
Bild vom Autor
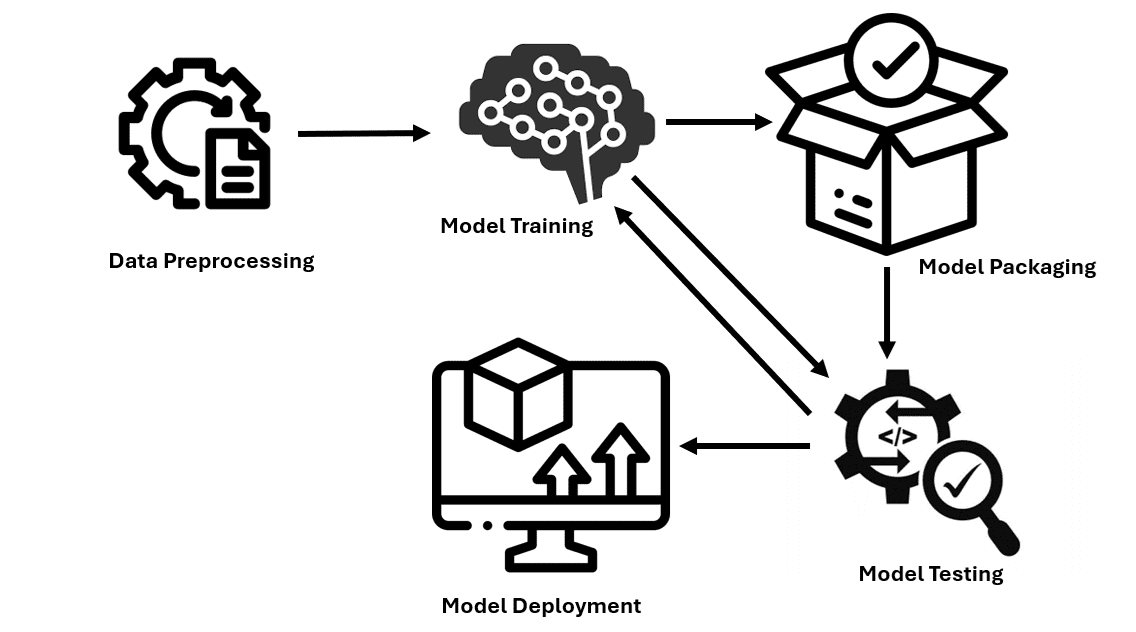
Unter Modellbereitstellung versteht man den Prozess, bei dem trainierte Modelle in praktische Anwendungen integriert werden. Dazu gehört die Definition der erforderlichen Umgebung, die Festlegung, wie Eingabedaten in das Modell eingeführt werden und welche Ausgabe erzeugt wird, sowie die Fähigkeit, neue Daten zu analysieren und relevante Vorhersagen oder Kategorisierungen bereitzustellen. Lassen Sie uns den Prozess der Bereitstellung von Modellen in der Produktion untersuchen.
Schritt 1: Datenvorverarbeitung
Behandeln Sie fehlende Werte, indem Sie sie mit Mittelwerten ersetzen oder die Zeilen/Spalten löschen. Stellen Sie sicher, dass kategoriale Variablen ebenfalls durch One-Scorching-Encoding oder Label-Encoding von qualitativen in quantitative Daten umgewandelt werden. Normalisieren und standardisieren Sie numerische Merkmale, um sie auf eine gemeinsame Skala zu bringen.
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
# Load your information
df = pd.read_csv('your_data.csv')
# Deal with lacking values
imputer_mean = SimpleImputer(technique='imply')
df('numeric_column') = imputer_mean.fit_transform(df(('numeric_column')))
# Encode categorical variables
one_hot_encoder = OneHotEncoder()
encoded_features = one_hot_encoder.fit_transform(df(('categorical_column'))).toarray()
encoded_df = pd.DataFrame(encoded_features, columns=one_hot_encoder.get_feature_names_out(('categorical_column')))
# Normalize and standardize numerical options
# Standardization (zero imply, unit variance)
scaler = StandardScaler()
df('standardized_column') = scaler.fit_transform(df(('numeric_column')))
# Normalization (scaling to a spread of (0, 1))
normalizer = MinMaxScaler()
df('normalized_column') = normalizer.fit_transform(df(('numeric_column')))Schritt 2: Modelltraining und -bewertung
Teilen Sie die Daten in zwei Gruppen auf: Trainingsdatensatz und Testdatensatz, um das Modell zu trainieren. Wählen Sie ein Modell aus und trainieren Sie es mit den verwendeten Daten. Durch die Feinabstimmung der Hyperparameter werden die leistungsstärksten Modelle für maschinelles Lernen ausgewählt. Das Modell wird mit verschiedenen Untergruppen der Daten auf seine Stabilität geprüft, um eine Kreuzvalidierung durchzuführen.
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
# Load your information
df = pd.read_csv('information.csv')
# Cut up information into coaching and testing units
X = df.drop(columns=('target_column'))
y = df('target_column')
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Hyperparameter tuning
param_grid = {
'n_estimators': (50, 100, 200),
'max_depth': (None, 10, 20, 30),
'min_samples_split': (2, 5, 10)
}
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1)
# Match the grid search to the info
grid_search.match(X_train, y_train)
# Get the perfect mannequin from the grid search
best_model = grid_search.best_estimator_
# Cross-validation to evaluate mannequin generalization and robustness
cv_scores = cross_val_score(best_model, X_train, y_train, cv=5, scoring='accuracy')
print(f"Cross-validation scores: {cv_scores}")
print(f"Imply cross-validation rating: {cv_scores.imply()}")Schritt 3: Modellverpackung
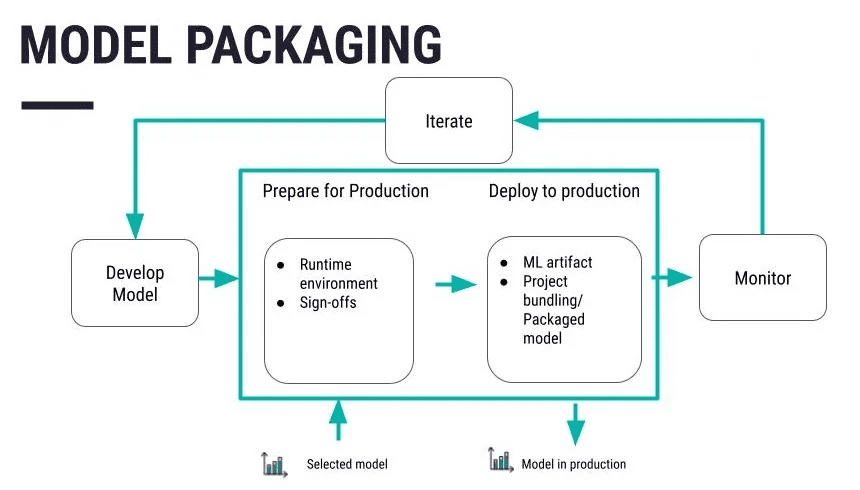
Quelle: https://data.dataiku.com/newest/mlops-o16n/structure/concept-model-packaging.html
Serialisieren Sie den Code in ein geeigneteres Format, das gespeichert oder an das andere System verteilt werden kann. Pickle ist eines der herkömmlichen Formate, gefolgt von den Formaten Joblib und ONNX, je nach den Anforderungen des Benutzers. Nachdem Sie Ihr Modell definiert und optimiert haben, speichern Sie es in einer Datei oder Datenbank. Plattformen wie Git sind auch praktisch, um die vorzunehmenden Änderungen und Modifikationen zu handhaben. Wenden Sie spezielle Maßnahmen wie die Verschlüsselung von Daten sowohl während der Speicherung als auch während der Übertragung an, damit die Daten für niemanden leicht zugänglich sind.
import joblib
joblib.dump(mannequin, 'mannequin.pkl')Legen Sie Ihr serialisiertes Modell in einen Container wie Docker. Dadurch wird es portierbar und der Transport von Machine-Studying-Modellen in verschiedene Umgebungen wird einfacher.
# Docker code
FROM python:3.8-slim
COPY mannequin.pkl /app/mannequin.pkl
COPY app.py /app/app.py
WORKDIR /app
RUN pip set up -r necessities.txt
CMD ("python", "app.py")Schritt 4: Einrichten der Umgebung für die Bereitstellung
Um Infrastruktur und Ressourcen für die Modellbereitstellung einzurichten, wird empfohlen, Cloud-Dienste wie AWS, Azure oder Google Cloud zu verwenden. Ändern Sie die erforderlichen Komponenten, die zum Hosten des Modells erforderlich sind, wie Server, Datenbanken und all das kann auf den richtigen Cloud-Infrastrukturdiensten der ausgewählten Cloud-Plattform erfolgen.
AWS: EC2-Instanz mit AWS CLI einrichten
aws ec2 run-instances
--image-id ami-0abcdef1234567890
--count 1
--instance-type t2.micro
--key-name MyKeyPair
--security-group-ids sg-0abcdef1234567890
--subnet-id subnet-0abcdef1234567890Azurblau: Virtuelle Maschine mit Azure CLI einrichten
az vm create
--resource-group myResourceGroup
--name myVM
--image UbuntuLTS
--admin-username azureuser
--generate-ssh-keysGoogle Cloud: Compute Engine-Instanz mit Google Cloud CLI einrichten
gcloud compute cases create my-instance
--zone=us-central1-a
--machine-type=e2-medium
--subnet=default
--network-tier=PREMIUM
--maintenance-policy=MIGRATE
--image=debian-9-stretch-v20200902
--image-project=debian-cloud
--boot-disk-size=10GB
--boot-disk-type=pd-standard
--boot-disk-device-name=my-instanceSchritt 5: Erstellen der Bereitstellungspipeline
Verwenden Sie beispielsweise Jenkins oder GitLab CI/CD, um den Schritt der Bereitstellung des Modells zu automatisieren. Entwerfen Sie eine Liste der auszuführenden Schritte, um den Bereitstellungsprozess effizienter zu gestalten, und verwenden Sie im Kontext von GitHub Actions eine Jenkinsfile- oder YAML-Konfiguration.
# Utilizing Jenkins for CI/CD pipeline
pipeline {
agent any
levels {
stage('Construct') {
steps {
sh 'python setup.py construct'
}
}
stage('Check') {
steps {
sh 'python -m unittest uncover'
}
}
stage('Deploy') {
steps {
sh 'docker construct -t mymodel:newest .'
sh 'docker run -d -p 5000:5000 mymodel:newest'
}
}
}
}Schritt 6: Modelltests
Führen Sie Exams durch, um sicherzustellen, dass alle Funktionen des Modells angemessen erfüllt werden. Anschließend werden die prognostizierten Beträge mit den Ergebnissen verglichen, die dieses Modell liefern soll. Überprüfen Sie die Generalisierungsfähigkeit des Modells, um festzustellen, ob es bei anderen neuen Daten intestine funktioniert. Wählen Sie zum Vergleich mit den Beispieldaten die richtigen Bewertungskriterien – Genauigkeit, Präzision, Rückruf.
# Import mandatory libraries
from sklearn.metrics import accuracy_score, precision_score, recall_score
# Load your take a look at information
test_df = pd.read_csv('your_test_data.csv')
X_test = test_df.drop(columns=('target_column'))
y_test = test_df('target_column')
# Predict outcomes on the take a look at set
y_pred_test = best_model.predict(X_test)
# Consider efficiency metrics
test_accuracy = accuracy_score(y_test, y_pred_test)
test_precision = precision_score(y_test, y_pred_test, common="weighted")
test_recall = recall_score(y_test, y_pred_test, common="weighted")
# Print efficiency metrics
print(f"Check Set Accuracy: {test_accuracy}")
print(f"Check Set Precision: {test_precision}")
print(f"Check Set Recall: {test_recall}")Schritt 7: Überwachung und Wartung
Stellen Sie mithilfe von Instruments wie AWS CloudWatch, Azure Monitor oder Google Cloud Monitoring sicher, dass das Modell keine Fehler enthält. Dazu muss aufgezeigt werden, wie das in Zukunft bereitgestellte Modell geändert werden muss, um es noch besser zu machen.
AWS CloudWatch
aws cloudwatch put-metric-alarm --alarm-name CPUAlarm --metric-name CPUUtilization
--namespace AWS/EC2 --statistic Common --period 300 --threshold 70
--comparison-operator GreaterThanThreshold --dimensions "Identify=InstanceId,Worth=i-1234567890abcdef0"
--evaluation-periods 2 --alarm-actions arn:aws:sns:us-east-1:123456789012:my-sns-topic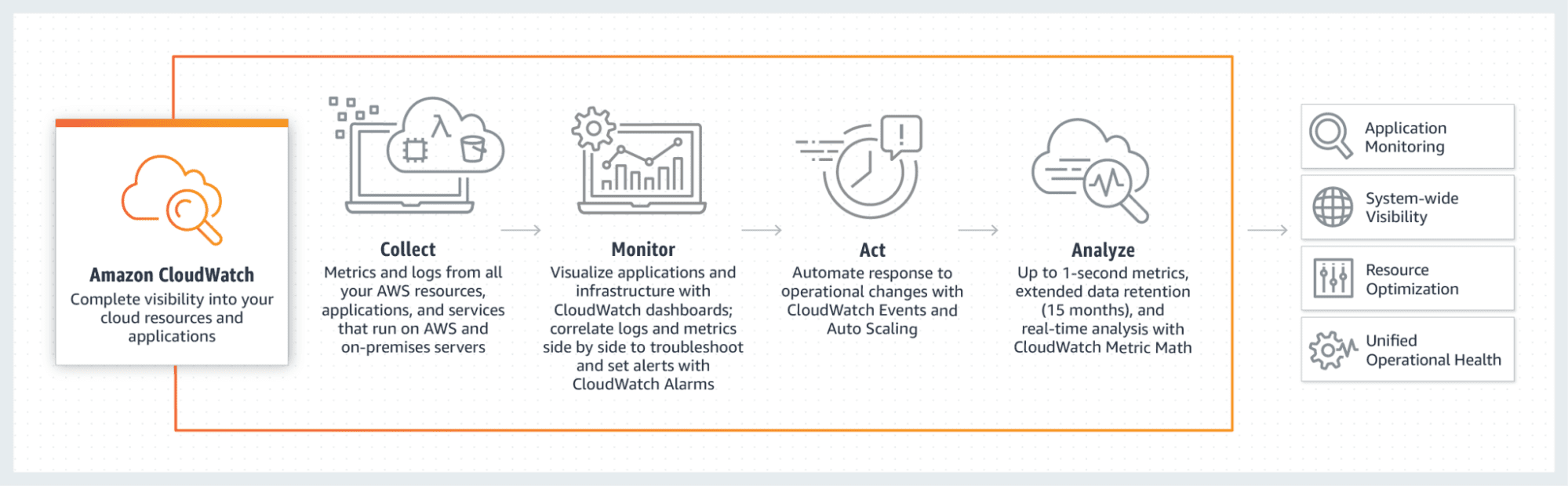
Quelle: https://blogs.vmware.com/administration/2021/03/cloud-services-aws-cloudwatch-azure-monitor.html
Azure Monitor
az monitor metrics alert create --name 'CPU Alert' --resource-group myResourceGroup
--scopes /subscriptions/{subscription-id}/resourceGroups/{resource-group-name}/suppliers/Microsoft.Compute/virtualMachines/{vm-name}
--condition "avg Share CPU > 80" --description 'Alert if CPU utilization exceeds 80%'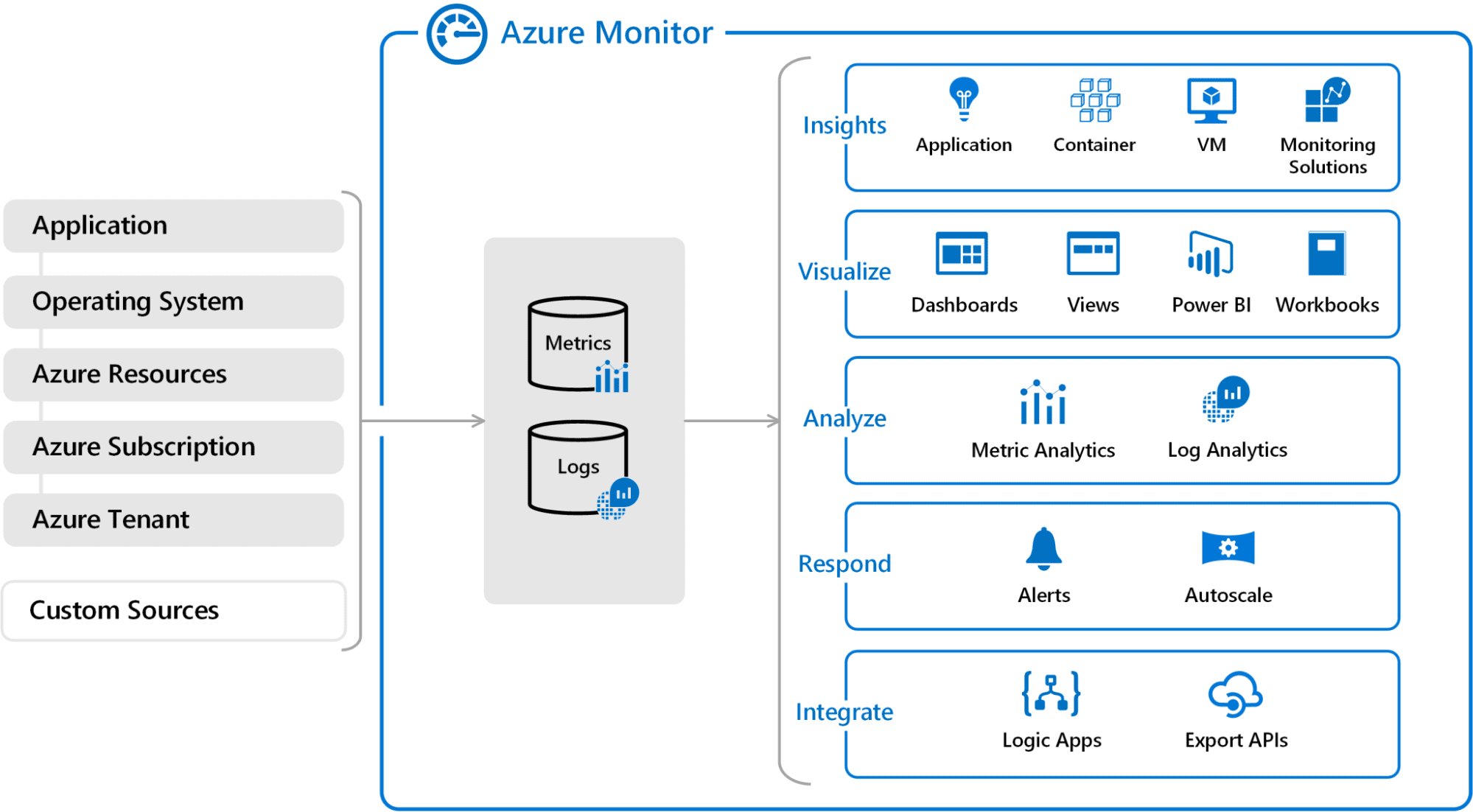
Quelle: https://blogs.vmware.com/administration/2021/03/cloud-services-aws-cloudwatch-azure-monitor.html
Einpacken
Die in diesem Tutorial beschriebenen Strategien stellen sicher, dass Sie über die wichtigsten Schritte verfügen, die zum Bereitstellen von Machine-Studying-Modellen erforderlich sind. Wenn Sie die oben genannten Schritte befolgen, können Sie die trainierten Modelle für den praxisbezogenen Einsatz nutzbar und einfach bereitstellen. Vom Erstellen des Modells bis zum Konfigurieren und Validieren der Struktur wissen Sie jetzt, wie Sie Ihre Machine-Studying-Bemühungen vom Hypothetischen in die Praxis umsetzen.
Jayita Gulati ist eine Enthusiastin für maschinelles Lernen und technische Autorin, die von ihrer Leidenschaft für die Erstellung von Modellen für maschinelles Lernen angetrieben wird. Sie hat einen Grasp-Abschluss in Informatik von der Universität Liverpool.