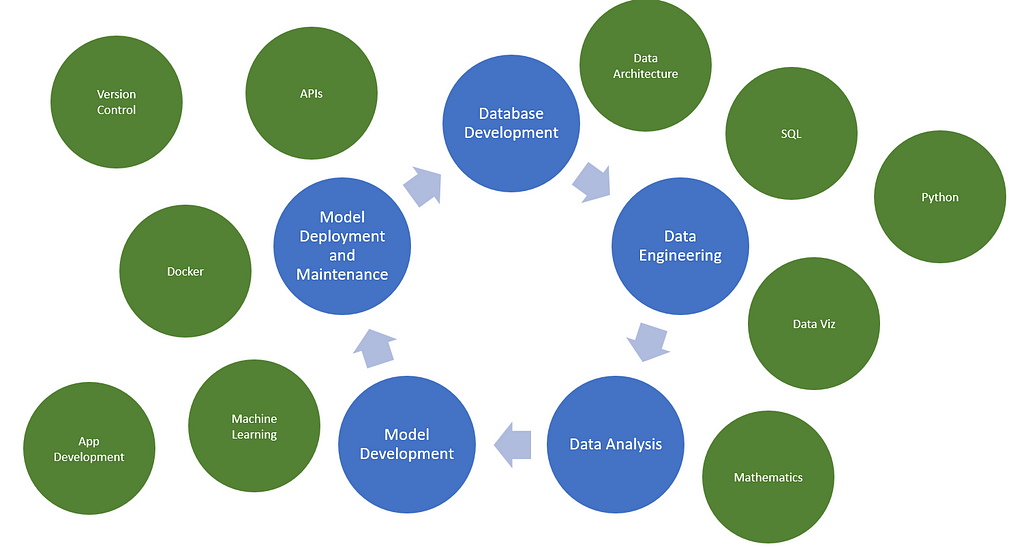
Eine Einführung in die Produktion von Modellen für maschinelles Lernen mithilfe von APIs und Docker.
Wachsende Verantwortung von Datenwissenschaftlern
Der Titel eines Datenwissenschaftlers ändert sich ständig und ist oft vage. In der Regel handelt es sich dabei um jemanden, der sich fließend in Mathematik, Programmierung und maschinellem Lernen auskennt. Sie verbringen Zeit damit, Daten zu bereinigen, Modelle zu erstellen, Feinabstimmungen vorzunehmen und Experimente durchzuführen. Sie müssen außerdem über hervorragende Kommunikationsfähigkeiten, ein gutes Verständnis ihres Fachgebiets und andere Comfortable Abilities verfügen.
Dies ist jedoch nicht immer genau der Fall. Wenn Sie genügend Zeit damit verbringen, durch Jobbörsen zu scrollen, kann „Information Scientist“ ziemlich unterschiedlich sein. Manche lesen sich eher wie ein Dateningenieur und konzentrieren sich auf Pipelines und Huge-Information-Plattformen. Einige ähneln eher einem Datenanalysten und konzentrieren sich auf Datenbereinigung und Dashboarding. Und in letzter Zeit gibt es viele, die der Software program- oder ML-Technik ähneln und sich auf objektorientierte Programmierung, das Erstellen von Anwendungen, das Bereitstellen von Modellen und manchmal sogar auf die Webentwicklung konzentrieren.
Und es gibt diejenigen, die all das und noch mehr erwarten, additionally den „Full-Stack Information Scientist“. Vor diesem Hintergrund sollten Datenwissenschaftler darüber nachdenken, über die Entwicklung von Modellen in einem Pocket book hinauszugehen und ihre Fähigkeiten auf andere Bereiche wie ML Ops zu erweitern. Als Pau Labarta Bajo sagt: „ML-Modelle in Jupyter-Notebooks haben einen Geschäftswert von 𝟬,𝟬𝟬“.
In diesem Artikel wird erläutert, wie Datenwissenschaftler mithilfe von FastAPI und Docker ihre Modelle für maschinelles Lernen erfolgreich von Notebooks bis hin zu vollständig produktiven APIs bereitstellen können.
Gedanken zum „Full-Stack“ Information Scientist
Zunächst meine persönliche Meinung zum „Full-Stack-Information-Scientist“. Angesichts all dieser aufkommenden Erwartungen ist es für uns wichtig, andere Fähigkeiten zu erlernen und mit ihnen vertraut zu sein, die wir in unserer Ausbildung oder zu Beginn unserer Karriere möglicherweise nicht erlernt haben. Allerdings scheint die Erwartung darin zu bestehen, alle diese Fähigkeiten zu beherrschen und zusätzlich mit der traditionellen Datenwissenschaft Schritt zu halten. Und obwohl es einige gibt, die dazu in der Lage sind, ist es für die meisten von uns nicht machbar.
Ich glaube nicht, dass man als Full-Stack-Datenwissenschaftler alle diese Fähigkeiten, Technologien usw. beherrschen muss. Ich denke, dass es bei einem Full-Stack-Information-Scientist darum geht, durch kontinuierliches Lernen und Weiterentwicklung alle Funktionen im Information-Science-Lebenszyklus zu übernehmen.
Auch wenn es vielleicht nicht mein Fachwissen ist, sollte ich in der Lage sein, mit Dateningenieuren zusammenzuarbeiten, um Pipelines zu optimieren. Und obwohl ich mit der Entwicklung von Modellen viel vertrauter bin, sollte ich in der Lage sein, meinen „ML Engineer“-Hut zu tragen und dabei zu helfen, ein Modell in die Bereitstellung zu bringen. Ein großartiger Datenwissenschaftler hat immer seine Nischen, verfügt aber auch über praktische Kenntnisse in anderen Bereichen und kann sich bei Bedarf schnell neue Fähigkeiten aneignen.
Modellentwicklung
Für unser Beispiel müssen wir zunächst ein Modell entwickeln. Da sich dieser Artikel auf die Modellbereitstellung konzentriert, machen wir uns keine Gedanken über die Leistung des Modells. Stattdessen werden wir ein einfaches Modell mit eingeschränkten Funktionen erstellen, um uns auf die Lernmodellbereitstellung zu konzentrieren.
In diesem Beispiel prognostizieren wir das Gehalt eines Datenexperten anhand einiger Merkmale wie Erfahrung, Berufsbezeichnung, Unternehmensgröße usw.
Daten finden Sie hier: https://www.kaggle.com/datasets/ruchi798/data-science-job-salaries (CC0: Public Area). Ich habe die Daten leicht geändert, um die Anzahl der Optionen für bestimmte Funktionen zu reduzieren.
#import packages for knowledge manipulation
import pandas as pd
import numpy as np
#import packages for machine studying
from sklearn import linear_model
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder
from sklearn.metrics import mean_squared_error, r2_score
#import packages for knowledge administration
import joblib
Schauen wir uns zunächst die Daten an.
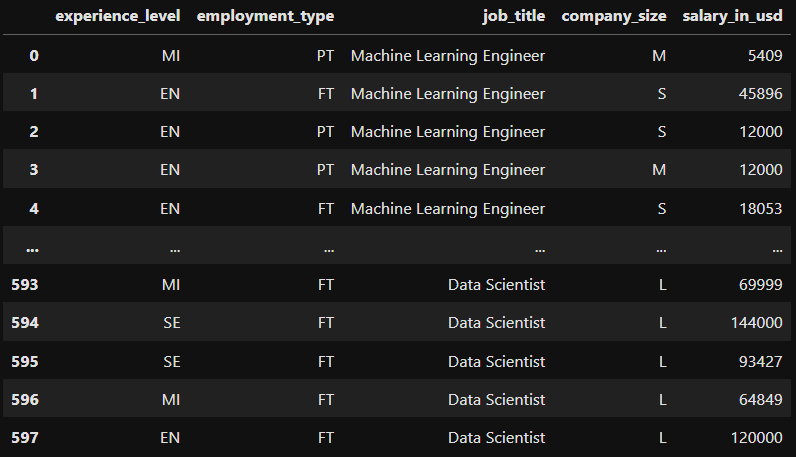
Da alle unsere Funktionen kategorial sind, verwenden wir die Codierung, um unsere Daten in numerische Daten umzuwandeln. Im Folgenden verwenden wir Ordinalkodierer, um den Erfahrungsgrad und die Unternehmensgröße zu kodieren. Diese sind ordinal, da sie eine Artwork Fortschritt darstellen (1 = Einstiegsniveau, 2 = mittleres Niveau usw.).
Für Berufsbezeichnung und Beschäftigungsart erstellen wir für jede Possibility eine Dummy-Variable (beachten Sie, dass wir die erste weglassen, um Multikollinearität zu vermeiden).
#use ordinal encoder to encode expertise stage
encoder = OrdinalEncoder(classes=(('EN', 'MI', 'SE', 'EX')))
salary_data('experience_level_encoded') = encoder.fit_transform(salary_data(('experience_level')))
#use ordinal encoder to encode firm dimension
encoder = OrdinalEncoder(classes=(('S', 'M', 'L')))
salary_data('company_size_encoded') = encoder.fit_transform(salary_data(('company_size')))
#encode employmeny sort and job title utilizing dummy columns
salary_data = pd.get_dummies(salary_data, columns = ('employment_type', 'job_title'), drop_first = True, dtype = int)
#drop authentic columns
salary_data = salary_data.drop(columns = ('experience_level', 'company_size'))
Nachdem wir nun unsere Modelleingaben transformiert haben, können wir unsere Trainings- und Testsätze erstellen. Wir werden diese Merkmale in ein einfaches lineares Regressionsmodell eingeben, um das Gehalt des Mitarbeiters vorherzusagen.
#outline impartial and dependent options
X = salary_data.drop(columns = 'salary_in_usd')
y = salary_data('salary_in_usd')
#cut up between coaching and testing units
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state = 104, test_size = 0.2, shuffle = True)
#match linear regression mannequin
regr = linear_model.LinearRegression()
regr.match(X_train, y_train)
#make predictions
y_pred = regr.predict(X_test)
#print the coefficients
print("Coefficients: n", regr.coef_)
#print the MSE
print("Imply squared error: %.2f" % mean_squared_error(y_test, y_pred))
#print the adjusted R2 worth
print("R2: %.2f" % r2_score(y_test, y_pred))
Mal sehen, wie sich unser Modell geschlagen hat.

Sieht so aus, als ob unser R-Quadrat 0,27 beträgt, huch. Bei diesem Modell müsste noch viel mehr Arbeit geleistet werden. Wir würden wahrscheinlich mehr Daten und zusätzliche Informationen zu den Beobachtungen benötigen. Aber für diesen Artikel werden wir weitermachen und unser Modell speichern.
#save mannequin utilizing joblib
joblib.dump(regr, 'lin_regress.sav')
Erstellen einer API
Es gibt verschiedene Möglichkeiten, ein Modell bereitzustellen. Eine dieser Möglichkeiten ist eine API. Eine API (Software Programming Interface) ermöglicht die Kommunikation zweier Softwareteile miteinander. Es gibt verschiedene API-Architekturen wie SOAP-, RPC- und REST-APIs. Wir werden eine REST-API verwenden, die beliebteste und flexibelste Architektur für den Zugriff auf einen Dienst.
Für unser Framework verwenden wir FastAPI (https://fastapi.tiangolo.com/), das sich hervorragend für Anfänger eignet, da es relativ einfach zu verwenden ist und jede Menge Dokumentation und Beispiele enthält.
Bei REST-APIs gibt es fünf Methoden, die häufig verwendet werden: POST, GET, PUT, PATCH und DELETE. Diese entsprechen den Vorgängen zum Erstellen, Lesen, Aktualisieren und Löschen. Unser Skript unten (Important.py) führt die folgenden Schritte aus:
- Initialisieren Sie das FastAPI-Framework und definieren Sie das Anforderungsformat.
- Laden Sie das Modell herunter.
- Erstellen Sie einen GET-Endpunkt, um das Modell abzurufen.
- Erstellen Sie einen POST-Endpunkt, damit der Benutzer ihm neue Daten senden und eine Vorhersage erstellen kann.
- Definieren Sie die Host-IP und den Port (Standort für den Betrieb der API).
import uvicorn
import pandas as pd
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
# Initialize FastAPI
app = FastAPI()
# Outline the request physique format for predictions
class PredictionFeatures(BaseModel):
experience_level_encoded: float
company_size_encoded: float
employment_type_PT: int
job_title_Data_Engineer: int
job_title_Data_Manager: int
job_title_Data_Scientist: int
job_title_Machine_Learning_Engineer: int
# World variable to retailer the loaded mannequin
mannequin = None
# Obtain the mannequin
def download_model():
international mannequin
mannequin = joblib.load('lin_regress.sav')
# Obtain the mannequin instantly when the script runs
download_model()
# API Root endpoint
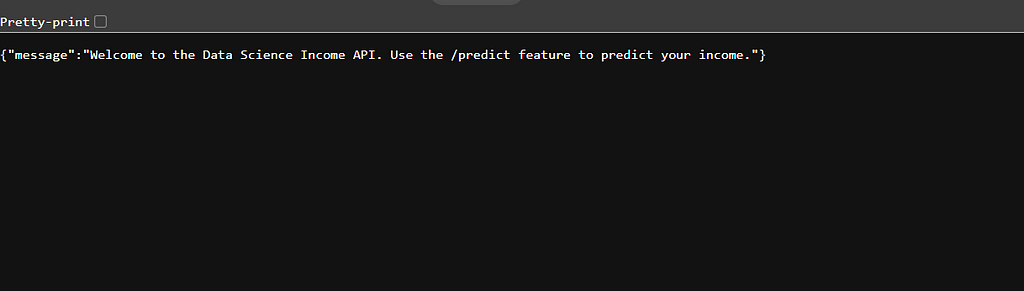
@app.get("/")
async def index():
return {"message": "Welcome to the Information Science Earnings API. Use the /predict characteristic to foretell your earnings."}
# Prediction endpoint
@app.publish("/predict")
async def predict(options: PredictionFeatures):
# Create enter DataFrame for prediction
input_data = pd.DataFrame(({
"experience_level_encoded": options.experience_level_encoded,
"company_size_encoded": options.company_size_encoded,
"employment_type_PT": options.employment_type_PT,
"job_title_Data Engineer": options.job_title_Data_Engineer,
"job_title_Data Supervisor": options.job_title_Data_Manager,
"job_title_Data Scientist": options.job_title_Data_Scientist,
"job_title_Machine Studying Engineer": options.job_title_Machine_Learning_Engineer
}))
# Predict utilizing the loaded mannequin
prediction = mannequin.predict(input_data)(0)
return {
"Wage (USD)": prediction
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Lassen Sie uns nun die Befehlszeile verwenden, um die API zu testen. Wechseln Sie zunächst das Verzeichnis zu Ihrem Projekt. Führen Sie dann die API mit uvicorn aus.
cd "C:UsersadaviOneDriveDesktopSalary Mannequin"
py -m uvicorn essential:app --reload
Die Befehlszeile gibt mir einen Hyperlink, dem ich folgen kann. Dann werde ich mit der Nachricht vom GET-Endpunkt begrüßt. Hübsch!
Zum Schluss erstellen wir ein Testskript, um neue Daten zu übermitteln und eine Vorhersage abzurufen. Mithilfe der Anforderungsbibliothek definieren wir die URL und übermitteln eine neue Beobachtung.
import requests
url = 'http://127.0.0.1:8000/predict'
#dummy knowledge to check API
knowledge = {"experience_level_encoded": 3.0,
"company_size_encoded": 3.0,
"employment_type_PT": 0,
"job_title_Data_Engineer": 0,
"job_title_Data_Manager": 1,
"job_title_Data_Scientist": 0,
"job_title_Machine_Learning_Engineer": 0}
#make a POST request to the API
response = requests.publish(url, json=knowledge)
#print response
response.json()

Die Vorhersage wird dann dank des POST-Endpunkts im JSON-Format zurückgegeben. Großartig, wir haben eine funktionierende API!
Modell mit Docker bereitstellen
Was ist Docker?
Jetzt haben wir die Möglichkeit, mit unserem Modell zu interagieren, aber das Modell ist immer noch nicht bereitgestellt. Nehmen wir an, wir haben ein Staff von 20 Leuten, von denen wir alle wollen, dass die API auf ihrem Laptop läuft. Das dürfte Kopfschmerzen bereiten. Die Replikation von Information-Science-Anwendungen kann eine Herausforderung sein, da es eine Reihe von Hindernissen gibt, wie z. B. unterschiedliche Betriebssysteme, Abhängigkeiten, Tech-Stacks usw.
Hier kommt Docker ins Spiel. Docker ist eine Plattform, die es Entwicklern ermöglicht, ihre Anwendungen und alle ihre Abhängigkeiten in „Containern“ zu packen. Jeder, der Zugriff auf einen Container hat, kann die Anwendung ausführen, ohne sich Gedanken über das Herunterladen der richtigen Paketversionen, den Wechsel des Betriebssystems usw. machen zu müssen. Docker-Container sind außerdem sehr schnell und leichtgewichtig, was einen Vorteil gegenüber virtuellen Umgebungen oder Maschinen bietet.
Laden Sie Docker Desktop hier herunter: https://www.docker.com/
Erstellen einer Docker-Datei und eines Photos
Bevor wir einen Container erstellen, müssen wir zunächst ein Bild erstellen. Ein Docker-Picture ist eine Momentaufnahme der Anwendung und ihrer Abhängigkeiten. Es beschreibt im Wesentlichen die Anweisungen für den Container.
Um ein Picture zu erstellen, müssen Sie eine Docker-Datei erstellen (https://docs.docker.com/reference/dockerfile/). Die Docker-Datei ist ein textbasiertes Dokument, das im Projekt gespeichert wird und Anweisungen zum Zusammenstellen des Bildes enthält. Die Docker-Datei darf keine TXT-Datei sein. Es darf keine Erweiterung haben. Der einfachste Weg, eine Docker-Datei zu erstellen, ist VSCode. Fügen Sie einfach eine neue Datei hinzu und nennen Sie sie „Dockerfile“.
Ich habe die folgende Docker-Datei mithilfe der Einsteigerdokumentation erstellt. Es folgt diesen Schritten:
- Installieren Sie Python 3.9.
- Erstellen Sie ein neues Verzeichnis und kopieren Sie die Projektdateien.
- Installieren Sie die erforderlichen Pakete mithilfe der Datei „necessities.txt“.
- Geben Sie den Port (8000) an.
- Führen Sie die Anwendung aus.
# A Dockerfile is a textual content doc that accommodates all of the instructions
# a consumer might name on the command line to assemble a picture.
FROM python:3.9.4-buster
# Our Debian with python is now put in.
RUN mkdir construct
# We create folder named construct for our stuff.
WORKDIR /construct
# Now we simply need to our WORKDIR to be /construct
COPY . .
# FROM (path to recordsdata from the folder we run docker run)
# TO (present WORKDIR)
# We copy our recordsdata (recordsdata from .dockerignore are ignored)
# to the WORKDIR
RUN pip set up --no-cache-dir -r necessities.txt
# OK, now we pip set up our necessities
EXPOSE 8000
# Instruction informs Docker that the container listens on port 8000
WORKDIR /construct/app
# Now we simply need to our WORKDIR to be /construct/app for simplicity
CMD ("uvicorn", "essential:app", "--host", "0.0.0.0", "--port", "8000")
# This command runs our uvicorn server
Nachdem wir nun unsere Docker-Datei haben, können wir das Picture mit dem folgenden Befehl erstellen. Der Identify des Bildes lautet „apiserver“.
#construct docker picture
docker construct . -t apiserver
Wenn wir zu Docker Desktop navigieren, können wir sehen, dass das Picture erfolgreich erstellt wurde.
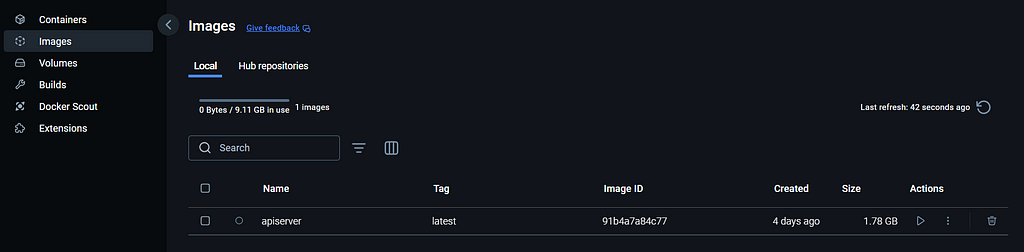
Erstellen eines Docker-Containers
Da wir nun ein Bild haben, ist das Erstellen des Containers sehr einfach. Sobald wir das Picture mit ein paar Anweisungen ausführen, wird der Container erstellt. Unten führen wir das Picture aus und geben den Port an.
#run docker picture
#acces at http://localhost:8000
docker run --rm -it -p 8000:8000/tcp apiserver:newest
Navigieren wir erneut zurück zum Docker Desktop, können wir den Container sehen. Docker gibt Containern zufällige Namen, die schwer nachzuverfolgen sein können. Wenn Sie viele Anwendungen entwickeln, ist es sinnvoll, diese umzubenennen.
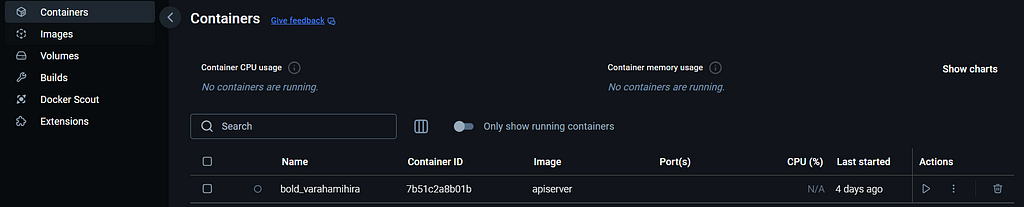
Das Modell ist jetzt bereitgestellt! Um auf unser 20-köpfiges Staff zurückzukommen: Sie benötigen lediglich Docker auf ihrem Laptop und Zugriff auf unseren Container. Anschließend können sie den Container ausführen und die API nach Bedarf verwenden.
Abschluss
Zusammenfassend lässt sich sagen, dass es angesichts der neuen Erwartungen an Datenwissenschaftler wichtig ist, andere Fähigkeiten wie Software program-Engineering und ML Ops zu erlernen. Der Bedarf an „Full-Stack-Information-Scientists“ wächst, da Unternehmen Mitarbeiter benötigen, die sich in allen Phasen des Information-Science-Lebenszyklus engagieren können.
Modelle für maschinelles Lernen aus Notebooks in die Produktion zu übertragen, ist ein großartiger erster Schritt auf dem Weg zum Full-Stack-Datenwissenschaftler. Durch die Verwendung von Instruments wie FastAPI und Docker können Sie die harte Arbeit, die zum Erstellen Ihres Modells erforderlich battle, teilen, indem Sie es auch anderen ermöglichen, es zu verwenden.
Ich hoffe, Ihnen hat mein Artikel gefallen! Bitte zögern Sie nicht, einen Kommentar abzugeben, Fragen zu stellen oder andere Themen anzufordern.
Vernetzen Sie sich mit mir auf LinkedIn: https://www.linkedin.com/in/alexdavis2020/
Der Weg zum Full-Stack-Information Scientist: Modellbereitstellung wurde ursprünglich veröffentlicht in Auf dem Weg zur Datenwissenschaft auf Medium, wo die Leute das Gespräch fortsetzen, indem sie diese Geschichte hervorheben und darauf reagieren.