Untersuchung von Geoffrey Hintons Nobelpreis-Gewinner und bauen Sie sie mit Pytorch von Grund auf neu auf
Ein Empfänger des Nobelpreises von 2024 in Physik battle Geoffrey Hinton für seine Beiträge im Bereich KI und maschinelles Lernen. Viele Leute wissen, dass er an neuronalen Netzwerken gearbeitet hat und wird als „Pate of Ai“ bezeichnet, aber nur wenige verstehen seine Werke. Insbesondere leitete er vor Jahrzehnten eingeschränkte Boltzmann -Maschinen (RBMS) Pionier.
Dieser Artikel wird eine Vorgehensweise von RBMs sein und hoffentlich eine gewisse Instinct hinter diesen komplexen mathematischen Maschinen bereitstellen. Ich werde nach dem Durchlaufen der Ableitungen einen Code zur Implementierung von RBMs in Pytorch bereitstellen.
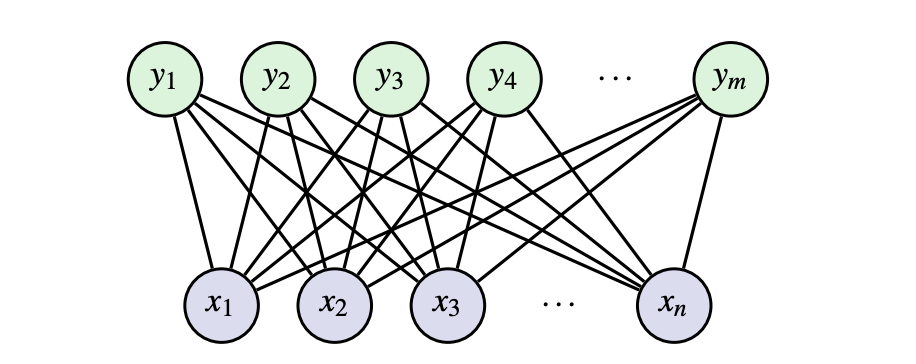
RBMs sind eine Type des unbeaufsichtigten Lernens (nur die Eingaben werden zum Lernen verwendet- keine Ausgangsbezeichnungen werden verwendet). Dies bedeutet, dass wir automatisch aussagekräftige Funktionen in den Daten extrahieren können, ohne sich auf Ausgänge zu verlassen. Ein RBM ist ein Netzwerk mit zwei verschiedenen Arten von Neuronen mit binären Eingaben: sichtbar, Xund versteckt, H. Sichtbare Neuronen nehmen die Eingabedaten auf und versteckte Neuronen lernen, Merkmale/Muster zu erkennen.

In technischeren Hinsicht sagen wir, dass ein RBM ein ungerichtes zweipartneres grafisches Modell mit stochastischen binären sichtbaren und versteckten Variablen ist. Das Hauptziel eines RBM ist es, die Energie der Gelenkkonfiguration zu minimieren E (x, h) oft mit kontrastivem Lernen (später diskutiert).
Eine Energiefunktion entspricht nicht physischer Energie, stammt jedoch aus Physik/Statistik. Stellen Sie sich das wie eine Wertungsfunktion vor. Eine Energiefunktion E Zuweist den Konfigurationen niedrigere Bewertungen (Energien) X Dass wir möchten, dass unser Modell bevorzugt, und höhere Ergebnisse für Konfigurationen, die es vermeiden soll. Die Energiefunktion ist etwas, das wir als Modelldesigner wählen können.
Für RBMs ist die Energiefunktion wie folgt (modelliert nach der Boltzmann -Verteilung):

Die Energiefunktion besteht aus 3 Begriffen. Die erste ist die Wechselwirkung zwischen der verborgenen und sichtbaren Schicht mit Gewichten, W. Die zweite ist die Summe der Vorspannungsbedingungen für die sichtbaren Einheiten. Der dritte ist die Summe der Vorurteile für die verborgenen Einheiten.
Mit der Energiefunktion können wir die Wahrscheinlichkeit der gemeinsamen Konfiguration berechnen, die durch die Boltzmann -Verteilung angegeben ist. Mit dieser Wahrscheinlichkeitsfunktion können wir unsere Einheiten modellieren:

Z ist die Partitionsfunktion (auch als Normalisierungskonstante bekannt). Es ist die Summe von e^(-e) über alle möglichen Konfigurationen von sichtbaren und verborgenen Einheiten. Die große Herausforderung bei Z besteht darin, dass es in der Regel rechnerisch unlösbar ist, genau zu berechnen, weil Sie über alle möglichen Konfigurationen von zusammengefasst werden müssen v Und H. Zum Beispiel mit binären Einheiten, wenn Sie haben M sichtbare Einheiten und N Versteckte Einheiten, Sie müssen über 2^summieren (M+N) Konfigurationen. Daher brauchen wir einen Weg, um eine Berechnung zu vermeiden Z.
Mit diesen definierten Funktionen und Verteilungen können wir einige Ableitungen für Inferenz durchgehen, bevor wir über Schulungen und Implementierung sprechen. Wir haben bereits die Berechnung der Unfähigkeit erwähnt Z in der gemeinsamen Wahrscheinlichkeitsverteilung. Um dies zu umgehen, können wir eine Gibbs -Probenahme verwenden. Die Gibbs -Probenahme ist ein Markov -Kettenmonte -Carlo -Algorithmus für die Probenahme aus einer bestimmten multivariaten Wahrscheinlichkeitsverteilung, wenn direkte Abtastung aus der Gelenkverteilung schwierig ist, aber die Probenahme aus der bedingten Verteilung ist praktischer (2). Daher brauchen wir bedingte Verteilungen.
Der Große an einem eingeschränkt Boltzmann gegen a vollständig verbunden Boltzmann ist die Tatsache, dass es keine Verbindungen innerhalb von Schichten gibt. Dies bedeutet angesichts der sichtbaren Schicht, alle versteckten Einheiten sind bedingt unabhängig und umgekehrt. Schauen wir uns an, was das vereinfacht wird, mit dem Sie beginnen können P(x | h):

Wir können sehen, dass die bedingte Verteilung zu einer Sigmoidfunktion vereinfacht wird W. Es gibt eine weitaus strengere Berechnung, die ich in die enthalten habe Anhang Nachweis der ersten Zeile dieser Ableitung. Greifen Sie bei Interesse nach! Beobachten wir nun die bedingte Verteilung P(h | x):

Wir können diese bedingte Verteilung sehen, die auch zu einer Sigmoidfunktion vereinfacht wird W. Aufgrund der eingeschränkten Kriterien in der RBM vereinfachen die bedingten Verteilungen während der Inferenz zu einfachen Berechnungen für Gibbs -Stichproben. Sobald wir verstehen, was genau der RBM zu lernen versucht, werden wir dies in Pytorch umsetzen.
Wie bei den meisten Tiefenlernen versuchen wir, die detrimental Log-Chance (NLL) zu minimieren, um unser Modell zu trainieren. Für die RBM:

Das Ableitungen dieser Ausbeuten einnehmen:

Der erste Time period auf der linken Seite der Gleichung wird als optimistic Section bezeichnet, da es das Modell dazu drängt, die Energie der realen Daten zu senken. Diese Begriff beinhaltet die Erwartung über versteckte Einheiten H Angesichts der tatsächlichen Trainingsdaten X. Eine optimistic Section ist leicht zu berechnen, da wir über die tatsächlichen Trainingsdaten Xᵗ verfügen und aufgrund der bedingten Unabhängigkeit die Erwartungen über H berechnen können.
Der zweite Time period wird als detrimental Section bezeichnet, da er die Energie der Konfigurationen erhöht, die das Modell derzeit für wahrscheinlich hält. Dieser Begriff beinhaltet die Erwartung über beide X Und H unter der aktuellen Verteilung des Modells. Es ist schwer zu berechnen, da wir aus der vollständigen Gelenkverteilung des Modells probieren müssen P(x, h) (Dies erfordert Markov -Ketten, die im Coaching wiederholt ineffizient sind). Die andere Various erfordert Pc Z was wir bereits als unmöglichkeit angesehen haben. Um dieses Drawback der Berechnung der negativen Section zu lösen, verwenden wir kontrastive Divergenz.
Die Schlüsselidee für kontrastive Divergenz besteht darin, verkürzte Gibbs -Probenahme zu verwenden, um nach Okay -Iterationen eine Punktschätzung zu erhalten. Wir können die detrimental Erwartungsphase durch diese Punktschätzung ersetzen.

Typischerweise ok = 1, aber je größer ok ist, desto weniger verzerrt ist die Schätzung des Gradienten. Ich werde die Ableitung für die verschiedenen Partials in Bezug auf die detrimental Section (für Updates für Gewicht/Voreingenommenheit) nicht zeigen, aber sie kann durch Einnahme des Teilendeivats von abgeleitet werden E(x, h) in Bezug auf die Variablen. Es gibt ein Konzept einer anhaltenden kontrastiven Divergenz, bei der wir die Kette mit der negativen Stichprobe der letzten Iteration initialisieren, anstatt die Kette in Xᵗ zu initialisieren. Ich werde jedoch nicht in die Tiefe eingehen, da die normale kontrastive Divergenz ausreichend funktioniert.
Das Erstellen eines RBM von Grund auf beinhaltet die Kombination aller Konzepte, die wir in einer Klasse besprochen haben. Im Konstruktor __init__ initialisieren wir die Gewichte, den Vorspannungsbegriff für die sichtbare Schicht, den Vorspannungsbegriff für die versteckte Schicht und die Anzahl der Iterationen für kontrastive Divergenz. Alles, was wir brauchen, ist die Größe der Eingangsdaten, die Größe der versteckten Variablen und ok.
Wir müssen auch eine Bernoulli -Verteilung definieren, um abzuprobieren. Die Bernoulli -Verteilung wird geklemmt, um einen explodierenden Gradienten während des Trainings zu verhindern. Beide Verteilungen werden im Vorwärtspass verwendet (kontrastive Divergenz).
class RBM(nn.Module):
"""Restricted Boltzmann Machine template."""def __init__(self, D: int, F: int, ok: int):
"""Creates an occasion RBM module.
Args:
D: Dimension of the enter information.
F: Dimension of the hidden variable.
ok: Variety of MCMC iterations for detrimental sampling.
The operate initializes the burden (W) and biases (c & b).
"""
tremendous().__init__()
self.W = nn.Parameter(torch.randn(F, D) * 1e-2) # Initialized from Regular(imply=0.0, variance=1e-4)
self.c = nn.Parameter(torch.zeros(D)) # Initialized as 0.0
self.b = nn.Parameter(torch.zeros(F)) # Initilaized as 0.0
self.ok = ok
def pattern(self, p):
"""Pattern from a bernoulli distribution outlined by a given parameter."""
p = torch.clamp(p, 0, 1)
return torch.bernoulli(p)
Die nächsten Methoden zum Aufbau der RBM -Klasse sind die bedingten Verteilungen. Wir haben diese beiden Bedingungen früher abgeleitet:
def P_h_x(self, x):
"""Steady conditional likelihood calculation"""
linear = torch.sigmoid(F.linear(x, self.W, self.b))
return lineardef P_x_h(self, h):
"""Steady seen unit activation"""
return self.c + torch.matmul(h, self.W)
Die endgültigen Methoden beinhalten die Implementierung des Ahead -Go und die Funktion der freien Energie. Die Energiefunktion stellt eine wirksame Energie für sichtbare Einheiten dar, nachdem alle möglichen Konfigurationen der versteckten Einheiten zusammengefasst wurden. Die Vorwärtsfunktion ist eine klassische kontrastive Divergenz für die Gibbs -Probenahme. Wir initialisieren x_negative, dann für Okay -Iterationen: Erhalten Sie H_K von p_h_x und x_negativ, pattern h_k aus einem bernoulli, holen Sie x_k aus p_x_h und h_k und erhalten dann ein neues x_negativ.
def free_energy(self, x):
"""Numerically steady free vitality calculation"""
seen = torch.sum(x * self.c, dim=1)
linear = F.linear(x, self.W, self.b)
hidden = torch.sum(torch.log(1 + torch.exp(linear)), dim=1)
return -visible - hiddendef ahead(self, x):
"""Contrastive divergence ahead move"""
x_negative = x.clone()
for _ in vary(self.ok):
h_k = self.P_h_x(x_negative)
h_k = self.pattern(h_k)
x_k = self.P_x_h(h_k)
x_negative = self.pattern(x_k)
return x_negative, x_k
Hoffentlich bildete dies eine Grundlage für die Theorie hinter RBMS sowie eine grundlegende Coding -Implementierungsklasse, mit der ein RBM geschult werden kann. Wenden Sie sich bei jedem Code oder weiteren Derwervien gerne nach weiteren Informationen!
Ableitung für insgesamt P(H | x) Das Produkt jeder einzelnen bedingten Verteilung ist:


(1) Montufar, Guido. „Beschränkte Boltzmann -Maschinen: Einführung und Bewertung.“ Arxiv: 1806.07066v1 (Juni 2018).
(2) https://en.wikipedia.org/wiki/gibbs_sampling
(3) Hinton, Geoffrey. „Schulungsprodukte von Experten durch Minimierung der kontrastiven Abweichungen.“ Neuronale Berechnung (2002).