid.distinctive().form(0)
sparsity = float(df.form(0)) / float(n_users*n_items) * 100
print('Ending likes data')
print('Variety of customers: {}'.format(n_users))
print('Variety of fashions: {}'.format(n_items))
print('Sparsity: {:4.3f}%'.format(sparsity))
return df
df_lim = threshold_likes(df, 5, 5)
Beginning likes data
Variety of customers: 62583
Variety of fashions: 28806
Sparsity: 0.035%
Ending likes data
Variety of customers: 15274
Variety of fashions: 25655
Sparsity: 0.140%
Intestine, wir sind über 0,1%, was für anständige Empfehlungen ausreichen sollte. Wir müssen jetzt jeden uid Und mid in eine Zeile bzw. Spalte für unsere Interaktionen oder „Likes“-Matrix. Dies kann einfach mit Python-Wörterbüchern erfolgen
# Create mappings
mid_to_idx = {}
idx_to_mid = {}
for (idx, mid) in enumerate(df_lim.mid.distinctive().tolist()):
mid_to_idx(mid) = idx
idx_to_mid(idx) = mid
uid_to_idx = {}
idx_to_uid = {}
for (idx, uid) in enumerate(df_lim.uid.distinctive().tolist()):
uid_to_idx(uid) = idx
idx_to_uid(idx) = uid
Der letzte Schritt besteht darin, die Matrix tatsächlich zu erstellen. Wir werden dünn besetzte Matrizen verwenden, um nicht zu viel Speicher zu beanspruchen. Dünne Matrizen sind schwierig, da sie in vielen Formen vorkommen und zwischen ihnen große Leistungseinbußen bestehen. Unten finden Sie eine sehr langsame Möglichkeit, eine Likes-Matrix zu erstellen. Ich habe versucht, Folgendes auszuführen: %%timeit aber es hat mir langweilig gemacht, als ich darauf gewartet habe, dass es zu Ende geht.
# # Do not do that!
# num_users = df_lim.uid.distinctive().form(0)
# num_items = df_lim.mid.distinctive().form(0)
# likes = sparse.csr_matrix((num_users, num_items), dtype=np.float64)
# for row in df_lim.itertuples():
# likes(uid_to_idx(uid), mid_to_idx(row.mid)) = 1.0
Alternativ ist das Folgende verdammt schnell, wenn man bedenkt, dass wir eine Matrix mit einer halben Million Likes erstellen.
def map_ids(row, mapper):
return mapper(row)
%%timeit
I = df_lim.uid.apply(map_ids, args=(uid_to_idx)).as_matrix()
J = df_lim.mid.apply(map_ids, args=(mid_to_idx)).as_matrix()
V = np.ones(I.form(0))
likes = sparse.coo_matrix((V, (I, J)), dtype=np.float64)
likes = likes.tocsr()
1 loop, greatest of three: 876 ms per loop
I = df_lim.uid.apply(map_ids, args=(uid_to_idx)).as_matrix()
J = df_lim.mid.apply(map_ids, args=(mid_to_idx)).as_matrix()
V = np.ones(I.form(0))
likes = sparse.coo_matrix((V, (I, J)), dtype=np.float64)
likes = likes.tocsr()
Kreuzvalidierung: Splitsville
Okay, wir haben eine Likes-Matrix und müssen sie in Trainings- und Testmatrizen aufteilen. Ich mache das ein bisschen trickreich (was ist vielleicht ein Wort?). Ich möchte später precision@okay als meine Optimierungsmetrik verfolgen. Ein okay von 5 wäre schön. Wenn ich jedoch für einige der Benutzer 5 Elemente vom Coaching zum Check verschiebe, haben sie möglicherweise keine Daten mehr im Trainingssatz (denken Sie daran, dass sie mindestens 5 Likes hatten). Daher sucht train_test_split nur nach Personen, die mindestens 2*okay (in diesem Fall 10) Likes haben, bevor einige ihrer Daten in den Testsatz verschoben werden. Dies verzerrt unsere Kreuzvalidierung offensichtlich in Richtung Benutzer mit mehr Likes. So geht das.
def train_test_split(rankings, split_count, fraction=None):
"""
Break up suggestion information into practice and take a look at units
Params
------
rankings : scipy.sparse matrix
Interactions between customers and gadgets.
split_count : int
Variety of user-item-interactions per consumer to maneuver
from coaching to check set.
fractions : float
Fraction of customers to separate off a few of their
interactions into take a look at set. If None, then all
customers are thought-about.
"""
# Observe: possible not the quickest approach to do issues beneath.
practice = rankings.copy().tocoo()
take a look at = sparse.lil_matrix(practice.form)
if fraction:
attempt:
user_index = np.random.selection(
np.the place(np.bincount(practice.row) >= split_count * 2)(0),
exchange=False,
measurement=np.int32(np.flooring(fraction * practice.form(0)))
).tolist()
besides:
print(('Not sufficient customers with > {} '
'interactions for fraction of {}')
.format(2*okay, fraction))
increase
else:
user_index = vary(practice.form(0))
practice = practice.tolil()
for consumer in user_index:
test_ratings = np.random.selection(rankings.getrow(consumer).indices,
measurement=split_count,
exchange=False)
practice(consumer, test_ratings) = 0.
# These are simply 1.0 proper now
take a look at(consumer, test_ratings) = rankings(consumer, test_ratings)
# Check and coaching are actually disjoint
assert(practice.multiply(take a look at).nnz == 0)
return practice.tocsr(), take a look at.tocsr(), user_index
practice, take a look at, user_index = train_test_split(likes, 5, fraction=0.2)
Kreuzvalidierung: Rastersuche
Nachdem die Daten nun in Trainings- und Testmatrizen aufgeteilt sind, führen wir eine riesige Rastersuche durch, um unsere Hyperparameter zu optimieren. Wir haben vier Parameter, die wir optimieren möchten:
num_factors: Die Anzahl der latenten Faktoren oder der Grad der Dimensionalität in unserem Modell.regularization: Maßstab der Regularisierung für Benutzer- und Artikelfaktoren.alpha: Unser Begriff zur Skalierung des Vertrauens.iterations: Anzahl der Iterationen zum Ausführen der Alternating Least Squares-Optimierung.
Ich werde den mittleren quadratischen Fehler (MSE) und die Präzision bei okay (p@okay) verfolgen, aber mir geht es hauptsächlich um Letzteres. Ich habe unten einige Funktionen geschrieben, die bei der Berechnung der Metriken helfen und dafür sorgen, dass der Ausdruck des Trainingsprotokolls intestine aussieht. Ich werde eine Reihe von Lernkurven berechnen (d. h. Leistungsmetriken in verschiedenen Phasen des Trainingsprozesses auswerten) für eine Reihe verschiedener Hyperparameterkombinationen. Ein Lob an scikit-learn dafür, dass es Open Supply ist und ich im Grunde ihren GridSearchCV-Code abschreiben durfte.
from sklearn.metrics import mean_squared_error
def calculate_mse(mannequin, rankings, user_index=None):
preds = mannequin.predict_for_customers()
if user_index:
return mean_squared_error(rankings(user_index, :).toarray().ravel(),
preds(user_index, :).ravel())
return mean_squared_error(rankings.toarray().ravel(),
preds.ravel())
def precision_at_k(mannequin, rankings, okay=5, user_index=None):
if not user_index:
user_index = vary(rankings.form(0))
rankings = rankings.tocsr()
precisions = ()
# Observe: line beneath might develop into infeasible for giant datasets.
predictions = mannequin.predict_for_customers()
for consumer in user_index:
# In case of enormous dataset, compute predictions row-by-row like beneath
# predictions = np.array((mannequin.predict(row, i) for i in xrange(rankings.form(1))))
top_k = np.argsort(-predictions(consumer, :))(:okay)
labels = rankings.getrow(consumer).indices
precision = float(len(set(top_k) & set(labels))) / float(okay)
precisions.append(precision)
return np.imply(precisions)
def print_log(row, header=False, spacing=12):
high = ''
center = ''
backside = ''
for r in row:
high += '+{}'.format('-'*spacing)
if isinstance(r, str):
center += '| {0:^{1}} '.format(r, spacing-2)
elif isinstance(r, int):
center += '| {0:^{1}} '.format(r, spacing-2)
elif isinstance(r, float):
center += '| {0:^{1}.5f} '.format(r, spacing-2)
backside += '+{}'.format('='*spacing)
high += '+'
center += '|'
backside += '+'
if header:
print(high)
print(center)
print(backside)
else:
print(center)
print(high)
def learning_curve(mannequin, practice, take a look at, epochs, okay=5, user_index=None):
if not user_index:
user_index = vary(practice.form(0))
prev_epoch = 0
train_precision = ()
train_mse = ()
test_precision = ()
test_mse = ()
headers = ('epochs', 'p@okay practice', 'p@okay take a look at',
'mse practice', 'mse take a look at')
print_log(headers, header=True)
for epoch in epochs:
mannequin.iterations = epoch - prev_epoch
if not hasattr(mannequin, 'user_vectors'):
mannequin.match(practice)
else:
mannequin.fit_partial(practice)
train_mse.append(calculate_mse(mannequin, practice, user_index))
train_precision.append(precision_at_k(mannequin, practice, okay, user_index))
test_mse.append(calculate_mse(mannequin, take a look at, user_index))
test_precision.append(precision_at_k(mannequin, take a look at, okay, user_index))
row = (epoch, train_precision(-1), test_precision(-1),
train_mse(-1), test_mse(-1))
print_log(row)
prev_epoch = epoch
return mannequin, train_precision, train_mse, test_precision, test_mse
def grid_search_learning_curve(base_model, practice, take a look at, param_grid,
user_index=None, patk=5, epochs=vary(2, 40, 2)):
"""
"Impressed" (stolen) from sklearn gridsearch
https://github.com/scikit-learn/scikit-learn/blob/grasp/sklearn/model_selection/_search.py
"""
curves = ()
keys, values = zip(*param_grid.gadgets())
for v in itertools.product(*values):
params = dict(zip(keys, v))
this_model = copy.deepcopy(base_model)
print_line = ()
for okay, v in params.gadgets():
setattr(this_model, okay, v)
print_line.append((okay, v))
print(' | '.be a part of('{}: {}'.format(okay, v) for (okay, v) in print_line))
_, train_patk, train_mse, test_patk, test_mse = learning_curve(this_model, practice, take a look at,
epochs, okay=patk, user_index=user_index)
curves.append({'params': params,
'patk': {'practice': train_patk, 'take a look at': test_patk},
'mse': {'practice': train_mse, 'take a look at': test_mse}})
return curves
Bitte beachten Sie, dass das folgende Parameterraster verdammt groß ist und auf meinem 6 Jahre alten 4-Core i5 etwa 2 Tage zum Ausführen benötigte. Es stellte sich heraus, dass die Funktionen für die Leistungsmetriken tatsächlich ein gutes Stück langsamer sind als der Trainingsprozess. Diese Funktionen könnten einfach parallelisiert werden – etwas, das ich zu einem späteren Zeitpunkt tun werde.
param_grid = {'num_factors': (10, 20, 40, 80, 120),
'regularization': (0.0, 1e-5, 1e-3, 1e-1, 1e1, 1e2),
'alpha': (1, 10, 50, 100, 500, 1000)}
base_model = implicit.ALS()
curves = grid_search_learning_curve(base_model, practice, take a look at,
param_grid,
user_index=user_index,
patk=5)
Das Trainingsprotokoll ist unglaublich lang, aber klicken Sie einfach Hier und probier es aus. Ansonsten hier der Ausdruck des besten Laufs:
alpha: 50 | num_factors: 40 | regularization: 0.1
+------------+------------+------------+------------+------------+
| epochs | p@okay practice | p@okay take a look at | mse practice | mse take a look at |
+============+============+============+============+============+
| 2 | 0.33988 | 0.02541 | 0.01333 | 0.01403 |
+------------+------------+------------+------------+------------+
| 4 | 0.31395 | 0.03916 | 0.01296 | 0.01377 |
+------------+------------+------------+------------+------------+
| 6 | 0.30085 | 0.04231 | 0.01288 | 0.01372 |
+------------+------------+------------+------------+------------+
| 8 | 0.29175 | 0.04231 | 0.01285 | 0.01370 |
+------------+------------+------------+------------+------------+
| 10 | 0.28638 | 0.04407 | 0.01284 | 0.01370 |
+------------+------------+------------+------------+------------+
| 12 | 0.28684 | 0.04492 | 0.01284 | 0.01371 |
+------------+------------+------------+------------+------------+
| 14 | 0.28533 | 0.04571 | 0.01285 | 0.01371 |
+------------+------------+------------+------------+------------+
| 16 | 0.28389 | 0.04689 | 0.01285 | 0.01372 |
+------------+------------+------------+------------+------------+
| 18 | 0.28454 | 0.04695 | 0.01286 | 0.01373 |
+------------+------------+------------+------------+------------+
| 20 | 0.28454 | 0.04728 | 0.01287 | 0.01374 |
+------------+------------+------------+------------+------------+
| 22 | 0.28409 | 0.04761 | 0.01288 | 0.01376 |
+------------+------------+------------+------------+------------+
| 24 | 0.28251 | 0.04689 | 0.01289 | 0.01377 |
+------------+------------+------------+------------+------------+
| 26 | 0.28186 | 0.04656 | 0.01290 | 0.01378 |
+------------+------------+------------+------------+------------+
| 28 | 0.28199 | 0.04676 | 0.01291 | 0.01379 |
+------------+------------+------------+------------+------------+
| 30 | 0.28127 | 0.04669 | 0.01292 | 0.01380 |
+------------+------------+------------+------------+------------+
| 32 | 0.28173 | 0.04650 | 0.01292 | 0.01381 |
+------------+------------+------------+------------+------------+
| 34 | 0.28153 | 0.04650 | 0.01293 | 0.01382 |
+------------+------------+------------+------------+------------+
| 36 | 0.28166 | 0.04604 | 0.01294 | 0.01382 |
+------------+------------+------------+------------+------------+
| 38 | 0.28153 | 0.04637 | 0.01295 | 0.01383 |
+------------+------------+------------+------------+------------+
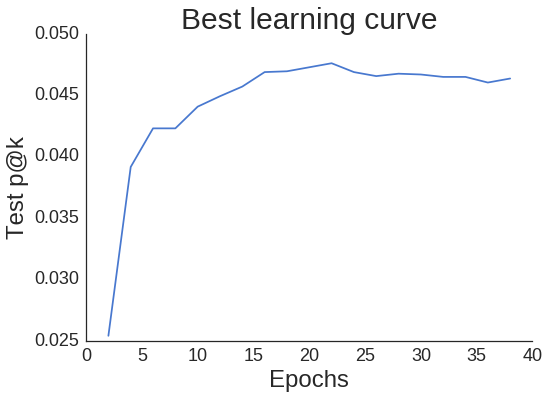
Mal sehen, wie die Lernkurve für unseren besten Lauf aussieht.
best_curves = sorted(curves, key=lambda x: max(x('patk')('take a look at')), reverse=True)
print(best_curves(0)('params'))
max_score = max(best_curves(0)('patk')('take a look at'))
print(max_score)
iterations = vary(2, 40, 2)(best_curves(0)('patk')('take a look at').index(max_score))
print('Epoch: {}'.format(iterations))
{'alpha': 50, 'num_factors': 40, 'regularization': 0.1}
0.0476096922069
Epoch: 22
import seaborn as sns
sns.set_style('white')
fig, ax = plt.subplots()
sns.despine(fig);
plt.plot(epochs, best_curves(0)('patk')('take a look at'));
plt.xlabel('Epochs', fontsize=24);
plt.ylabel('Check p@okay', fontsize=24);
plt.xticks(fontsize=18);
plt.yticks(fontsize=18);
plt.title('Greatest studying curve', fontsize=30);
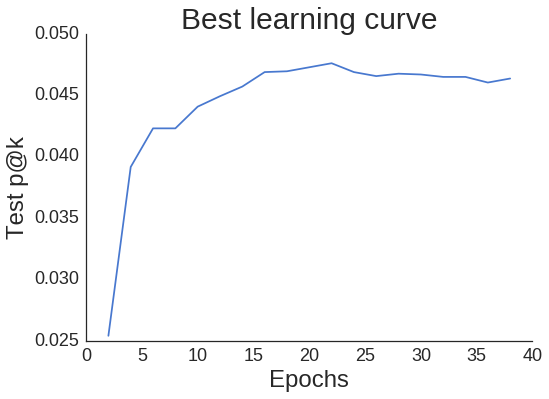
Obwohl die Kurve ein wenig gezackt ist, nimmt sie nicht zu stark ab, wenn wir unsere beste Epoche von 22 hinter uns lassen. Das bedeutet, dass wir bei der Implementierung eines frühzeitigen Stopps nicht übermäßig vorsichtig sein müssen (wenn wir p@okay als die einzige für uns relevante Kennzahl betrachten).
Wir können alle unsere Lernkurven darstellen und sehen, dass Unterschiede in den Hyperparametern definitiv einen Unterschied in der Leistung bewirken.
all_test_patks = (x('patk')('take a look at') for x in best_curves)
fig, ax = plt.subplots(figsize=(8, 10));
sns.despine(fig);
epochs = vary(2, 40, 2)
totes = len(all_test_patks)
for i, test_patk in enumerate(all_test_patks):
ax.plot(epochs, test_patk,
alpha=1/(.1*i+1),
c=sns.color_palette()(0));
plt.xlabel('Epochs', fontsize=24);
plt.ylabel('Check p@okay', fontsize=24);
plt.xticks(fontsize=18);
plt.yticks(fontsize=18);
plt.title('Grid-search p@okay traces', fontsize=30);
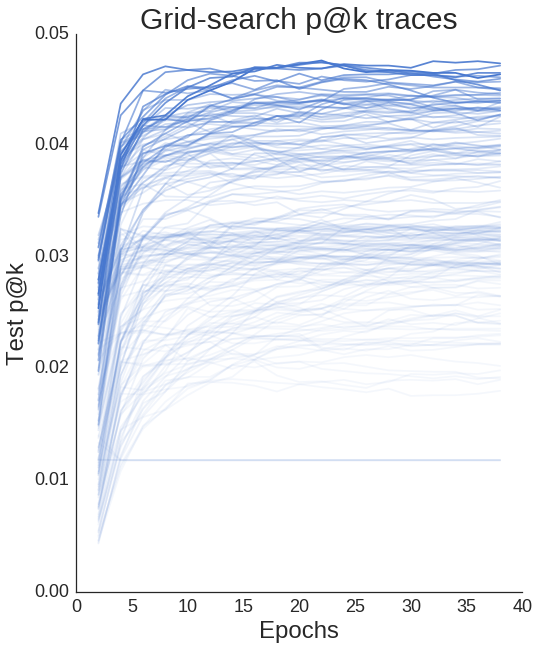
Erstellen Sie eine Skizze
Nach all dem haben wir endlich einige optimale Hyperparameter. Wir könnten jetzt eine feinere Rastersuche durchführen oder uns ansehen, wie sich das Variieren des Verhältnisses zwischen Benutzer- und Elementregularisierungseffekten auswirkt, aber ich habe keine Lust, noch zwei Tage zu warten…
Wir trainieren nun ein WRMF-Modell auf alle unserer Daten mit den optimalen Hyperparametern und visualisieren einige Artikel-zu-Artikel-Empfehlungen. Benutzer-zu-Artikel-Empfehlungen sind etwas schwieriger zu visualisieren und ein Gefühl dafür zu bekommen, wie genau sie sein können.
params = best_curves(0)('params')
params('iterations') = vary(2, 40, 2)(best_curves(0)('patk')('take a look at').index(max_score))
bestALS = implicit.ALS(**params)
Um Artikel-zu-Artikel-Empfehlungen zu erhalten, habe ich eine kleine Methode entwickelt predict_for_items im ALS Klasse. Dies ist im Wesentlichen nur ein Skalarprodukt zwischen allen Kombinationen von Elementvektoren. Wenn Sie norm=True (Normal), dann wird dieses Skalarprodukt durch die Norm jedes Elementvektors normalisiert, was zur Kosinusähnlichkeit führt. Dies sagt uns, wie ähnlich sich zwei Elemente im eingebetteten oder latenten Raum sind.
def predict_for_items(self, norm=True):
"""Suggest merchandise for all merchandise"""
pred = self.item_vectors.dot(self.item_vectors.T)
if norm:
norms = np.array((np.sqrt(np.diagonal(pred))))
pred = pred / norms / norms.T
return pred
item_similarities = bestALS.predict_for_items()
Lassen Sie uns nun einige der Modelle und die zugehörigen Empfehlungen visualisieren, um ein Gefühl dafür zu bekommen, wie intestine unser Empfehlungssystem funktioniert. Wir können einfach die Sketchfab-API abfragen, um die Miniaturansichten der Modelle abzurufen. Unten finden Sie eine Hilfsfunktion, die die Elementähnlichkeiten, einen Index und den Index-zu- verwendet.mid Mapper, um eine Liste der Miniaturansicht-URLs der Empfehlungen zurückzugeben. Beachten Sie, dass die erste Empfehlung immer das Modell selbst ist, da es eine Kosinusähnlichkeit von 1 mit sich selbst aufweist.
import requests
def get_thumbnails(sim, idx, idx_to_mid, N=10):
row = sim(idx, :)
thumbs = ()
for x in np.argsort(-row)(:N):
response = requests.get('https://sketchfab.com/i/fashions/{}'.format(idx_to_mid(x))).json()
thumb = (x('url') for x in response('thumbnails')('pictures') if x('width') == 200 and x('peak')==200)
if not thumb:
print('no thumbnail')
else:
thumb = thumb(0)
thumbs.append(thumb)
return thumbs
thumbs = get_thumbnails(item_similarities, 0, idx_to_mid)
https://dg5bepmjyhz9h.cloudfront.internet/urls/5dcebcfaedbd4e7b8a27bd1ae55f1ac3/dist/thumbnails/a59f9de0148e4986a181483f47826fe0/200x200.jpeg
Wir können die Bilder jetzt mit etwas HTML und Core anzeigen IPython Funktionen.
from IPython.show import show, HTML
def display_thumbs(thumbs, N=5):
thumb_html = "<img fashion='width: 160px; margin: 0px;
border: 1px strong black;' src='{}' />"
pictures = ''
show(HTML('<font measurement=5>'+'Enter Mannequin'+'</font>'))
show(HTML(thumb_html.format(thumbs(0))))
show(HTML('<font measurement=5>'+'Related Fashions'+'</font>'))
for url in thumbs(1:N+1):
pictures += thumb_html.format(url)
show(HTML(pictures))
Auch wenn die Empfehlungen möglicherweise nicht perfekt sind (siehe Polizeiauto + grünes Monster oben), ist es offensichtlich, dass unser Empfehlungsmodell Ähnlichkeiten gelernt hat.
Machen Sie einen Schritt zurück und denken Sie einen Second darüber nach:
Unser Algorithmus weiß nichts darüber, wie diese Fashions aussehen, welche Tags sie möglicherweise haben oder irgendetwas über die Künstler. Der Algorithmus weiß lediglich, welche Benutzer welche Fashions geliked haben. Ziemlich gruselig, oder?
Was kommt als nächstes?
Heute haben wir die gewichtete, regulierte Matrixfaktorisierung gelernt, den Klassiker der impliziten MF. Das nächste Mal lernen wir eine andere Methode zur Optimierung impliziter Suggestions-Modelle kennen, die „Studying to Rank“ heißt. Mit „Studying to Rank“-Modellen können wir zusätzliche Informationen über die Modelle und Benutzer einbeziehen, z. B. die den Modellen zugewiesenen Kategorien und Tags. Danach werden wir sehen, wie sich eine unüberwachte Empfehlung mit Bildern und vorab trainierten neuronalen Netzwerken im Vergleich zu diesen Methoden schlägt, und schließlich werden wir eine Flask-App erstellen, um diese Empfehlungen einem Endbenutzer bereitzustellen.
Bleiben Sie dran!