# Einführung
Sie haben wahrscheinlich eine Frage in eine Suchleiste eingegeben und Ergebnisse erhalten, die mit Ihren Worten übereinstimmten, deren Bedeutung jedoch völlig verfehlt wurde. Oder einen gesehen Empfehlungsmaschine etwas unheimlich Relevantes ans Licht bringen, auch wenn Sie nie direkt danach gesucht haben. Die Lücke zwischen „genauen Wörtern finden“ und „verstehen, was jemand tatsächlich meint“ macht eine Suchfunktion aus nützlich.
Vektorsuche schließt diese Lücke, indem es Textual content als Punkte im hochdimensionalen Raum darstellt, in dem geometrische Nähe semantische Ähnlichkeit kodiert. Zwei Sätze können null Wörter gemeinsam haben und am Ende trotzdem Nachbarn sein, weil das Modell gelernt hat, dass ihre Bedeutungen nahe beieinander liegen.
In diesem Artikel wird nur eine Vektorsuchmaschine in Python von Grund auf erstellt NumPysodass Sie genau sehen können, was bei jedem Schritt passiert: wie Einbettungen gespeichert und normalisiert werden, warum sich die Kosinusähnlichkeit auf ein Skalarprodukt reduziert und wie der resultierende Suchraum tatsächlich aussieht, wenn Sie ihn auf zwei Dimensionen projizieren.
Den Code erhalten Sie auf GitHub.
# Was ist Vektorsuche?
Traditionelle Stichwortsuche sucht nach exakten Wortübereinstimmungen. Die Vektorsuche funktioniert anders: Sie wandelt Dokumente und Abfragen in numerische Vektoren, sogenannte Einbettungen, um und findet dann die Vektoren, die im hochdimensionalen Raum am nächsten beieinander liegen.
Die wichtigste Erkenntnis ist das Nähe im Vektorraum bedeutet semantische Ähnlichkeit. Zwei Sätze, die dasselbe bedeuten – auch wenn sie keine Wörter gemeinsam haben – haben Einbettungen, die nahe beieinander liegen.
Die Entfernungsmetrik, die Sie zur Messung der „Nähe“ verwenden, ist der Antrieb für das gesamte System. Das häufigste ist Kosinusähnlichkeitder den Winkel zwischen zwei Vektoren und nicht ihren absoluten Abstand misst. Dies macht es skaleninvariant – nützlich, wenn Ihnen die Richtung oder Bedeutung wichtiger ist als die Größe oder Wortanzahl.
# Einrichten des Datensatzes
Wir arbeiten mit einer Reihe kurzer Produktbeschreibungen aus einem fiktiven E-Commerce-Katalog. Diese sind als 8-dimensionale Vektoren vorab eingebettet – eine stark reduzierte Dimensionalität, die realistisch genug ist, um die Konzepte zu demonstrieren.
In einem realen System würden Sie diese Einbettungen aus einem Modell wie generieren Satztransformatoren. Für dieses Tutorial simulieren wir diesen Schritt mit kontrollierten Zufallsdaten, die eine klare Clusterstruktur aufweisen.
import numpy as np
np.random.seed(42)
# Product catalog — 3 semantic clusters: electronics, clothes, furnishings
merchandise = (
"Wi-fi noise-cancelling headphones with 30-hour battery",
"Bluetooth speaker with waterproof design",
"USB-C hub with 7 ports and energy supply",
"4K HDMI cable 6ft braided",
"Mechanical keyboard with RGB backlight",
"Males's slim-fit chino pants navy blue",
"Ladies's merino wool turtleneck sweater",
"Unisex working jacket light-weight windbreaker",
"Leather-based chelsea boots for males",
"Natural cotton crew neck t-shirt",
"Stable oak eating desk seats 6",
"Ergonomic mesh workplace chair lumbar assist",
"Linen couch 3-seater pure beige",
"Bamboo bookshelf 5-tier adjustable",
"Reminiscence foam mattress queen dimension medium agency",
)
# Simulate embeddings with cluster construction
# Cluster facilities in 8D house
electronics_center = np.array((0.9, 0.1, 0.2, 0.8, 0.1, 0.3, 0.7, 0.2))
clothing_center = np.array((0.1, 0.8, 0.7, 0.1, 0.9, 0.2, 0.1, 0.8))
furniture_center = np.array((0.2, 0.3, 0.9, 0.2, 0.1, 0.9, 0.3, 0.1))
n_per_cluster = 5
noise = 0.08
embeddings = np.vstack((
electronics_center + np.random.randn(n_per_cluster, 8) * noise,
clothing_center + np.random.randn(n_per_cluster, 8) * noise,
furniture_center + np.random.randn(n_per_cluster, 8) * noise,
))
print(f"Embeddings form: {embeddings.form}")Ausgabe:
Embeddings form: (15, 8)Jede Zeile ist ein Produkt. Jede Spalte ist eine Dimension ihrer Einbettung. Die Produktnamen werden von der Suchmaschine nicht verwendet; Nur die Einbettungen sind wichtig.
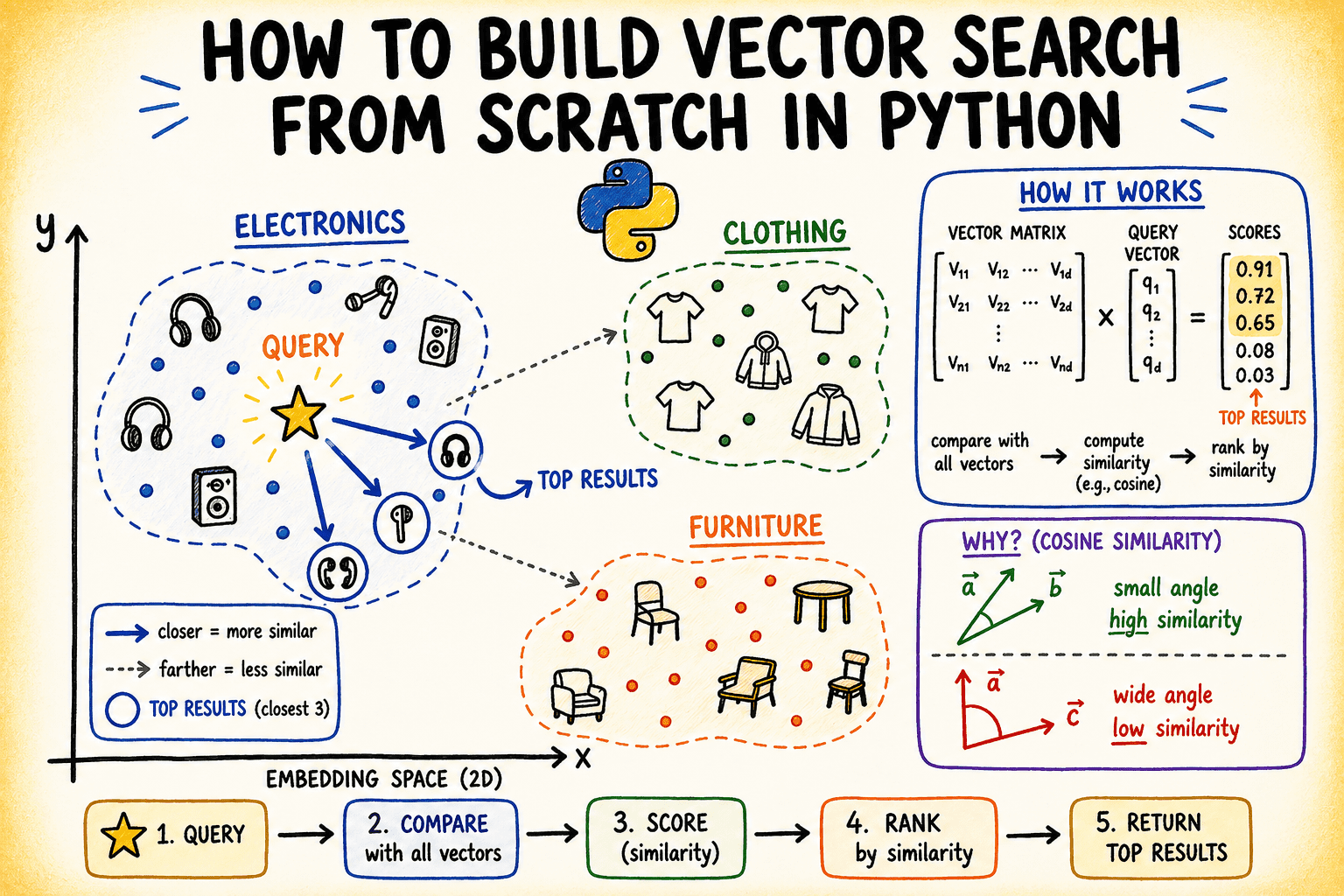
Bild vom Autor
# Erstellen des Index
Der „Index“ in einer Vektorsuchmaschine ist lediglich der gespeicherte Satz normalisierter Einbettungen. Die Normalisierung ist hier wichtig, da dadurch die Kosinusähnlichkeit einem Skalarprodukt entspricht, was kostengünstiger zu berechnen ist.
def normalize(vectors: np.ndarray) -> np.ndarray:
"""L2-normalize every row vector."""
norms = np.linalg.norm(vectors, axis=1, keepdims=True)
# Keep away from division by zero
norms = np.the place(norms == 0, 1e-10, norms)
return vectors / norms
class VectorIndex:
def __init__(self):
self.vectors = None
self.labels = None
def add(self, vectors: np.ndarray, labels: listing):
self.vectors = normalize(vectors)
self.labels = labels
print(f"Listed {len(labels)} gadgets with {vectors.form(1)}-dimensional embeddings.")
def search(self, query_vector: np.ndarray, top_k: int = 3):
query_norm = normalize(query_vector.reshape(1, -1))
# Cosine similarity = dot product of normalized vectors
scores = self.vectors @ query_norm.T # form: (n_items, 1)
scores = scores.flatten()
# Get top-k indices sorted by descending rating
top_indices = np.argsort(scores)(::-1)(:top_k)
return ((self.labels(i), float(scores(i))) for i in top_indices)
index = VectorIndex()
index.add(embeddings, merchandise)Ausgabe:
Listed 15 gadgets with 8-dimensional embeddings.Der search Die Methode führt drei Dinge aus: Sie normalisiert die Abfrage, berechnet Skalarprodukte für jeden gespeicherten Vektor, sortiert dann nach Punktzahl und gibt die High-k-Ergebnisse zurück. Diese Matrixmultiplikation (self.vectors @ query_norm.T) ist der gesamte Abrufschritt.
# Ausführen von Abfragen
Lassen Sie uns nun mit ein paar Abfragen testen, was wir erstellt haben. Wir konstruieren Abfragevektoren, indem wir von einem der Clusterzentren ausgehen und ein wenig Rauschen hinzufügen, um eine echte Abfrageeinbettung zu simulieren.
def make_query(middle: np.ndarray, noise_scale: float = 0.05) -> np.ndarray:
return middle + np.random.randn(8) * noise_scale
queries = {
"audio gear": make_query(electronics_center),
"informal put on": make_query(clothing_center),
"house furnishings": make_query(furniture_center),
}
for query_name, q_vec in queries.gadgets():
print(f"nQuery: '{query_name}'")
outcomes = index.search(q_vec, top_k=3)
for rank, (label, rating) in enumerate(outcomes, 1):
print(f" {rank}. ({rating:.4f}) {label}")Ausgabe:
Question: 'audio gear'
1. (0.9856) Wi-fi noise-cancelling headphones with 30-hour battery
2. (0.9840) USB-C hub with 7 ports and energy supply
3. (0.9829) Mechanical keyboard with RGB backlight
Question: 'informal put on'
1. (0.9960) Males's slim-fit chino pants navy blue
2. (0.9958) Leather-based chelsea boots for males
3. (0.9916) Ladies's merino wool turtleneck sweater
Question: 'house furnishings'
1. (0.9929) Bamboo bookshelf 5-tier adjustable
2. (0.9902) Linen couch 3-seater pure beige
3. (0.9881) Stable oak eating desk seats 6Werte nahe 1,0 bedeuten eine nahezu identische Richtung im Einbettungsraum, was genau das ist, was Sie für Abfragen erwarten, die aus demselben Clusterzentrum wie ihre Zieldokumente erstellt wurden.
# Visualisierung des Einbettungsraums
Hochdimensionale Daten sind visuell schwer zu verstehen. Hauptkomponentenanalyse (PCA) projiziert die 8-dimensionalen Einbettungen auf 2D, damit wir die Clusterstruktur sehen können. Wir werden eine minimale PCA nur mit NumPy implementieren.
Der folgende Code berechnet die 2D-PCA-Projektion und stellt alle Produkteinbettungen mit Beschriftungen und Clusterfarben dar:
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
projected = pca_2d(embeddings)
cluster_colors = (
("#4A90D9") * 5 + # electronics — blue
("#E8734A") * 5 + # clothes — orange
("#5BAD72") * 5 # furnishings — inexperienced
)
cluster_labels = ("Electronics") * 5 + ("Clothes") * 5 + ("Furnishings") * 5
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(projected(:, 0), projected(:, 1),
c=cluster_colors, s=100, edgecolors="white", linewidths=0.7, zorder=3)Dieser Teil projiziert Abfragevektoren in denselben Raum, überlagert sie und stellt die Darstellung fertig:
# Plot question projections
q_projected = pca_2d(
np.vstack(listing(queries.values())) - embeddings.imply(axis=0)
)
for (qname, _), (qx, qy) in zip(queries.gadgets(), q_projected):
ax.scatter(qx, qy, marker="*", s=200, coloration="gold",
edgecolors="#333", linewidths=0.6, zorder=4)
ax.annotate(f"⟵ question: {qname}", (qx, qy),
textcoords="offset factors", xytext=(6, -8),
fontsize=7, coloration="#555555", type="italic")
legend_patches = (
mpatches.Patch(coloration="#4A90D9", label="Electronics"),
mpatches.Patch(coloration="#E8734A", label="Clothes"),
mpatches.Patch(coloration="#5BAD72", label="Furnishings"),
mpatches.Patch(coloration="gold", label="Question vectors"),
)
ax.legend(handles=legend_patches, loc="higher left", fontsize=6)
ax.set_title("Vector Search — Embedding House (PCA projection)", fontsize=10, pad=10)
ax.set_xlabel("PC 1"); ax.set_ylabel("PC 2")
ax.grid(True, linestyle="--", alpha=0.4)
plt.tight_layout()
plt.savefig("embedding_space_queries_only.png", dpi=150)
plt.present()Ausgabe:
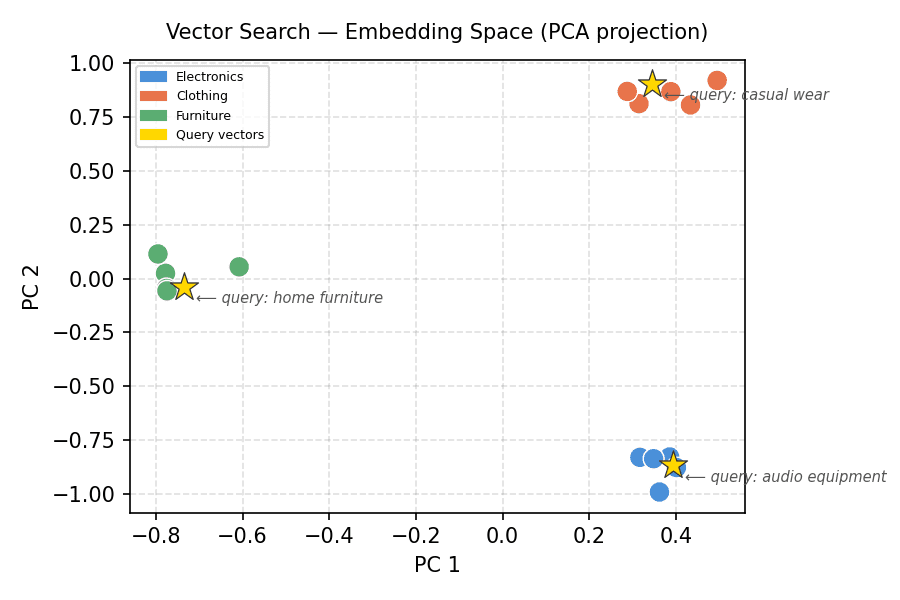
Vektorsuche – Einbettungsraum (PCA-Projektion)
Die Cluster trennen sich sauber. Jeder Goldstern (Abfragevektor) landet innerhalb des Clusters, aus dem er konstruiert wurde. Dies ist die Geometrie, die die Vektorsuche nutzt.
# Visualisierung der Ähnlichkeitsbewertungsverteilung
Für jede beliebige Abfrage ist es hilfreich zu sehen, wie die Ähnlichkeitswerte über den gesamten Index verteilt sind – und nicht nur über die High-Ok. Dadurch erfahren Sie, ob das High-Ergebnis ein klarer Gewinner ist oder nur geringfügig besser als alles andere.
q_vec_furniture = queries("house furnishings")
q_norm_furniture = normalize(q_vec_furniture.reshape(1, -1))
all_scores_furniture = (index.vectors @ q_norm_furniture.T).flatten()
sorted_idx_furniture = np.argsort(all_scores_furniture)(::-1)
sorted_scores_furniture = all_scores_furniture(sorted_idx_furniture)
sorted_labels_furniture = (merchandise(i)(:30) + "…" if len(merchandise(i)) > 30
else merchandise(i) for i in sorted_idx_furniture)
# Outline bar colours: inexperienced for furnishings gadgets, grey for others
bar_colors_furniture = ()
for i in sorted_idx_furniture:
if i >= 10 and that i <= 14: # Furnishings gadgets are initially at indices 10-14
bar_colors_furniture.append("#5BAD72") # Inexperienced for furnishings
else:
bar_colors_furniture.append("#cccccc") # Grey for others
fig, ax = plt.subplots(figsize=(10, 5))
bars = ax.barh(sorted_labels_furniture(::-1), sorted_scores_furniture(::-1),
coloration=bar_colors_furniture(::-1), edgecolor="white", top=0.65)
ax.axvline(sorted_scores_furniture(2), coloration="#5BAD72", linestyle="--",
linewidth=1.2, label="High-3 cutoff")
ax.set_xlim(sorted_scores_furniture.min() - 0.002, 1.001)
ax.set_xlabel("Cosine Similarity Rating")
ax.set_title("Question: 'house furnishings' — Similarity Throughout All Merchandise", fontsize=11, pad=12)
ax.legend(fontsize=8)
ax.grid(axis="x", linestyle="--", alpha=0.4)
plt.tight_layout()
plt.savefig("score_distribution_furniture.png", dpi=150)
plt.present()Ausgabe:
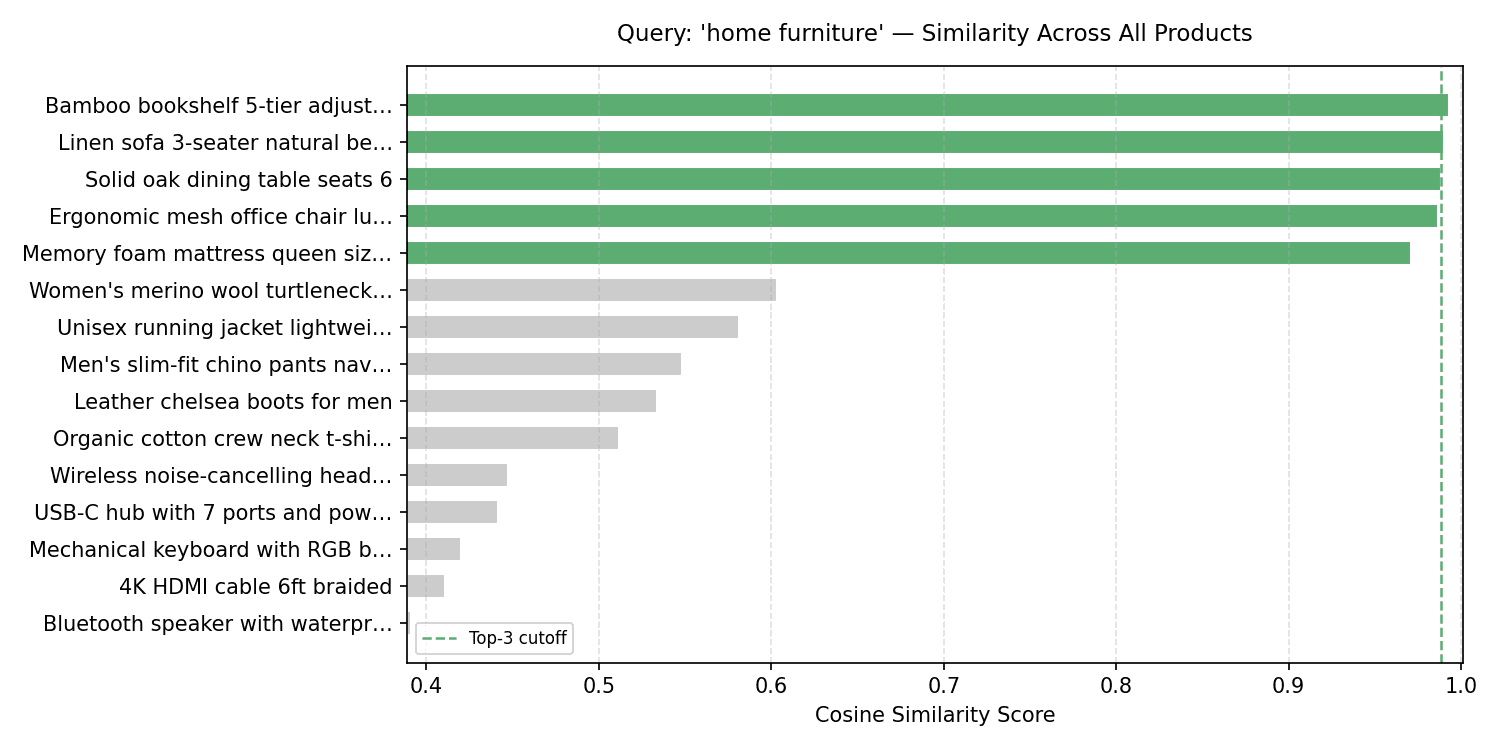
Suchanfrage: „Wohnmöbel“ – Ähnlichkeit aller Produkte
Es gibt eine sichtbare Lücke zwischen der Möbelgruppe (obere 5 Balken) und allem anderen. In der Praxis würden Sie diese Lücke nutzen, um einen Ähnlichkeitsschwellenwert festzulegen, unterhalb dessen Ergebnisse vollständig unterdrückt werden.
# Zusammenfassung
Sie haben eine Vektorsuchmaschine mit etwa 50 Zeilen NumPy erstellt: eine Indexklasse, die Einbettungen normalisiert und speichert, eine Suchmethode, die Matrixmultiplikation zur Berechnung der Kosinusähnlichkeit verwendet, und zwei Visualisierungen, die die Geometrie hinter den Ergebnissen offenbaren.
Der nächste Schritt besteht darin, die simulierten Einbettungen durch echte zu ersetzen. Versuchen Sie, Satztransformatoren zu laden und Ihren eigenen Textkorpus einzubetten. Der Indexcode hier funktioniert ohne Änderungen.
Wenn Sie weitere Artikel „von Grund auf“ lesen möchten, teilen Sie uns mit, was Sie als Nächstes sehen möchten!
Bala Priya C ist ein Entwickler und technischer Redakteur aus Indien. Sie arbeitet gerne an der Schnittstelle von Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Zu ihren Interessen- und Fachgebieten gehören DevOps, Datenwissenschaft und Verarbeitung natürlicher Sprache. Sie liebt es zu lesen, zu schreiben, zu programmieren und Kaffee zu trinken! Derzeit arbeitet sie daran, zu lernen und ihr Wissen mit der Entwickler-Neighborhood zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst. Bala erstellt außerdem ansprechende Ressourcenübersichten und Programmier-Tutorials.