Optimierung der Datenübertragung für Enterprise Knowledge Lakes

Azure Knowledge Manufacturing facility (ADF) ist ein beliebtes Software zum Verschieben von Daten in großem Maßstab, insbesondere in Enterprise Knowledge Lakes. Es wird häufig zum Erfassen und Transformieren von Daten verwendet, wobei häufig mit dem Kopieren von Daten aus der lokalen Umgebung in Azure Storage begonnen wird. Von dort aus werden die Daten nach einer Medaillonarchitektur durch verschiedene Zonen bewegt. ADF ist auch für die Erstellung und Wiederherstellung von Backups im Falle von Katastrophen wie Datenbeschädigung, Malware oder Kontolöschung unerlässlich.
Dies bedeutet, dass ADF zum Verschieben großer Datenmengen, TBs und manchmal sogar PBs, verwendet wird. Daher ist es wichtig, die Kopierleistung zu optimieren und so die Durchlaufzeit zu begrenzen. Eine gängige Methode zur Verbesserung der ADF-Leistung ist die Parallelisierung von Kopieraktivitäten. Die Parallelisierung erfolgt jedoch dort, wo sich die meisten Daten befinden, und dies kann eine Herausforderung sein, wenn der Knowledge Lake verzerrt ist.
In diesem Blogbeitrag werden verschiedene ADF-Parallelisierungsstrategien für Knowledge Lakes diskutiert und ein Projekt bereitgestellt. Das ADF-Lösungsprojekt finden Sie unter diesem Hyperlink: https://github.com/rebremer/data-factory-copy-skewed-data-lake.
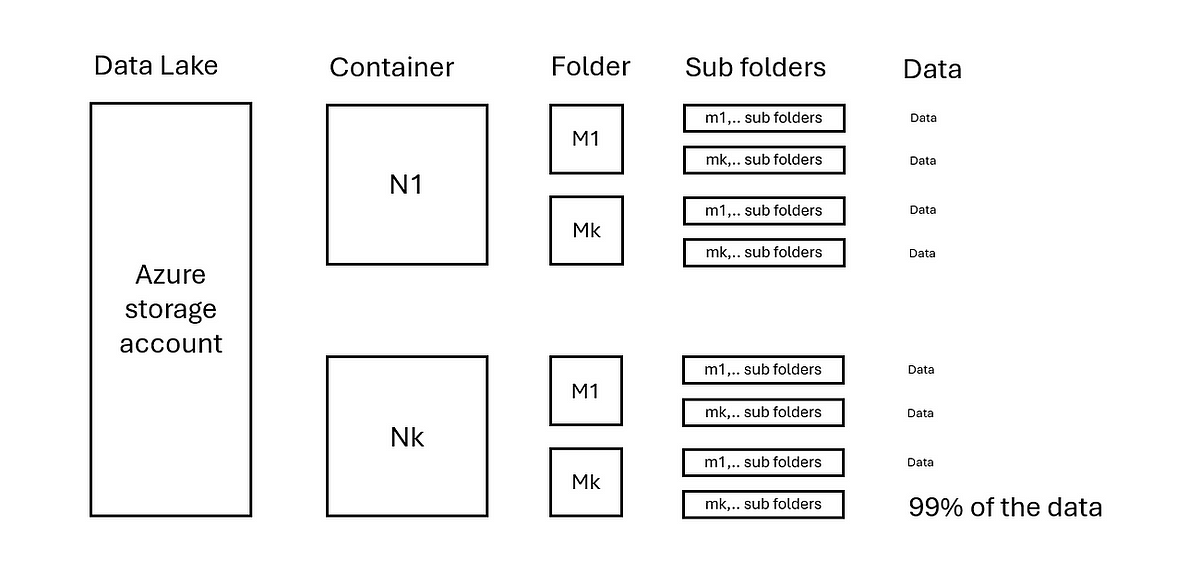
Knowledge Lakes gibt es in allen Größen und Ausführungen. Um die Kopierleistung zu verbessern, ist es wichtig, die Datenverteilung innerhalb eines Knowledge Lake zu verstehen. Betrachten Sie die folgende State of affairs:
- Ein Azure Storage-Konto verfügt über N Container.
- Jeder Container enthält M Ordner und m Ebenen von Unterordnern.
- Die Daten werden gleichmäßig in den Ordnern N/M/… verteilt.
Siehe auch Bild unten:

In dieser State of affairs können Kopieraktivitäten auf jedem Container N parallelisiert werden. Bei größeren Datenmengen kann die Leistung durch Parallelisierung auf Ordner M innerhalb von Container N weiter verbessert werden. Anschließend kann professional Kopieraktivität konfiguriert werden, wie viel Datenintegrationseinheiten (DIU) Und Parallelisierung kopieren innerhalb Es wird eine Kopieraktivität verwendet.
Betrachten Sie nun die folgende Extremsituation, in der der letzte Ordner Nk und Mk 99 % der Daten enthält, siehe Abbildung unten:

Dies bedeutet, dass die Parallelisierung in den Unterordnern in Nk/Mk erfolgen muss, in denen sich die Daten befinden. Dann ist eine ausgefeiltere Logik erforderlich, um die genauen Speicherorte der Daten zu bestimmen. Hierzu kann eine in ADF integrierte Azure-Funktion genutzt werden. Im nächsten Kapitel wird ein Projekt bereitgestellt und die Parallelisierungsmöglichkeiten genauer besprochen.
In diesem Teil wird das Projekt bereitgestellt und ein Kopiertest durchgeführt und besprochen. Das gesamte Projekt finden Sie im Projekt: https://github.com/rebremer/data-factory-copy-skewed-data-lake.
3.1 Projekt bereitstellen
Führen Sie das Skript aus deploy_adf.ps1. Falls ADF erfolgreich bereitgestellt wird, werden zwei Pipelines bereitgestellt:

Führen Sie anschließend das Skript aus deploy_azurefunction.ps1. Falls die Azure-Funktion erfolgreich bereitgestellt wird, wird der folgende Code bereitgestellt.

Um das Projekt endgültig auszuführen, stellen Sie sicher, dass die vom System zugewiesene verwaltete Identität der Azure-Funktion und der Knowledge Manufacturing facility auf das Speicherkonto zugreifen kann, von dem und in das die Daten kopiert werden.
3.2 Im Projekt verwendete Parallelisierung
Nachdem das Projekt bereitgestellt wurde, kann festgestellt werden, dass die folgenden Instruments bereitgestellt werden, um die Leistung mithilfe der Parallelisierung zu verbessern.
- Root-Pipeline: Root-Pipeline, die Container N im Speicherkonto auflistet und für jeden Container eine untergeordnete Pipeline auslöst.
- Untergeordnete Pipeline: Untergeordnete Pipeline, die Ordner M in einem Container auflistet und rekursive Kopieraktivitäten für jeden Ordner auslöst.
- Schalten: Die untergeordnete Pipeline verwendet einen Schalter, um zu entscheiden, wie Listenordner bestimmt werden sollen. Für den Fall „default“ (gerade) wird Get Metadata verwendet, für den Fall „uneven“ wird eine Azure Operate verwendet.
- Metadaten abrufen: Pay attention Sie alle Stammordner M in einem bestimmten Container N auf.
- Azure-Funktion: Alle Ordner und Unterordner auflisten, die nicht mehr als X GB Daten enthalten und als Ganzes kopiert werden sollen.
- Aktivität kopieren: Rekursives Kopieren aller Daten aus einem bestimmten Ordner.
- DIU: Anzahl der Datenintegrationseinheiten professional Kopieraktivität.
- Parallelisierung kopieren: Innerhalb eine Kopieraktivität, Anzahl der parallelen Kopierthreads, die gestartet werden können. Jeder Thread kann eine Datei kopieren, maximal 50 Threads.
Im gleichmäßig verteilten Knowledge Lake werden die Daten gleichmäßig auf N Container und M Ordner verteilt. In dieser State of affairs können Kopieraktivitäten einfach für jeden Ordner M parallelisiert werden. Dies kann mithilfe von „Metadaten abrufen“ zum Auflisten der Ordner „M“ und „Für jeden“ zum Durchlaufen von Ordnern und zum Kopieren von Aktivitäten professional Ordner erfolgen. Siehe auch Bild unten.

Bei dieser Strategie würde dies bedeuten, dass bei jeder Kopieraktivität die gleiche Datenmenge kopiert wird. Insgesamt werden N*M Kopieraktivitäten ausgeführt.
Im schief verteilten Knowledge Lake sind die Daten nicht gleichmäßig auf N Container und M Ordner verteilt. In dieser State of affairs müssen Kopieraktivitäten dynamisch bestimmt werden. Dies kann mithilfe einer Azure-Funktion erfolgen, um die datenintensiven Ordner aufzulisten, und anschließend mit „For Every“, um über Ordner zu iterieren und Aktivitäten professional Ordner zu kopieren. Siehe auch Bild unten.

Mit dieser Strategie werden Kopieraktivitäten dynamisch im Knowledge Lake skaliert, wo Daten gefunden werden können und Parallelisierung daher am meisten benötigt wird. Obwohl diese Lösung komplexer ist als die vorherige Lösung, da sie eine Azure-Funktion erfordert, ermöglicht sie das Kopieren verzerrter verteilter Daten.
3.3: Parallelisierungsleistungstest
Um die Leistung verschiedener Parallelisierungsoptionen zu vergleichen, wird ein einfacher Take a look at wie folgt aufgebaut:
- Zwei Speicherkonten und 1 ADF-Instanz mit einer Azure IR in der Area Westeuropa. Daten werden vom Quell- in das Zielspeicherkonto kopiert.
- Das Quellspeicherkonto enthält drei Container mit jeweils 0,72 TB Daten, verteilt auf mehrere Ordner und Unterordner.
- Die Daten werden gleichmäßig über die Container verteilt, es gibt keine verzerrten Daten.
Take a look at A: Kopieren Sie 1 Container mit 1 Kopieraktivität unter Verwendung von 32 DIU und 16 Threads in der Kopieraktivität (beide auf „Automatisch“ eingestellt) => 0,72 TB Daten werden kopiert, 12 m27 s Kopierzeit, durchschnittlicher Durchsatz beträgt 0,99 GB/s
Take a look at B: Kopieren Sie 1 Container mit 1 Kopieraktivität unter Verwendung von 128 DIU und 32 Threads in der Kopieraktivität => 0,72 TB Daten werden kopiert, 06 Min. 19 Sek. Kopierzeit, durchschnittlicher Durchsatz beträgt 1,95 GB/s.
Take a look at C: Kopieren Sie 1 Container mit 1 Kopieraktivität mit 200 DIU und 50 Threads (max.) => Take a look at wurde wegen Drosselung abgebrochen, kein Leistungsgewinn im Vergleich zu Take a look at B.
Take a look at D: Kopieren Sie 2 Container mit 2 Kopieraktivitäten parallel unter Verwendung von 128 DIU und 32 Threads für jede Kopieraktivität => 1,44 TB Daten werden kopiert, 07:00 Uhr Kopierzeit, durchschnittlicher Durchsatz beträgt 3,53 GB/s.
Take a look at E: Kopieren Sie 3 Container mit 3 Kopieraktivitäten parallel unter Verwendung von 128 DIU und 32 Threads für jede Kopieraktivität => 2,17 TB Daten werden kopiert, 08 Min. 07 Sekunden Kopierzeit, durchschnittlicher Durchsatz beträgt 4,56 GB/s. Siehe auch Screenshot unten.

Dabei ist zu beachten, dass der ADF nicht sofort mit dem Kopieren beginnt, da es eine Startzeit gibt. Bei einer Azure IR beträgt dies etwa 10 Sekunden. Diese Startzeit ist festgelegt und ihre Auswirkung auf den Durchsatz kann bei großen Kopien vernachlässigt werden. Außerdem beträgt der maximale Eingang eines Speicherkontos 60 Gbit/s (=7,5 GB/s). Eine Skalierung über diesen Wert hinaus ist nicht möglich, es sei denn, es wird zusätzliche Kapazität auf dem Speicherkonto angefordert.
Aus dem Take a look at lassen sich folgende Erkenntnisse ziehen:
- Durch die Erhöhung von DIU und Paralleleinstellungen kann bereits eine deutliche Leistungssteigerung erzielt werden innerhalb Kopieraktivität.
- Durch die parallele Ausführung von Copy-Pipelines kann die Leistung weiter gesteigert werden.
- Bei diesem Take a look at wurden die Daten gleichmäßig auf zwei Container verteilt. Wenn die Daten verzerrt wären und sich alle Daten aus Container 1 in einem Unterordner von Container 2 befinden würden, müssten beide Kopieraktivitäten auf Container 2 abzielen. Dadurch wird eine ähnliche Leistung wie bei Take a look at D gewährleistet.
- Wenn der Datenspeicherort vorher unbekannt oder tief verschachtelt ist, wäre eine Azure-Funktion erforderlich, um die Datentaschen zu identifizieren und sicherzustellen, dass die Kopieraktivitäten am richtigen Ort ausgeführt werden.
Azure Knowledge Manufacturing facility (ADF) ist ein beliebtes Software zum Verschieben von Daten in großem Maßstab. Es wird häufig zum Erfassen, Transformieren, Sichern und Wiederherstellen von Daten in Enterprise Knowledge Lakes verwendet. Angesichts seiner Rolle beim Verschieben großer Datenmengen ist die Optimierung der Kopierleistung von entscheidender Bedeutung, um die Durchlaufzeit zu minimieren.
In diesem Blogbeitrag haben wir die folgenden Parallelisierungsstrategien besprochen, um die Leistung des Datenkopierens in und aus Azure Storage zu verbessern.
- Innerhalb Verwenden Sie bei einer Kopieraktivität standardmäßige Knowledge Integration Items (DIU) und Parallelisierungsthreads innerhalb einer Kopieraktivität.
- Führen Sie Kopieraktivitäten parallel aus. Wenn bekannt ist, dass die Daten gleichmäßig verteilt sind, können Standardfunktionen in ADF verwendet werden, um Kopieraktivitäten über jeden Container (N) und Stammordner (M) hinweg zu parallelisieren.
- Führen Sie Kopieraktivitäten dort aus, wo sich die Daten befinden. Falls dies nicht im Voraus bekannt oder tief verschachtelt ist, kann eine Azure-Funktion zum Auffinden der Daten genutzt werden. Allerdings erhöht die Integration einer Azure-Funktion in eine ADF-Pipeline die Komplexität und sollte vermieden werden, wenn sie nicht benötigt wird.
Leider gibt es keine Patentlösung und es sind immer Analysen und Exams erforderlich, um die beste Strategie zur Verbesserung der Kopierleistung für Enterprise Knowledge Lakes zu finden. Ziel dieses Artikels warfare es, eine Orientierungshilfe bei der Auswahl der besten Strategie zu geben.