
Xai eingeführt GROK-4-FASTein kostenoptimierter Nachfolger von GROK-4, der Verhaltensweisen „Argumentation“ und „Nicht-Begrenzung“ in einen einzigen Satz von Gewichten, die über Systemaufforderungen kontrollierbar sind, verschmelzen. Das Modell zielt auf Hochdurchsatz-Suche, Codierung und Fragen und Antworten mit a 2M-TOOKE-Kontextfenster und native Software-Use-RL, die entscheidet, wann Sie im Net durchsuchen, Code ausführen oder Instruments aufrufen sollen.
Architekturnote
Frühere GROK-Veröffentlichungen haben langkettige „Argumentation“ und kurze „Nicht-Bewertung“ -Tonantionen über separate Modelle teilgenommen. GROK-4-FAST Einheitlicher Gewichtsraum Reduziert Finish-to-Finish-Latenz und Token durch Lenkverhalten über Systemaufforderungen, was für Echtzeit-Anwendungen (Suche, Hilfsmittel und interaktive Codierung) related ist, wobei die Schaltmodelle sowohl Latenz als auch Kosten bestraft.
Such- und Agentenverwendung
GROK-4-FAST wurde Finish-to-Finish mit trainiert Werkzeugnutzungsverstärkungslernen und zeigt Zuwächse bei suchzentrierten Agenten-Benchmarks an: Browssecomp 44,9%Anwesend SimpleQa 95,0%Anwesend Reka Analysis 66,0%plus höhere Punktzahlen für chinesische Varianten (z. B., z. BrowseComp-Zh 51,2%). XAI zitiert auch personal Schlachtprüfung auf Larena, wo grok-4-fast-search (Codename „Menlo“) Rang 1 in der Sucharena mit 1163 Elo.und die Textvariante (Codename „Tahoe“) sitzt bei #8 in der Textarenaungefähr gleich mit grok-4-0709.
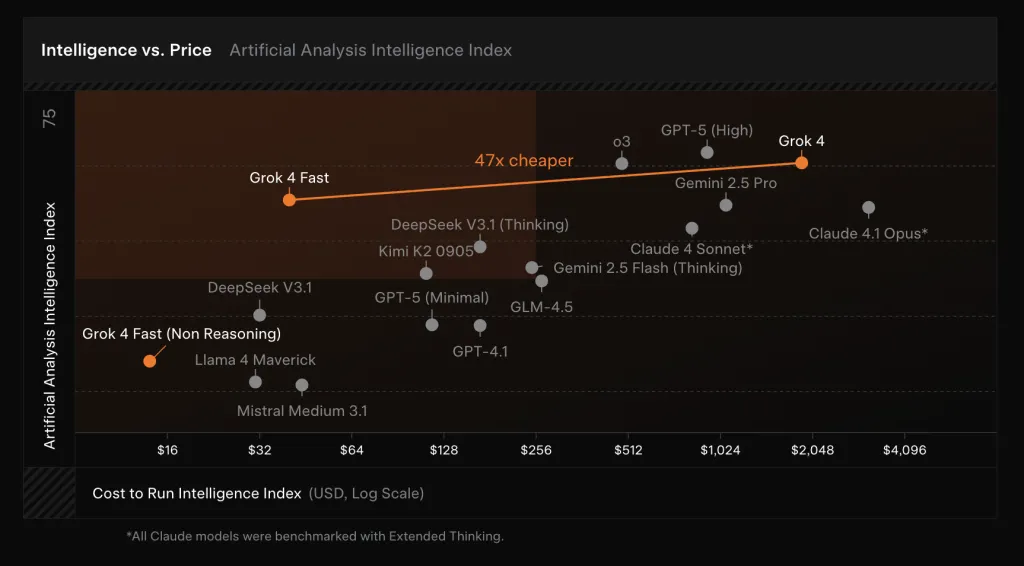
Leistungs- und Effizienzdeltas
Auf internen und öffentlichen Benchmarks, GROK-4-FAST-Pfosten Grenzklasse-Ergebnisse Während des Schneidens von Token -Nutzung. XAI -Berichte passieren@1 Ergebnisse von 92,0% (Aime 2025, keine Werkzeuge)Anwesend 93,3% (HMMT 2025, keine Werkzeuge)Anwesend 85,7% (GPQA Diamond)Und 80,0% (LivecodeBench Jan – Mai)Annäherung oder Matching GROK-4, aber verwenden ~ 40% weniger „Denken“ -Token durchschnittlich. Das Unternehmen rahmt dies als „Intelligenzdichte“ und beansprucht a ~ 98% Preissenkung, um die gleiche Benchmark-Leistung wie GROK-4 zu erreichen Wenn der untere Token-Zähler und die neue Preisgestaltung professional TOOKE kombiniert werden.
Einsatz und Preis
Das Modell ist im Allgemeinen für alle Benutzer zur Verfügung in grok’s Schnell Und Auto Modi über Net und Cell; Auto wählt GROK-4-Quick für schwierige Abfragen zur Verbesserung der Latenz, ohne Qualität zu verlieren, und-zum ersten Mal-zum ersten Mal-Kostenlose Benutzer Zugriff auf XAIs neueste Modellstufe. Für Entwickler exponiert XAI Zwei Skus–grok-4-fast-reasoning Und grok-4-fast-non-reasoning– sowohl mit 2m Kontext. Preisgestaltung (XAI -API) ist $ 0,20 / 1M Eingangs -Token (<128K)Anwesend $ 0,40 / 1m Eingangs -Token (≥ 128K)Anwesend $ 0,50 / 1 Mio. Ausgangstoken (<128K)Anwesend $ 1,00 / 1m Output -Token (≥ 128K)Und $ 0.05 / 1 Mio. Zwischeneingangs -Token.
5 Technische Imbissbuden:
- Einheitlicher Modell + 2m Kontext. GROK-4-FAST verwendet einen einzelnen Gewichtsraum für „Argumentation“ und „Nicht-Begrenzung“, ein prompt-stetter, mit einem 2.000.000-köpfigen Fenster über beide SKUs.
- Preisgestaltung für Skala. Die API -Preisgestaltung beginnt bei $ 0,20/m EingabeAnwesend $ 0,50/m Ausgabemit zwischengespeicherter Eingabe bei $ 0,05/m und höhere Raten nur über 128.000 Kontext.
- Effizienzansprüche. XAI berichtet ~40% weniger „denkende“ Token bei vergleichbarer Genauigkeit gegen GROK-4, die a ergibt ~ 98% niedrigerer Preis für die GROK-4-Leistung auf Grenz -Benchmarks.
- Benchmark -Profil. Gemeldet Cross@1: Aime-2025 92,0%Anwesend HMMT-2025 93,3%Anwesend GPQA-Diamond 85,7%Anwesend LivecodeBench (Jan. -Mai) 80,0%.
- Verwendung von Agenten/Suche. Nach dem Coaching mit Werkzeugnutzungs-RL; Positioniert zum Surfen/Such-Workflows mit dokumentierten Such-Agent-Metriken und Dwell-Such-Abrechnung in DOCS.

Zusammenfassung
GROK-4-schnelle Pakete GROK-4-Degree-Fähigkeit in ein einzelnes, prompt-vorgeschriebenes Modell mit einem 2-m-gepflegten Fenster, einem Werkzeugnutzungs-RL und einer Preisgestaltung, die für Such- und Agent-Workloads mit hohem Durchsatz abgestimmt ist. Frühe öffentliche Signale (LMARena #1 in der Suche, Wettbewerbstextplatzierung) entsprechen der Behauptung von XAI, ähnliche Genauigkeit unter Verwendung von ~ 40% weniger „Denken“ -Token, was zu niedrigeren Latenz- und Einheitskosten in der Produktion führt.
Schauen Sie sich das an Technische Particulars. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.