habe ich meine Masterarbeit zum Thema Emotion Recognition in Dialog (ERC) eingereicht. Das Modell, EmoNeterreichte eine gewichtete F1 von 39,18 auf EmoryNLP – konkurrenzfähig mit der damaligen öffentlichen PapersWithCode-Bestenliste, lag zwischen TUCORE-GCN_RoBERTa (39,24) und S+PAGE (39,14) und verbesserte sich gegenüber meiner gewählten Basislinie, CoMPM, um +1,81 F1.
Zwei Jahre später kehrte ich zurück, um mir anzusehen, wo sich das Feld jetzt befindet. Die Bestenliste ist nicht erkennbar. Die Prime-Einträge sind nicht mehr nur Encoder-Modelle mit cleveren Aufmerksamkeitsköpfen – sie sind es LLaMA-2–7B-basierte Systeme mit LoRA-Feinabstimmung und abrufgestützter Eingabeaufforderung: InstructERC, CKERC, BiosERC, LaERC-S. Die Methoden sind unterschiedlich. Die Berechnung ist unterschiedlich. Die Denkweise ist anders.
Und doch – wenn ich diese neuen Papiere sorgfältig lese, Die Kernideen, die ich in EmoNet vorgeschlagen habe, tauchen darin auf, nur auf einer anderen Ebene des Stapels implementiert. Dies ist die Geschichte darüber, was ich gebaut habe, wo es platziert wurde und was ich jetzt bauen würde, wenn ich von vorne anfangen würde.
Was ERC ist und warum es schwierig ist, nur Textual content zu verwenden
Bei der Emotionserkennung im Gespräch geht es darum, jeder Äußerung in einem Dialog mit mehreren Runden eine Emotionsbezeichnung zuzuordnen. Sie unterscheidet sich in einem wichtigen Punkt von der Sentimentanalyse an isolierten Sätzen: Die Emotion einer Äußerung wird durch das Vorangegangene und durch den Sprecher geprägt.
Betrachten Sie diesen Austausch aus dem EmoryNLP-Datensatz (aus der TV-Present). Freunde):
Monica: Wendy, wir hatten einen Deal! Ja, du hast es versprochen! Wendy! Wendy! Wendy! (Verrückt)
Rachel: Wer conflict das? (Impartial)
Monica: Wendy ist abgehauen. Ich habe keine Kellnerin. (Verrückt)
Isoliert: „Wer conflict das?“ ist emotional impartial. Das Etikett Impartial ist nur sinnvoll im Kontext – es liegt zwischen zwei wütenden Äußerungen eines anderen Sprechers und ERC-Modelle müssen diese Gesprächsdynamik erfassen.
Es gibt noch eine zweite Falte: Es fehlen multimodale Informationen. In echten menschlichen Gesprächen tragen Tonfall, Mimik und Körpersprache einen enormen Anteil an emotionalen Signalen. Das reine Textual content-ERC macht das alles überflüssig. Die gleichen Worte – „Oh, großartig.“ – kann aufrichtig oder sarkastisch sein, und der Textual content allein kann oft nicht sagen, was.
Dieser Informationsverlust ist die zentrale Herausforderung. Sie müssen Emotionen aus einem lauteren Sign als dem menschlichen Benchmark extrahieren.
Die Landschaft 2024
Als ich Ende 2023 mit meiner Abschlussarbeit begann, dominierten transformatorbasierte Architekturen mit verschiedenen cleveren Modifikationen die EmoryNLP-Bestenliste. Eine kurze Tour:
– KET (Zhong et al., 2019) – Wissenserweiterter Transformer mit affektiver Graph-Aufmerksamkeit, der erste Artikel, der Transformers zum ERC bringt.
– DialogueGCN (Ghosal et al., 2019) – Graph-Faltungsnetzwerk, das Dialoge in Knotenklassifizierungsprobleme umwandelt.
– RGAT (Ishiwatari et al., 2020) – beziehungsbewusste Graphenaufmerksamkeit mit relationaler Positionskodierung für Sprecherabhängigkeiten.
– DialogXL (Shen et al., 2020) – angepasstes XLNet mit Äußerungswiederholung und Dialog-Selbstaufmerksamkeit.
– HiTrans (Li et al., 2020) – hierarchischer Transformator mit paarweiser Äußerungs-Sprecherüberprüfung als Hilfsaufgabe.
– TUCORE-GCN (Lee & Choi, 2021) – heterogener Dialoggraph mit sprecherbewusstem BERT.
– CoMPM (Lee & Lee, 2021) – kombinierter Dialogkontext mit vortrainierter Gedächtnisverfolgung für den Sprecher.
Ich habe gewählt CoMPM als meine Foundation aus zwei Gründen. Erstens wurde das vorab trainierte Gedächtnis des Sprechers explizit als separates Modul modelliert – was meiner Instinct entsprach WHO ist das Sprechen genauso wichtig wie Was sie sagen. Zweitens conflict seine Architektur modular genug, um sie zu erweitern, ohne sie von Grund auf neu schreiben zu müssen. Das CoMPM-Papier zeigte, dass das Hinzufügen eines vorab trainierten Gedächtnisses zum Kontextmodell einen messbaren Schub brachte – ihre Sprecheridentität blieb jedoch erhalten lokal für jeden Dialog. Sobald ein neues Gespräch begann, wurde alles, was das Mannequin über einen Sprecher erfahren hatte, verworfen.
Das schien ein Downside zu sein, das es wert conflict, gelöst zu werden.
Drei Beiträge, mit Instinct
1. Globale Sprecheridentität
Das Downside. In CoMPM und den meisten früheren Arbeiten sind Sprecher-IDs auf einen einzelnen Dialog beschränkt. Sprecher A in Szene 1 hat keine Beziehung zu Sprecher A in Szene 14, auch wenn es sich um dieselbe Individual handelt. Daher beginnt jeder Dialog kalt.
Die Instinct. Menschen haben charakteristische emotionale Muster. Monica wird über bestimmte Dinge wütend; Phoebe ist zuverlässig fröhlich; Ross hat vorhersehbare Anfälle von Unsicherheit. Wenn ein Modell Informationen darüber enthalten kann diesen speziellen Lautsprecher Über Dialoge hinweg sollte es in der Lage sein, besser kalibrierte Vorhersagen zu treffen, wann dieser Sprecher wieder auftaucht.
Die Umsetzung. Jeder einzelne Sprecher im gesamten Datensatz erhält eine stabile, datensatzweite ID. Das erste Mal Monica Geller erscheint, wird ihr eine ID zugewiesen – sagen wir ID 7 –, die bei ihr bleibt. Bei jedem weiteren Auftritt – über Episoden, Staffeln, Szenen hinweg – bleibt sie ID 7. Das Modell kann nun sprecherspezifische Muster lernen, die bestehen bleiben.
Im Nachhinein klingt das offensichtlich. Im Jahr 2024 funktionierten die Bestenlistenmodelle nicht so.
2. Modul „Sprecherverhalten“.
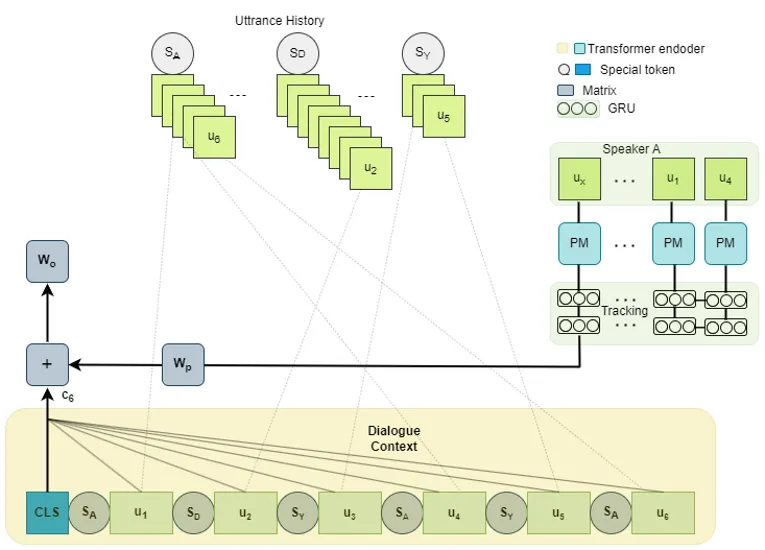
Das Downside. International Speaker Id allein ist nur ein Label. Um es nützlich zu machen, muss das Modell dies tun etwas tun mit der gesammelten Geschichte des Sprechers. Wie geben Sie einem Transformator Zugriff auf „alles, was Monica jemals in diesem Datensatz gesagt hat“, ohne das Kontextfenster zu sprengen oder das Coaching unlösbar zu machen?
Die Instinct. Wiederauftreten. Eine GRU eignet sich hervorragend zum sequentiellen Komprimieren der historischen Äußerungen eines Sprechers in einer einzigen Darstellung mit fester Größe. Aktuelle Äußerungen tragen mehr dazu bei; Ältere verdünnen sich allmählich. Eine konfigurierbare Schiebefenster Begrenzt die Eingabe der GRU – beispielsweise die letzten N-Äußerungen dieses Sprechers – und sorgt so dafür, dass Rechenleistung und Speicher vorhersehbar bleiben.
Die Umsetzung. Jede Äußerung wird unabhängig von einem vorab trainierten RoBERTa-Spine codiert. Die resultierenden Einbettungen fließen durch eine unidirektionale GRU. Der letzte verborgene Zustand der GRU – nennen wir ihn „kt“ – repräsentiert das Verhaltensmuster des Sprechers im aktuellen Second. Dies wird in die gleiche Dimension wie die Ausgabe des Dialogkontexts projiziert und hinzugefügt. Das kombinierte Sign speist den endgültigen Klassifikator.
Die Architektur ähnelt strukturell dem vorab trainierten Speichermodul von CoMPM, weist jedoch zwei wesentliche Unterschiede auf: Der Sprecherverlaufspool ist es world (nicht lokal für den aktuellen Dialog), und die GRU modelliert explizit den zeitlichen Verfall.

3. Gewichteter Kreuzentropieverlust
Das Downside. EmoryNLP ist unausgeglichen – Impartial zahlenmäßig überlegen Traurig um etwa 4,5:1. Die meisten Arbeiten behandeln dies mit Datenerweiterung oder Unterabtastung. Aber Konversationsdaten sind es sequentiell: Das Weglassen oder Duplizieren von Äußerungen verzerrt den natürlichen emotionalen Fluss, der genau das Sign ist, aus dem das Modell lernen möchte.
Die Instinct. Wenn Sie die Daten nicht sicher ändern können, ändern Sie den Verlust. Gewicht seltener Klassen höher, additionally eine einzige Fehlklassifizierung von Traurig kostet das Modell mehr als eine einzige Fehlklassifizierung Impartial.
Die Umsetzung. Kreuzentropie mit Gewichtungen professional Klasse, abgeleitet aus der inversen Klassenhäufigkeit, dann normalisiert. Nichts Exotisches – aber mit dem Argument der Konversationssequenz als expliziter Motivation wird dies eher zu einer prinzipiellen Entscheidung als zu einer willkürlichen.
Ergebnisse: Was hat funktioniert und was hat mich überrascht
Hier ist die Ablationstabelle aus der Arbeit:

Das Ergebnis, das mich überrascht hat – und das meiner Meinung nach der ehrlichste Teil dieser Arbeit ist – ist die zweite Reihe. Allein die Hinzufügung der International Speaker ID verschlechterte das Modell erheblich (F1 fiel von 37,85 auf 29,43). Das sah zunächst wie ein Misserfolg aus.
Aber das conflict es nicht. Die globale Sprecheridentität ist eine Fähigkeit – Es gibt dem Modell die Möglichkeit, Lautsprechermuster mit großer Reichweite zu lernen. Allein diese Fähigkeit erzeugt eine repräsentative Belastung, die der Relaxation des Modells nicht absorbieren könnte. Nur einmal die Modul „Sprecherverhalten“. wurde hinzugefügt – um dem Modell eine strukturierte Möglichkeit zu geben verwenden die globalen Identitäten – tauchte der Beitrag auf. Bis zur endgültigen Konfiguration hatte sich EmoNet erholt und die CoMPM-Basislinie um 1,81 F1 übertroffen.
Dies ist die Lehre, die ich aus der Ablation gezogen habe: Eine Funktion ist für sich genommen nicht wertvoll. In Kombination mit der Maschine, die es verbraucht, ist es wertvoll. In Forschungsarbeiten, die berichten, dass „dieser Zusatz uns + Ich habe mich dafür entschieden, diese Reihe beizubehalten.

Das vollständige Modell behandelt Impartial, FreudeUnd Verängstigt Additionally. Kraftvoll blieb die härteste Klasse – teils weil sie selten vorkommt, teils weil Kraftvoll Und Freude sind in Textgesprächen ohne akustische Hinweise kaum zu unterscheiden. Dies ist ein multimodales Downside, das sich als Textproblem tarnt.
Reflexion (2026): Das Feld hat sich bewegt, und wir sollten es auch tun
Zwei Jahre später sieht die EmoryNLP-Bestenliste völlig anders aus. Die derzeit führenden Systeme sind:
– InstructERC (Lei et al., 2023) – formuliert ERC als generative LLM-Aufgabe neu. Es verwendet abruferweiterte Anweisungsvorlagen und Hilfsaufgaben wie Sprecheridentifikation und Emotionsvorhersage, um Dialogrollen und emotionale Dynamik besser zu modellieren.
– CKERC (Fu, 2024) – führt den durch gesunden Menschenverstand verbesserten ERC ein. Für jede Äußerung generiert ein LLM vernünftige Anmerkungen zur Absicht des Sprechers und zur wahrscheinlichen Reaktion des Zuhörers und liefert so implizite soziale und emotionale Argumente über den expliziten Dialogkontext hinaus.
– BiosERC (Xue et al., 2024) – fügt von LLM abgeleitete biografische Informationen des Sprechers in den ERC-Prozess ein und ermöglicht es dem Modell, nicht nur über den Äußerungskontext, sondern auch über sprecherspezifische Merkmale nachzudenken.
– LaERC-S (Fu et al., 2025) – zweistufige Befehlsoptimierung. Stufe 1: Statten Sie das LLM mit aus sprecherspezifische Eigenschaften. Stufe 2: Nutzen Sie diese Eigenschaften während der ERC-Aufgabe selbst.
Schauen Sie sich die letzten beiden genau an.
Biografische Informationen zum Sprecher des BiosERC ist im Grunde genommen eine vergrößerte globale Sprecheridentität – anstelle einer ganzzahligen ID handelt es sich um ein Textprofil, das der LLM verwalten kann. Eigenschaften des LaERC-S-Lautsprechers sind im Grunde das Modul „Speaker Habits“ – historische Lautsprechermuster, die dem Modell zur Verfügung gestellt werden – aber in die Befehlsabstimmung integriert und nicht als separate GRU implementiert.
Die architektonischen Intuitionen hielten stand. Die Implementierungsschicht hat sich geändert.
Das ist der Teil, den ich wirklich interessant finde. Als ich 2024 an EmoNet arbeitete, dachte ich innerhalb des Encoder-only-Transformer-Paradigmas nach: „Wie füge ich der Architektur ein weiteres Modul hinzu?“ Die Papiere von 2024–2025 denken innerhalb des LLM-Paradigmas: „Wie codiere ich diese Idee in den Unterrichtsoptimierungs- oder Abrufkontext?“ Die Ideen sind ähnlich; Die Hebelpunkte sind unterschiedlich.
Wenn ich EmoNet heute neu aufbauen würdeich würde nicht von RoBERTa-large ausgehen. Ich würde mit einem kleinen Open-Supply-LLM beginnen – LLaMA-3.2–3B, Qwen-2.5–3B oder Phi-3.5 – und verwenden LoRA um es auf EmoryNLP zu verfeinern und dabei der InstructERC-Ansatzfamilie zu folgen. Die globale Sprecheridentität wird zu einer textuellen Sprecherbiografie, die aus einem Vektorspeicher abgerufen wird. Das Modul „Sprecherverhalten“ wird zu einer Kurzaufforderung mit der jüngsten emotionalen Vergangenheit des Sprechers. Der gewichtete Verlust bleibt nahezu unverändert – das Klassenungleichgewicht spielt keine Rolle, welches Modell Sie verwenden.
Das Architekturdiagramm würde völlig anders aussehen. Die konzeptionelle Verschuldung gegenüber der These von 2024 wäre sichtbar, wenn man wüsste, wo man suchen muss.
Es hat mich gelehrt, dass Forschungsschulden eine längere Halbwertszeit haben, als ich erwartet hatte – Ideen überleben Paradigmenwechsel, selbst wenn ihre Umsetzung dies nicht tut.
Wohin mich das führt
EmoNet ist jetzt öffentlich archiviert unter DOI 10.5281/zenodo.20048006 mit der vollständigen Dissertation, Verteidigungsfolien und der PyTorch-Implementierung GitHub. Ich arbeite derzeit an der modernisierten Portierung – einem LoRA-fein abgestimmten LLM mit abrufbasiertem Sprecherkontext – als Folgeprojekt, über das ich bald schreiben werde.
Wenn Sie an Konversations-KI, angewandtem NLP oder LLM-Feinabstimmung arbeiten, würde es mich interessieren, was Sie entwickeln.