
Google hat seine Gemini-Modellfamilie mit der Veröffentlichung von erweitert Zwillinge Einbettung 2. Dieses Modell der zweiten Era löst das Nur-Textual content-Modell ab gemini-embedding-001 und wurde speziell entwickelt, um die Herausforderungen bei der hochdimensionalen Speicherung und dem modalübergreifenden Abruf zu bewältigen, mit denen KI-Entwickler im produktionstauglichen Bau konfrontiert sind Retrieval-Augmented Era (RAG) Systeme. Der Zwillinge Einbettung 2 Die Veröffentlichung markiert einen bedeutenden technischen Wandel in der Architektur von Einbettungsmodellen, weg von modalitätsspezifischen Pipelines hin zu einem einheitlichen, nativ multimodalen latenten Raum.
Native Multimodalität und verschachtelte Eingaben
Der wichtigste architektonische Fortschritt in Gemini Embedding 2 ist seine Fähigkeit zur Kartierung fünf verschiedene Medientypen—Textual content, Bild, Video, Audio und PDF– in einen einzigen, hochdimensionalen Vektorraum. Dadurch entfällt der Bedarf an komplexen Pipelines, die bisher separate Modelle für verschiedene Datentypen erforderten, wie etwa CLIP für Bilder und BERT-basierte Modelle für Textual content.
Das Modell unterstützt verschachtelte Eingängewodurch Entwickler verschiedene Modalitäten in einer einzigen Einbettungsanfrage kombinieren können. Dies ist besonders related für Anwendungsfälle, in denen Textual content allein keinen ausreichenden Kontext bietet. Die technischen Grenzen für diese Eingaben sind wie folgt definiert:
- Textual content: Bis zu 8.192 Token professional Anfrage.
- Bilder: Bis zu 6 Bilder (PNG, JPEG, WebP, HEIC/HEIF).
- Video: Bis zu 120 Sekunden Video (MP4, MOV usw.).
- Audio: Bis zu 80 Sekunden natives Audio (MP3, WAV usw.), ohne dass ein separater Transkriptionsschritt erforderlich ist.
- Unterlagen: Bis zu 6 Seiten PDF-Dateien.
Durch die native Verarbeitung dieser Eingaben erfasst Gemini Embedding 2 die semantischen Beziehungen zwischen einem visuellen Body in einem Video und dem gesprochenen Dialog in einer Audiospur und projiziert sie als einen einzelnen Vektor, der mit Textabfragen mithilfe von Standardentfernungsmetriken wie verglichen werden kann Kosinusähnlichkeit.
Effizienz durch Matryoshka Illustration Studying (MRL)
Speicher- und Rechenkosten sind oft die größten Engpässe bei der groß angelegten Vektorsuche. Um dies zu mildern, implementiert Gemini Embedding 2 Matroschka-Repräsentationslernen (MRL).
Normal-Einbettungsmodelle verteilen semantische Informationen gleichmäßig über alle Dimensionen. Wenn ein Entwickler einen Vektor mit 3.072 Dimensionen auf 768 Dimensionen kürzt, sinkt die Genauigkeit normalerweise, weil die Informationen verloren gehen. Im Gegensatz dazu ist Gemini Embedding 2 darauf trainiert, die kritischsten semantischen Informationen in die frühesten Dimensionen des Vektors zu packen.
Das Modell ist standardmäßig auf 3.072 DimensionenAber Das Google-Group hat drei spezifische Ebenen für den Produktionseinsatz optimiert:
- 3.072: Höchste Präzision für komplexe rechtliche, medizinische oder technische Datensätze.
- 1.536: Ein Gleichgewicht zwischen Leistung und Speichereffizienz.
- 768: Optimiert für den Abruf mit geringer Latenz und reduziertem Speicherbedarf.
Matroschka-Repräsentationslernen (MRL) ermöglicht eine „Quick-Itemizing“-Architektur. Ein System kann mithilfe der 768-dimensionalen Untervektoren eine grobe Hochgeschwindigkeitssuche über Millionen von Elementen durchführen und dann mithilfe der vollständigen 3.072-dimensionalen Einbettungen eine präzise Neuordnung der High-Ergebnisse durchführen. Dies reduziert den Rechenaufwand der anfänglichen Abrufphase, ohne die endgültige Genauigkeit der RAG-Pipeline zu beeinträchtigen.
Benchmarking: MTEB und Lengthy-Context Retrieval
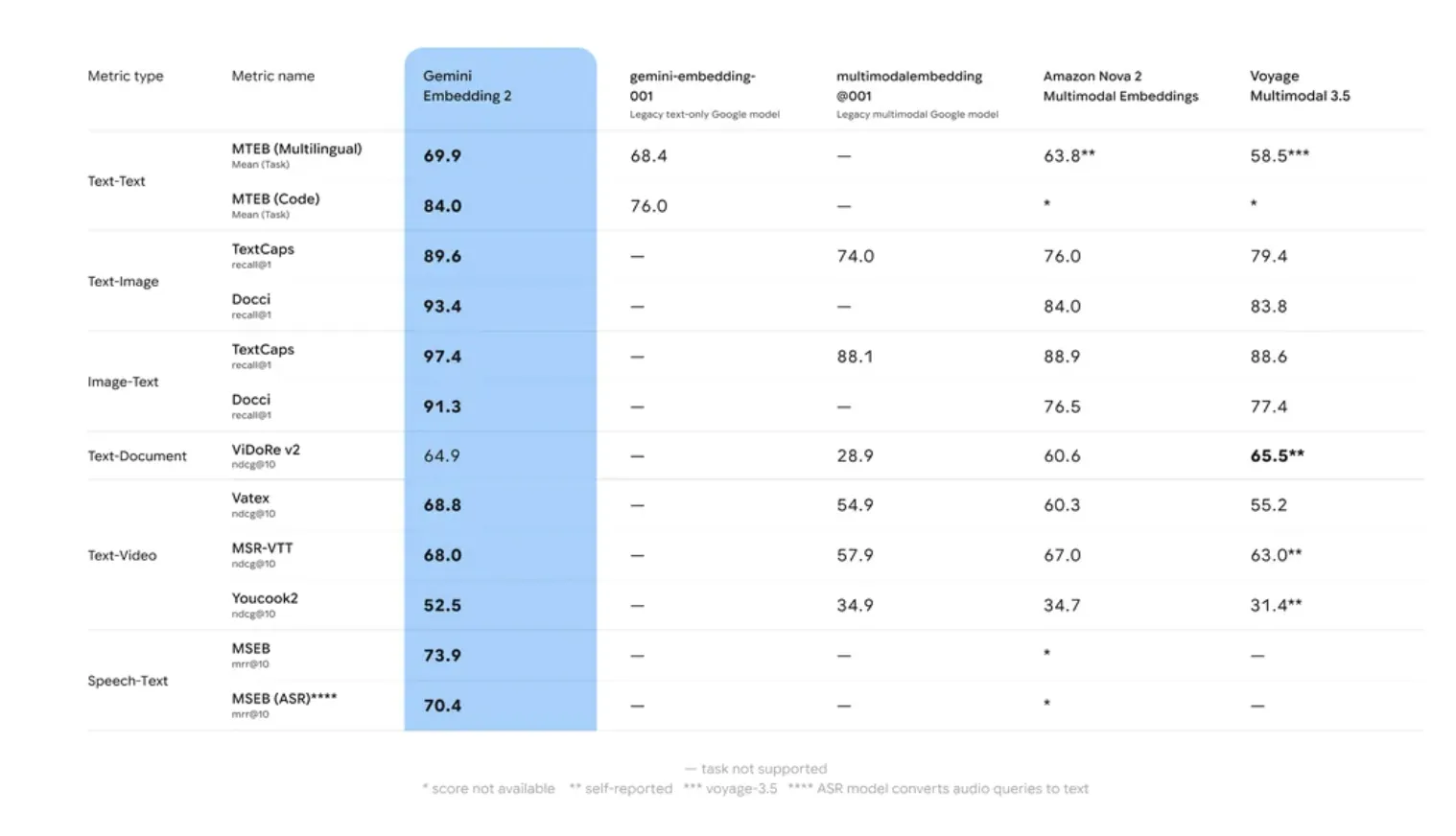
Interne Bewertung und Leistung von Google AI auf der Large Textual content Embedding Benchmark (MTEB) weisen darauf hin, dass Gemini Embedding 2 seinen Vorgänger übertrifft zwei spezifische Bereiche: Abrufgenauigkeit Und Robustheit gegenüber Domänenverschiebungen.
Viele Einbettungsmodelle leiden unter „Domänendrift“, bei dem die Genauigkeit abnimmt, wenn von generischen Trainingsdaten (wie Wikipedia) zu spezialisierten Domänen (wie proprietären Codebasen) gewechselt wird. Gemini Embedding 2 nutzte einen mehrstufigen Trainingsprozess mit verschiedenen Datensätzen, um eine höhere Zero-Shot-Leistung bei speziellen Aufgaben sicherzustellen.
Die des Modells 8.192-Token-Fenster ist eine kritische Spezifikation für RAG. Es ermöglicht die Einbettung größerer Textblöcke, wodurch der Kontext erhalten bleibt, der zum Auflösen von Koreferenzen und weitreichenden Abhängigkeiten innerhalb eines Dokuments erforderlich ist. Dies verringert die Wahrscheinlichkeit einer „Kontextfragmentierung“, einem häufigen Drawback, bei dem einem abgerufenen Block die Informationen fehlen, die das LLM benötigt, um eine kohärente Antwort zu generieren.
Wichtige Erkenntnisse
- Native Multimodalität: Gemini Embedding 2 unterstützt fünf verschiedene Medientypen:Textual content, Bild, Video, Audio und PDF– innerhalb eines einheitlichen Vektorraums. Dies ermöglicht verschachtelte Eingänge (z. B. ein Bild kombiniert mit einer Textbeschriftung), das als einzelne Einbettung ohne separate Modellpipelines verarbeitet werden soll.
- Matroschka-Repräsentationslernen (MRL): Das Modell ist so konzipiert, dass es die kritischsten semantischen Informationen in den frühen Dimensionen eines Vektors speichert. Während es standardmäßig ist 3.072 Dimensionenunterstützt es eine effiziente Kürzung von 1.536 oder 768 Abmessungen mit minimalem Genauigkeitsverlust, wodurch die Lagerkosten gesenkt und die Bereitstellungsgeschwindigkeit erhöht werden.
- Erweiterter Kontext und Leistung: Das Modell verfügt über eine 8.192-Token-Eingabefensterwas größere Textblöcke in RAG-Pipelines ermöglicht. Es zeigt deutliche Leistungsverbesserungen gegenüber dem Large Textual content Embedding Benchmark (MTEB)insbesondere in Bezug auf die Genauigkeit des Abrufs und den Umgang mit speziellen Bereichen wie Code oder technischer Dokumentation.
- Aufgabenspezifische Optimierung: Entwickler können verwenden
task_typeParameter (z.BRETRIEVAL_QUERY,RETRIEVAL_DOCUMENToderCLASSIFICATION), um Hinweise zum Modell bereitzustellen. Dadurch werden die mathematischen Eigenschaften des Vektors für die spezifische Operation optimiert und die „Trefferquote“ bei der semantischen Suche verbessert.
Kasse Technische Particularsin der öffentlichen Vorschau über das Gemini-API Und Vertex-KI. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.