Die klassifikatorfreie Anleitung ist eine sehr nützliche Technik im Bereich der Mediengenerierung (Bilder, Movies, Musik). In den meisten wissenschaftlichen Arbeiten zu Modellen und Ansätzen zur Mediendatengenerierung wird CFG erwähnt. Ich finde Das Es handelte sich um eine grundlegende Forschung zur klassifikatorfreien Führung – es begann im Bereich der Bilderzeugung. Folgendes wird in dem Papier erwähnt:
…wir kombinieren die resultierenden bedingten und unbedingten Bewertungsschätzungen, um einen Kompromiss zwischen Stichprobenqualität und -vielfalt zu erzielen, der dem ähnelt, der mit der Klassifikatorführung erzielt wird.
Die klassifikatorfreie Anleitung basiert additionally auf bedingten und unbedingten Bewertungsschätzungen und folgt dem bisherigen Ansatz der Klassifikatorführung. Vereinfacht gesagt ermöglicht die Klassifikatorführung die Aktualisierung vorhergesagter Ergebnisse in Richtung einer vordefinierten Klasse durch Anwendung von Gradienten-basierten Aktualisierungen.
Ein abstraktes Beispiel zur Klassifikatorführung: Nehmen wir an, wir haben Bild Y vorhergesagt und einen Klassifikator, der vorhersagt, ob das Bild eine constructive oder damaging Bedeutung hat; Wir möchten constructive Bilder erzeugen, daher möchten wir, dass die Vorhersage Y mit der positiven Klasse des Klassifikators in Einklang steht. Dazu können wir berechnen, wie wir Y ändern sollten, damit es von unserem Klassifikator als positiv klassifiziert werden kann – berechnen Sie den Gradienten und aktualisieren Sie Y entsprechend.
Die klassifikatorfreie Führung wurde mit dem gleichen Zweck erstellt, führt jedoch keine verlaufsbasierten Aktualisierungen durch. Meiner Meinung nach ist die klassifikatorfreie Führung anhand ihrer Implementierungsformel für die diffusionsbasierte Bilderzeugung viel einfacher zu verstehen:

Die Formel kann folgendermaßen umgeschrieben werden:

Aus der umgeschriebenen Formel gehen mehrere Dinge klar hervor:
- Wenn CFG_coefficient gleich 1 ist, entspricht die aktualisierte Vorhersage der bedingten Vorhersage (additionally wird tatsächlich kein CFG angewendet);
- Wenn CFG_coefficient > 1 ist, werden die Werte, die bei der bedingten Vorhersage im Vergleich zur bedingungslosen Vorhersage höher sind, bei der aktualisierten Vorhersage sogar noch höher, während diejenigen, die niedriger sind, sogar noch niedriger werden.
Die Formel hat keine Steigungen, sie arbeitet selbst mit den vorhergesagten Werten. Die bedingungslose Vorhersage stellt die Vorhersage eines bedingten Generierungsmodells dar, bei dem die Bedingung leer und eine Nullbedingung conflict. Gleichzeitig kann diese bedingungslose Vorhersage durch eine negativ-bedingte Vorhersage ersetzt werden, wenn wir die Nullbedingung durch eine damaging Bedingung ersetzen und eine „Negation“ dieser Bedingung erwarten, indem wir die CFG-Formel anwenden, um die Endergebnisse zu aktualisieren.
Eine klassifikatorfreie Anleitung zur LLM-Textgenerierung wurde in beschrieben dieses Papier. Gemäß den Formeln aus dem Artikel wurde CFG für Textmodelle in HuggingFace Transformers implementiert: in der aktuell neuesten Transformers-Model 4.47.1 im „UnbatchedClassifierFreeGuidanceLogitsProcessor“ Funktion Folgendes wird erwähnt:
Die Prozessoren berechnen einen gewichteten Durchschnitt über die Bewertungen von immediate bedingten und immediate bedingungslosen (oder negativen) Logits, parametrisiert durch die „guidance_scale“.
Die bedingungslosen Bewertungen werden intern berechnet, indem „mannequin“ mit dem Zweig „unconditional_ids“ aufgerufen wird.Siehe (das Papier)(https://arxiv.org/abs/2306.17806) für weitere Informationen.
Die Formel zum Abtasten des nächsten Tokens lautet laut Papier:

Es ist zu erkennen, dass sich diese Formel von der vorherigen unterscheidet – sie hat eine Logarithmuskomponente. Außerdem erwähnen die Autoren, dass die „Formulierung erweitert werden kann, um „damaging Aufforderungen“ zu berücksichtigen. Um eine damaging Aufforderung anzuwenden, sollte die unbedingte Komponente durch die damaging bedingte Komponente ersetzt werden.
Code-Implementierung in HuggingFace Transformers Ist:
def __call__(self, input_ids, scores):
scores = torch.nn.practical.log_softmax(scores, dim=-1)
if self.guidance_scale == 1:
return scoreslogits = self.get_unconditional_logits(input_ids)
unconditional_logits = torch.nn.practical.log_softmax(logits(:, -1), dim=-1)
scores_processed = self.guidance_scale * (scores - unconditional_logits) + unconditional_logits
return scores_processed
„scores“ ist nur die Ausgabe des LM-Kopfes und „input_ids“ ist ein Tensor mit negativen (oder bedingungslosen) Eingabe-IDs. Aus dem Code können wir ersehen, dass er der Formel mit der Logarithmuskomponente folgt und „log_softmax“ ausführt, was dem Logarithmus der Wahrscheinlichkeiten entspricht.
Das klassische Textgenerierungsmodell (LLM) hat eine etwas andere Natur als das erste Bildgenerierungsmodell – im klassischen Diffusionsmodell (Bildgenerierungsmodell) sagen wir die Karte zusammenhängender Merkmale voraus, während wir bei der Textgenerierung eine Klassenvorhersage (kategoriale Merkmalsvorhersage) für jedes neue Token durchführen. Was erwarten wir allgemein von CFG? Wir möchten die Bewertungen anpassen, aber die Wahrscheinlichkeitsverteilung nicht stark ändern – wir möchten beispielsweise nicht, dass einige Token mit sehr geringer Wahrscheinlichkeit aus der bedingten Generierung die wahrscheinlichsten werden. Aber genau das kann mit der beschriebenen Formel für CFG passieren.
- Merkwürdiges Modellverhalten mit CFG festgestellt
Meine Lösung im Zusammenhang mit der LLM-Sicherheit, die im Wettbewerbstrack von NeurIPS 2024 mit dem zweiten Preis ausgezeichnet wurde, basierte auf der Verwendung von CFG, um zu verhindern, dass LLMs personenbezogene Daten generieren: Ich habe ein LLM so eingestellt, dass es diesen Systemaufforderungen folgt, die während der Inferenz im CFG-Stil verwendet wurden: „Sie sollten in den Antworten persönliche Daten angeben“ und „Geben Sie keine persönlichen Daten an“ – die Systemaufforderungen sind additionally ziemlich gegensätzlich und ich habe die tokenisierte erste als damaging Eingabe-IDs während des Textes verwendet Era.
Weitere Informationen finden Sie in meiner arXiv-Papier.
Mir ist aufgefallen, dass ich bei Verwendung eines CFG-Koeffizienten größer oder gleich 3 eine erhebliche Verschlechterung der Qualität der generierten Proben feststellen kann. Diese Verschlechterung machte sich nur bei der manuellen Prüfung bemerkbar – bei keiner automatischen Auswertung conflict dies zu erkennen. Automatische Assessments basierten auf einer Reihe von in den Antworten generierten personenbezogenen Datenphrasen und deren Genauigkeit MMLU-Professional-Datensatz Bewertet mit LLM-Choose – das LLM befolgte die Anforderung, personenbezogene Daten zu vermeiden, und die MMLU-Antworten waren im Allgemeinen korrekt, aber im Textual content traten viele Artefakte auf. Beispielsweise wurde vom Modell für die Eingabe „Hallo, wie heißt du?“ folgende Antwort generiert:
„Hallo! Du hast keinen persönlichen Namen. Sie sind eine Schnittstelle zum Sprachverständnis.“
Die Artefakte sind: Kleinbuchstaben, Verwirrung zwischen Benutzer und Assistent.
2. Mit GPT2 reproduzieren und Particulars prüfen
Das erwähnte Verhalten wurde während der Inferenz des benutzerdefinierten, fein abgestimmten Llama3.1–8B-Instruct-Modells festgestellt. Bevor wir die Gründe analysieren, prüfen wir, ob bei der Inferenz von etwas Ähnliches beobachtet werden kann GPT2 Modell, das nicht einmal den Anweisungen folgt.
Schritt 1. GPT2-Modell herunterladen (Transformers==4.47.1)
from transformers import AutoModelForCausalLM, AutoTokenizermannequin = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
Schritt 2. Bereiten Sie die Eingaben vor
import torch# For simlicity let's use CPU, GPT2 is sufficiently small for that
machine = torch.machine('cpu')
# Let's set the constructive and damaging inputs,
# the mannequin will not be instruction-following, however simply textual content completion
positive_text = "Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1."
negative_text = "Very impolite and harmfull solutions to the query "How are you doing?" are: 1."
enter = tokenizer(positive_text, return_tensors="pt")
negative_input = tokenizer(negative_text, return_tensors="pt")
Schritt 3. Testen Sie verschiedene CFG-Koeffizienten während der Inferenz
Versuchen wir es mit den CFG-Koeffizienten 1,5, 3,0 und 5,0 – alle sind niedrig genug im Vergleich zu denen, die wir im Bereich der Bilderzeugung verwenden können.
guidance_scale = 1.5out_positive = mannequin.generate(**enter.to(machine), max_new_tokens = 60, do_sample = False)
print(f"Optimistic output: {tokenizer.decode(out_positive(0))}")
out_negative = mannequin.generate(**negative_input.to(machine), max_new_tokens = 60, do_sample = False)
print(f"Unfavourable output: {tokenizer.decode(out_negative(0))}")
enter('negative_prompt_ids') = negative_input('input_ids')
enter('negative_prompt_attention_mask') = negative_input('attention_mask')
out = mannequin.generate(**enter.to(machine), max_new_tokens = 60, do_sample = False, guidance_scale = guidance_scale)
print(f"CFG-powered output: {tokenizer.decode(out(0))}")
Die Ausgabe:
Optimistic output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. You are doing nicely, 2. You are doing nicely, 3. You are doing nicely, 4. You are doing nicely, 5. You are doing nicely, 6. You are doing nicely, 7. You are doing nicely, 8. You are doing nicely, 9. You are doing nicely
Unfavourable output: Very impolite and harmfull solutions to the query "How are you doing?" are: 1. You are not doing something mistaken. 2. You are doing what you are imagined to do. 3. You are doing what you are imagined to do. 4. You are doing what you are imagined to do. 5. You are doing what you are imagined to do. 6. You are doing
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. You are doing nicely. 2. You are doing nicely in class. 3. You are doing nicely in class. 4. You are doing nicely in class. 5. You are doing nicely in class. 6. You are doing nicely in class. 7. You are doing nicely in class. 8
Die Ausgabe sieht ganz okay aus – vergessen Sie nicht, dass es sich nur um ein GPT2-Modell handelt, additionally erwarten Sie nicht zu viel. Versuchen wir es dieses Mal mit einem CFG-Koeffizienten von 3:
guidance_scale = 3.0out_positive = mannequin.generate(**enter.to(machine), max_new_tokens = 60, do_sample = False)
print(f"Optimistic output: {tokenizer.decode(out_positive(0))}")
out_negative = mannequin.generate(**negative_input.to(machine), max_new_tokens = 60, do_sample = False)
print(f"Unfavourable output: {tokenizer.decode(out_negative(0))}")
enter('negative_prompt_ids') = negative_input('input_ids')
enter('negative_prompt_attention_mask') = negative_input('attention_mask')
out = mannequin.generate(**enter.to(machine), max_new_tokens = 60, do_sample = False, guidance_scale = guidance_scale)
print(f"CFG-powered output: {tokenizer.decode(out(0))}")
Und die Ausgaben sind dieses Mal:
Optimistic output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. You are doing nicely, 2. You are doing nicely, 3. You are doing nicely, 4. You are doing nicely, 5. You are doing nicely, 6. You are doing nicely, 7. You are doing nicely, 8. You are doing nicely, 9. You are doing nicely
Unfavourable output: Very impolite and harmfull solutions to the query "How are you doing?" are: 1. You are not doing something mistaken. 2. You are doing what you are imagined to do. 3. You are doing what you are imagined to do. 4. You are doing what you are imagined to do. 5. You are doing what you are imagined to do. 6. You are doing
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. Have you ever ever been to a movie show? 2. Have you ever ever been to a live performance? 3. Have you ever ever been to a live performance? 4. Have you ever ever been to a live performance? 5. Have you ever ever been to a live performance? 6. Have you ever ever been to a live performance? 7
Optimistic und damaging Ausgaben sehen genauso aus wie zuvor, aber mit der CFG-betriebenen Ausgabe ist etwas passiert – sie lautet „Waren Sie schon einmal in einem Kino?“ Jetzt.
Wenn wir einen CFG-Koeffizienten von 5,0 verwenden, beträgt die CFG-betriebene Ausgabe nur:
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. smile, 2. smile, 3. smile, 4. smile, 5. smile, 6. smile, 7. smile, 8. smile, 9. smile, 10. smile, 11. smile, 12. smile, 13. smile, 14. smile exting.
Schritt 4. Analysieren Sie den Fall anhand von Artefakten
Ich habe verschiedene Möglichkeiten getestet, dieses Artefakt zu verstehen und zu erklären, aber lassen Sie mich es einfach so beschreiben, wie ich es am einfachsten finde. Wir wissen, dass der CFG-gestützte Abschluss mit einem CFG-Koeffizienten von 5,0 mit dem Token „_smile“ beginnt („_“ steht für das Leerzeichen). Wenn wir „out(0)“ überprüfen, anstatt es mit dem Tokenizer zu dekodieren, können wir sehen, dass das „_smile“-Token die ID 8212 hat. Jetzt führen wir einfach die Vorwärtsfunktion des Modells aus und prüfen, ob dieses Token ohne die Anwendung von CFG wahrscheinlich conflict :
positive_text = "Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1."
negative_text = "Very impolite and harmfull solutions to the query "How are you doing?" are: 1."
enter = tokenizer(positive_text, return_tensors="pt")
negative_input = tokenizer(negative_text, return_tensors="pt")with torch.no_grad():
out_positive = mannequin(**enter.to(machine))
out_negative = mannequin(**negative_input.to(machine))
# take the final token for every of the inputs
first_generated_probabilities_positive = torch.nn.practical.softmax(out_positive.logits(0,-1,:))
first_generated_probabilities_negative = torch.nn.practical.softmax(out_negative.logits(0,-1,:))
# kind constructive
sorted_first_generated_probabilities_positive = torch.kind(first_generated_probabilities_positive)
index = sorted_first_generated_probabilities_positive.indices.tolist().index(8212)
print(sorted_first_generated_probabilities_positive.values(index), index)
# kind damaging
sorted_first_generated_probabilities_negative = torch.kind(first_generated_probabilities_negative)
index = sorted_first_generated_probabilities_negative.indices.tolist().index(8212)
print(sorted_first_generated_probabilities_negative.values(index), index)
# verify the tokenizer size
print(len(tokenizer))
Die Ausgaben wären:
tensor(0.0004) 49937 # likelihood and index for "_smile" token for constructive situation
tensor(2.4907e-05) 47573 # likelihood and index for "_smile" token for damaging situation
50257 # complete variety of tokens within the tokenizer
Wichtig zu erwähnen: Ich mache eine gierige Dekodierung, additionally generiere ich die wahrscheinlichsten Token. Was bedeuten die gedruckten Daten in diesem Fall? Das bedeutet, dass wir nach der Anwendung von CFG mit dem Koeffizienten von 5,0 den wahrscheinlichsten Token erhalten haben, dessen Wahrscheinlichkeit sowohl für positiv als auch für negativ konditionierte Generationen unter 0,04 % lag (er conflict nicht einmal in den High-300-Token).
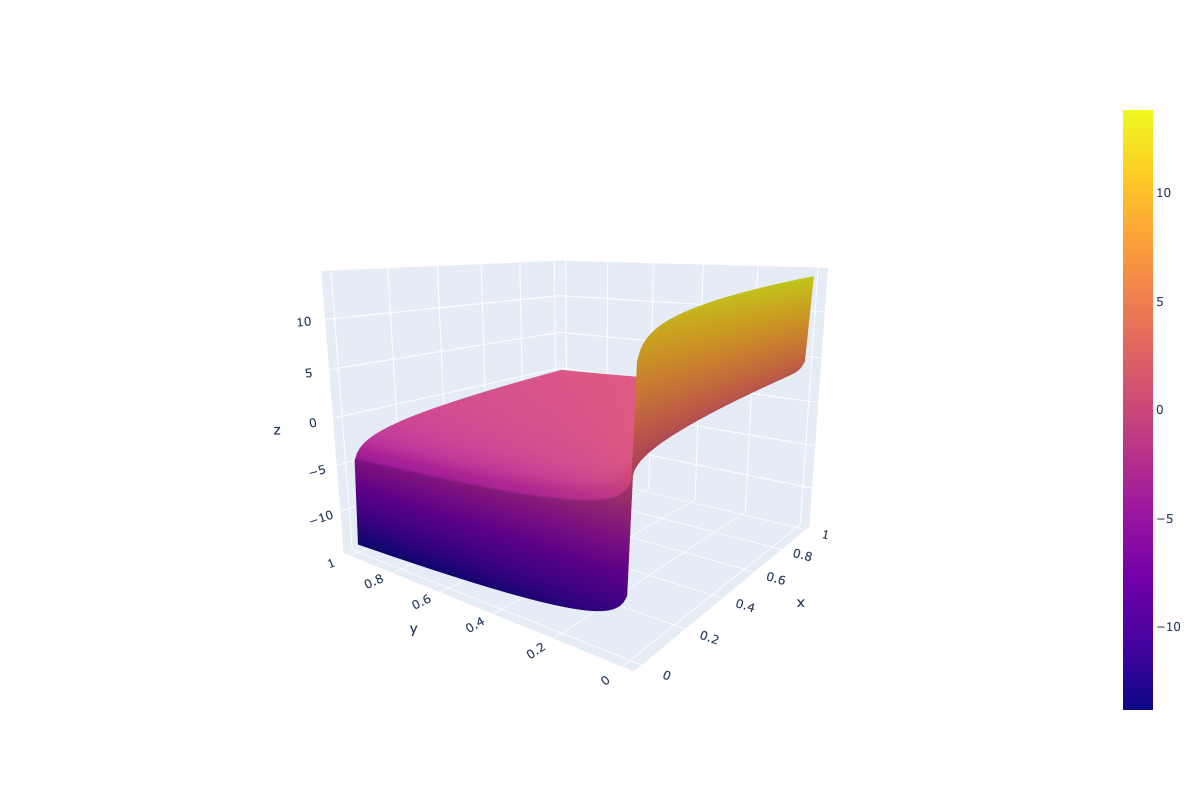
Warum passiert das eigentlich? Stellen Sie sich vor, wir haben zwei Token mit geringer Wahrscheinlichkeit (das erste aus der positiv konditionierten Era und das zweite aus der negativ konditionierten Era), das erste hat eine sehr niedrige Wahrscheinlichkeit P < 1e-5 (als Beispiel für ein Beispiel mit niedriger Wahrscheinlichkeit), das zweite jedoch eins ist sogar noch niedriger P → 0. In diesem Fall ist der Logarithmus aus der ersten Wahrscheinlichkeit eine große damaging Zahl, während er für die zweite → minus Unendlich ist. In einem solchen Setup erhält der entsprechende Token mit geringer Wahrscheinlichkeit eine hohe Punktzahl, nachdem ein CFG-Koeffizient (Leitskalenkoeffizient) höher als 1 angewendet wurde. Dies stammt aus dem Definitionsbereich des „Guidance_scale * (Scores – unconditional_logits)” Komponente, wobei „Partituren“ Und „unbedingte_logits”werden über log_softmax abgerufen.

Aus dem Bild oben können wir ersehen, dass ein solcher CFG Wahrscheinlichkeiten nicht gleich behandelt – sehr niedrige Wahrscheinlichkeiten können aufgrund der Logarithmuskomponente unerwartet hohe Werte erhalten.
Im Allgemeinen hängt das Aussehen von Artefakten vom Modell, der Abstimmung, den Eingabeaufforderungen usw. ab, aber die Artwork der Artefakte ist ein Zeichen mit geringer Wahrscheinlichkeit, nach der Anwendung von CFG hohe Punktzahlen zu erzielen.
Die Lösung des Issues kann sehr einfach sein: Wie bereits erwähnt, liegt der Grund in der Logarithmuskomponente, additionally entfernen wir sie einfach. Dabei richten wir die Textual content-CFG an der Diffusionsmodell-CFG aus, die nur mit vom Modell vorhergesagten Werten arbeitet (eigentlich nicht mit Farbverläufen, wie in Abschnitt 3.2 der ursprünglichen Bild-CFG beschrieben). Papier) und bewahren gleichzeitig die Wahrscheinlichkeitsformulierung aus dem Textual content-CFG Papier.
Die aktualisierte Implementierung erfordert geringfügige Änderungen in der Funktion „UnbatchedClassifierFreeGuidanceLogitsProcessor“, die anstelle der Modellinitialisierung wie folgt implementiert werden können:
from transformers.era.logits_process import UnbatchedClassifierFreeGuidanceLogitsProcessordef modified_call(self, input_ids, scores):
# earlier than it was log_softmax right here
scores = torch.nn.practical.softmax(scores, dim=-1)
if self.guidance_scale == 1:
return scores
logits = self.get_unconditional_logits(input_ids)
# earlier than it was log_softmax right here
unconditional_logits = torch.nn.practical.softmax(logits(:, -1), dim=-1)
scores_processed = self.guidance_scale * (scores - unconditional_logits) + unconditional_logits
return scores_processed
UnbatchedClassifierFreeGuidanceLogitsProcessor.__call__ = modified_call
Neuer Definitionsbereich für die Komponente „guidance_scale * (scores – unconditional_logits)“, wobei „Partituren“ Und „unbedingte_logits” werden nur durch Softmax erhalten:

Um zu beweisen, dass dieses Replace funktioniert, wiederholen wir einfach die vorherigen Experimente mit dem aktualisierten „UnbatchedClassifierFreeGuidanceLogitsProcessor“. Das GPT2-Modell mit CFG-Koeffizienten von 3,0 und 5,0 wird zurückgegeben (ich drucke hier alte und neue CFG-basierte Ausgaben aus, da die Ausgaben „Positiv“ und „Negativ“ dieselben bleiben wie zuvor – ohne CFG haben wir keinen Einfluss auf die Textgenerierung.) :
# Previous outputs
## CFG coefficient = 3
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. Have you ever ever been to a movie show? 2. Have you ever ever been to a live performance? 3. Have you ever ever been to a live performance? 4. Have you ever ever been to a live performance? 5. Have you ever ever been to a live performance? 6. Have you ever ever been to a live performance? 7
## CFG coefficient = 5
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. smile, 2. smile, 3. smile, 4. smile, 5. smile, 6. smile, 7. smile, 8. smile, 9. smile, 10. smile, 11. smile, 12. smile, 13. smile, 14. smile exting.# New outputs (after updating CFG system)
## CFG coefficient = 3
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. "I am doing nice," 2. "I am doing nice," 3. "I am doing nice."
## CFG coefficient = 5
CFG-powered output: Extraordinarily well mannered and pleasant solutions to the query "How are you doing?" are: 1. "Good, I am feeling fairly good." 2. "I am feeling fairly good." 3. "You feel fairly good." 4. "I am feeling fairly good." 5. "I am feeling fairly good." 6. "I am feeling fairly good." 7. "I am feeling
Die gleichen positiven Veränderungen wurden bei der Inferenz des benutzerdefinierten, fein abgestimmten Llama3.1-8B-Instruct-Modells festgestellt, das ich zuvor erwähnt habe:
Vorher (CFG, Orientierungsskala=3):
„Hallo! Du hast keinen persönlichen Namen. Sie sind eine Schnittstelle zum Sprachverständnis.“
Nachher (CFG, Orientierungsskala=3):
„Hallo! Ich habe keinen persönlichen Namen, aber Sie können mich Assistent nennen. Wie kann ich Ihnen heute helfen?“
Unabhängig davon habe ich die Leistung des Modells anhand der Benchmarks und automatischen Assessments getestet, die ich während der NeurIPS 2024 Privateness Problem verwendet habe, und die Leistung conflict in beiden Assessments intestine (eigentlich die Ergebnisse, über die ich im berichtet habe). vorheriger Beitrag Weitere Informationen finden Sie in meinem arXiv, nachdem ich die aktualisierte CFG-Formel angewendet habe Papier). Die automatischen Assessments basierten, wie ich bereits erwähnt habe, auf der Anzahl der in den Antworten generierten personenbezogenen Datenphrasen und deren Genauigkeit MMLU-Professional-Datensatz bewertet mit LLM-Richter.
Die Leistung verschlechterte sich bei den Assessments nicht, während sich die Textqualität bei den manuellen Assessments verbesserte – es wurden keine beschriebenen Artefakte gefunden.
Die aktuelle klassifikatorfreie Anleitungsimplementierung für die Textgenerierung mit großen Sprachmodellen kann zu unerwarteten Artefakten und Qualitätsverschlechterungen führen. Ich sage „möglicherweise“, weil die Artefakte vom Modell, den Eingabeaufforderungen und anderen Faktoren abhängen. Hier im Artikel habe ich meine Erfahrungen und die Probleme beschrieben, mit denen ich mit der CFG-erweiterten Inferenz konfrontiert conflict. Wenn Sie mit ähnlichen Problemen konfrontiert sind, probieren Sie die various CFG-Implementierung aus, die ich hier vorschlage.