

Bild vom Autor
# Einführung
Wenn Sie genügend Datenprobleme im Interviewstil lösen, bemerken Sie einen lustigen Effekt: Die „Type“ des Datensatzes bestimmt stillschweigend Ihren Codierungsstil. Eine Zeitreihentabelle führt Sie zu Fensterfunktionen. Ein Sternschema drängt Sie in JOIN-Ketten und GROUP BY. A Pandas Aufgabe mit zwei DataFrames geradezu bettelnd .merge() Und isin().
Dieser Artikel macht diese Instinct messbar. Anhand einer Reihe repräsentativer SQL- und Pandas-Probleme werden wir grundlegende Codestrukturmerkmale identifizieren (Nutzung von Widespread Desk Expression (CTE), Häufigkeit von Fensterfunktionen, gängige Pandas-Techniken) und veranschaulichen, welche Elemente vorherrschen und welche Gründe dafür vorliegen.
# Warum die Datenstruktur Ihren Codierungsstil verändert
Datenprobleme ähneln nicht nur Logik, sondern eher Einschränkungen, die in Tabellen verpackt sind:
// Zeilen, die von anderen Zeilen abhängen (Zeit, Rang, „Vorheriger Wert“)
Wenn die Antwort jeder Zeile von benachbarten Zeilen abhängt (z. B. Temperatur von gestern, vorherige Transaktion, laufende Summen), stützen sich Lösungen natürlich auf Fensterfunktionen wie LAG(), LEAD(), ROW_NUMBER()Und DENSE_RANK().
Betrachten Sie zum Beispiel dies Interviewfragen Tabellen:

Das Ergebnis jedes Kunden an einem bestimmten Tag kann nicht isoliert ermittelt werden. Nach der Aggregation der Bestellkosten auf der Ebene des Kundentages muss jede Zeile im Verhältnis zu anderen Kunden am selben Datum ausgewertet werden, um zu ermitteln, welcher Gesamtwert am höchsten ist.
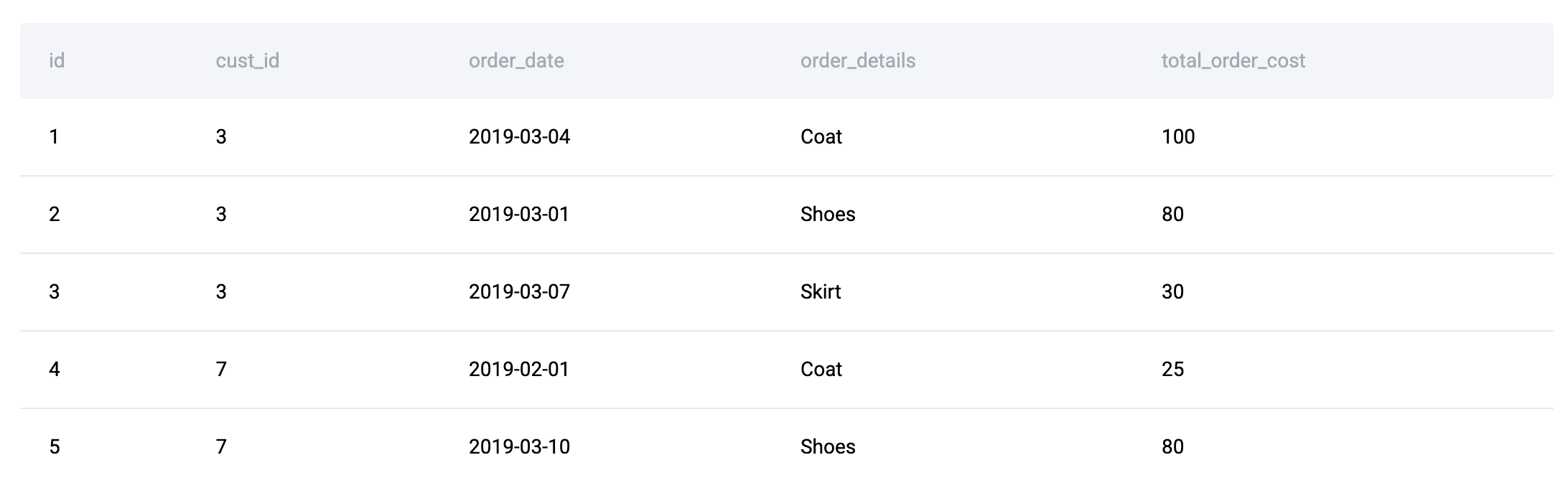
Da die Antwort für eine Zeile davon abhängt, wie sie im Verhältnis zu ihren Mitbewerbern innerhalb einer Zeitpartition eingestuft wird, führt diese Datensatzform natürlich zu Fensterfunktionen wie z RANK() oder DENSE_RANK() statt einer einfachen Aggregation allein.
// Mehrere Tabellen mit Rollen (Dimensionen vs. Fakten)
Wenn eine Tabelle Entitäten und eine andere Ereignisse beschreibt, tendieren Lösungen zu JOIN + GROUP BY-Mustern (SQL) oder .merge() + .groupby() Muster (Pandas).
Zum Beispiel hier InterviewfrageDie Datentabellen lauten wie folgt:

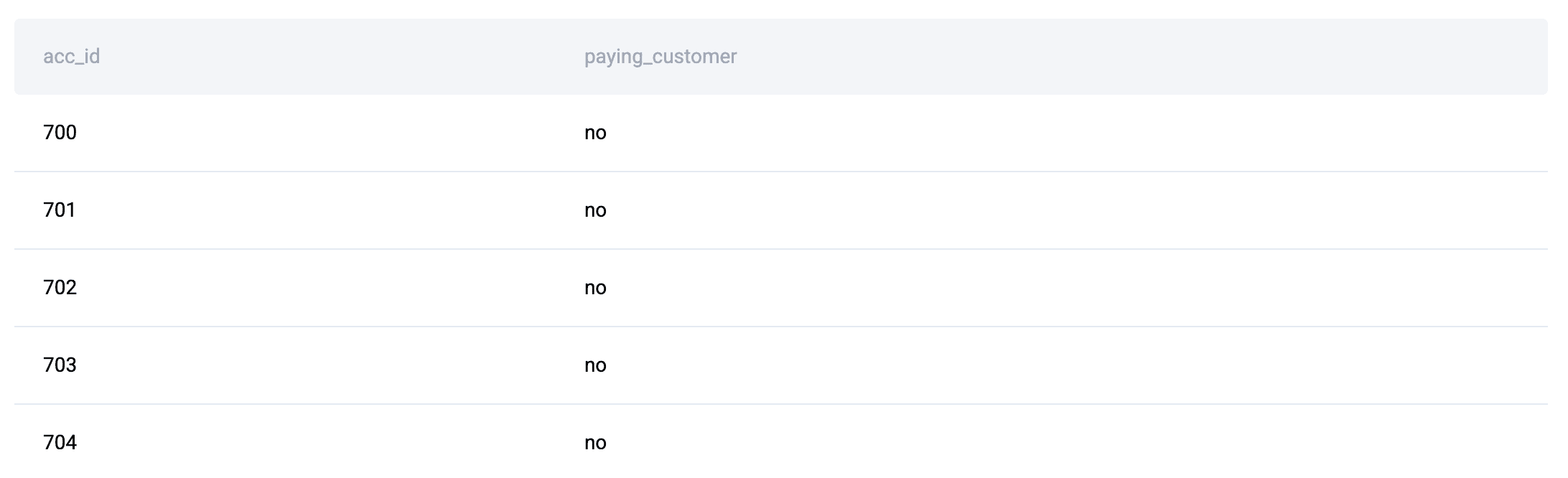
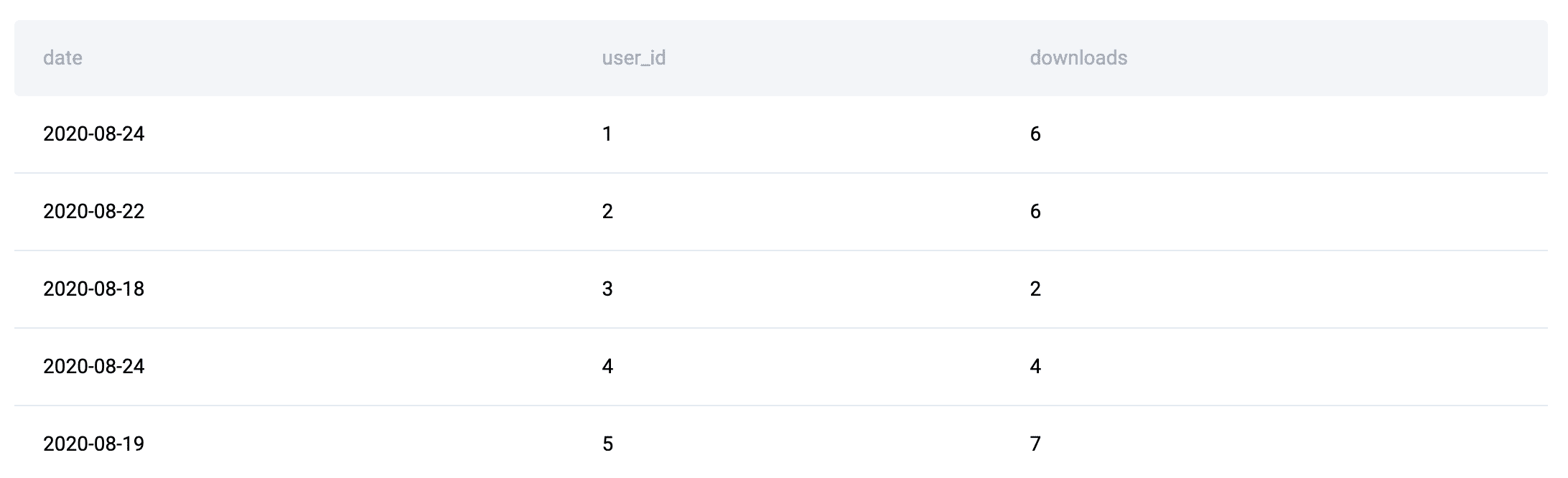
Da in diesem Beispiel Entitätsattribute (Benutzer und Kontostatus) und Ereignisdaten (Downloads) getrennt sind, muss die Logik sie zunächst mithilfe von JOINs neu kombinieren, bevor eine sinnvolle Aggregation (genau die Dimension) stattfinden kann. Dieses Faktenmuster ist es, was JOIN + GROUP BY-Lösungen schafft.
// Kleine Ausgaben mit Ausschlusslogik (Anti-Be part of-Muster)
Probleme mit der Frage „Wer hat X nie gemacht?“ werden oft zu LEFT JOIN … IS NULL / NOT EXISTS (SQL) oder ~df('col').isin(...) (Pandas).
# Was wir messen: Codestrukturmerkmale
Um den „Codierungsstil“ verschiedener Lösungen zu vergleichen, ist es hilfreich, einen begrenzten Satz beobachtbarer Merkmale zu identifizieren, die aus SQL-Textual content und Python-Code extrahiert werden können.
Auch wenn dies möglicherweise keine einwandfreien Indikatoren für die Lösungsqualität (z. B. Korrektheit oder Effizienz) sind, können sie doch als vertrauenswürdige Signale dafür dienen, wie Analysten mit einem Datensatz umgehen.
// Von uns gemessene SQL-Funktionen
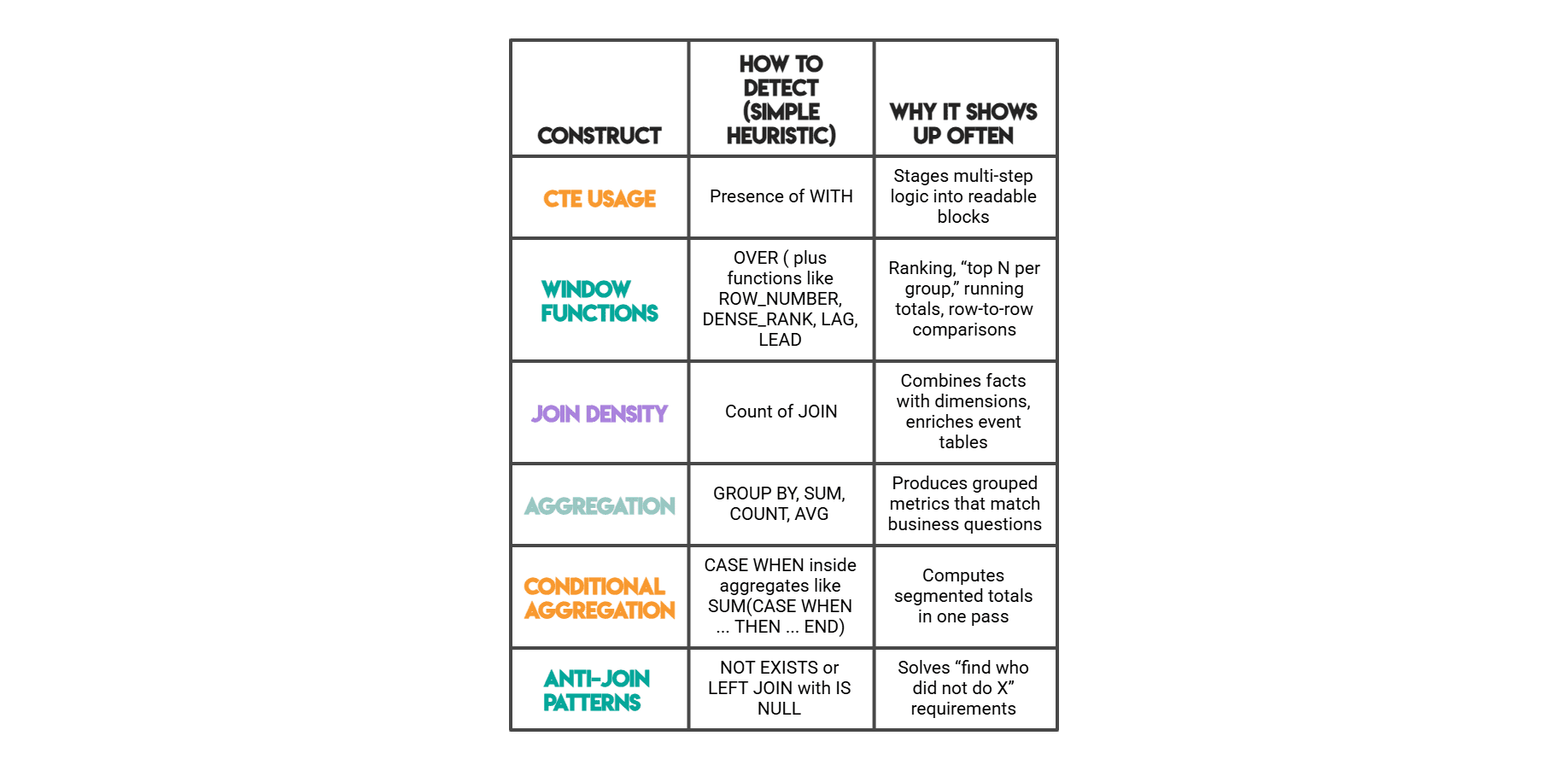
// Pandas-Funktionen, die wir messen
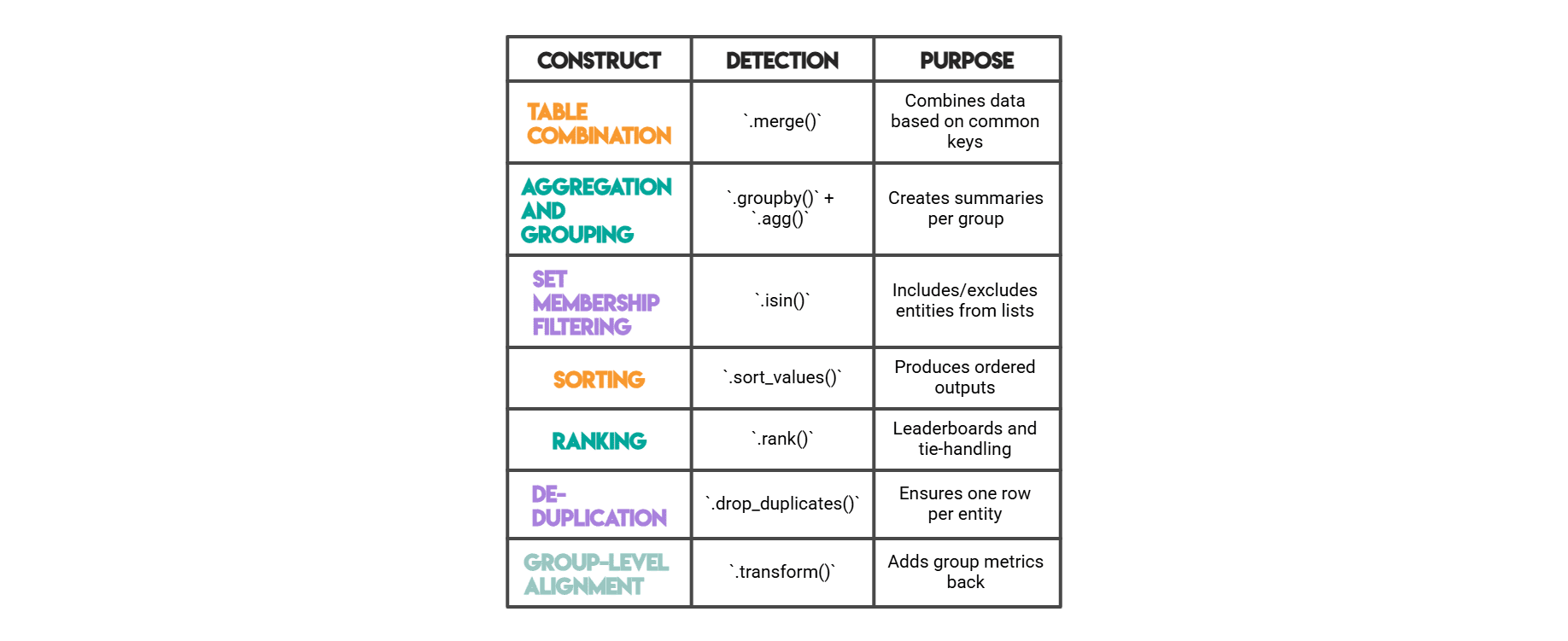
# Welche Konstrukte kommen am häufigsten vor?
Um über anekdotische Beobachtungen hinauszugehen und diese Muster zu quantifizieren, benötigen Sie eine einfachere und konsistentere Methode, um strukturelle Signale direkt aus dem Lösungscode abzuleiten.
Als konkreten Anker für diesen Workflow nutzten wir alle pädagogischen Fragen zum StrataScratch Plattform.
Im unten gezeigten Ergebnis ist „Gesamtzahl der Vorkommen“ die rohe Anzahl der Vorkommen eines Musters im gesamten Code. Die Lösung einer einzelnen Frage könnte JOIN dreimal verwenden, sodass sich diese drei addieren. Bei „Fragen mit“ geht es darum, wie viele unterschiedliche Fragen dieses Merkmal mindestens einmal aufweisen (d. h. ein binäres „verwendet/nicht verwendet“ professional Frage).
Diese Methode reduziert jede Lösung auf einen begrenzten Satz beobachtbarer Merkmale und ermöglicht es uns, Codierungsstile problemübergreifend konsistent und reproduzierbar zu vergleichen und die Datensatzstruktur direkt mit dominanten Konstrukten zu verknüpfen.
// SQL-Funktionen
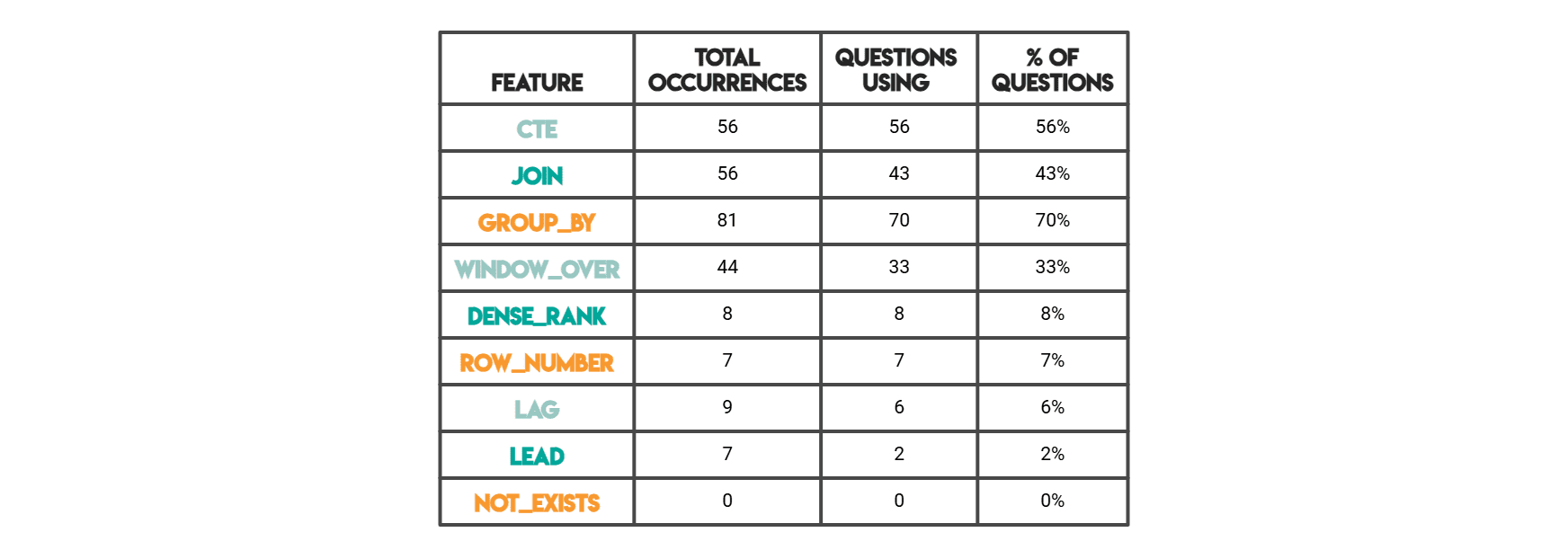
// Pandas-Funktionen (Python-Lösungen)
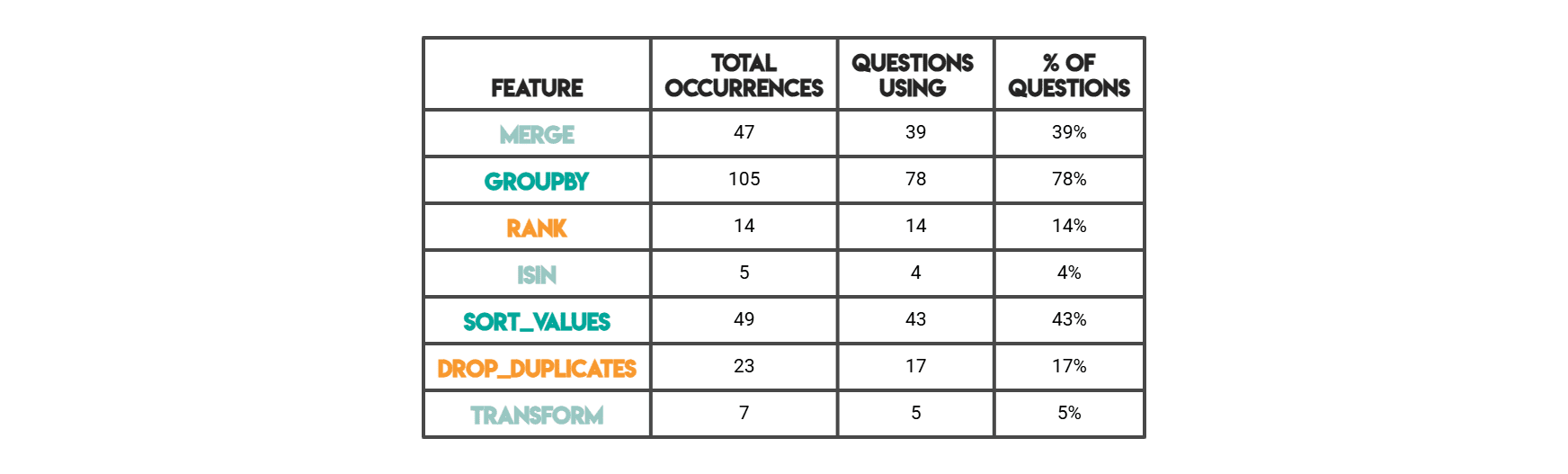
// Funktionsextraktionscode
Im Folgenden stellen wir die verwendeten Codeausschnitte vor, die Sie für Ihre eigenen Lösungen verwenden (oder Antworten in Ihren eigenen Begriffen umformulieren) und Funktionen aus dem Codetext extrahieren können.
// SQL-Characteristic-Extraktion (Beispiel)
import re
from collections import Counter
sql = # insert code right here
SQL_FEATURES = {
"cte": r"bWITHb",
"be a part of": r"bJOINb",
"group_by": r"bGROUPs+BYb",
"window_over": r"bOVERs*(",
"dense_rank": r"bDENSE_RANKb",
"row_number": r"bROW_NUMBERb",
"lag": r"bLAGb",
"lead": r"bLEADb",
"not_exists": r"bNOTs+EXISTSb",
}
def extract_sql_features(sql: str) -> Counter:
sql_u = sql.higher()
return Counter({okay: len(re.findall(p, sql_u)) for okay, p in SQL_FEATURES.objects()})// Pandas-Characteristic-Extraktion (Beispiel)
import re
from collections import Counter
pandas = # paste code right here
PD_FEATURES = {
"merge": r".merges*(",
"groupby": r".groupbys*(",
"rank": r".ranks*(",
"isin": r".isins*(",
"sort_values": r".sort_valuess*(",
"drop_duplicates": r".drop_duplicatess*(",
"rework": r".transforms*(",
}
def extract_pd_features(code: str) -> Counter:
return Counter({okay: len(re.findall(p, code)) for okay, p in PD_FEATURES.objects()})Lassen Sie uns nun ausführlicher über die Muster sprechen, die uns aufgefallen sind.
# Highlights der SQL-Häufigkeit
// Fensterfunktionen nehmen bei „höchsten professional Tag“- und unentschiedenfreundlichen Rating-Aufgaben zu
Zum Beispiel hier Interviewfragewerden wir gebeten, eine tägliche Gesamtsumme professional Kunde zu berechnen und dann das höchste Ergebnis für jedes Datum auszuwählen, einschließlich Unentschieden. Dies ist eine Anforderung, die natürlich dazu führt, dass Fensterfunktionen wie z RANK() oder DENSE_RANK()segmentiert nach Tag.
Die Lösung lautet wie folgt:
WITH customer_daily_totals AS (
SELECT
o.cust_id,
o.order_date,
SUM(o.total_order_cost) AS total_daily_cost
FROM orders o
WHERE o.order_date BETWEEN '2019-02-01' AND '2019-05-01'
GROUP BY o.cust_id, o.order_date
),
ranked_daily_totals AS (
SELECT
cust_id,
order_date,
total_daily_cost,
RANK() OVER (
PARTITION BY order_date
ORDER BY total_daily_cost DESC
) AS rnk
FROM customer_daily_totals
)
SELECT
c.first_name,
rdt.order_date,
rdt.total_daily_cost AS max_cost
FROM ranked_daily_totals rdt
JOIN prospects c ON rdt.cust_id = c.id
WHERE rdt.rnk = 1
ORDER BY rdt.order_date;Dieser zweistufige Ansatz – zuerst aggregieren, dann innerhalb jedes Datums ordnen – zeigt, warum Fensterfunktionen perfect für „Höchste professional Gruppe“-Szenarien sind, in denen Gleichstände aufrechterhalten werden müssen, und warum die grundlegende GROUP BY-Logik unzureichend ist.
// Die CTE-Nutzung steigt, wenn die Frage eine stufenweise Berechnung hat
Ein gemeinsamer Tabellenausdruck (CTE) (oder mehrere CTEs) sorgt dafür, dass jeder Schritt lesbar bleibt und die Validierung von Zwischenergebnissen erleichtert wird.
Diese Struktur spiegelt auch die Denkweise von Analysten wider: Sie trennt die Datenaufbereitung von der Geschäftslogik, sodass die Abfrage einfacher zu verstehen, Fehler zu beheben und anzupassen ist, wenn sich die Anforderungen ändern.
// JOIN Plus-Aggregation wird zum Normal bei Geschäftsmetriken mit mehreren Tabellen
Wenn Kennzahlen in einer Tabelle und Dimensionen in einer anderen Tabelle gespeichert sind, kommen Sie oft nicht um JOIN-Klauseln herum. Nach dem Beitritt werden GROUP BY und bedingte Summen (SUM(CASE WHEN ... THEN ... END)) sind normalerweise der kürzeste Weg.
# Highlights der Pandas-Methode
// .merge() erscheint immer dann, wenn die Antwort von mehr als einer Tabelle abhängt
Das Interviewfrage ist ein gutes Beispiel für das Pandas-Muster. Wenn sich Fahrten und Zahlungs- oder Rabattlogik über Spalten und Tabellen erstrecken, kombinieren Sie normalerweise zuerst die Daten und zählen und vergleichen dann.
import pandas as pd
orders_payments = lyft_orders.merge(lyft_payments, on='order_id')
orders_payments = orders_payments((orders_payments('order_date').dt.to_period('M') == '2021-08') & (orders_payments('promo_code') == False))
grouped_df = orders_payments.groupby('metropolis').measurement().rename('n_orders').reset_index()
consequence = grouped_df(grouped_df('n_orders') == grouped_df('n_orders').max())('metropolis')Sobald die Tabellen zusammengeführt sind, reduziert sich der Relaxation der Lösung auf ein vertrautes Bild .groupby() und Vergleichsschritt, der unterstreicht, wie die anfängliche Tabellenzusammenführung die nachgelagerte Logik in Pandas vereinfachen kann.
# Warum diese Muster immer wieder auftauchen
// Zeitbasierte Tabellen erfordern häufig Fensterlogik
Wenn sich ein Drawback auf Gesamtwerte „professional Tag“, Vergleiche zwischen Tagen oder die Auswahl des höchsten Werts für jedes Datum bezieht, ist normalerweise eine geordnete Logik erforderlich. Aus diesem Grund funktioniert das Rating mit OVER sind häufig, insbesondere wenn Bindungen gewahrt bleiben müssen.
// Mehrstufige Geschäftsregeln profitieren vom Staging
Einige Probleme vermischen Filterregeln, Verknüpfungen und berechnete Metriken. Es ist möglich, alles in einer einzigen Abfrage zu schreiben, aber das erhöht die Schwierigkeit beim Lesen und Debuggen. CTEs helfen dabei, indem sie die Anreicherung von der Aggregation auf eine Weise trennen, die leichter zu validieren ist und sich am Premium- vs. Freemium-Modell orientiert.
// Fragen mit mehreren Tabellen erhöhen auf natürliche Weise die Verknüpfungsdichte
Wenn eine Metrik von Attributen abhängt, die in einer anderen Tabelle gespeichert sind, ist eine Verknüpfung erforderlich. Sobald die Tabellen kombiniert sind, sind gruppierte Zusammenfassungen der natürliche nächste Schritt. Diese Gesamtform taucht wiederholt in StrataScratch-Fragen auf, die Ereignisdaten mit Entitätsprofilen mischen.
# Praktische Erkenntnisse für schnellere und sauberere Lösungen
- Wenn die Ausgabe von geordneten Zeilen abhängt, erwarten Sie Fensterfunktionen wie
ROW_NUMBER()oderDENSE_RANK() - Wenn die Frage wie folgt lautet: „Berechnen Sie A, dann berechnen Sie B aus A“, verbessert ein WITH-Block normalerweise die Klarheit.
- Wenn der Datensatz auf mehrere Entitäten aufgeteilt ist, planen Sie JOIN frühzeitig und legen Sie Ihre Gruppierungsschlüssel fest, bevor Sie die endgültige Auswahl schreiben.
- Bei Pandas behandeln
.merge()als Normal, wenn die Logik mehrere DataFrames umfasst, dann erstellen Sie die Metrik mit.groupby()und saubere Filterung.
# Abschluss
Der Codierungsstil folgt der Struktur: Zeitbasierte und „höchste professional Gruppe“-Fragen führen tendenziell zu Fensterfunktionen. Mehrstufige Geschäftsregeln führen tendenziell zu CTEs.
Multi-Desk-Metriken erhöhen die JOIN-Dichte und Pandas spiegelt dieselben Bewegungen wider .merge() Und .groupby().
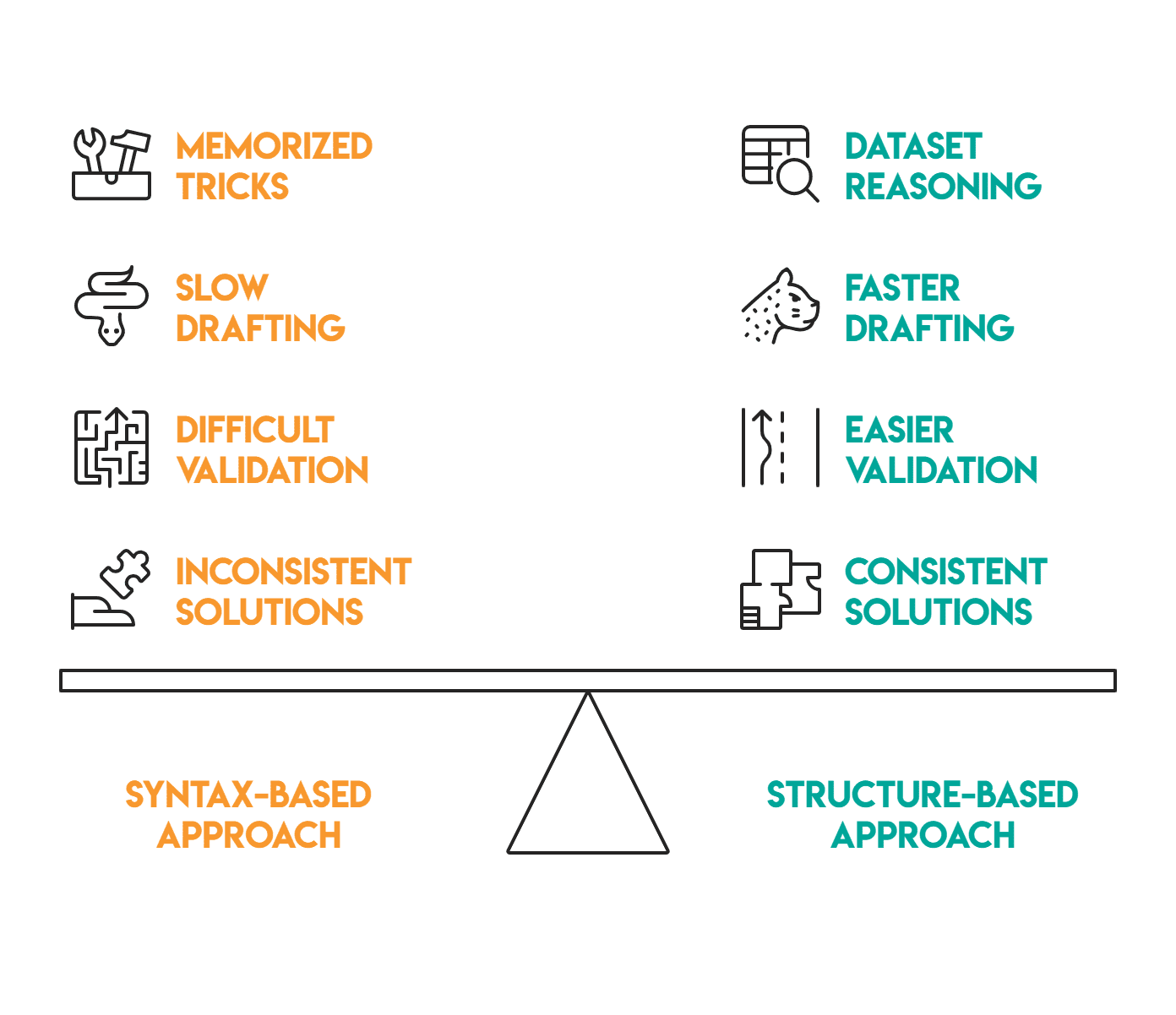
Noch wichtiger ist, dass das frühzeitige Erkennen dieser Strukturmuster Ihre Herangehensweise an ein neues Drawback erheblich verändern kann. Anstatt von der Syntax oder auswendig gelernten Tips auszugehen, können Sie vom Datensatz selbst ausgehen: Handelt es sich um ein Most professional Gruppe? Eine inszenierte Geschäftsregel? Eine Metrik mit mehreren Tabellen?
Diese Änderung der Denkweise ermöglicht es Ihnen, das Hauptgerüst vorwegzunehmen, bevor Sie Code schreiben. Letztendlich führt dies zu einem schnelleren Lösungsentwurf, einer einfacheren Validierung und mehr Konsistenz zwischen SQL und Pandas, da Sie auf die Datenstruktur und nicht nur auf den Fragetext reagieren.
Sobald Sie lernen, die Type des Datensatzes zu erkennen, können Sie das dominante Konstrukt frühzeitig vorhersagen. Dadurch lassen sich Lösungen schneller schreiben, einfacher debuggen und bei neuen Problemen konsistenter machen.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Developments auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.