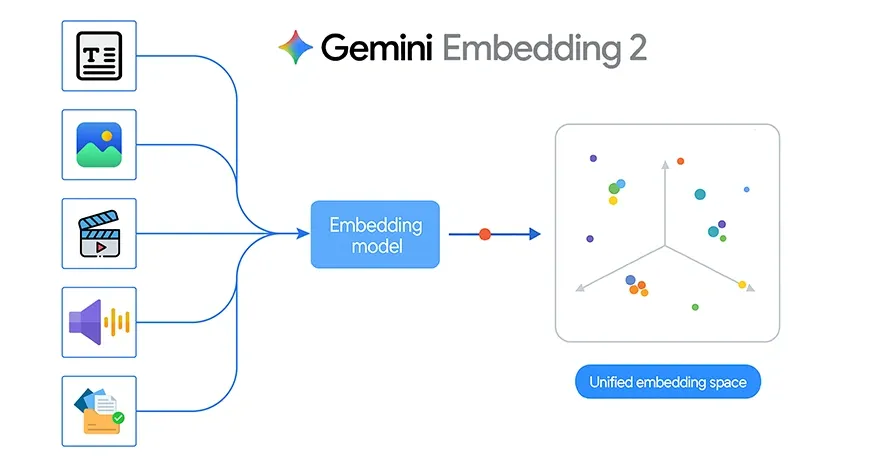
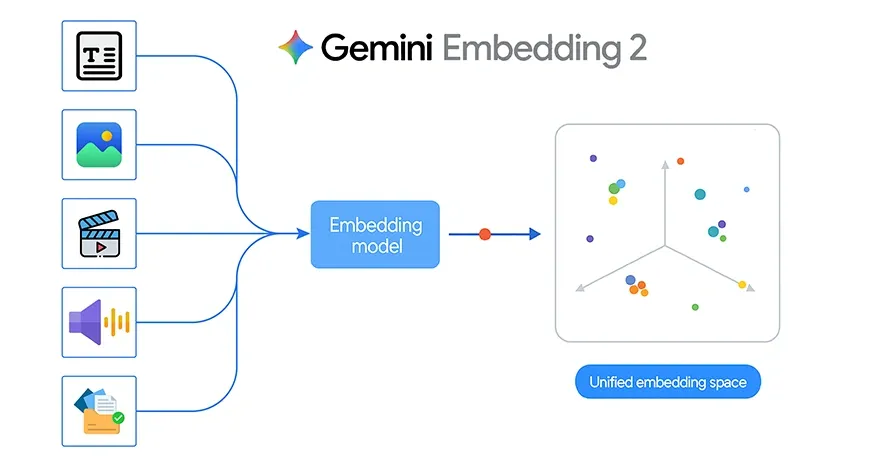
Google hat kürzlich Gemini Embedding 2 vorgestellt, sein erstes nativ multimodales Einbettungsmodell. Dies ist ein wichtiger Fortschritt, da Textual content, Bilder, Video, Audio und Dokumente in einem einzigen gemeinsamen Einbettungsraum zusammengefasst werden. Anstatt mit separaten Modellen für jeden Datentyp zu arbeiten, können Entwickler jetzt ein Einbettungsmodell für mehrere Modalitäten zum Abrufen, Suchen, Clustering und Klassifizieren verwenden.
Dieser Wandel ist theoretisch wirkungsvoll, wird aber noch interessanter, wenn er auf ein reales Projekt angewendet wird. Um herauszufinden, was Gemini Embedding 2 in der Praxis leisten kann, habe ich ein einfaches Bildabgleichssystem erstellt, das identifiziert, welche Particular person in einem Abfragebild den gespeicherten Bildern am ähnlichsten ist.
Gemini Embedding 2 Hauptfunktionen
Herkömmliche Einbettungssysteme sind oft nur für Textual content konzipiert. Wenn Sie ein System aufbauen wollten, das über Bilder, Audio oder Dokumente hinweg funktioniert, mussten Sie normalerweise mehrere Pipelines zusammenfügen. Gemini Embedding 2 ändert sich, indem es verschiedene Arten von Inhalten in einem einheitlichen Vektorraum abbildet.
Laut Google unterstützt Gemini Embedding 2:
- Textual content mit bis zu 8192 Eingabe-Tokens
- Bilder, mit bis zu 6 Bildern professional Anfrage im PNG- und JPEG-Format
- Video bis zu 120 Sekunden im MP4- und MOV-Format
- Audio ohne vorherige Transkription
- PDF-Dokumente mit einer Länge von bis zu 6 Seiten
Es unterstützt auch verschachtelte multimodale Eingaben, z. B. Bild und Textual content in einer einzigen Anfrage. Dadurch kann das Modell umfassendere Beziehungen zwischen verschiedenen Arten von Daten erfassen.
Ein weiteres wichtiges Merkmal ist die versatile Ausgabedimensionalität durch Matroschka Repräsentationslernen. Die Standardgröße beträgt 3072 Dimensionen, sie kann jedoch auf kleinere Größen wie 1536 oder 768 verkleinert werden. Dies hilft Entwicklern dabei, Qualität, Speicher und Abrufgeschwindigkeit je nach Anwendung in Einklang zu bringen.
Lesen Sie auch: 14 leistungsstarke Techniken, die die Entwicklung der Einbettung definieren
Erstellen eines Bildanpassungssystems mit Gemini Embedding 2
Das Projekt verwendet drei Ordner in einem Datensatzverzeichnis:
dataset/
nitika/
vasu/
janvi/
Jeder Ordner enthält mehrere Bilder einer Particular person. Das Ziel ist klar:
- Lesen Sie alle Bilder aus dem Datensatz
- Generieren Sie mit Gemini Embedding 2 eine Einbettung für jedes Bild
- Speichern Sie diese Einbettungen im Speicher und speichern Sie sie lokal zwischen
- Machen Sie ein Abfragebild
- Generieren Sie seine Einbettung
- Vergleichen Sie es mit allen gespeicherten Bildeinbettungen unter Verwendung der Kosinusähnlichkeit
- Geben Sie die am besten passenden Bilder zurück und sagen Sie den Namen der Particular person voraus
Dies ist ein starkes Beispiel dafür, wie Gemini Embedding 2 für den bildbasierten Abruf und die einfache Klassifizierung verwendet werden kann.
Das Beste an diesem Projekt ist, dass es keine vollständige Deep-Studying-Trainingspipeline erfordert. Es gibt keinen Brauch CNN Schulung, keine Feinabstimmung und kein annotationsintensiver Workflow. Stattdessen verlässt sich das System auf das Einbettungsmodell als semantischen Merkmalsextraktor.
Das macht die Entwicklung viel schneller.
Da Gemini Embedding 2 von Natur aus multimodal ist, kann das gleiche Projektdesign später über Bilder hinaus erweitert werden. Zum Beispiel:
- Zuordnen eines gesprochenen Audioclips zu einem Personenprofil
- Suche nach einem relevanten PDF aus einem Bild
- Abrufen eines Videosegments aus einer Textabfrage
- Vergleich gemischter Bild- und Textbeschreibungen in einem einzigen Einbettungsraum
In diesem Sinne ist das aktuelle Projekt ein einfacher Einstiegspunkt in eine viel umfassendere multimodale Retrieval-Architektur.
Gemini Embedding 2 API-Nutzung
Google stellt das Gemini Embedding 2-Modell über die Gemini API und Vertex AI bereit. Der Einbettungsaufruf erfolgt über embed_content Verfahren.
Ein multimodales Beispiel von Google sieht so aus:
from google import genai
from google.genai import varieties
consumer = genai.Shopper()
with open("instance.png", "rb") as f:
image_bytes = f.learn()
with open("pattern.mp3", "rb") as f:
audio_bytes = f.learn()
consequence = consumer.fashions.embed_content(
mannequin="gemini-embedding-2-preview",
contents=(
"What's the which means of life?",
varieties.Half.from_bytes(
knowledge=image_bytes,
mime_type="picture/png",
),
varieties.Half.from_bytes(
knowledge=audio_bytes,
mime_type="audio/mpeg",
),
),
)
print(consequence.embeddings) Für mein Projekt benötigte ich nur den Bildteil dieses Workflows. Anstatt Textual content, Bild und Audio zusammen zu senden, habe ich professional Anfrage ein einzelnes Bild verwendet und dessen Einbettung generiert.
Projektumsetzung
Das Projekt beginnt mit dem Laden des Gemini-API-Schlüssels aus einer .env-Datei und dem Erstellen eines Shoppers:
from dotenv import load_dotenv
import os
from google import genai
load_dotenv()
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
consumer = genai.Shopper(api_key=GEMINI_API_KEY) Dann habe ich Hilfsfunktionen für die Bildvalidierung, MIME-Typerkennung, Normalisierung, Kosinusähnlichkeit und Bildanzeige definiert.
Die Haupteinbettungsfunktion liest die Bildbytes und sendet sie an Gemini Embedding 2:
def embed_image(image_path):
image_path = Path(image_path)
mime_type = guess_mime_type(image_path)
with open(image_path, "rb") as f:
image_bytes = f.learn()
consequence = consumer.fashions.embed_content(
mannequin="gemini-embedding-2-preview",
contents=(
varieties.Half.from_bytes(
knowledge=image_bytes,
mime_type=mime_type,
)
),
config=varieties.EmbedContentConfig(
output_dimensionality=3072
)
)
emb = np.array(consequence.embeddings(0).values, dtype=np.float32)
return normalize(emb) Diese Funktion ist der Kern der gesamten Pipeline. Es verwandelt jedes Bild in eine 3072-dimensionale Vektordarstellung.
Erstellen der Datenbank zum Einbetten von Datensätzen
Der nächste Schritt besteht darin, durch den Datensatzordner zu gehen, alle Bilder für jede Particular person zu lesen und sie einzeln einzubetten.
Jedes eingebettete Bild wird als Wörterbuch gespeichert, das Folgendes enthält:
- das Personenetikett
- der Dateipfad
- der Einbettungsvektor
Um zu vermeiden, dass Einbettungen jedes Mal neu berechnet werden müssen, habe ich sie in einer lokalen Pickle-Datei zwischengespeichert:
def build_embeddings_db(dataset, cache_file="image_embeddings_cache.pkl", force_rebuild=False):
cache_path = Path(cache_file)
if cache_path.exists() and never force_rebuild:
with open(cache_path, "rb") as f:
embeddings_db = pickle.load(f)
return embeddings_db
embeddings_db = ()
for merchandise in dataset:
emb = embed_image(merchandise("path"))
embeddings_db.append({
"label": merchandise("label"),
"path": merchandise("path"),
"embedding": emb
})
with open(cache_path, "wb") as f:
pickle.dump(embeddings_db, f)
return embeddings_dbDadurch wird das Pocket book wesentlich effizienter, da Einbettungen nur einmal generiert werden, es sei denn, der Datensatz ändert sich.
Passend zu einem Abfragebild
Sobald die Datensatzeinbettungen fertig sind, besteht der nächste Schritt darin, das System mit einem neuen Abfragebild zu testen.
Das Abfragebild wird mit derselben Funktion eingebettet. Anschließend wird seine Einbettung mit allen gespeicherten Einbettungen unter Verwendung der Kosinusähnlichkeit verglichen.
def find_best_matches(query_image_path, top_k=5):
query_emb = embed_image(query_image_path)
outcomes = ()
for merchandise in embeddings_db:
rating = cosine_similarity(query_emb, merchandise("embedding"))
outcomes.append({
"label": merchandise("label"),
"path": merchandise("path"),
"rating": rating
})
outcomes.kind(key=lambda x: x("rating"), reverse=True)
return outcomes(:top_k) Diese Funktion gibt die am besten passenden Datensatzbilder zurück.
Um die endgültige Personenbezeichnung vorherzusagen, habe ich die High-Okay-Abstimmung verwendet:
def predict_person(query_image_path, top_k=5):
matches = find_best_matches(query_image_path, top_k=top_k)
labels = (m("label") for m in matches)
predicted_label = Counter(labels).most_common(1)(0)(0)
return predicted_label, matches Dies ist stabiler, als sich auf ein einzelnes nächstgelegenes Bild zu verlassen.
Testen des Projekts
Im Projekt habe ich Abfragebilder getestet wie:
Beispiel 1:
query_image = "Nitika_Test_Image.jpeg"
predicted_person, matches = predict_person(query_image, top_k=2)
print("nQuery picture:")
show_image(query_image, title="Question Picture")
print("Predicted individual:", predicted_person)
print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match('label')} | rating={match('rating'):.4f} | path={match('path')}")
show_image(match("path"), title=f"Rank {i} | {match('label')} | rating={match('rating'):.4f}")
print("nBest match:")
print(matches(0))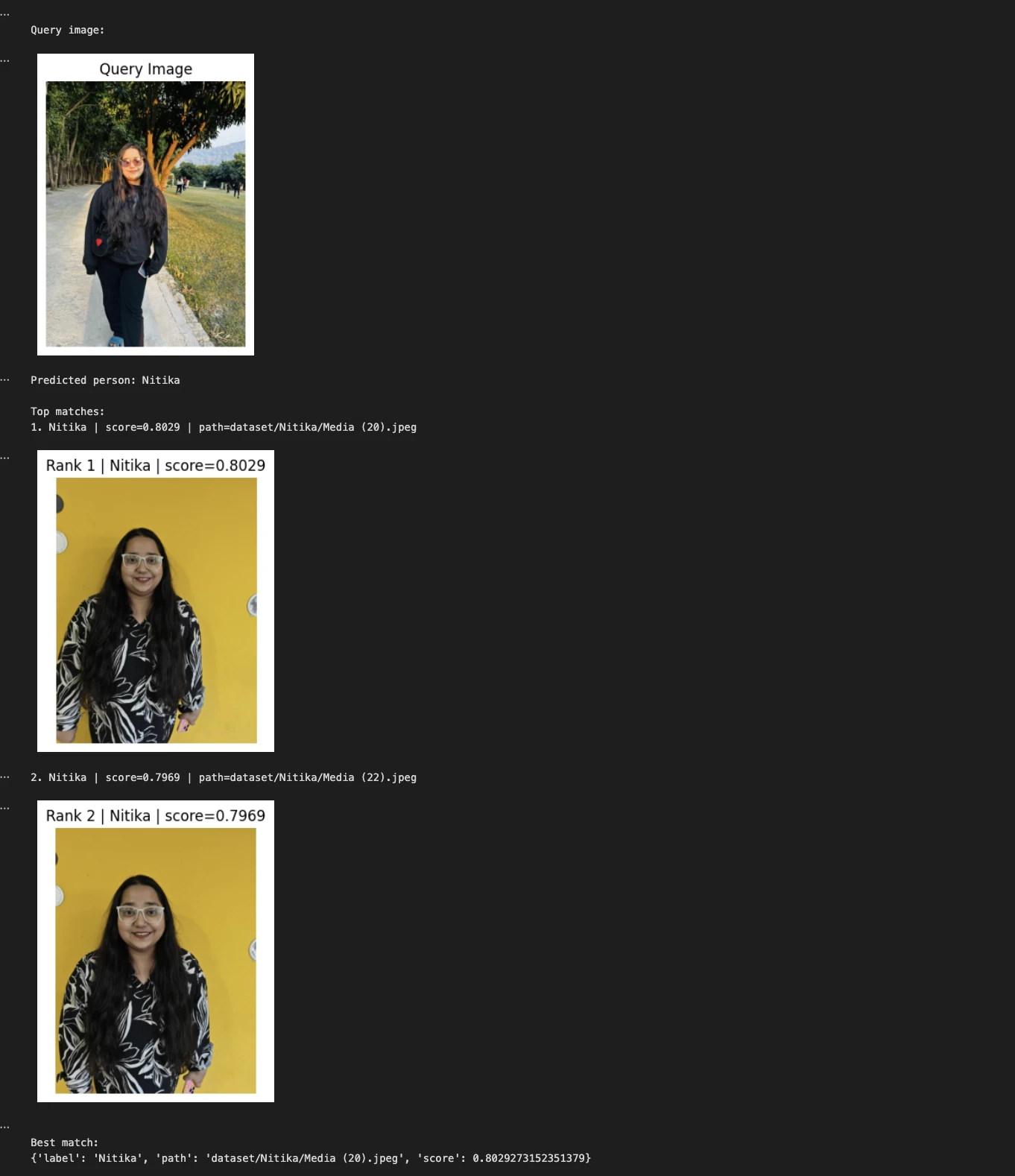
Beispiel 2:
query_image = "/Customers/janvi/Downloads/Him.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=2)
print("nQuery picture:") show_image(query_image, title="Question Picture")
print("Predicted individual:", predicted_person) print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match('label')} | rating={match('rating'):.4f} | path={match('path')}") show_image(match("path"), title=f"Rank {i} | {match('label')} | rating={match('rating'):.4f}")
print("nBest match:") print(matches(0))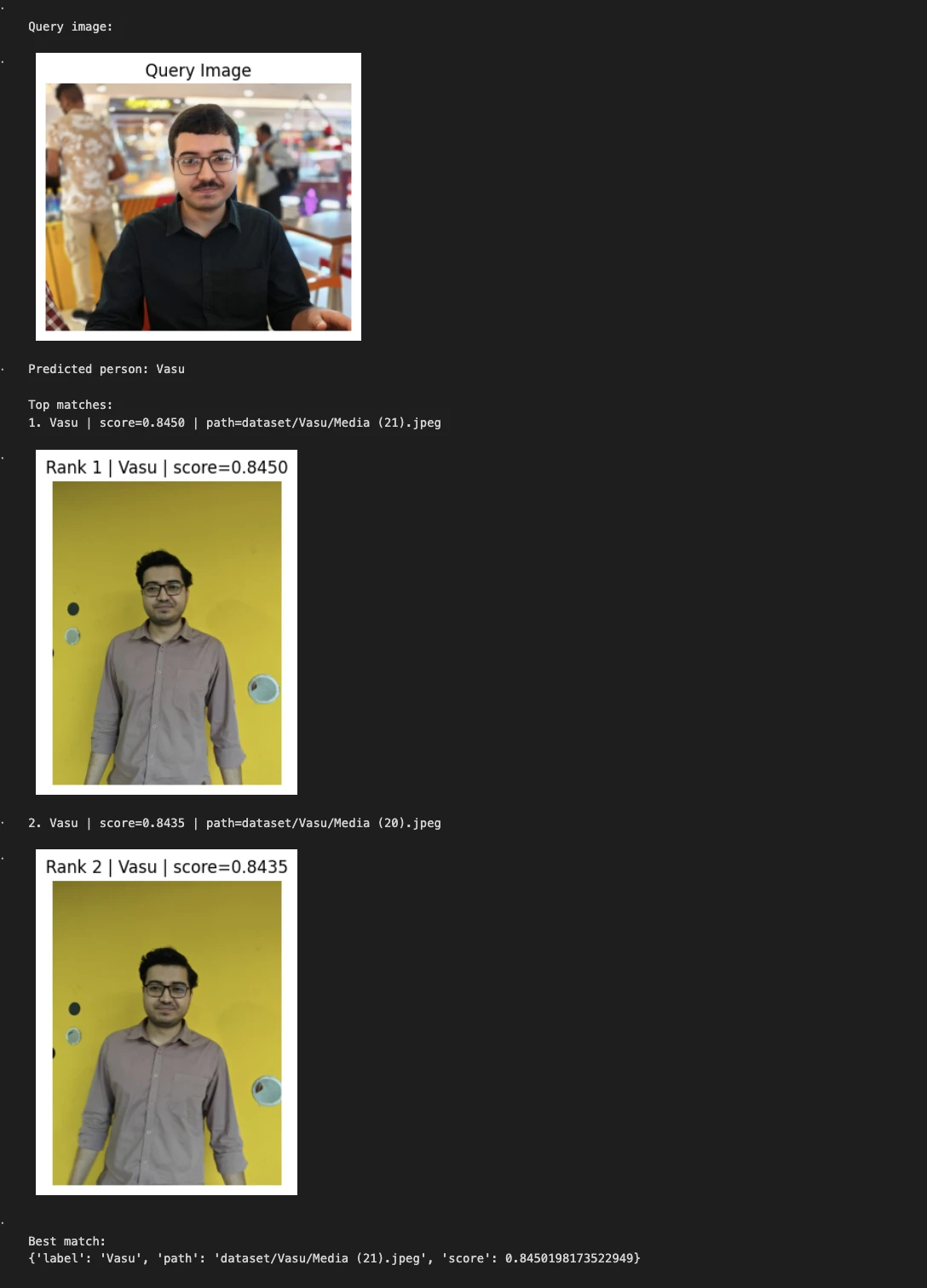
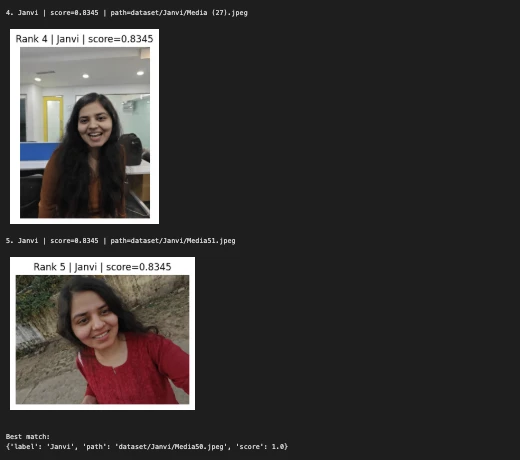
3. Beispiel:
query_image = "/Customers/janvi/Downloads/Nerd.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=5)
print("nQuery picture:")
show_image(query_image, title="Question Picture")
print("Predicted individual:", predicted_person)
print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match('label')} | rating={match('rating'):.4f} | path={match('path')}")
show_image(match("path"), title=f"Rank {i} | {match('label')} | rating={match('rating'):.4f}")
print("nBest match:")
print(matches(0))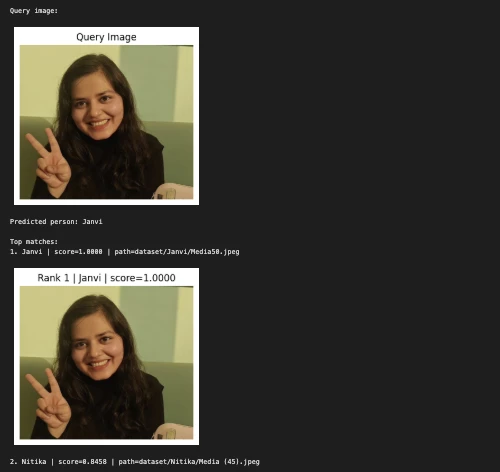
Das Notizbuch zeigte dann Folgendes an:
- das Abfragebild
- die vorhergesagte Personenbezeichnung
- die am besten passenden Bilder aus dem Datensatz
- der Kosinus-Ähnlichkeitswert für jede Übereinstimmung
Dies erleichtert die visuelle Inspektion des Programs und hilft zu überprüfen, ob der einbettungsbasierte Abruf ordnungsgemäß funktioniert.
Meine Erfahrung mit Gemini Embedding 2
Dieses Projekt magazine einfach sein, aber es zeigt deutlich den praktischen Wert von Gemini Embedding 2.
Erstens zeigt es, dass Einbettungen direkt zum Abrufen von Bildern verwendet werden können, ohne ein separates Klassifizierungsmodell zu trainieren.
Zweitens zeigt es, wie ein gemeinsamer Einbettungsraum reale Anwendungen vereinfachen kann. Obwohl diese Model nur Bilder verwendet, kann dieselbe Architektur später auf den Abruf von Textual content, Audio, Video und Dokumenten erweitert werden.
Drittens wird hervorgehoben, wie moderne multimodale Einbettungen den Bedarf an komplexen Vorverarbeitungspipelines reduzieren. Anstatt handgefertigte Options manuell zu extrahieren oder ein Modell von Grund auf zu erstellen, können Entwickler das Einbettungsmodell als universelles semantisches Rückgrat verwenden.
Stärken dieses Ansatzes
Es gibt mehrere Gründe, warum dieser Ansatz für einen Prototyp intestine funktioniert:
- Sehr geringer Schulungsaufwand
- Einfache Implementierung in einem Pocket book
- Einfach zu erweitern
- Schnelles Experimentieren
- Für Menschen lesbare Ergebnisse durch High-Match-Visualisierung
- Funktioniert natürlich mit der Ähnlichkeitssuche
Dies ist besonders nützlich für kleine Bildabgleichsaufgaben, bei denen Sie einen sauberen Machbarkeitsnachweis wünschen.
Einschränkungen
Gleichzeitig handelt es sich immer noch um eine leichtgewichtige Demoversion und nicht um ein biometrisches Produktionssystem.
Einige Einschränkungen sind erwähnenswert:
- Die Leistung hängt von Bildqualität, Beleuchtung, Hintergrund und Pose ab
- Mehr Bilder professional Particular person verbessern normalerweise die Robustheit
- Bei ähnlich aussehenden Personen kann es zu engeren Einbettungen kommen
- Die aktuelle Pipeline enthält keinen Schwellenwert für unbekannte Personen
- Für ein ernsthaftes Benchmarking wäre ein vollständiger Bewertungssatz erforderlich
Hierbei handelt es sich nicht um Fehler von Gemini Embedding 2. Es handelt sich um normale Überlegungen für jedes Bildabgleichssystem.
Abschluss
Gemini Embedding 2 markiert einen wichtigen Wandel in der Artwork und Weise, wie Entwickler mit multimodalen Daten arbeiten können. Anstatt separate Pipelines für Textual content, Bild, Audio, Video und Dokumente zu erstellen, verfügen wir jetzt über ein Modell, das sie alle in einem einheitlichen semantischen Raum darstellt.
Mein Picture-Matching-Projekt ist ein kleines, aber nützliches Beispiel für die Umsetzung dieser Idee. Durch das Einbetten von Bildern von drei bekannten Personen und den Vergleich eines Abfragebilds mittels Kosinusähnlichkeit konnte ich mit sehr wenig Code einen sauberen Abruf- und Klassifizierungsworkflow erstellen.
Das ist das wahre Versprechen von Gemini Embedding 2. Es handelt sich nicht nur um die Ankündigung eines neuen Modells. Es ist ein praktischer Baustein für multimodale Systeme, die einfacher zu entwerfen, einfacher zu skalieren und viel näher an realen Daten sind.
Häufig gestellte Fragen
A. Es handelt sich um das multimodale Einbettungsmodell von Google, das Textual content, Bilder, Audio, Video und Dokumente in einem gemeinsamen Vektorraum zum Suchen, Abrufen, Clustern und Klassifizieren abbildet.
A. Es bettet Datensatzbilder ein, vergleicht ein Abfragebild mithilfe der Kosinusähnlichkeit und sagt die Particular person basierend auf den am besten übereinstimmenden Einbettungen vorher.
A. Es fungiert als semantischer Merkmalsextraktor und ermöglicht den Bildabgleich, ohne ein separates Deep-Studying-Klassifizierungsmodell zu erstellen oder zu trainieren.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.