
In diesem Python-Tutorial gehen wir auf Net-Scraping mit Scrapy ein – und arbeiten ein Beispiel-Scraping-Projekt für E-Commerce-Web sites durch.
Bis 2025 wird das Web auf mehr als wachsen 175 Zetabyte von Dateien. Leider ist ein Großteil davon unstrukturiert und nicht maschinenlesbar. Das bedeutet, dass Sie über Web sites und technisch gesehen in Type von HTML-Seiten auf die Daten zugreifen können. Gibt es eine einfachere Möglichkeit, nicht nur auf diese Webdaten zuzugreifen, sondern sie auch in einem strukturierten Format herunterzuladen, damit sie maschinenlesbar und für die Gewinnung von Erkenntnissen bereit sind?
Hier kommt Net Scraping und Scrapy kann dir helfen! Beim Net Scraping werden strukturierte Daten aus Web sites extrahiert. Scrapy ist eines der beliebtesten Net-Scraping-Frameworks und eine gute Wahl, wenn Sie lernen möchten, wie man Daten aus dem Net scrapt. In diesem Tutorial erfahren Sie, wie Sie mit Scrapy beginnen und implementieren außerdem ein Beispielprojekt zum Scrapen einer E-Commerce-Web site.
Lass uns anfangen!
Voraussetzungen
Um dieses Tutorial abzuschließen, benötigen Sie Folgendes Python installiert auf Ihrem System und es wird empfohlen, über Grundkenntnisse in der Programmierung in Python zu verfügen.
Scrapy installieren
Um Scrapy nutzen zu können, müssen Sie es installieren. Glücklicherweise gibt es eine sehr einfache Möglichkeit, dies über Pip zu tun. Sie können verwenden pip set up scrapy um Scrapy zu installieren. Weitere Installationsmöglichkeiten finden Sie auch im Scrapy-Dokumente. Es wird empfohlen, Scrapy in einer virtuellen Python-Umgebung zu installieren.
virtualenv env
supply env/bin/activate
pip set up scrapyDieses Snippet erstellt eine neue virtuelle Python-Umgebung, aktiviert sie und installiert Scrapy.
Scrapy-Projektstruktur
Wenn Sie ein neues Scrapy-Projekt erstellen, müssen Sie eine bestimmte Dateistruktur verwenden, um sicherzustellen, dass Scrapy weiß, wo es nach den einzelnen Modulen suchen muss. Glücklicherweise verfügt Scrapy über einen praktischen Befehl, der Ihnen dabei helfen kann, ein leeres Scrapy-Projekt mit allen Modulen von Scrapy zu erstellen:
scrapy startproject bookscraperWenn Sie diesen Befehl ausführen, wird – basierend auf einer Vorlage – ein neues Scrapy-Projekt erstellt, das wie folgt aussieht:
📦bookscraper
┣ 📂bookscraper
┃ ┣ 📂spiders
┃ ┃ ┗ 📜bookscraper.py
┃ ┣ 📜gadgets.py
┃ ┣ 📜middlewares.py
┃ ┣ 📜pipelines.py
┃ ┗ 📜settings.py
┗ 📜scrapy.cfgDies ist eine typische Scrapy-Projektdateistruktur. Lassen Sie uns diese Dateien und Ordner kurz auf einer allgemeinen Ebene untersuchen, damit Sie verstehen, was die einzelnen Elemente bewirken:
spidersOrdner: Dieser Ordner enthält alle unsere zukünftigen Scrapy-Spider-Dateien, die die Daten extrahieren.gadgets: Diese Datei enthält Elementobjekte, die sich wie Python-Wörterbücher verhalten und eine Abstraktionsebene zum Speichern von Scraping-Daten innerhalb des Scrapy-Frameworks bereitstellen.middlewares(Fortgeschritten): Scrapy-Middleware ist nützlich, wenn Sie die Artwork und Weise ändern möchten, wie Scrapy ausgeführt wird und Anfragen an den Server stellt (z. B. um Antibot-Lösungen zu umgehen). Für einfache Scraping-Projekte müssen Sie die Middleware nicht ändern.pipelines: Scrapy-Pipelines dienen für zusätzliche Datenverarbeitungsschritte, die Sie nach dem Extrahieren von Daten implementieren möchten. Sie können Daten in diesen Pipelines bereinigen, organisieren oder sogar löschen.settings: Allgemeine Einstellungen für die Ausführung von Scrapy, z. B. Verzögerungen zwischen Anfragen, Caching, Datei-Obtain-Einstellungen usw.
In diesem Tutorial konzentrieren wir uns auf zwei Scrapy-Module: Spinnen und Gegenstände. Mit diesen beiden Modulen können Sie einfache und effektive Net-Scraper implementieren, die Daten von jeder Web site extrahieren können.
Nachdem Sie Scrapy erfolgreich installiert und ein neues Scrapy-Projekt erstellt haben, lernen wir, wie Sie einen Scrapy-Spider (auch Scraper genannt) schreiben, der Produktdaten aus einem E-Commerce-Store extrahiert.
Scraping-Logik
Als Beispiel verwendet dieses Tutorial eine Web site, die speziell zum Üben von Net Scraping erstellt wurde: Bücher zum Kratzen. Bevor Sie den Spider programmieren, ist es wichtig, einen Blick auf die Web site zu werfen und den Weg zu analysieren, den der Spider einschlagen muss, um auf die Daten zuzugreifen und sie zu extrahieren.
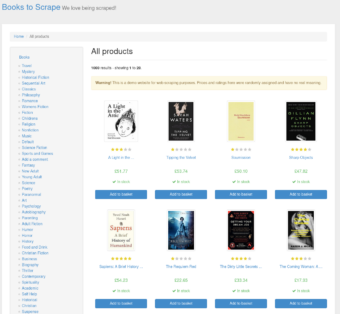
Wir werden diese Web site nutzen, um alle verfügbaren Bücher zu durchsuchen. Wie Sie auf der Web site sehen können, gibt es auf jeder Kategorieseite mehrere Kategorien von Büchern und mehrere Artikel. Das bedeutet, dass unser Scraper zu jeder Kategorieseite gehen und jede Buchseite öffnen muss.
Lassen Sie uns aufschlüsseln, was der Scraper auf der Web site tun muss:
- Öffnen Sie die Web site (http://books.toscrape.com/).
- Finden Sie alle Kategorie-URLs (wie Dieses hier).
- Finden Sie alle Buch-URLs auf den Kategorieseiten (wie Dieses hier).
- Öffnen Sie jede URL einzeln und extrahieren Sie Buchdaten.
In Scrapy müssen wir Scraped-Daten speichern Merchandise Klassen. In unserem Fall verfügt ein Artikel über Felder wie Titel, Hyperlink und Posting-Zeitpunkt. Lassen Sie uns den Artikel umsetzen!
Scrapy-Artikel
Erstellen Sie ein neues Scrapy-Factor, das die Scraping-Daten speichert. Nennen wir diesen Artikel BookItem und fügen Sie die Datenfelder hinzu, die jedes Buch darstellen:
- Titel
- Preis
- upc
- Bild URL
- URL
So erstellen Sie im Code eine neue Merchandise-Klasse in Scrapy:
from scrapy import Merchandise, Subject
class BookItem(Merchandise):
title = Subject()
value = Subject()
upc = Subject()
image_url = Subject()
url = Subject()Wie Sie im Codeausschnitt sehen können, müssen Sie zwei Scrapy-Objekte importieren: Merchandise Und Subject.
Merchandise wird als übergeordnete Klasse für verwendet BookItem Daher weiß Scrapy, dass dieses Objekt im gesamten Projekt zum Speichern und Referenzieren der gescrapten Datenfelder verwendet wird.
Subject ist ein Objekt, das als Teil einer Merchandise-Klasse gespeichert wird, um die Datenfelder innerhalb des Artikels anzugeben.
Sobald Sie das erstellt haben BookItem In der Klasse können Sie weitermachen und an der Scrapy-Spinne arbeiten, die die Scraping-Logik und Extraktion übernimmt.
Kratzende Spinne
Erstellen Sie eine neue Python-Datei im spiders Ordner namens bookscraper.py
contact bookscraper.pyDiese Spider-Datei enthält die Spider-Logik und den Scraping-Code. Um festzustellen, was in dieser Datei enthalten sein muss, schauen wir uns die Web site an!
Web site-Inspektion
Die Web site-Inspektion ist ein mühsamer, aber wichtiger Schritt im Net-Scraping-Prozess. Ohne eine ordnungsgemäße Inspektion wissen Sie nicht, wie Sie die Daten auf den Web sites effizient finden und extrahieren können. Die Inspektion erfolgt normalerweise mit dem „Examine“-Device Ihres Browsers oder einem Browser-Plugin eines Drittanbieters, mit dem Sie „unter die Haube schauen“ und den Quellcode einer Web site analysieren können. Es wird empfohlen, während der Analyse der Web site die JS-Ausführung in Ihrem Browser zu deaktivieren – so können Sie dies tun sehen die Web site auf die gleiche Weise wie Ihre Scrapy-Spinne sehen Es.
Fassen wir noch einmal zusammen, welche URLs und Datenfelder wir im Quellcode der Web site finden müssen:
- Kategorie-URLs
- Buch-URLs
- Schließlich buchen Sie Datenfelder
Überprüfen Sie den Quellcode, um Kategorie-URLs im HTML zu finden:
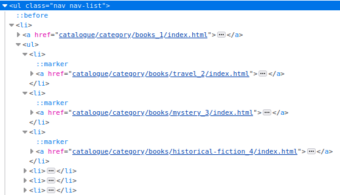
Wenn Sie sich die Web site ansehen, können Sie feststellen, dass Kategorie-URLs in einem gespeichert sind ul HTML-Factor mit einer Klasse nav nav-list. Dies sind wichtige Informationen, da Sie dieses CSS und die umgebenden HTML-Elemente verwenden können, um alle Kategorie-URLs auf der Seite zu finden – genau das, was wir brauchen!
Lassen Sie uns dies im Hinterkopf behalten und tiefer graben, um andere potenzielle CSS-Selektoren zu finden, die wir in unserem Spider verwenden können. Überprüfen Sie den HTML-Code, um Buchseiten-URLs zu finden:

Die einzelnen URLs der Buchseiten befinden sich unter einem article HTML-Factor mit der CSS-Klasse product pod. Mithilfe dieser CSS-Regel können wir mit unserem Scraper die Buchseiten-URLs finden.
Überprüfen Sie abschließend die Web site, um einzelne Datenfelder auf der Buchseite zu finden: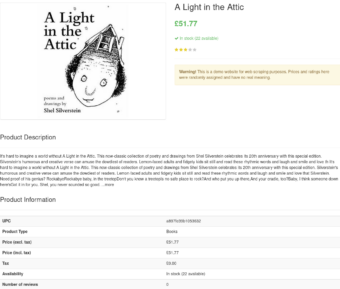
Diesmal ist es etwas schwieriger, da wir nach mehreren Datenfeldern auf der Seite suchen, nicht nur nach einem. Wir benötigen additionally mehrere CSS-Selektoren, um jedes Feld auf der Seite zu finden. Wie Sie auf dem Screenshot oben sehen können, sind einige Datenfelder (wie UPC und Preis) in einer HTML-Tabelle zu finden, andere Felder (wie der Titel) befinden sich jedoch oben auf der Seite in einer anderen Artwork von HTML-Factor.
Nach der Prüfung und dem Finden aller benötigten Datenfelder und URL-Locators können Sie den Spider implementieren:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from bookscraper.gadgets import BookItem
class BookScraper(CrawlSpider):
identify = "bookscraper"
start_urls = ("http://books.toscrape.com/")
guidelines = (
Rule(LinkExtractor(restrict_css=".nav-list > li > ul > li > a"), comply with=True),
Rule(LinkExtractor(restrict_css=".product_pod > h3 > a"), callback="parse_book")
)
def parse_book(self, response):
book_item = BookItem()
book_item("image_url") = response.urljoin(response.css(".merchandise.energetic > img::attr(src)").get())
book_item("title") = response.css(".col-sm-6.product_main > h1::textual content").get()
book_item("value") = response.css(".price_color::textual content").get()
book_item("upc") = response.css(".desk.table-striped > tr:nth-child(1) > td::textual content").get()
book_item("url") = response.url
return book_itemLassen Sie uns aufschlüsseln, was in diesem Codeausschnitt passiert:
- Scrapy öffnet die Web site http://books.toscrape.com/.
- Es beginnt mit der Iteration über die durch definierten Kategorieseiten
.nav-list > li > ul > li > aCSS-Selektor. - Mithilfe dieses CSS-Selektors wird die Iteration über alle Buchseiten auf allen Kategorieseiten gestartet:
.product_pod > h3 > a. - Sobald schließlich eine Buchseite geöffnet wird, extrahiert Scrapy die
image_url,title,value,upcUndurlDatenfelder von der Seite und gibt die zurückBookItemObjekt.
Die Spinne laufen lassen
Abschließend müssen wir testen, ob unser Spider tatsächlich funktioniert und alle benötigten Daten erfasst. Sie können die Spinne mit dem ausführen scrapy crawl Befehl und Verweis auf den Namen des Spiders (wie im Spider-Code definiert, nicht auf den Namen der Datei!):
scrapy crawl bookscraperNachdem Sie diesen Befehl ausgeführt haben, sehen Sie die Ausgabe von Scrapy in Echtzeit, während die gesamte Web site gescrapt wird:
{'image_url': 'http://books.toscrape.com/media/cache/0f/76/0f76b00ea914ced1822d8ac3480c485f.jpg',
'value': '£12.61',
'title': 'The Third Wave: An Entrepreneur’s Imaginative and prescient of the Future',
'upc': '3bebf34ee9330cbd',
'url': 'http://books.toscrape.com/catalogue/the-third-wave-an-entrepreneurs-vision-of-the-future_862/index.html'}
2022-05-01 18:46:18 (scrapy.core.scraper) DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/shoe-dog-a-memoir-by-the-creator-of-nike_831/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/fc/21/fc21d144c7289e5b1cb133e01a925126.jpg',
'value': '£23.99',
'title': 'Shoe Canine: A Memoir by the Creator of NIKE',
'upc': '0e0dcc3339602b28',
'url': 'http://books.toscrape.com/catalogue/shoe-dog-a-memoir-by-the-creator-of-nike_831/index.html'}
2022-05-01 18:46:18 (scrapy.core.scraper) DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/the-10-entrepreneur-live-your-startup-dream-without-quitting-your-day-job_836/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/50/4b/504b1891508614ff9393563f69d66c95.jpg',
'value': '£27.55',
'title': 'The ten% Entrepreneur: Stay Your Startup Dream With out Quitting Your '
'Day Job',
'upc': '56e4f9eab2e8e674',
'url': 'http://books.toscrape.com/catalogue/the-10-entrepreneur-live-your-startup-dream-without-quitting-your-day-job_836/index.html'}
2022-05-01 18:46:18 (scrapy.core.scraper) DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/far-from-true-promise-falls-trilogy-2_320/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/9c/aa/9caacda3ff43984447ee22712e7e9ca9.jpg',
'value': '£34.93',
'title': 'Far From True (Promise Falls Trilogy #2)',
'upc': 'ad15a9a139919918',
'url': 'http://books.toscrape.com/catalogue/far-from-true-promise-falls-trilogy-2_320/index.html'}
2022-05-01 18:46:18 (scrapy.core.scraper) DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/the-travelers_285/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/42/a3/42a345bdcb3e13d5922ff79cd1c07d0e.jpg',
'value': '£15.77',
'title': 'The Vacationers',
'upc': '2b685187f55c5d31',
'url': 'http://books.toscrape.com/catalogue/the-travelers_285/index.html'}
2022-05-01 18:46:18 (scrapy.core.scraper) DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/the-bone-hunters-lexy-vaughan-steven-macaulay-2_343/index.html>
{'image_url': 'http://books.toscrape.com/media/cache/8d/1f/8d1f11673fbe46f47f27b9a4c8efbf8a.jpg',
'value': '£59.71',
'title': 'The Bone Hunters (Lexy Vaughan & Steven Macaulay #2)',
'upc': '9c4d061c1e2fe6bf',
'url': 'http://books.toscrape.com/catalogue/the-bone-hunters-lexy-vaughan-steven-macaulay-2_343/index.html'}Abschluss
Ich hoffe, dieses kurze Scrapy-Tutorial hilft Ihnen beim Einstieg in Scrapy und Net Scraping. Das Erlernen einer Net-Scraping-Fähigkeit macht sehr viel Spaß, aber es ist auch sehr wertvoll, eine große Datenmenge aus dem Net herunterladen zu können, um etwas Interessantes zu erstellen. Scrapy hat ein tolles Gemeinschaft So können Sie sicher sein, dass Sie, wenn Sie in Zukunft beim Schaben nicht weiterkommen, dort oder weiter eine Lösung für Ihr Downside finden Paketüberfluss, Reddit, oder an anderen Orten. Viel Spaß beim Schaben!