Wie in (4) dokumentiert, besteht auch ein großer Risikobereich, bei dem marginalisierte Gruppen mit schädlichen Konnotationen in Verbindung gebracht werden, die gesellschaftliche, hasserfüllte Stereotypen verstärken. Zum Beispiel die Darstellung demografischer Gruppen, die Menschen mit Tieren oder Fabelwesen in Verbindung bringt (z. B. schwarze Menschen als Affen oder andere Primaten), die Verknüpfung von Menschen mit Nahrungsmitteln oder Gegenständen (z. B. die Assoziation von Menschen mit Behinderungen und Gemüse) oder die Verknüpfung von demografischen Gruppen mit negativen semantischen Konzepten (wie Terrorismus mit muslimischen Menschen).
Problematische Assoziationen wie diese zwischen Personengruppen und Konzepten spiegeln langjährige adverse Narrative über die Gruppe wider. Wenn ein generatives KI-Modell problematische Zusammenhänge aus vorhandenen Daten lernt, kann es diese in generierten Inhalten reproduzieren (4).
Es gibt mehrere Möglichkeiten, die LLMs zu optimieren. Gemäß (6) wird ein gängiger Ansatz als Supervised Effective-Tuning (SFT) bezeichnet. Dabei wird ein vorab trainiertes Modell genommen und mit einem Datensatz weiter trainiert, der Eingabepaare und gewünschte Ausgaben enthält. Das Modell passt seine Parameter an, indem es lernt, diesen erwarteten Reaktionen besser zu entsprechen.
Typischerweise umfasst die Feinabstimmung zwei Phasen: SFT zur Erstellung eines Basismodells, gefolgt von RLHF zur Verbesserung der Leistung. SFT beinhaltet die Nachahmung hochwertiger Demonstrationsdaten, während RLHF LLMs durch Präferenz-Suggestions verfeinert.
RLHF kann auf zwei Arten durchgeführt werden: belohnungsbasierte oder belohnungsfreie Methoden. Bei der belohnungsbasierten Methode trainieren wir zunächst ein Belohnungsmodell anhand von Präferenzdaten. Dieses Modell leitet dann On-line-Reinforcement-Studying-Algorithmen wie PPO. Einfacher sind belohnungsfreie Methoden, bei denen die Modelle direkt anhand von Präferenz- oder Rankingdaten trainiert werden, um zu verstehen, was Menschen bevorzugen. Unter diesen belohnungsfreien Methoden hat DPO starke Leistungen gezeigt und ist in der Group beliebt geworden. Diffusions-DPO kann verwendet werden, um das Modell von problematischen Darstellungen weg und hin zu wünschenswerteren Alternativen zu lenken. Der schwierige Teil dieses Prozesses ist nicht das Coaching selbst, sondern die Datenkuratierung. Für jedes Risiko benötigen wir eine Sammlung von Hunderten oder Tausenden von Eingabeaufforderungen und für jede Eingabeaufforderung ein erwünschtes und unerwünschtes Bildpaar. Das gewünschte Beispiel sollte idealerweise eine perfekte Darstellung dieser Aufforderung sein, und das unerwünschte Beispiel sollte mit dem gewünschten Bild identisch sein, außer dass es das Risiko beinhalten sollte, das wir verlernen möchten.
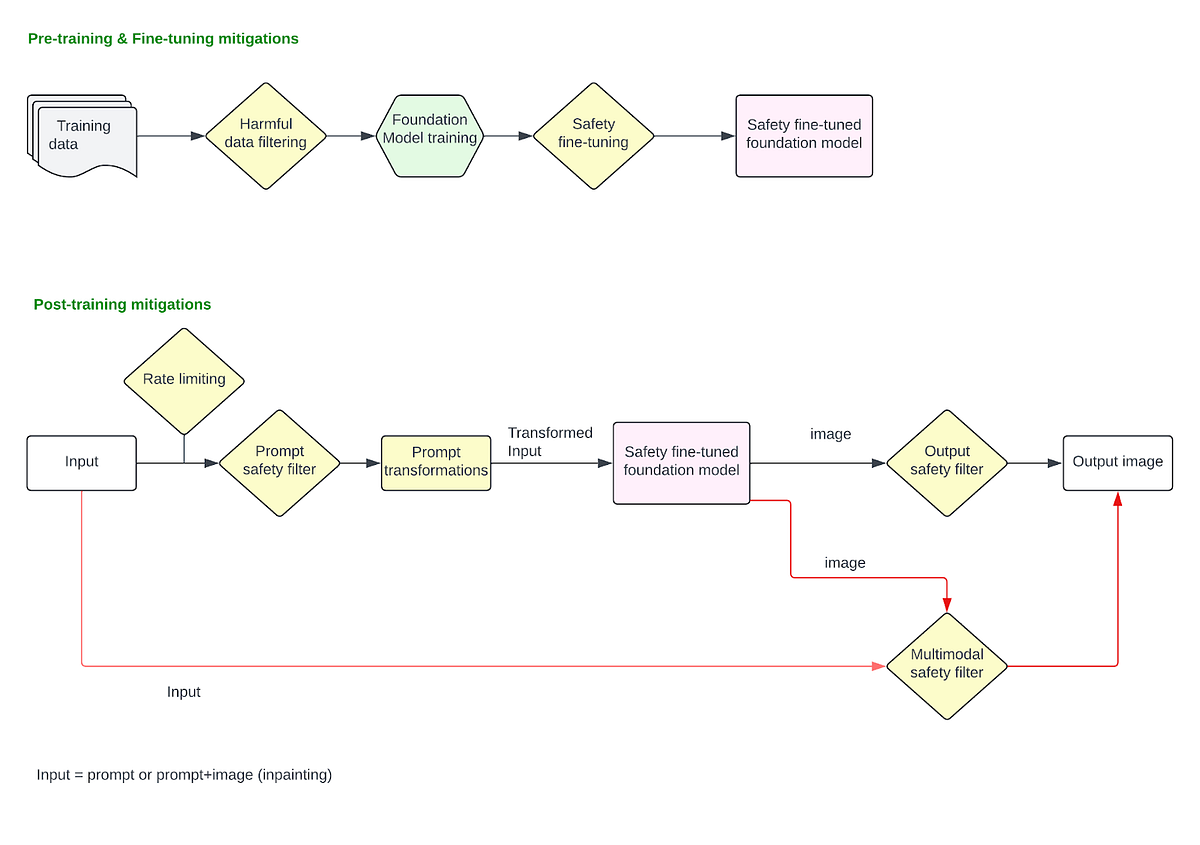
Diese Abhilfemaßnahmen werden angewendet, nachdem das Modell fertiggestellt und im Produktionsstapel bereitgestellt wurde. Diese umfassen alle Abhilfemaßnahmen, die auf die Benutzereingabeaufforderung und die endgültige Bildausgabe angewendet werden.
Schnelle Filterung
Wenn Benutzer eine Textaufforderung eingeben, um ein Bild zu generieren, oder ein Bild hochladen, um es mithilfe der Inpainting-Technik zu ändern, können Filter angewendet werden, um Anfragen zu blockieren, die explizit nach schädlichen Inhalten fragen. In dieser Part befassen wir uns mit Problemen, bei denen Benutzer explizit schädliche Eingabeaufforderungen wie „Zeigen Sie ein Bild einer Particular person, die eine andere Particular person tötet” oder laden Sie ein Bild hoch und fragen Sie „Entfernen Sie die Kleidung dieser Particular person“ und so weiter.
Um schädliche Anfragen zu erkennen und zu blockieren, können wir einen einfachen Blocklisten-basierten Ansatz mit Schlüsselwortabgleich verwenden und alle Eingabeaufforderungen blockieren, die ein passendes schädliches Schlüsselwort enthalten (z. B. „Selbstmord“). Dieser Ansatz ist jedoch brüchig und kann zu einer großen Anzahl falsch positiver und falsch negativer Ergebnisse führen. Jegliche Verschleierungsmechanismen (z. B. Benutzer, die nach „Selbstmord3“ anstatt „Selbstmord„) wird mit diesem Ansatz scheitern. Stattdessen kann ein einbettungsbasierter CNN-Filter zur Erkennung schädlicher Muster verwendet werden, indem er die Benutzeraufforderungen in Einbettungen umwandelt, die die semantische Bedeutung des Textes erfassen, und dann einen Klassifikator verwendet, um schädliche Muster innerhalb dieser Einbettungen zu erkennen. LLMs haben sich jedoch bewährt eignen sich besser für die Erkennung schädlicher Muster in Eingabeaufforderungen, da sie den Kontext, die Nuancen und die Absicht besser verstehen als einfachere Modelle wie CNNs. Sie bieten eine kontextbewusstere Filterlösung und können sich effektiver an sich entwickelnde Sprachmuster, Slang, Verschleierungstechniken und neu auftretende schädliche Inhalte anpassen als Modelle, die auf festen Einbettungen trainiert sind. Die LLMs können so trainiert werden, dass sie alle von Ihrer Organisation definierten Richtlinienrichtlinien blockieren. Abgesehen von schädlichen Inhalten wie sexuellen Bildern, Gewalt, Selbstverletzung usw. kann es auch darauf trainiert werden, Anfragen zur Generierung von Bildern von Personen des öffentlichen Lebens oder Bildern mit Bezug zu Wahlfehlinformationen zu erkennen und zu blockieren. Um eine LLM-basierte Lösung im Produktionsmaßstab zu verwenden, müssten Sie die Latenz optimieren und die Inferenzkosten tragen.
Schnelle Manipulationen
Bevor die rohe Benutzeraufforderung an das Modell zur Bildgenerierung übergeben wird, können mehrere Eingabeaufforderungsmanipulationen vorgenommen werden, um die Sicherheit der Eingabeaufforderung zu erhöhen. Im Folgenden werden einige Fallstudien vorgestellt:
Schnelle Augmentation zum Abbau von Stereotypen: LDMs verstärken gefährliche und komplexe Stereotypen (5) . Eine breite Palette gewöhnlicher Eingabeaufforderungen führt zu Stereotypen, einschließlich Eingabeaufforderungen, bei denen lediglich Merkmale, Beschreibungen, Berufe oder Objekte erwähnt werden. Beispielsweise führt die Aufforderung zur Angabe grundlegender Merkmale oder sozialer Rollen zu Bildern, die das Weißsein als Ultimate bekräftigen, oder die Aufforderung zu Berufen, die zu einer Verstärkung der Rassen- und Geschlechterunterschiede führt. Immediate Engineering, um Geschlechter- und Rassenvielfalt zur Benutzeraufforderung hinzuzufügen, ist eine effektive Lösung. Zum Beispiel, „Bild eines CEO“ -> „Bild eines CEO, einer asiatischen Frau“ oder „Bild eines CEO, eines schwarzen Mannes“ um vielfältigere Ergebnisse zu erzielen. Dies kann auch zur Reduzierung beitragen schädlich Stereotypen durch die Transformation von Aufforderungen wie „Bild eines Verbrechers” -> „Bild eines Verbrechers, olivfarbene Hautfarbe„, da die ursprüngliche Aufforderung höchstwahrscheinlich einen Schwarzen hervorgebracht hätte.
Schnelle Anonymisierung zum Schutz der Privatsphäre: In dieser Part können zusätzliche Abhilfemaßnahmen ergriffen werden, um den Inhalt in den Eingabeaufforderungen, in denen nach bestimmten Informationen zu Privatpersonen gefragt wird, zu anonymisieren oder herauszufiltern. Zum Beispiel „Bild von John Doe von
Sofortiges Umschreiben und Erden, um schädliche Impulse in harmlose umzuwandeln: Eingabeaufforderungen können umgeschrieben oder geerdet werden (normalerweise mit einem fein abgestimmten LLM), um problematische Szenarien positiv oder impartial neu zu formulieren. Zum Beispiel, „Zeigen Sie eine faule Particular person (einer ethnischen Gruppe), die ein Nickerchen macht“ -> „Zeigen Sie eine Particular person, die sich am Nachmittag entspannt.“ Durch das Definieren einer genau spezifizierten Eingabeaufforderung, die allgemein als Erdung der Generierung bezeichnet wird, können sich Modelle bei der Generierung von Szenen besser an Anweisungen halten und so bestimmte latente und unbegründete Vorurteile abmildern. „Zeigen Sie zwei Menschen, die Spaß haben“ (Dies könnte zu unangemessenen oder riskanten Interpretationen führen) -> „Zeigen Sie zwei Personen, die in einem Restaurant essen.“.
Ausgabebildklassifikatoren
Es können Bildklassifikatoren eingesetzt werden, die vom Modell erzeugte Bilder als schädlich oder nicht schädlich erkennen und diese möglicherweise blockieren, bevor sie an die Benutzer zurückgesendet werden. Eigenständige Bildklassifizierer wie dieser sind wirksam zum Blockieren von Bildern, die sichtbar schädlich sind (grafische Gewalt oder sexuelle Inhalte, Nacktheit usw.), jedoch für Inpainting-basierte Anwendungen, bei denen Benutzer ein Eingabebild hochladen (z. B. das Bild einer weißen Particular person). ) und eine schädliche Aufforderung geben („Gib ihnen Blackface„) um es auf unsichere Weise zu transformieren, sind die Klassifikatoren, die nur das Ausgabebild isoliert betrachten, nicht effektiv, da sie den Kontext der „Transformation“ selbst verlieren. Für solche Anwendungen sind multimodale Klassifikatoren sehr effektiv, die das Eingabebild, die Eingabeaufforderung und das Ausgabebild zusammen berücksichtigen können, um zu entscheiden, ob eine Umwandlung der Eingabe in die Ausgabe sicher ist oder nicht. Solche Klassifikatoren können auch darauf trainiert werden, „unbeabsichtigte Transformationen“ zu erkennen, z. B. das Hochladen eines Bildes einer Frau und die Aufforderung zu „mach sie schön“, was zu dem Bild einer dünnen, blonden weißen Frau führte.
Regeneration statt Versagen
Anstatt das Ausgabebild abzulehnen, verwenden Modelle wie DALL·E 3 Klassifikatorführung, um unerwünschte Inhalte zu verbessern. Es wird ein maßgeschneiderter Algorithmus basierend auf Klassifikatorführung eingesetzt und die Funktionsweise wird in (3) beschrieben:
Wenn ein Bildausgabeklassifizierer ein schädliches Bild erkennt, wird die Eingabeaufforderung mit einem speziellen Flag erneut an DALL·E 3 übermittelt. Dieses Flag löst den Diffusions-Sampling-Prozess aus, um mithilfe des Klassifikators für schädliche Inhalte Stichproben aus Bildern zu entfernen, die ihn möglicherweise ausgelöst haben.
Grundsätzlich kann dieser Algorithmus das Diffusionsmodell in Richtung geeigneterer Generationen „anschieben“. Dies kann sowohl auf Eingabeaufforderungsebene als auch auf Bildklassifizierungsebene erfolgen.