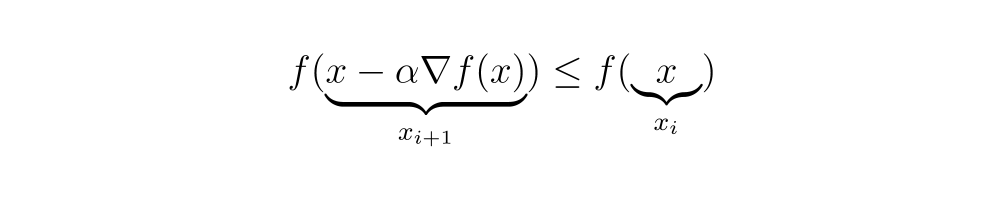
Dieser Algorithmus ist als „Gradientenabstieg“ oder „Methode des steilsten Abstiegs“ bekannt und stellt eine Optimierungsmethode dar, um das Minimal einer Funktion zu finden, bei der jeder Schritt in Richtung des negativen Gradienten erfolgt. Diese Methode garantiert nicht, dass das globale Minimal der Funktion gefunden wird, sondern ein lokales Minimal.
Diskussionen zum Finden des globalen Minimums könnten in einem anderen Artikel entwickelt werden, aber hier haben wir mathematisch demonstriert, wie der Gradient für diesen Zweck verwendet werden kann.
Wenden wir es nun auf die Kostenfunktion an E das kommt darauf an N Gewichte wwir haben:

Um alle Elemente von zu aktualisieren W Basierend auf dem Gradientenabstieg haben wir:

Und für jeden NFactor 𝑤 des Vektors Wwir haben:

Deshalb haben wir unsere theoretischer Lernalgorithmus. Logischerweise bezieht sich dies nicht auf die hypothetische Idee des Kochs, sondern auf zahlreiche Algorithmen des maschinellen Lernens, die wir heute kennen.
Basierend auf dem, was wir gesehen haben, können wir die Demonstration und den mathematischen Beweis des theoretischen Lernalgorithmus abschließen. Eine solche Struktur wird auf zahlreiche Lernmethoden wie AdaGrad, Adam und Stochastic Gradient Descent (SGD) angewendet.
Diese Methode garantiert nicht, dass das gefunden wird N-Gewichtswerte w bei dem die Kostenfunktion ergibt ein Ergebnis von Null oder sehr nahe daran. Es stellt jedoch sicher, dass ein lokales Minimal der Kostenfunktion gefunden wird.
Um das Downside der lokalen Minima anzugehen, gibt es mehrere robustere Methoden wie SGD und Adam, die häufig beim Deep Studying verwendet werden.
Dennoch wird das Verständnis der Struktur und des mathematischen Beweises des auf dem Gradientenabstieg basierenden theoretischen Lernalgorithmus das Verständnis komplexerer Algorithmen erleichtern.
Verweise
Carreira-Perpinan, MA, & Hinton, GE (2005). Über kontrastives Divergenzlernen. In RG Cowell & Z. Ghahramani (Hrsg.), Synthetic Intelligence and Statistics, 2005. (S. 33–41). Fort Lauderdale, FL: Gesellschaft für künstliche Intelligenz und Statistik.
García Cabello, J. Mathematische neuronale Netze. Axiome 2022, 11, 80.
Geoffrey E. Hinton, Simon Osindero, Yee-Whye Teh. Ein schnell lernender Algorithmus für Deep-Perception-Netze. Neuronale Berechnung 18, 1527–1554. Massachusetts Institute of Expertise
LeCun, Y., Bottou, L. & Haffner, P. (1998). Gradientenbasiertes Lernen für die Dokumenterkennung. Proceedings of the IEEE, 86(11), 2278–2324.