

Bild vom Herausgeber
# Einführung
Synthetische Daten werden, wie der Title schon sagt, künstlich erstellt und nicht aus realen Quellen gesammelt. Es sieht aus wie echte Daten, vermeidet jedoch Datenschutzprobleme und hohe Kosten für die Datenerfassung. Dies ermöglicht Ihnen das einfache Testen von Software program und Modellen während der Durchführung von Experimenten, um die Leistung nach der Veröffentlichung zu simulieren.
Während Bibliotheken mögen Schwindler, SDVUnd SynthCity Es gibt zwar viele Sprachen – und selbst große Sprachmodelle (LLMs) werden häufig zur Generierung synthetischer Daten verwendet – mein Schwerpunkt in diesem Artikel liegt darauf, mich nicht auf diese externen Bibliotheken oder KI-Instruments zu verlassen. Stattdessen erfahren Sie, wie Sie die gleichen Ergebnisse erzielen, indem Sie Ihre eigenen Texte schreiben Python Skripte. Dies ermöglicht ein besseres Verständnis dafür, wie ein Datensatz geformt wird und wie Verzerrungen oder Fehler entstehen. Wir beginnen mit einfachen Spielzeugskripten, um die verfügbaren Optionen zu verstehen. Sobald Sie diese Grundlagen verstanden haben, können Sie problemlos zu Spezialbibliotheken wechseln.
# 1. Generieren einfacher Zufallsdaten
Der einfachste Ausgangspunkt ist ein Tisch. Wenn Sie beispielsweise einen gefälschten Kundendatensatz für eine interne Demo benötigen, können Sie ein Skript ausführen, um Daten mit durch Kommas getrennten Werten (CSV) zu generieren:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
nations = ("Canada", "UK", "UAE", "Germany", "USA")
plans = ("Free", "Primary", "Professional", "Enterprise")
def random_signup_date():
begin = datetime(2024, 1, 1)
finish = datetime(2026, 1, 1)
delta_days = (finish - begin).days
return (begin + timedelta(days=random.randint(0, delta_days))).date().isoformat()
rows = ()
for i in vary(1, 1001):
age = random.randint(18, 70)
nation = random.alternative(nations)
plan = random.alternative(plans)
monthly_spend = spherical(random.uniform(0, 500), 2)
rows.append({
"customer_id": f"CUST{i:05d}",
"age": age,
"nation": nation,
"plan": plan,
"monthly_spend": monthly_spend,
"signup_date": random_signup_date()
})
with open("clients.csv", "w", newline="", encoding="utf-8") as f:
author = csv.DictWriter(f, fieldnames=rows(0).keys())
author.writeheader()
author.writerows(rows)
print("Saved clients.csv")Ausgabe:
Dieses Skript ist unkompliziert: Sie definieren Felder, wählen Bereiche aus und schreiben Zeilen. Der random Das Modul unterstützt die Generierung von Ganzzahlen, Gleitkommawerten, Zufallsauswahl und Stichproben. Der csv Das Modul dient zum Lesen und Schreiben zeilenbasierter Tabellendaten. Diese Artwork von Datensatz eignet sich für:
- Frontend-Demos
- Dashboard-Checks
- API-Entwicklung
- Erlernen der strukturierten Abfragesprache (SQL)
- Unit-Testing von Eingabepipelines
Dieser Ansatz hat jedoch eine wesentliche Schwäche: Alles ist völlig zufällig. Dies führt oft zu Daten, die flach oder unnatürlich aussehen. Unternehmenskunden geben möglicherweise nur 2 Greenback aus, während „kostenlose“ Benutzer möglicherweise 400 ausgeben. Ältere Benutzer verhalten sich genauso wie jüngere, da keine zugrunde liegende Struktur vorhanden ist.
In realen Szenarien verhalten sich Daten selten so. Anstatt Werte eigenständig zu generieren, können wir Beziehungen und Regeln einführen. Dadurch fühlt sich der Datensatz realistischer an und bleibt gleichzeitig vollständig synthetisch. Zum Beispiel:
- Unternehmenskunden sollten quick nie keine Ausgaben tätigen
- Die Ausgabenspanne sollte vom ausgewählten Plan abhängen
- Ältere Nutzer geben im Durchschnitt möglicherweise etwas mehr aus
- Bestimmte Pläne sollten häufiger vorkommen als andere
Fügen wir dem Skript diese Steuerelemente hinzu:
import csv
import random
random.seed(42)
plans = ("Free", "Primary", "Professional", "Enterprise")
def choose_plan():
roll = random.random()
if roll < 0.45:
return "Free"
if roll < 0.75:
return "Primary"
if roll < 0.93:
return "Professional"
return "Enterprise"
def generate_spend(age, plan):
if plan == "Free":
base = random.uniform(0, 10)
elif plan == "Primary":
base = random.uniform(10, 60)
elif plan == "Professional":
base = random.uniform(50, 180)
else:
base = random.uniform(150, 500)
if age >= 40:
base *= 1.15
return spherical(base, 2)
rows = ()
for i in vary(1, 1001):
age = random.randint(18, 70)
plan = choose_plan()
spend = generate_spend(age, plan)
rows.append({
"customer_id": f"CUST{i:05d}",
"age": age,
"plan": plan,
"monthly_spend": spend
})
with open("controlled_customers.csv", "w", newline="", encoding="utf-8") as f:
author = csv.DictWriter(f, fieldnames=rows(0).keys())
author.writeheader()
author.writerows(rows)
print("Saved controlled_customers.csv")Ausgabe:
Jetzt behält der Datensatz aussagekräftige Muster bei. Anstatt zufälliges Rauschen zu erzeugen, simulieren Sie Verhaltensweisen. Zu wirksamen Kontrollen können gehören:
- Gewichtete Kategorieauswahl
- Realistische Mindest- und Höchstreichweiten
- Bedingte Logik zwischen Spalten
- Absichtlich hinzugefügte seltene Randfälle
- Fehlende Werte werden zu geringen Raten eingefügt
- Korrelierte Merkmale statt unabhängiger
# 2. Simulationsprozesse für synthetische Daten
Die simulationsbasierte Generierung ist eine der besten Möglichkeiten, realistische synthetische Datensätze zu erstellen. Anstatt Spalten direkt zu füllen, simulieren Sie einen Prozess. Stellen Sie sich zum Beispiel ein kleines Lager vor, in dem Bestellungen eingehen, der Lagerbestand abnimmt und niedrige Lagerbestände zu Lieferrückständen führen.
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
stock = {
"A": 120,
"B": 80,
"C": 50
}
rows = ()
current_time = datetime(2026, 1, 1)
for day in vary(30):
for product in stock:
daily_orders = random.randint(0, 12)
for _ in vary(daily_orders):
qty = random.randint(1, 5)
earlier than = stock(product)
if stock(product) >= qty:
stock(product) -= qty
standing = "fulfilled"
else:
standing = "backorder"
rows.append({
"time": current_time.isoformat(),
"product": product,
"qty": qty,
"stock_before": earlier than,
"stock_after": stock(product),
"standing": standing
})
if stock(product) < 20:
restock = random.randint(30, 80)
stock(product) += restock
rows.append({
"time": current_time.isoformat(),
"product": product,
"qty": restock,
"stock_before": stock(product) - restock,
"stock_after": stock(product),
"standing": "restock"
})
current_time += timedelta(days=1)
with open("warehouse_sim.csv", "w", newline="", encoding="utf-8") as f:
author = csv.DictWriter(f, fieldnames=rows(0).keys())
author.writeheader()
author.writerows(rows)
print("Saved warehouse_sim.csv")Ausgabe:
Diese Methode ist hervorragend, da die Daten ein Nebenprodukt des Systemverhaltens sind, das in der Regel realistischere Beziehungen liefert als die direkte Generierung zufälliger Zeilen. Weitere Simulationsideen sind:
- Warteschlangen im Callcenter
- Fahrtanfragen und Fahrerzuordnung
- Kreditanträge und Genehmigungen
- Abonnements und Abwanderung
- Ablauf der Patiententermine
- Web site-Visitors und Conversion
# 3. Generieren synthetischer Zeitreihendaten
Synthetische Daten sind nicht nur auf statische Tabellen beschränkt. Viele Systeme erzeugen im Laufe der Zeit Sequenzen, wie z. B. App-Verkehr, Sensorwerte, Bestellungen professional Stunde oder Server-Reaktionszeiten. Hier ist ein einfacher Zeitreihengenerator für stündliche Web site-Besuche mit Wochentagsmustern.
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
begin = datetime(2026, 1, 1, 0, 0, 0)
hours = 24 * 30
rows = ()
for i in vary(hours):
ts = begin + timedelta(hours=i)
weekday = ts.weekday()
base = 120
if weekday >= 5:
base = 80
hour = ts.hour
if 8 <= hour <= 11:
base += 60
elif 18 <= hour <= 21:
base += 40
elif 0 <= hour <= 5:
base -= 30
visits = max(0, int(random.gauss(base, 15)))
rows.append({
"timestamp": ts.isoformat(),
"visits": visits
})
with open("traffic_timeseries.csv", "w", newline="", encoding="utf-8") as f:
author = csv.DictWriter(f, fieldnames=("timestamp", "visits"))
author.writeheader()
author.writerows(rows)
print("Saved traffic_timeseries.csv")Ausgabe:
Dieser Ansatz funktioniert intestine, weil er Tendencies, Rauschen und zyklisches Verhalten berücksichtigt und gleichzeitig leicht zu erklären und zu debuggen ist.
# 4. Erstellen von Ereignisprotokollen
Ereignisprotokolle sind ein weiterer nützlicher Skriptstil, der sich very best für Produktanalysen und Workflow-Checks eignet. Anstelle einer Zeile professional Kunde erstellen Sie eine Zeile professional Aktion.
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
occasions = ("signup", "login", "view_page", "add_to_cart", "buy", "logout")
rows = ()
begin = datetime(2026, 1, 1)
for user_id in vary(1, 201):
event_count = random.randint(5, 30)
current_time = begin + timedelta(days=random.randint(0, 10))
for _ in vary(event_count):
occasion = random.alternative(occasions)
if occasion == "buy" and random.random() < 0.6:
worth = spherical(random.uniform(10, 300), 2)
else:
worth = 0.0
rows.append({
"user_id": f"USER{user_id:04d}",
"event_time": current_time.isoformat(),
"event_name": occasion,
"event_value": worth
})
current_time += timedelta(minutes=random.randint(1, 180))
with open("event_log.csv", "w", newline="", encoding="utf-8") as f:
author = csv.DictWriter(f, fieldnames=rows(0).keys())
author.writeheader()
author.writerows(rows)
print("Saved event_log.csv")Ausgabe:
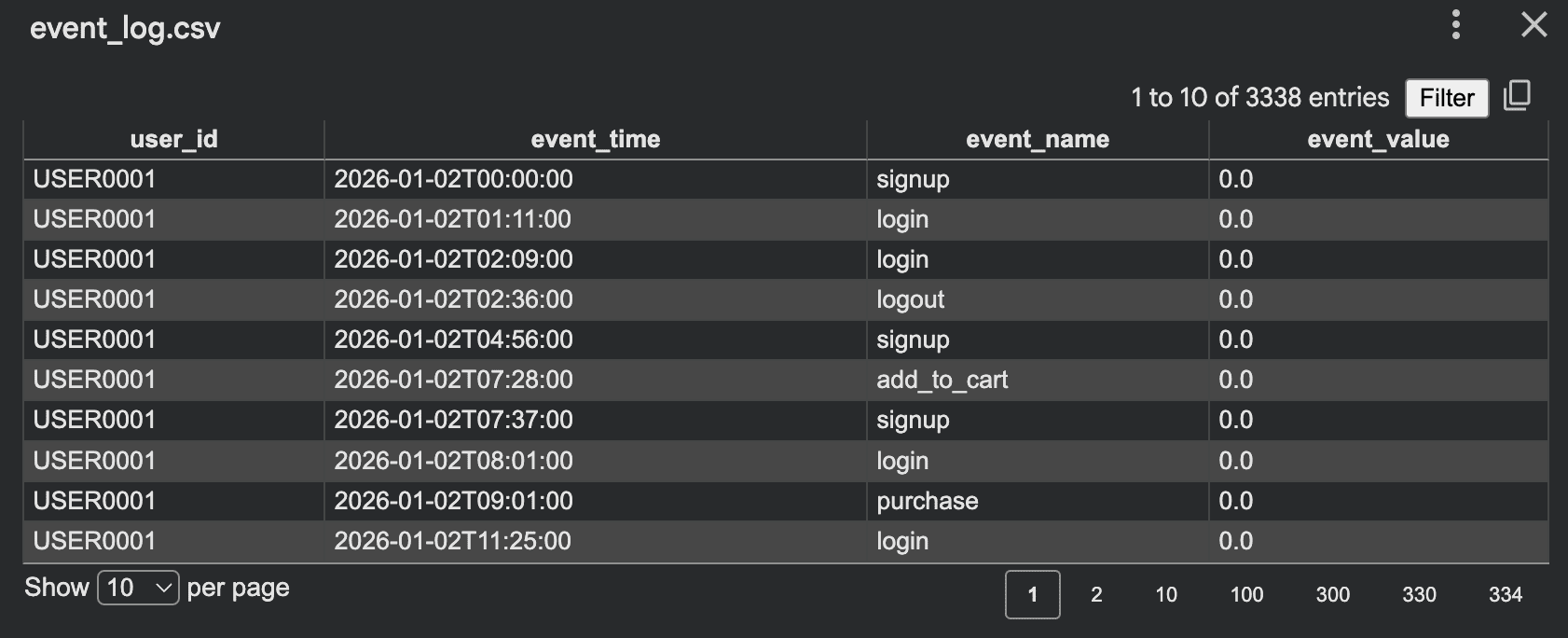
Dieses Format ist nützlich für:
- Trichteranalyse
- Analyse-Pipeline-Checks
- Enterprise Intelligence (BI)-Dashboards
- Sitzungsrekonstruktion
- Experimente zur Anomalieerkennung
Eine nützliche Technik besteht darin, Ereignisse von früheren Aktionen abhängig zu machen. Beispielsweise sollte ein Kauf typischerweise auf eine Anmeldung oder einen Seitenaufruf folgen, um das synthetische Protokoll glaubwürdiger zu machen.
# 5. Generieren synthetischer Textdaten mit Vorlagen
Synthetische Daten sind auch für die Verarbeitung natürlicher Sprache (NLP) wertvoll. Sie benötigen nicht immer einen LLM, um zu beginnen. Mithilfe von Vorlagen und kontrollierter Variation können Sie effektive Textdatensätze erstellen. Sie können beispielsweise Help-Ticket-Schulungsdaten erstellen:
import json
import random
random.seed(42)
points = (
("billing", "I used to be charged twice for my subscription"),
("login", "I can't log into my account"),
("delivery", "My order has not arrived but"),
("refund", "I wish to request a refund"),
)
tones = ("Please assist", "That is pressing", "Are you able to examine this", "I would like assist")
data = ()
for _ in vary(100):
label, message = random.alternative(points)
tone = random.alternative(tones)
textual content = f"{tone}. {message}."
data.append({
"textual content": textual content,
"label": label
})
with open("support_tickets.jsonl", "w", encoding="utf-8") as f:
for merchandise in data:
f.write(json.dumps(merchandise) + "n")
print("Saved support_tickets.jsonl")Ausgabe:
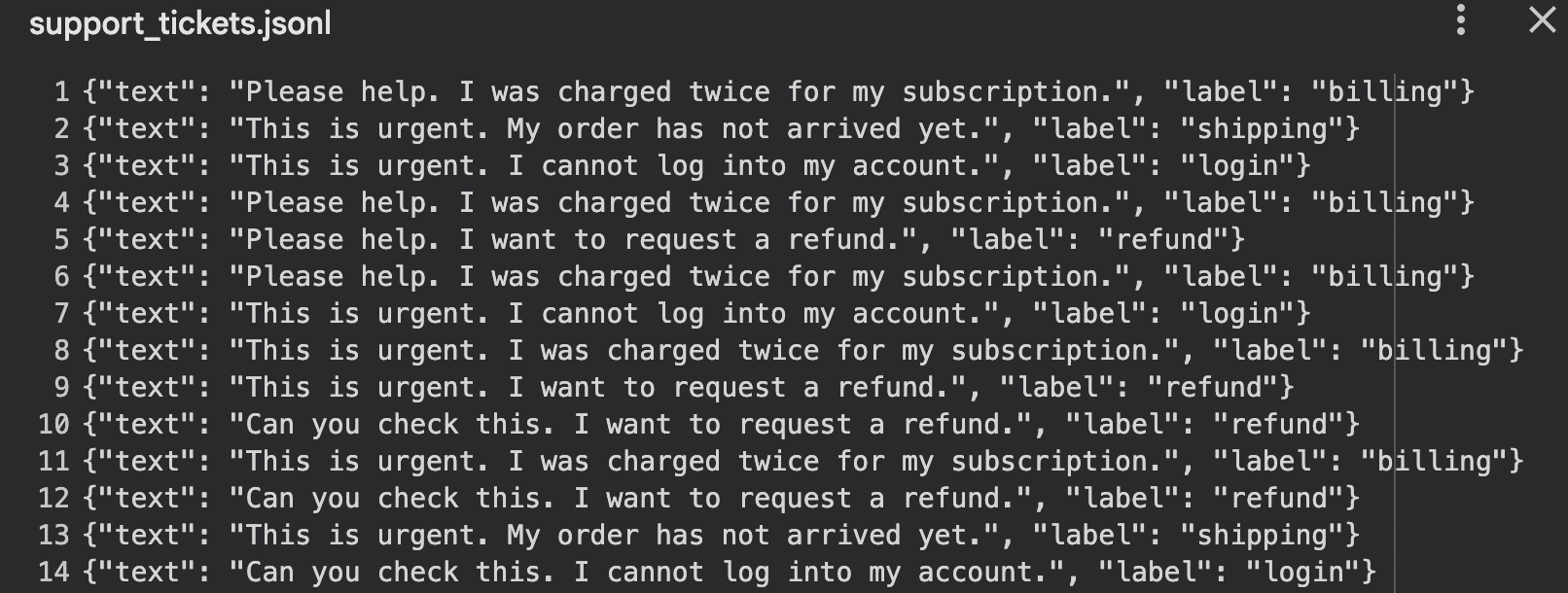
Dieser Ansatz eignet sich intestine für:
- Demos zur Textklassifizierung
- Absichtserkennung
- Chatbot-Checks
- Prompte Bewertung
# Letzte Gedanken
Synthetische Datenskripte sind leistungsstarke Werkzeuge, können jedoch falsch implementiert werden. Vermeiden Sie unbedingt diese häufigen Fehler:
- Alle Werte einheitlich zufällig machen
- Abhängigkeiten zwischen Feldern vergessen
- Generieren von Werten, die gegen die Geschäftslogik verstoßen
- Es wird davon ausgegangen, dass synthetische Daten standardmäßig von Natur aus sicher sind
- Erstellen von Daten, die zu „sauber“ sind, um zum Testen realer Randfälle nützlich zu sein
- Verwenden Sie dasselbe Muster so häufig, dass der Datensatz vorhersehbar und unrealistisch wird
Der Datenschutz bleibt der wichtigste Aspekt. Obwohl synthetische Daten die Gefährdung durch reale Aufzeichnungen verringern, sind sie nicht risikofrei. Wenn ein Generator zu eng mit den ursprünglichen sensiblen Daten verknüpft ist, kann es dennoch zu Datenlecks kommen. Aus diesem Grund sind Methoden zur Wahrung der Privatsphäre, wie z. B. differenziell personal synthetische Daten, unerlässlich.
Kanwal Mehreen ist ein Ingenieur für maschinelles Lernen und ein technischer Redakteur mit einer großen Leidenschaft für Datenwissenschaft und die Schnittstelle zwischen KI und Medizin. Sie ist Mitautorin des E-Books „Maximizing Productiveness with ChatGPT“. Als Google Technology Scholar 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie ist außerdem als Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar und Harvard WeCode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter von Veränderungen und hat FEMCodes gegründet, um Frauen in MINT-Bereichen zu stärken.