
Die KI-Entwicklung schreitet rasant voran. Fortschritte in der {Hardware}- und Softwareoptimierung sowie bessere Datensätze ermöglichen nun, dass Trainingsläufe, die früher Wochen dauerten, in wenigen Stunden abgeschlossen werden konnten. Ein aktuelles Replace des KI-Forschers Andrej Karpathy zeigt diesen Wandel deutlich: Das Open-Supply-Projekt Nanochat kann jetzt ein GPT-2-Modell auf einem einzelnen Knoten mit 8× NVIDIA H100-GPUs in etwa zwei Stunden trainieren, im Gegensatz zu drei vor einem Monat.
Noch auffälliger ist, dass KI-Agenten innerhalb von 12 Stunden 110 Codeänderungen vorgenommen haben und so den Validierungsverlust verbessert haben, ohne das Coaching zu verlangsamen. In diesem Artikel untersuchen wir, wie selbstoptimierende KI-Systeme die Artwork und Weise, wie KI-Forschung und Modelltraining durchgeführt werden, verändern könnten.

Was ist Nanochat?
Andrej Karpathy hat Nanochat entwickelt, um ein grundlegendes, vollständiges Sprachmodell-Trainingssystem bereitzustellen, das als Finish-to-Finish-Lösung dient. Ziel des Projekts ist es zu zeigen, wie Entwickler ein vollständiges System im ChatGPT-Stil aufbauen können, indem sie eine kleine und verständliche Codebasis als Grundlage verwenden. Nanochat bietet durch sein Design zwei Hauptvorteile, da es die Notwendigkeit mehrerer komplexer Abhängigkeiten eliminiert und gleichzeitig eine vollständige Systemtransparenz gewährleistet.
Das Framework umfasst den gesamten Lebenszyklus des Trainings und der Bereitstellung eines Sprachmodells:
- Tokenizer-Schulung
- Vortraining des Basismodells
- Mitte des Trainings mit Konversationsdatensätzen
- Beaufsichtigte Feinabstimmung
- Optimierung des Reinforcement-Lernens
- Inferenz- und Chat-Schnittstelle
Mit einer Gesamtcodelänge von 8000 Zeilen stellt die gesamte Pipeline eine der einfachsten Open-Supply-Lösungen dar LLM Trainingssysteme, auf die heute zugegriffen werden kann.
Wie funktioniert das AutoResearch-System?
Das AutoResearch-Framework etabliert eine Forschungsschleife, die es KI-Agenten ermöglicht, die Codebasis durch ihren fortlaufenden Check- und Verifizierungsprozess zu entwickeln. Das System fungiert als automatischer Forschungsingenieur, der Experimente durchführt, um seine Leistung zu untersuchen.
Der Workflow umfasst die folgenden Schritte:
- Repository-Initialisierung
Der Agent startet mit einem vorhandenen Projekt-Repository (z. B. Nanochat). Das System erstellt eine experimentelle Umgebung, die die vollständige Codebasis durch einen Prozess des Codebasis-Klonens umfasst.
- Zweigerstellung
Der Agent richtet einen neuen Testzweig ein, der es ihm ermöglicht, Exams zu Änderungen durchzuführen, ohne das Risiko einer Störung der primären Codebasis einzugehen.
- Vorschlag zur Codeänderung
Der Agent analysiert das Repository und schlägt durch seine Analysearbeit, die vier Hauptkomponenten umfasst, mögliche Verbesserungen vor.
- Optimierungen der Trainingsschleife
- Verbesserungen bei der Vorverarbeitung von Datensätzen
- Hyperparameter-Anpassungen
- Optimierungen der Modellarchitektur
- Automatisierte Experimentausführung
Das System führt die automatische Ausführung von geändertem Code durch, um Modellschulungs- und Testaktivitäten zu unterstützen. Es zeichnet Metriken auf wie:
- Validierungsverlust
- Trainingsgeschwindigkeit
- Ressourcennutzung
- Leistungsbewertung
Das System führt einen direkten Vergleich zwischen den aktuellen Ergebnissen und der ermittelten Basisleistung des Modells durch. Die neue Model weist gegenüber der Vorgängerversion eine überlegene Leistung auf, was als System-Improve gilt.
- Automatisierte Zusammenführung
Das System führt die automatische Zusammenführung validierter Verbesserungen im Hauptcodezweig durch.
- Kontinuierliche Forschungsschleife
Der Agent richtet einen ewigen Forschungszyklus ein, der die Entwicklung eines automatisierten Forschungssystems ermöglicht, das sich durch dauerhaften Betrieb selbst verbessert.
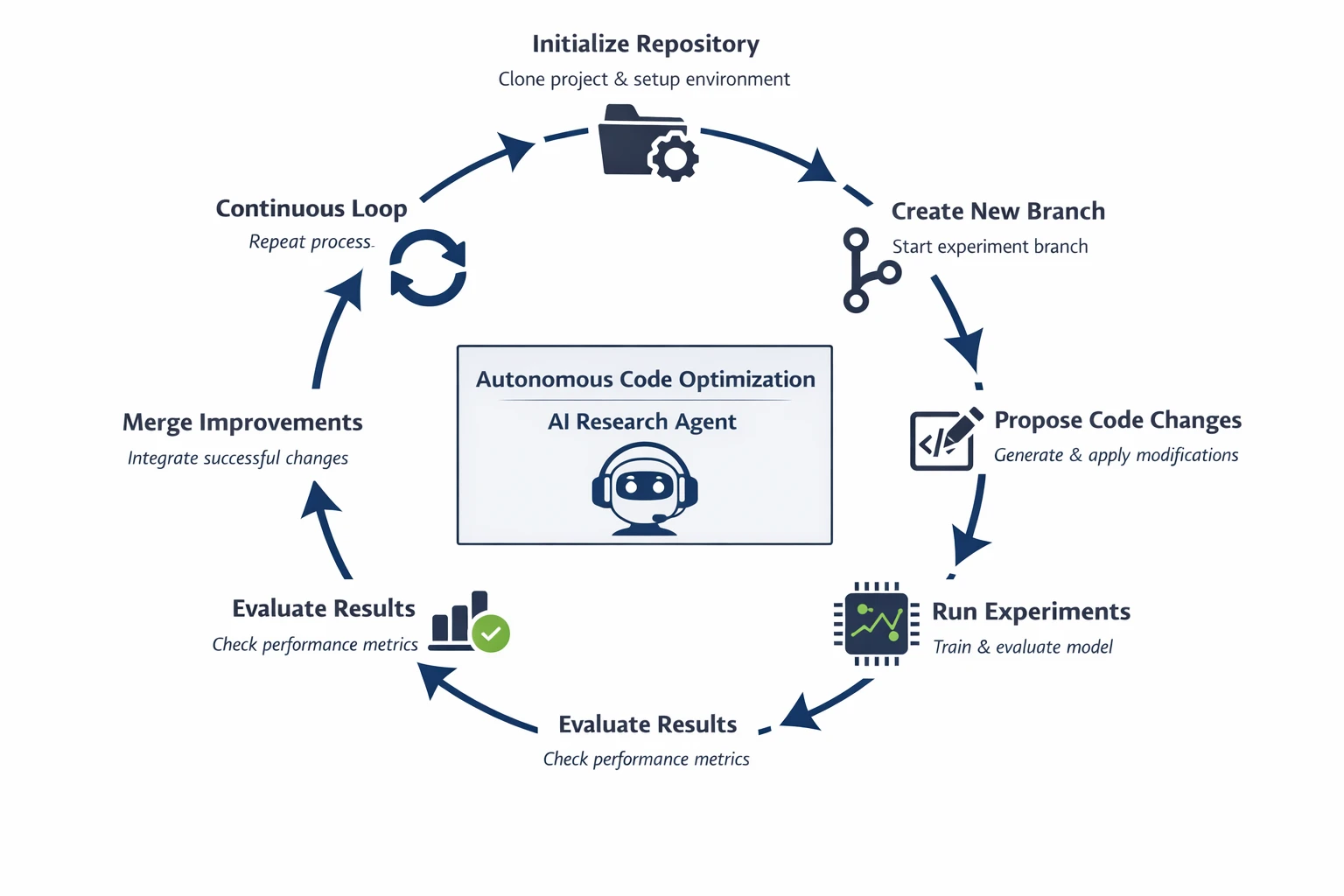
Durch seine autonome Betriebsweise, die keinen menschlichen Kontakt erfordert, kann das System mehrere Dutzende bis Hunderte von Codeverbesserungen erzeugen.
Einrichtung und Set up
Das Framework kann so eingerichtet werden, dass autonome Forschungsexperimente lokal durchgeführt werden.
- Klonen Sie das Repository
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch- Einrichten der Umgebung
python -m venv venv
supply venv/bin/activate- Installieren Sie die Abhängigkeiten
pip set up -r necessities.txt - Konfigurieren Sie die API-Schlüssel
export OPENAI_API_KEY="your_api_key_here" - Führen Sie den Autonomous Agent aus
python primary.py Der 2-stündige GPT-2-Trainingsdurchbruch
Das Nanochat-Projekt erzielte seine wichtigste jüngste Errungenschaft durch die Erreichung einer schnelleren Geschwindigkeit GPT-2 Modellschulungszeiten. Die folgenden Informationen zeigen die Trainingszeit und die {Hardware}, die zur Erledigung der Aufgabe verwendet wurden:
- Trainingszeit: ~3 Stunden
- {Hardware}: 8× NVIDIA H100 GPUs
Die Einarbeitungszeit hat sich bei gleichem {Hardware}-Setup auf etwa zwei Stunden verkürzt. Die Verbesserung scheint geringfügig zu sein, aber die maschinelle Lernforschung profitiert von schnelleren Trainingszyklen, da sie es Forschern ermöglicht, Experimente schneller durchzuführen.
Forscher können mehr Ideen testen, schneller iterieren und Verbesserungen früher entdecken. Als wesentliche Bestandteile, die diese Leistung ermöglichten, dienten folgende Optimierungen:
1. Wechsel zum NVIDIA ClimbMix-Datensatz
Die bedeutendste Leistungssteigerung resultierte aus der Änderung des Trainingsdatensatzes. Frühere Forschungsstudien analysierten die folgenden Datensätze:
Die Trainingsexperimente zeigten Trainingsregressionen, wenn diese Datensätze verwendet wurden.
Nanochat erzielte bessere Ergebnisse, als es mit der Verwendung des NVIDIA ClimbMix-Datensatzes begann, da weniger Optimierungsarbeiten erforderlich waren. Die Studie zeigt eine entscheidende Lektion über die KI-Entwicklung. Die Datenqualität kann genauso wichtig sein wie die Modellarchitektur.
Die richtige Auswahl des Datensatzes führt zu erheblichen Fortschritten sowohl bei der Trainingseffizienz als auch bei den Modelltestergebnissen.
2. FP8 Präzisionstraining
Die zweite Optimierungsleistung ermöglichte die Ausführung des FP8-Präzisionstrainings innerhalb des Programs. FP8 (8-Bit-Gleitkomma) ermöglicht es GPUs, Berechnungen schneller durchzuführen und gleichzeitig eine ausreichende Genauigkeit für das Coaching neuronaler Netzwerke beizubehalten.
- Die Vorteile der FP8-Schulung bringen den Benutzern folgende Vorteile:
- Das System führt Tensorberechnungen mit höheren Geschwindigkeiten durch.
- Das System benötigt für seinen Betrieb weniger Speicherbandbreite.
- Das System erzielt eine bessere Ausgabeleistung seiner Grafikverarbeitungseinheit.
- Das System bietet Bildungseinrichtungen günstigere Ausbildungskosten.
Die effektivste Methode zur Leistungssteigerung bei umfangreichen KI-Workloads besteht in der Auswahl von Präzisionsstufen, die optimale Ergebnisse liefern.
3. Schulung der Pipeline-Optimierung
Die Trainingspipeline für Nanochat erhielt über die Datensatzänderungen und die FP8-Optimierung hinaus mehrere Verbesserungen. Das System erhielt mehrere Upgrades, darunter bessere Datenladepipelines und optimierte Trainingsschleifen sowie eine verbesserte GPU-Auslastung und eine verfeinerte Stapelplanung.
Die Kombination kleiner Leistungsverbesserungen aus jeder einzelnen Optimierung führte zu einer beobachtbaren Verkürzung der Trainingsdauer.
KI-Agenten verbessern jetzt Nanochat
Das Nanochat-Ökosystem hat seinen aufregendsten Punkt erreicht, da KI-Agenten daran arbeiten, die Projektentwicklung durch automatische Projekt-Upgrades zu verbessern. Karpathy hat ein Testsystem entwickelt, das es KI-Agenten ermöglicht, die Codebasis durch automatisierte Exams zu entwickeln, anstatt manuelle Exams für Verbesserungen durchzuführen.
Der Workflow läuft über die folgenden grundlegenden Schritte ab:
- Der Agent richtet einen neuen Function-Zweig ein.
- Der Agent schlägt Änderungen und Leistungsverbesserungen vor.
- Das System führt Experimente automatisiert durch.
- Das System führt Aktualisierungen zusammen, wenn die Änderungen zu besseren Ergebnissen führen.
Das System generierte seine Ausgabe in 12 Stunden, darunter:
- 110 Codeänderungen
- Das System verringerte den Validierungsverlust 0,862415 bis 0,858039
- Das System behielt die vorhandene Trainingszeit bei
Das System etabliert einen fortlaufenden Testprozess, der eine schnelle Umsetzung von Testergebnissen ermöglicht, die zu System-Upgrades führen. Das System fungiert als Forschungseinheit, die an ihrem eigenen Entwicklungsprozess arbeitet.
Die Zukunft der Open-Supply-KI
Nanochat ist auch Teil einer breiteren Bewegung hin zu einer Open-Supply-KI-Infrastruktur. Entwickler aus verschiedenen Ländern erstellen und verbessern durch ihre gemeinsamen Bemühungen KI-Systeme, die nicht von großen Unternehmenslabors abhängig sind. Open-Supply-LLM Projekte bieten mehrere Vorteile:
- Transparenz bei der KI-Entwicklung
- Group-Zusammenarbeit ermöglicht schnellere Innovationen
- neuen Forschern fällt der Einstieg in das Fachgebiet leichter
Die bevorstehenden {Hardware}-Fortschritte und Verbesserungen der Schulungspipeline werden es kleinen Groups ermöglichen, mit den Fähigkeiten großer KI-Labore mitzuhalten.
Das KI-Ökosystem wird aufgrund dieser Entwicklung eine Explosion an Kreativität und Experimentierfreudigkeit erleben.
Abschluss
Die neueste Errungenschaft von Nanochat beweist, dass die KI-Entwicklung ein beschleunigtes Fortschrittstempo erreicht hat. Die Fähigkeit, ein GPT-2-Fähigkeitsmodell innerhalb von zwei Stunden mit aktueller Computertechnologie zu trainieren, gilt als herausragende Leistung.
Der wichtigste technologische Fortschritt ergibt sich aus der Entwicklung von KI-Agenten die über die Fähigkeit verfügen, Systemverbesserungen ohne menschliches Zutun durchzuführen. Autonome Forschungsschleifen, die jetzt in ihrem aktuellen Zustand existieren, werden es Forschern ermöglichen, Forschungsprogramme zu entwickeln, die erhebliche Ergebnisse liefern.
Häufig gestellte Fragen
A. Nanochat ist ein Open-Supply-Projekt von Andrej Karpathy, das eine vollständige Finish-to-Finish-Pipeline für das Coaching und die Bereitstellung eines Sprachmodells im ChatGPT-Stil demonstriert.
A. Nanochat kann ein GPT-2-Stage-Modell in etwa zwei Stunden mit einem einzelnen Knoten mit 8 NVIDIA H100-GPUs trainieren.
A. Autonome KI-Agenten testen Codeänderungen, führen Experimente durch und führen Verbesserungen automatisch zusammen, wodurch über 100 Optimierungen generiert und gleichzeitig Validierungsverluste reduziert werden.
Information Science Trainee bei Analytics Vidhya
Derzeit arbeite ich als Information Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen.
Mit fundierten Kenntnissen in den Bereichen Informatik, Softwareentwicklung und Datenanalyse setze ich KI leidenschaftlich ein, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen.
📩 Du kannst mich auch erreichen unter (e mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.