
In diesem Artikel erfahren Sie, was kleine Sprachmodelle sind, warum sie im Jahr 2026 wichtig sind und wie Sie sie effektiv in realen Produktionssystemen einsetzen.
Zu den Themen, die wir behandeln werden, gehören:
- Was zeichnet kleine Sprachmodelle aus und wie unterscheiden sie sich von großen Sprachmodellen?
- Die Kosten-, Latenz- und Datenschutzvorteile, die die Einführung von SLM vorantreiben.
- Praktische Anwendungsfälle und ein klarer Weg zum Einstieg.
Kommen wir gleich zur Sache.
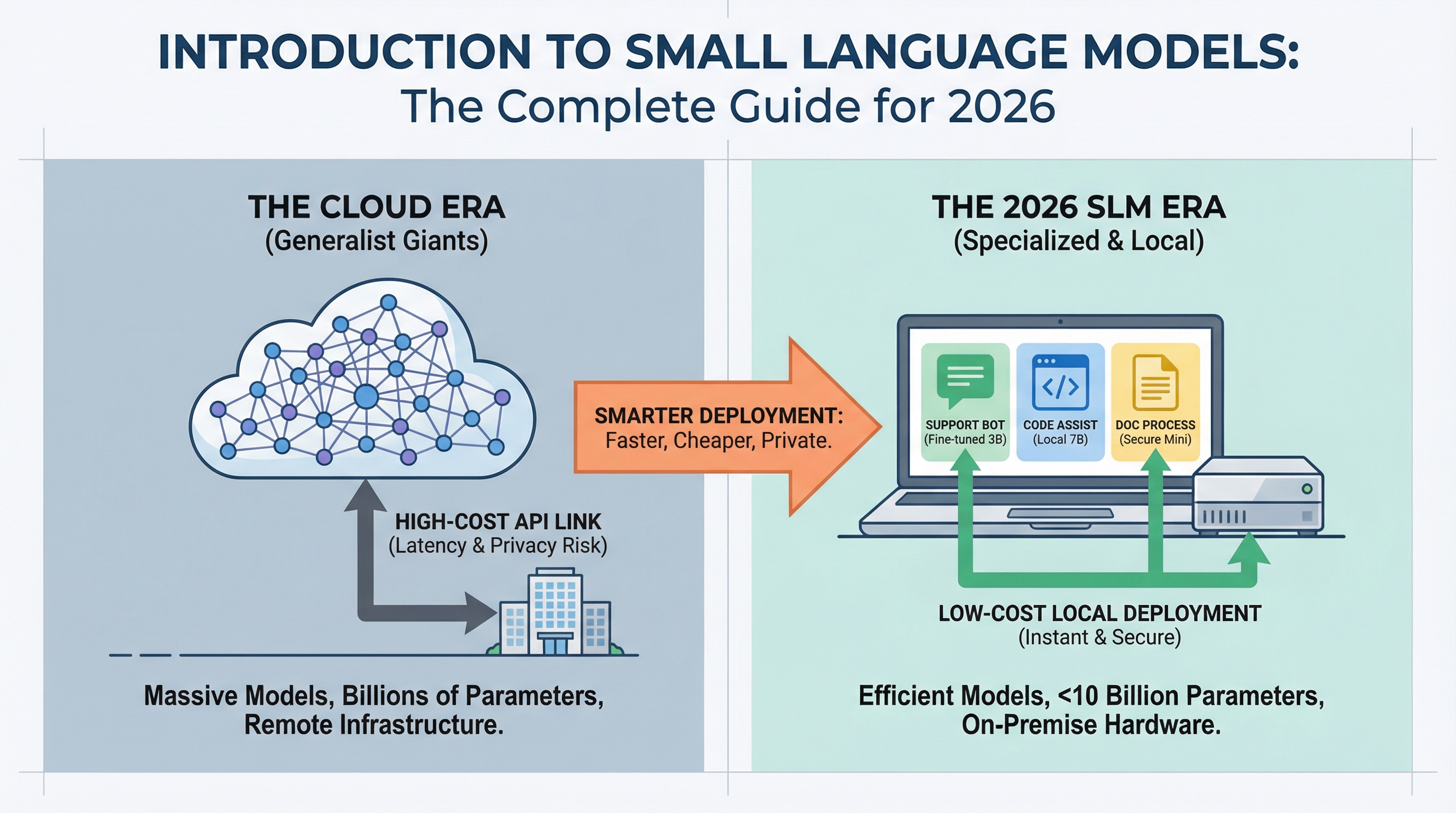
Einführung in kleine Sprachmodelle: Der vollständige Leitfaden für 2026
Bild vom Autor
Einführung
Der KI-Einsatz verändert sich. Während sich die Schlagzeilen auf immer größere Sprachmodelle konzentrieren, die neue Maßstäbe setzen, stellen Produktionsteams fest, dass kleinere Modelle die meisten alltäglichen Aufgaben zu einem Bruchteil der Kosten bewältigen können.
Wenn Sie einen Chatbot bereitgestellt, einen Code-Assistenten erstellt oder die Dokumentenverarbeitung automatisiert haben, haben Sie wahrscheinlich für Cloud-API-Aufrufe an Modelle mit Hunderten Milliarden Parametern bezahlt. Aber die meisten Praktiker, die im Jahr 2026 arbeiten, stellen fest, dass für 80 % der Produktionsanwendungsfälle ein Modell, das Sie auf einem Laptop computer ausführen können, genauso intestine funktioniert und 95 % weniger kostet. Wenn Sie direkt in die praktischen Optionen einsteigen möchten, finden Sie unseren Leitfaden dazu Die 7 besten kleinen Sprachmodelle, die Sie auf einem Laptop computer ausführen können behandelt die besten heute verfügbaren Modelle und wie man sie vor Ort zum Laufen bringt.
Möglich machen dies kleine Sprachmodelle (SLMs). In diesem Leitfaden erfahren Sie, was sie sind, wann Sie sie verwenden und wie sie die Wirtschaftlichkeit des KI-Einsatzes verändern.
Was sind kleine Sprachmodelle?
Kleine Sprachmodelle sind Sprachmodelle mit weniger als 10 Milliarden Parametern, normalerweise im Bereich von 1 Milliarde bis 7 Milliarden.
Parameter sind die „Knöpfe und Regler“ innerhalb eines neuronalen Netzwerks. Jeder Parameter ist ein numerischer Wert, den das Modell verwendet, um Eingabetext in Vorhersagen darüber umzuwandeln, was als nächstes kommt. Wenn Sie sehen „GPT-4 hat über 1 Billion Parameter“, das bedeutet, dass das Modell über 1 Billion dieser einstellbaren Werte verfügt, die zusammenarbeiten, um Sprache zu verstehen und zu generieren. Mehr Parameter bedeuten im Allgemeinen mehr Kapazität zum Erlernen von Mustern, aber sie bedeuten auch mehr Rechenleistung, Speicher und Betriebskosten.
Der Skalenunterschied ist erheblich. GPT-4 hat über 1 Billion Parameter, Claude Opus hat Hunderte von Milliarden und sogar Lama 3.1 70B gilt als „groß“. SLMs arbeiten in einem völlig anderen Maßstab.
Aber „klein“ bedeutet nicht „einfach“. Moderne SLMs mögen Phi-3 Mini (3.8B-Parameter), Llama 3.2 3B und Mistral 7B liefern bei vielen Aufgaben eine Leistung, die mit Modellen, die zehnmal so groß sind, mithalten kann. Der eigentliche Unterschied ist die Spezialisierung.
Während große Sprachmodelle zu Generalisten mit umfassendem Wissen über jedes erdenkliche Thema ausgebildet werden, zeichnen sich SLMs durch eine Feinabstimmung auf bestimmte Domänen aus. Ein auf Kundensupportgesprächen geschultes 3B-Modell übertrifft GPT-4 bei Ihren spezifischen Supportanfragen, während es auf {Hardware} läuft, die Sie bereits besitzen.
Sie bauen sie nicht von Grund auf neu
Die Einführung eines SLM bedeutet nicht, dass man es von Grund auf neu aufbauen muss. Selbst „kleine“ Modelle sind viel zu komplex, als dass Einzelpersonen oder kleine Groups sie von Grund auf trainieren könnten. Stattdessen laden Sie ein vorab trainiertes Modell herunter, das bereits Sprache versteht, und bringen ihm dann durch Feinabstimmung Ihre spezifische Domäne bei.
Es ist, als würde man einen Mitarbeiter einstellen, der bereits Englisch spricht, und ihn in den Abläufen Ihres Unternehmens schulen, anstatt einem Child von Geburt an das Sprechen beizubringen. Das Modell verfügt über ein integriertes allgemeines Sprachverständnis. Sie fügen lediglich Fachwissen hinzu.
Sie benötigen kein Staff von Doktoranden oder riesige Computercluster. Sie benötigen einen Entwickler mit Python Kenntnisse, einige Beispieldaten aus Ihrer Area und ein paar Stunden GPU-Zeit. Die Eintrittsbarriere ist viel niedriger als die meisten Menschen annehmen.
Warum SLMs im Jahr 2026 wichtig sind
Drei Kräfte treiben die SLM-Einführung voran: Kosten, Latenz und Datenschutz.
Kosten: Die Cloud-API-Preise für große Modelle liegen zwischen 0,01 und 0,10 US-Greenback professional 1.000 Token. Im Maßstab summiert sich das schnell. Ein Kundensupportsystem, das täglich 100.000 Anfragen bearbeitet, kann monatlich über 30.000 US-Greenback an API-Kosten verursachen. Ein SLM, der auf einem einzelnen GPU-Server läuft, kostet die gleiche {Hardware}, unabhängig davon, ob er 10.000 oder 10 Millionen Abfragen verarbeitet. Die Wirtschaftslage dreht sich völlig um.
Latenz: Wenn Sie eine Cloud-API aufrufen, warten Sie auf Netzwerk-Roundtrips plus Inferenzzeit. Lokal laufende SLMs reagieren in 50 bis 200 Millisekunden. Bei Anwendungen wie Programmierassistenten oder interaktiven Chatbots spüren Benutzer diesen Unterschied sofort.
Datenschutz: Regulierte Branchen (Gesundheitswesen, Finanzen, Recht) können keine sensiblen Daten an externe APIs senden. Mit SLMs können diese Organisationen KI einsetzen und gleichzeitig die Daten vor Ort behalten. Keine externen API-Aufrufe bedeuten, dass keine Daten Ihre Infrastruktur verlassen.
LLMs vs. SLMs: Die Kompromisse verstehen
Die Entscheidung zwischen einem LLM und einem SLM hängt davon ab, ob die Fähigkeiten den Anforderungen entsprechen. Die Unterschiede liegen im Umfang, im Bereitstellungsmodell und in der Artwork der Aufgabe.
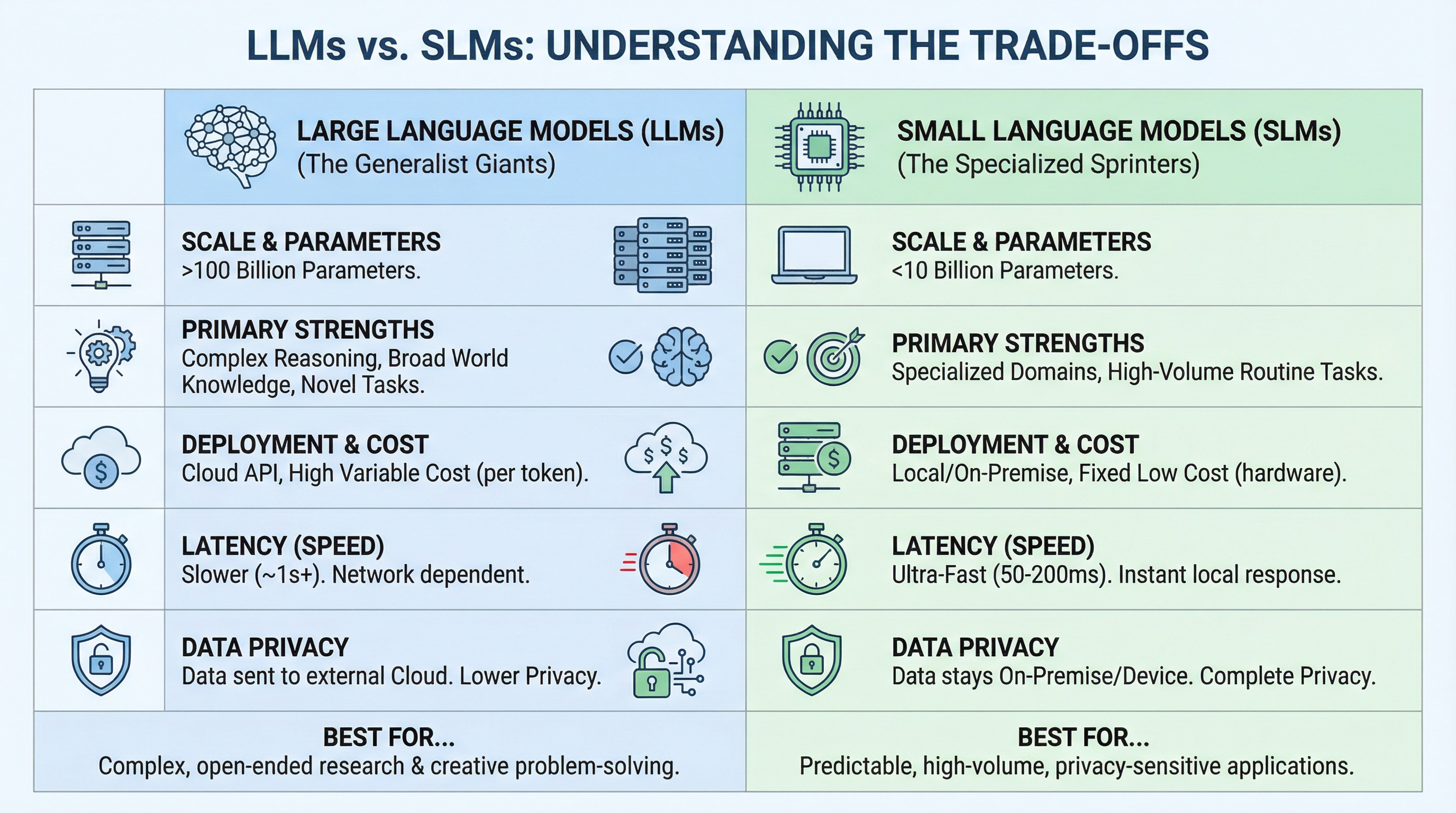
Der Vergleich zeigt ein Muster: LLMs sind auf Breite und Unvorhersehbarkeit ausgelegt, während SLMs auf Tiefe und Wiederholung ausgelegt sind. Wenn Ihre Aufgabe die Bearbeitung von Fragen zu einem beliebigen Thema erfordert, benötigen Sie das umfassende Wissen eines LLM. Wenn Sie jedoch die gleiche Artwork von Downside tausende Male lösen, ist ein SLM, das genau auf diesen speziellen Bereich abgestimmt ist, schneller, kostengünstiger und oft genauer.
Hier ist ein konkretes Beispiel. Wenn Sie einen Analysator für juristische Dokumente erstellen, kann ein LLM alle rechtlichen Fragen vom Gesellschaftsrecht bis hin zu internationalen Verträgen bearbeiten. Wenn Sie jedoch nur Arbeitsverträge bearbeiten, ist ein fein abgestimmtes 7B-Modell für diese spezielle Aufgabe schneller, kostengünstiger und genauer.
Die meisten Groups entscheiden sich für einen hybriden Ansatz: Verwenden Sie SLMs für 80 % der Anfragen (die vorhersehbaren), eskalieren Sie für die komplexen 20 % zu LLMs. Dieses „Router“-Muster vereint das Beste aus beiden Welten.
Wie SLMs ihren Vorsprung erzielen
SLMs sind nicht nur „kleine LLMs“. Sie verwenden spezielle Techniken, um eine hohe Leistung bei geringer Parameteranzahl zu liefern.
Wissensdestillation Trainiert kleinere „Schüler“-Modelle, um größere „Lehrer“-Modelle nachzuahmen. Der Schüler lernt, die Ergebnisse des Lehrers zu reproduzieren, ohne die gleiche huge Architektur zu benötigen. Die Phi-3-Serie von Microsoft wurde aus viel größeren Modellen destilliert und behielt über 90 % der Leistungsfähigkeit bei 5 % der Größe.
Hochwertige Trainingsdaten Für SLMs ist die Datenmenge wichtiger als die bloße Datenmenge. Während LLMs auf Billionen von Tokens aus dem gesamten Web trainiert werden, profitieren SLMs von kuratierten, qualitativ hochwertigen Datensätzen. Phi-3 wurde mit synthetischen Daten in „Lehrbuchqualität“ trainiert, die sorgfältig gefiltert wurden, um Rauschen und Redundanz zu entfernen.
Quantisierung Komprimiert Modellgewichte von 16-Bit- oder 32-Bit-Gleitkommazahlen auf 4-Bit- oder 8-Bit-Ganzzahlen. Ein 7B-Parametermodell mit 16-Bit-Präzision erfordert 14 GB Speicher. Auf 4-Bit quantisiert, passt es in 3,5 GB (klein genug, um auf einem Laptop computer zu laufen). Moderne Quantisierungstechniken wie GGUF behalten eine Modellqualität von über 95 % bei und erreichen gleichzeitig eine Größenreduzierung von 75 %.
Architekturoptimierungen wie spärliche Aufmerksamkeit reduzieren den Rechenaufwand. Anstatt dass sich jedes Token um jedes andere Token kümmert, verwenden Modelle Techniken wie Sliding-Window-Consideration oder Grouped-Question-Consideration, um die Berechnung dort zu konzentrieren, wo sie am wichtigsten ist.
Produktionsanwendungsfälle
SLMs betreiben bereits branchenübergreifend Produktionssysteme.
Kundensupport: Eine große E-Commerce-Plattform ersetzte GPT-3.5-API-Aufrufe durch einen fein abgestimmten Mistral 7B für Tier-1-Supportanfragen. Sie verzeichneten eine Kostenreduzierung um 90 %, dreimal schnellere Antwortzeiten und eine gleiche oder bessere Genauigkeit bei häufig gestellten Fragen. Komplexe Anfragen eskalieren immer noch zu GPT-4, aber 75 % der Tickets werden vom SLM bearbeitet.
Code-Unterstützung: Entwicklungsteams führen Llama 3.2 3B lokal aus, um den Code zu vervollständigen und einfach umzugestalten. Entwickler erhalten sofortige Vorschläge, ohne proprietären Code an externe APIs senden zu müssen. Das Modell wurde auf der Codebasis des Unternehmens optimiert, sodass es interne Muster und Bibliotheken versteht.
Dokumentenverarbeitung: Ein Gesundheitsdienstleister verwendet Phi-3 Mini, um strukturierte Daten aus Krankenakten zu extrahieren. Das Modell läuft vor Ort, HIPAA-konform und verarbeitet Tausende von Dokumenten professional Stunde auf Commonplace-Serverhardware. Zuvor verzichteten sie aufgrund von Datenschutzbeschränkungen vollständig auf KI.
Cell Anwendungen: Übersetzungs-Apps betten jetzt 1B-Parametermodelle direkt in die App ein. Benutzer erhalten sofortige Übersetzungen ohne Internetverbindung. Die Akkulaufzeit ist besser als bei Cloud-API-Aufrufen und Übersetzungen funktionieren auf Flügen oder in abgelegenen Gebieten.
Wann SLMs nicht verwendet werden sollten: Offene Forschungsfragen, kreatives Schreiben, das Neues erfordert, Aufgaben, die umfassendes Wissen erfordern, oder komplexe, mehrstufige Argumentation. Ein SLM wird kein neuartiges Drehbuch schreiben oder neuartige physikalische Probleme lösen. Aber für klar definierte, sich wiederholende Aufgaben sind sie ideally suited.
Erste Schritte mit SLMs
Wenn Sie neu bei SLMs sind, beginnen Sie hier.
Führen Sie einen Schnelltest durch. Installieren Ollama und führen Sie Llama 3.2 3B oder Phi-3 Mini auf Ihrem Laptop computer aus. Verbringen Sie einen Nachmittag damit, es an Ihren tatsächlichen Anwendungsfällen zu testen. Sie werden den Geschwindigkeitsunterschied und die Leistungsgrenzen sofort verstehen.
Identifizieren Sie Ihren Anwendungsfall. Sehen Sie sich Ihre KI-Workloads an. Wie viel Prozent sind vorhersehbare, sich wiederholende Aufgaben im Vergleich zu neuartigen Abfragen? Wenn mehr als 50 % vorhersehbar sind, haben Sie einen starken SLM-Kandidaten.
Bei Bedarf eine Feinabstimmung vornehmen. Sammeln Sie 500 bis 1.000 Beispiele Ihrer konkreten Aufgabenstellung. Die Feinabstimmung dauert Stunden, nicht Tage, und die Leistungsverbesserung kann erheblich sein. Werkzeuge wie Die Transformers-Bibliothek von Hugging Face und Plattformen wie Google Colab Machen Sie dies Entwicklern mit grundlegenden Python-Kenntnissen zugänglich.
Lokal oder vor Ort bereitstellen. Beginnen Sie mit einem einzelnen GPU-Server oder sogar einem leistungsstarken Laptop computer. Überwachen Sie Kosten, Latenz und Qualität. Vergleichen Sie Ihre aktuellen Ausgaben für die Cloud-API. Die meisten Groups erzielen einen ROI innerhalb des ersten Monats.
Skalieren Sie mit einem Hybridansatz. Sobald Sie das Konzept bewiesen haben, fügen Sie einen Router hinzu, der einfache Abfragen an Ihr SLM und komplexe Abfragen an ein Cloud-LLM sendet. Dies funktioniert sowohl im Hinblick auf die Kosten als auch auf die Leistungsfähigkeit.
Wichtige Erkenntnisse
Der Pattern in der KI geht nicht nur zu „größeren Modellen“. Es ist eine intelligentere Bereitstellung. Mit der Verbesserung der SLM-Architekturen und der Weiterentwicklung der Quantisierungstechniken verringert sich die Kluft zwischen kleinen und großen Modellen für spezielle Aufgaben.
Im Jahr 2026 werden erfolgreiche KI-Bereitstellungen nicht daran gemessen, welches Modell Sie verwenden. Sie werden daran gemessen, wie intestine Sie Modelle den Aufgaben zuordnen. SLMs bieten Ihnen diese Flexibilität: die Möglichkeit, leistungsfähige KI dort einzusetzen, wo Sie sie benötigen, auf der von Ihnen kontrollierten {Hardware}, und das zu Kosten, die sich an Ihr Unternehmen anpassen.
Bei den meisten Produktions-Workloads stellt sich nicht die Frage, ob SLMs verwendet werden sollen. Es geht darum, mit welchen Aufgaben man zuerst beginnen sollte.