
Characteristic Engineering ist die Grundlage leistungsstarker Systeme für maschinelles Lernen. Der traditionelle Prozess ist jedoch oft manuell, zeitaufwändig und abhängig von Domänenexpertise. Es ist zwar effektiv, kann jedoch tiefere Signale übersehen, die in unstrukturierten Daten wie Textual content, Protokollen und Benutzerinteraktionen verborgen sind.
Große Sprachmodelle ändern dies, indem sie Maschinen helfen, Sprache zu verstehen, Bedeutung zu extrahieren und automatisch umfangreichere Funktionen zu generieren. Dieser Wandel eröffnet neue Möglichkeiten zum Aufbau intelligenterer ML-Pipelines. Dieser Artikel bietet eine praktische Anleitung zum Characteristic Engineering mit LLMs.
Was ist Characteristic Engineering mit LLMs?
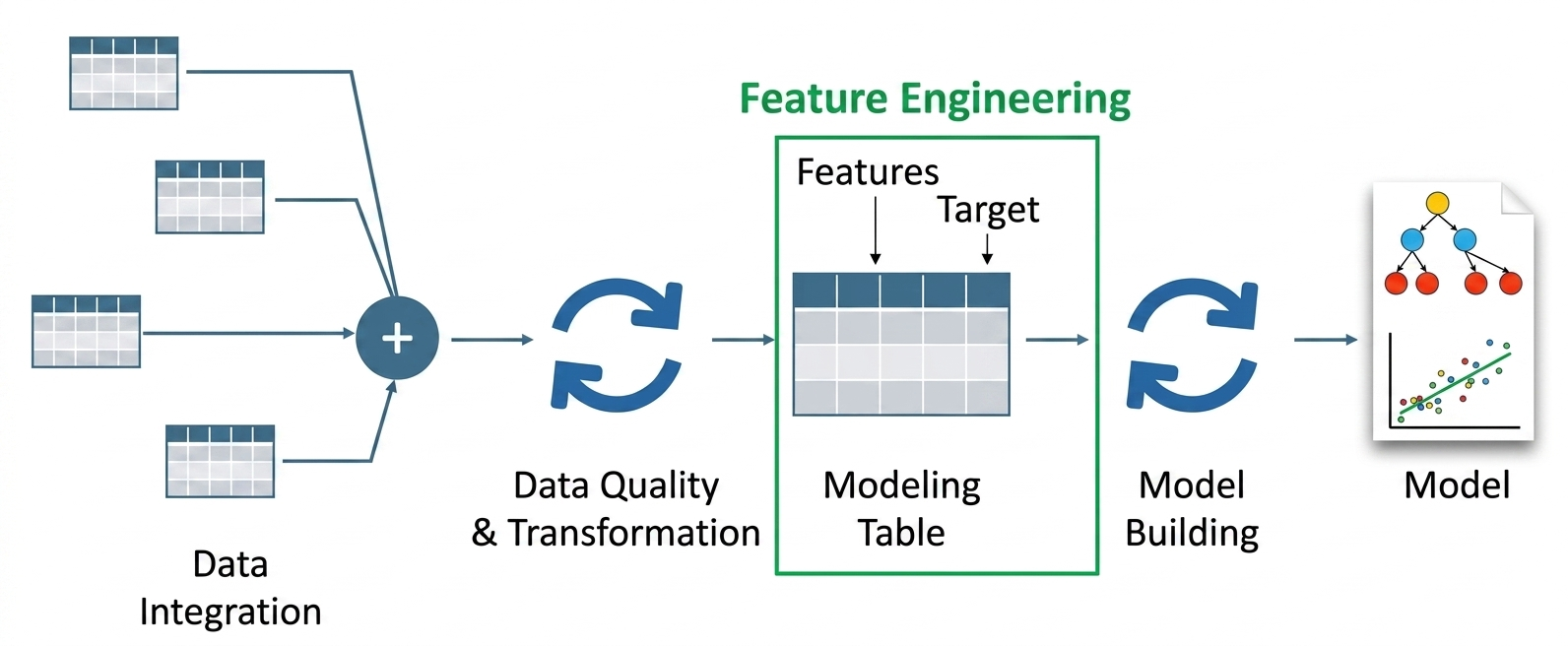
Beim Characteristic-Engineering mit LLMs werden große Sprachmodelle verwendet, um Eingabefunktionen zu entwickeln und zu ändern, die für maschinelle Lernsysteme erforderlich sind. Ihr System extrahiert semantische Bedeutung und strukturierte Signale aus Rohdaten durch die Anwendung von LLMs, anstatt nur manuelle Transformationen zu verwenden.
Der neue Ansatz des Characteristic Engineering ermöglicht es Ingenieuren, Modelle für maschinelles Lernen mithilfe verschiedener Methoden zu entwickeln, die sowohl numerische Transformationen als auch kontextbasierte Darstellungen umfassen.
Characteristic Engineering mit LLMs nutzt vorab trainierte Sprachmodelle, um Roheingaben in strukturierte hochdimensionale Darstellungen umzuwandeln, die den Modellen helfen, eine bessere Leistung zu erzielen. Die Modelle nutzen den Kontext, um Beziehungen zwischen Elementen zu bestimmen und gleichzeitig Merkmale zu erstellen, die eine Bedeutung über statistische Muster hinaus ausdrücken.
Wie es sich vom traditionellen Characteristic Engineering unterscheidet
Beim herkömmlichen Characteristic-Engineering werden Regeln erstellt und Aggregations- und Transformationsmethoden zum Erstellen von Options verwendet. LLM-basiertes Characteristic-Engineering extrahiert Bedeutungs- und Benutzerabsichten sowie Beziehungsdaten, die bei der manuellen Codierung nicht erfasst werden können.
Der Wandel: Von manuellen Funktionen zu semantischen Funktionen
Maschinelles Lernen entwickelt Modelle durch die Verwendung handgefertigter Funktionen, darunter One-Scorching-Vektoren und TF-IDF sowie standardisierte numerische Werte. Manuelle Funktionen unterliegen Einschränkungen, da sie den Kontext nicht berücksichtigen, spezielles Wissen erfordern und subtile Unterschiede nicht berücksichtigen. Die TF-IDF-Methode behandelt Wörter als separate Einheiten, was zum Verlust von Wortbeziehungen und emotionaler Bedeutung führt.
- Einschränkungen traditioneller Methoden: Die manuelle Erstellung von Options erfordert permanente Systemverbindungen und spezifische Fachkenntnisse. Das System berücksichtigt weder Allgemeinwissen noch komplexe Zusammenhänge. Ein Bag-of-Phrases-Modell erfordert mehr Wissen als „kaltes Essen“, um unfavourable Gefühle zu erkennen. Die Personalabteilung muss viel Zeit aufwenden, um alle Ausnahmesituationen zu erkennen.
- Rolle von LLMs im Kontext: LLMs funktionieren in ihrem jeweiligen Kontext durch LLMs, die ihr Coaching aus umfangreichen Textdatenbanken nutzen, um Wissen zu erwerben und Muster zu erkennen. Das System versteht den Sprachkontext durch sein vorhandenes Weltwissen und die Fähigkeit, verborgene Botschaften zu verstehen. Das System extrahiert semantische Merkmale aus Daten über LLMs, die automatische Merkmale erstellen, die Datenelemente wie Stimmung sowie Themen- und Risikokategorien identifizieren.
- Warum dieser Wandel wichtig ist: Die Bedeutung dieses Übergangs ergibt sich aus seiner Fähigkeit zu zeigen, dass semantische Merkmale bei der Bewältigung komplizierter Aufgaben bessere Ergebnisse liefern als von Menschen erstellte Merkmale. Das System benötigt für seinen Betrieb weniger Characteristic-Heuristiken, was zu schnelleren Testprozessen führt.
Kerntechniken im Characteristic Engineering mit LLMs
In diesem Abschnitt werden die wichtigsten Methoden anhand von Codebeispielen veranschaulicht. Wir generieren kleine Beispieldaten und zeigen, wie Options abgeleitet werden.
Einbettungen als Options
LLMs erzeugen dichte semantische Vektoren aus Textual content. Die extrahierten Einbettungen fungieren als numerische Merkmale, die es dem Modell ermöglichen, Bedeutungen zu verstehen, die über die grundlegenden Worthäufigkeiten hinausgehen. Wir können ein Transformatormodell verwenden, um durch Satzkodierung 384-dimensionale Satzeinbettungen zu erstellen.
from sentence_transformers import SentenceTransformer
mannequin = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ("I really like machine studying", "The film was implausible")
embeddings = mannequin.encode(sentences)
print("Embeddings form:", embeddings.form)Ausgabe:
Embeddings form: (2, 384)
Die Ausgabeform (2, 384) zeigt zwei Sätze, die in 384-dimensionalen dichten Vektoren abgebildet sind (einer professional Satz). Die Vektoren repräsentieren semantische Eigenschaften des Textes, einschließlich verwandter Bedeutungen und emotionaler Ausdrücke.
Wann sollten Einbettungen im Vergleich zu herkömmlichen Funktionen verwendet werden:
from sklearn.feature_extraction.textual content import TfidfVectorizer
docs = (
"The cat sat on the mat",
"The canine ate the cat",
)
# Conventional TF-IDF: sparse bag-of-words
tfidf = TfidfVectorizer()
X_tfidf = tfidf.fit_transform(docs)
# LLM embeddings: dense semantic options
X_emb = mannequin.encode(docs)
print("TF-IDF function form:", X_tfidf.form)
print("LLM embedding function form:", X_emb.form)Ausgabe:
TF-IDF function form: (2, 6)LLM embedding function form: (2, 384)
Der TF-IDF Merkmale erzeugen eine (2×6) dünn besetzte Matrix, die sechs eindeutige Terme enthält, während die LLM-Einbettungen als (2×384) dichte Vektoren vorliegen. Die Einbettungen stellen die Bedeutung von Wörtern in ihrem Kontext dar, da sie am Beispiel von „Katze“ und „Hund“ zeigen, wie Synonyme zueinander in Beziehung stehen. Verwenden Sie semantische Funktionen aus Einbettungen, während herkömmliche Funktionen für einfache numerische Daten und hochfrequente kategoriale Daten funktionieren, die eine spärliche Codierung erfordern.
Wir können den LLM veranlassen, bestimmte strukturierte Informationen aus Textual content zu extrahieren. Die Modellausgaben können in Options analysiert werden.
from transformers import pipeline
critiques = (
"The cellphone battery lasts all day and efficiency is easy",
"The laptop computer overheats and may be very sluggish",
)
extractor = pipeline("text2text-generation", mannequin="google/flan-t5-base")
immediate = """
Extract options: sentiment, product_issue, efficiency
Textual content: The laptop computer overheats and may be very sluggish
"""
end result = extractor(immediate, max_length=50)
print(end result(0)("generated_text"))Ausgabe:
sentiment: unfavourable, product_issue: overheating, efficiency: sluggish
Wir verwenden die LLM-Eingabeaufforderung, die besagt „Extrahieren Sie die Stimmung (positiv/negativ), das Thema und die Dringlichkeit (niedrig/mittel/hoch) aus dieser Rezension.“ Das Modell gibt strukturierte Options als JSON-ähnliches Wörterbuch zurück. Die Merkmale Stimmung, Betreff und Dringlichkeit liegen nun als separate Spalten vor, die wir in unser Klassifikationssystem eingeben können
Ein JSON-Schema kann in einem Aufruf erzwungen werden, sodass konsistente Ausgaben gewährleistet sind. Zum Beispiel:
immediate = """
Extract in JSON format:
{
"sentiment": "",
"problem": "",
"efficiency": ""
}
Textual content: The cellphone battery lasts all day and efficiency is easy
"""
end result = extractor(immediate, max_length=100)
print(end result(0)("generated_text"))Ausgabe:
{
"sentiment": "constructive",
"problem": "none",
"efficiency": "easy"
}
Generierung semantischer Merkmale
LLMs generieren neue beschreibende Attribute, die sowohl auf einzelne Zeilen als auch auf einzelne Datenwerte angewendet werden können.
information = (
{"evaluation": "Nice digicam high quality however battery drains quick"},
{"evaluation": "Reasonably priced and sturdy, good for each day use"},
)
immediate = """
Generate a brand new function referred to as 'user_intent' from this evaluation:
Evaluate: Nice digicam high quality however battery drains quick
"""
end result = extractor(immediate, max_length=50)
print(end result(0)("generated_text"))Ausgabe:
user_intent: photography-focused however involved about battery
Das LLM extrahiert durch die Analyse des Textes die Absicht des Benutzers aus der Rezension. Das System wandelt unverarbeiteten Textual content in strukturierte Funktionen um, die die Präferenz des Benutzers für Kameras und seine Bedenken hinsichtlich der Akkulaufzeit zeigen. Das System ermöglicht Benutzern das Hinzufügen neuer Spalten, die das Modellverständnis der Benutzeraktivitätsmuster verbessern.
Kontextbewusste Characteristic-Erstellung
LLMs können Textmerkmale generieren, wenn sie ihr Wissen nutzen, um den Wert eines Merkmals in bestimmten Situationen zu analysieren. Das LLM verwendet Postleitzahleninformationen, um das entsprechende geografische Gebiet zu erläutern.
immediate = """
Infer buyer kind:
Evaluate: Reasonably priced and sturdy, good for each day use
"""
end result = extractor(immediate, max_length=50)
print(end result(0)('generated_text'))Ausgabe:
customer_type: budget-conscious sensible person
Das LLM verwendet Kundenbewertungsinformationen, um zu bestimmen, zu welcher Kundengruppe der Rezensent gehört. Das System wandelt den eingegebenen Textual content in ein standardisiertes Etikett um, das die beiden Hauptpräferenzen des Benutzers für erschwingliche und langlebige Produkte anzeigt. Das System ermöglicht Benutzern die Implementierung einer neuen Funktion, die es Modellen ermöglicht, Benutzer anhand ihrer Verhaltensmuster und spezifischen Vorlieben zu kategorisieren.
Hybride Characteristic-Räume (multimodale Pipelines)
Kombinieren von Tabellen, Textual content und Einbettungen
Wir beginnen mit numerischen Merkmalen und semantischen Merkmalen, die wir zu einem Hybridvektor kombinieren.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"worth": (1000, 500),
"ranking": (4.5, 3.0),
"evaluation": (
"Wonderful efficiency and battery life",
"Sluggish and heats up rapidly",
),
})
embeddings = mannequin.encode(df("evaluation").tolist())
final_features = np.hstack((
df(("worth", "ranking")).values,
embeddings,
))
print("Last function form:", final_features.form)Ausgabe:
Last function form: (2, 386)
Der vollständige Datensatz enthält jetzt 2 Zeilen mit 386 Options. Die ursprünglichen Tabellendaten (Preis Und Bewertung) wird mit Texteinbettungen aus den Rezensionen kombiniert. Das System entwickelt erweiterte Funktionen durch die Kombination von strukturierten Daten und semantischen Textinformationen, was zu einer besseren Modellleistung führt.
Multimodale Characteristic-Pipelines
Wir beginnen mit numerischen Merkmalen und semantischen Merkmalen, die wir zu einem Hybridvektor kombinieren.
def feature_pipeline(row):
embedding = mannequin.encode((row('evaluation')))(0)
return checklist(row(('worth', 'ranking'))) + checklist(embedding)
options = df.apply(feature_pipeline, axis=1)
print(options.iloc(0)(:5))Ausgabe:
(1000, 4.5, 0.023, -0.045, 0.067)
Der vollständige Datensatz enthält jetzt 2 Zeilen mit 386 Options. Die ursprünglichen tabellarischen Daten (Preis und Bewertung) werden mit Texteinbettungen aus den Bewertungen kombiniert. Das System entwickelt erweiterte Funktionen durch die Kombination von strukturierten Daten und semantischen Textinformationen, was zu einer besseren Modellleistung führt.
Finish-to-Finish-Fluss (Daten → LLM → Funktionen → Modell)
In diesem Abschnitt gehen wir die Workflow-Demonstration durch, bei der Transformers zum Extrahieren von Options für die Verwendung mit einem einfachen Klassifikator verwendet wird. Betrachten Sie beispielsweise eine Stimmungsklassifizierungsaufgabe. Dazu nehmen wir zunächst einen Beispieldatensatz.
import pandas as pd
df = pd.DataFrame({
"evaluation": (
"Superb product, supply was tremendous quick and packaging was excellent",
"Horrible high quality, broke after one use and assist was unhelpful",
"Good worth for cash, does what it guarantees",
"The product is okay, not nice however not unhealthy both",
"Wonderful efficiency, exceeded my expectations fully",
"Very sluggish supply and the product high quality is disappointing",
"I really like the design and construct high quality, extremely advisable",
"Waste of cash, stopped working inside two days",
"Respectable product for the value, however could possibly be improved",
"Customer support was useful however the product is common",
"Unbelievable expertise, will certainly purchase once more",
"The merchandise arrived late and was broken",
"Fairly good total, happy with the acquisition",
"Not well worth the worth, high quality feels low-cost",
"Completely शानदार product, very pleased with it",
"Works effective however nothing distinctive",
"Horrible expertise, I desire a refund",
"The options are helpful and efficiency is easy",
"Mediocre high quality, anticipated higher at this worth",
"Excellent construct high quality and quick efficiency",
"Product is ok, supply took too lengthy",
"Liked it, precisely what I wanted",
"It’s okay, does the job however has some points",
"Worst buy ever, fully ineffective",
"Excellent high quality and fast supply",
"Common product, nothing particular",
"Extremely sturdy and dependable, nice purchase",
"Poor packaging and broken merchandise obtained",
"Glad with the acquisition, first rate efficiency",
"Not pleased with the product, high quality is subpar",
),
"label": (
1, 0, 1, 1, 1,
0, 1, 0, 1, 1,
1, 0, 1, 0, 1,
1, 0, 1, 0, 1,
0, 1, 1, 0, 1,
1, 1, 0, 1, 0,
),
})Jetzt machen wir uns daran, eine Agentenpipeline zu erstellen, die beim Characteristic-Engineering für eine bestimmte Aufgabe hilft. In diesem Fall wird die Stimmungsanalyse durchgeführt.
from transformers import pipeline
from sentence_transformers import SentenceTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
# Step 1: Initialize fashions
llm = pipeline("text2text-generation", mannequin="google/flan-t5-base")
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Step 2: Characteristic Extraction Agent
def extract_features(textual content):
immediate = f"Extract sentiment (constructive/unfavourable): {textual content}"
end result = llm(immediate, max_length=20)(0)("generated_text")
return 1 if "constructive" in end result.decrease() else 0
# Step 3: Construct Characteristic Set
df("sentiment_feature") = df("evaluation").apply(extract_features)
embeddings = embedder.encode(df("evaluation").tolist())
X = np.hstack((
df(("sentiment_feature")).values,
embeddings
))
y = df("label")
# Step 4: Practice Mannequin
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2
)
mannequin = LogisticRegression()
mannequin.match(X_train, y_train)
# Step 5: Consider
accuracy = mannequin.rating(X_test, y_test)
print("Mannequin Accuracy:", accuracy)Ausgabe:
Mannequin Accuracy: 0.95
Dies zeigt den kompletten Systembetrieb, der von Anfang bis Ende funktioniert. Der LLM Extrahiert eine Stimmungsfunktion aus jeder Bewertung, die mit Einbettungen kombiniert wird, um umfassendere Eingaben zu erstellen. Der Agentic Characteristic Engineering-Prozess dieses Programs ermöglicht es dem Modell, Textual content besser zu verstehen, was zu einer höheren Genauigkeit bei der Stimmungsvorhersage führt.
Anwendungen aus der Praxis
Die Anwendung von LLMs im Characteristic Engineering führt zu Veränderungen, die sich auf verschiedene Branchen auswirken. Die Lösung zeigt die Fähigkeit, Aufgaben in verschiedenen Einsatzbereichen auszuführen.
- Klassifizierung und NLP-Systeme: LLMs liefern erweiterte Textelemente, die Stimmungsanalysen, Chatbot-Entwicklung und Dokumentklassifizierungsaufgaben in Klassifizierungs- und NLP-Systemen unterstützen.
- Tabellarisches maschinelles Lernen: LLMs ermöglichen es allen Arten von Aufgaben, Vorteile aus ihren Fähigkeiten zu ziehen. Die LLM-Technologie wandelt unstrukturierte Daten aus Nebenquellen in nutzbare Funktionen um, die ein tabellarisches Modell verstehen kann.
- Domänenspezifische Anwendungsfälle: LLM-Funktionen haben modern Anwendungen in verschiedenen Bereichen gefunden, darunter Finanzen, Gesundheitswesen, Versicherungen und weitere Branchen. Das LLM-System in der Versicherungspreisgestaltung ermöglicht es Versicherungsmathematikern, automatische Funktionen zu erstellen, für die zuvor menschliche Spezialisten erforderlich waren. Das LLM-System verwendet Fahrzeugmodellbeschreibungen, um Risikobewertungen zu ermitteln, die Fahrzeuge als „Boy-Racer“-Modelle kennzeichnen.
Einschränkungen und Herausforderungen
Characteristic Engineering mit LLMs bietet Benutzern Vorteile, schafft jedoch mehrere Hindernisse, die gelöst werden müssen. Der Implementierungsprozess erfordert, dass alle Teammitglieder die bestehenden Einschränkungen verstehen. Dazu gehören:
- Zuverlässigkeit und Reproduzierbarkeit: Die Ausgaben von LLM-Systemen weisen ein inkonsistentes Verhalten auf, da Modelländerungen und geringfügige sofortige Änderungen eine neue Modellbewertung erfordern. Um eine konstante Leistung zu erzielen, benötigt das System eine sofortige Protokollierung und Nulltemperatureinstellungen. Organisationen stehen bei der LLM-Bereitstellung vor Herausforderungen, da sie zwei Aspekte bewältigen müssen, darunter API-Zugänglichkeit und Versionskontrolle.
- Voreingenommenheit und Interpretierbarkeit: Die Merkmale von LLM-Systemen sind schwer zu verstehen, da ihre dichten Einbettungen als LLM-Kernkomponenten fungieren. Das System könnte durch seine Betriebsabläufe zu einer auf Trainingsdaten basierenden Verzerrung führen. Ein LLM generiert ein Merkmal, das das Wort „Arzt“ implizit mit einem bestimmten Geschlecht verbindet. Der Prüfungsprozess muss Merkmale untersuchen, um ihre Equity festzustellen.
- Übermäßiges Vertrauen in LLM-Funktionen: LLMs bieten eine vollständige Automatisierung, die durch ihre Fassade der Zuverlässigkeit zu gefährlichen Ergebnissen führt. LLMs generieren irrelevante Funktionen, wenn Benutzer falsche Eingabeaufforderungen geben. Die LLM-Funktionen sollten als ergänzende Instruments fungieren, die Benutzer zusammen mit den Hauptdomänenfunktionen anwenden sollten.
Abschluss
Der Bereich der maschinellen Lernentwicklung erfährt durch den Einsatz von Characteristic Engineering mit LLMs einen großen Wandel. Der Schwerpunkt des Prozesses verlagert sich nun von der manuellen Datentransformationsarbeit hin zur Erstellung automatisierter Funktionen durch semantisches Verständnis. Diese Methode ermöglicht es Forschern, neue Methoden zur Analyse komplexer und unorganisierter Datensätze zu entwickeln.
Der Prozess erfordert eine präzise Umsetzung und gründliche Bewertungs- und Validierungsverfahren, um erfolgreich zu sein. LLM-Fähigkeiten in Kombination mit menschlichem Fachwissen ermöglichen es Praktikern, KI-Systeme zu entwickeln, die leistungsfähiger, skalierbarer und effektiver arbeiten.
Häufig gestellte Fragen
A. Es verwendet LLMs, um Rohdaten in semantische, strukturierte Funktionen für Modelle des maschinellen Lernens umzuwandeln.
A. Sie wandeln Textual content in dichte Vektoren um, die Bedeutung, Kontext und Beziehungen erfassen, die über die einfache Worthäufigkeit hinausgehen.
A. LLM-basierte Funktionen können inkonsistent, verzerrt, schwer zu interpretieren und riskant sein, wenn sie ohne Validierung verwendet werden.
Hallo! Ich bin Vipin, ein leidenschaftlicher Fanatic für Datenwissenschaft und maschinelles Lernen mit fundierten Kenntnissen in Datenanalyse, Algorithmen für maschinelles Lernen und Programmierung. Ich verfüge über praktische Erfahrung in der Modellerstellung, der Verwaltung unübersichtlicher Daten und der Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu schaffen, die zu Ergebnissen führen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung einzubringen und gleichzeitig weiterhin in den Bereichen Knowledge Science, maschinelles Lernen und NLP zu lernen und mich weiterzuentwickeln.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.