

# SQL + Python ist einfach nicht genug
Jahrelang schien die Formel einfach: SQL lernen + Python lernen = einen Datenjob bekommen. Vor allem, als mittelständische Unternehmen begannen, „datengesteuert“ zu werden. Die Personalmanager waren froh, dass sie jeden finden konnten, der halbwegs intestine schreiben konnte GROUP BY und einen Pandas DataFrame streiten, ohne etwas kaputt zu machen. Wissen Sie, was PostgreSQL ist? Steigen Sie ein, Sie haben den Job! Das hat einige Zeit funktioniert. Bis das nicht der Fall conflict.
Falls Sie es noch nicht bemerkt haben: Der Arbeitsmarkt für Datenexperten hat einen strukturellen Wandel erfahren. Ja, SQL und Python sind weiterhin wichtig; Sie stehen in jeder Stellenbeschreibung. Aber sie waren es von Unterscheidungsmerkmalen zu Voraussetzungen herabgestuft.
Wahrscheinlich optimieren Sie immer noch die Interviewfragen, die Sie vor drei Jahren geübt haben. Vergiss es. In diesem Artikel geht es um die Lücke zwischen dem, worauf sich Kandidaten vorbereiten, und dem, was Unternehmen derzeit tatsächlich benötigen.
# Was der Arbeitsmarkt tatsächlich verlangt
Eine Panne im Januar 2026 Eine Studie von Future Proof Knowledge Science aus über 700 Stellenausschreibungen für Datenwissenschaftler ergab, dass Python und SQL immer noch zu den drei besten Fähigkeiten gehören, aber Maschinelles Lernen und KI-Fähigkeiten stehen an zweiter und vierter Stelle.
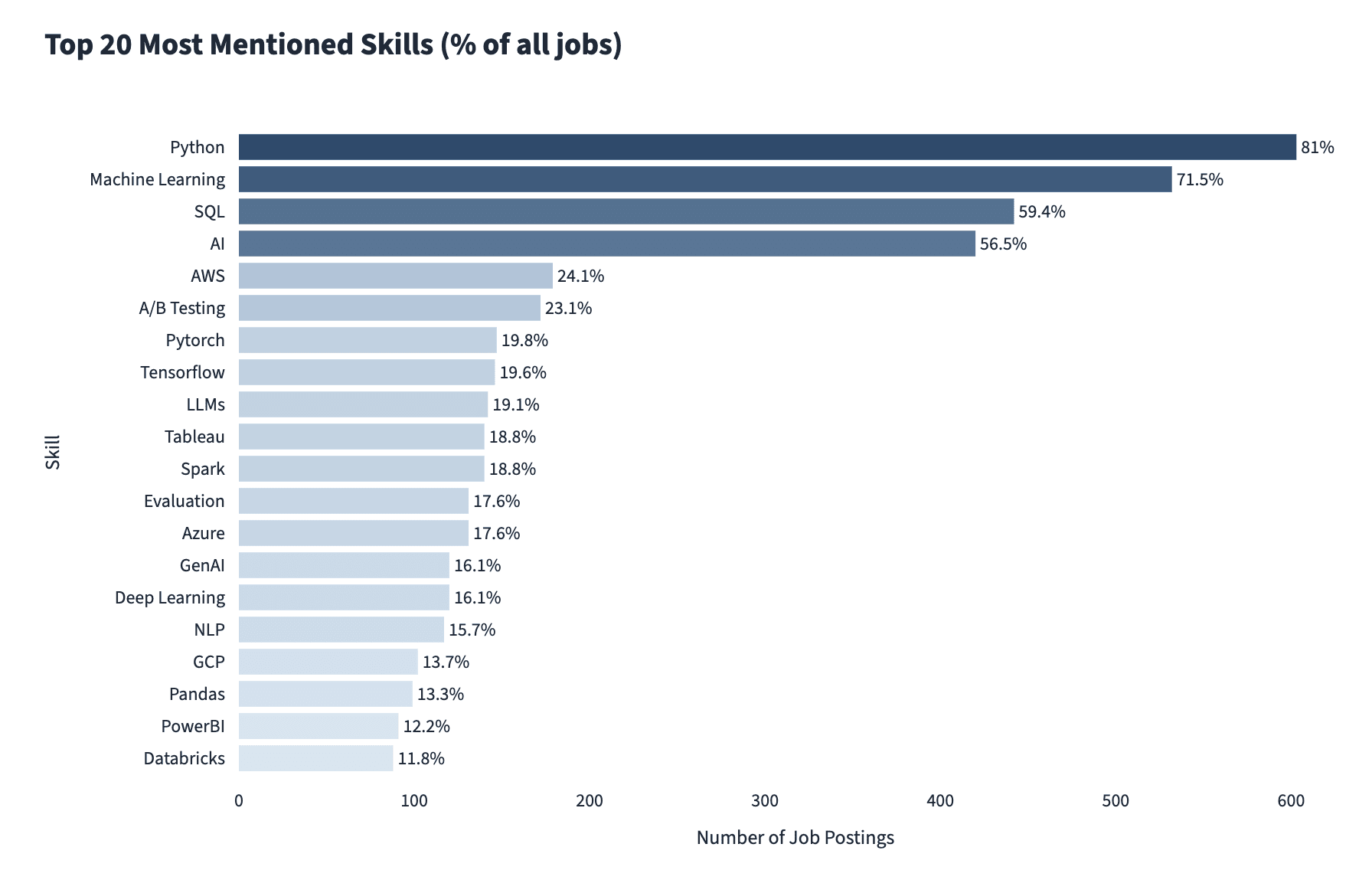
Bildquelle: Zukunftssichere Datenwissenschaft
Nicht alle KI-bezogenen Beiträge erfordern praktische KI-Kenntnisse, aber jeder Dritte tut dies. Der die am meisten benötigten spezifischen KI-Fähigkeiten Sind:
- Große Sprachmodelle (LLMs)
- Retrieval-Augmented Era (RAG)
- Prompte Technik
- Vektordatenbanken
Das spricht für einen steigende Nachfrage nach Datenexperten, die KI-Systeme erstellen und bereitstellen können.
Beachten Sie die Richtung Und Die Geschwindigkeit dieser Veränderung ist von Bedeutung. Das erinnert mich daran, wie sich maschinelles Lernen von einer Nischenanforderung im Jahr 2012 zu einer nahezu universellen Anforderung im Jahr 2020 entwickelte.
Die zweite Geschichte ist weniger sichtbar, aber fraglich für die meisten Kandidaten unmittelbarer: Die Die Messlatte für den Grundbau ist stark gestiegen. Fähigkeiten im Bereich Datentechnik – Pipelines, Orchestrierung, Cloud-Plattformen, Datenqualitätsprüfungen – und maschinelles Lernen in der Produktion – Modellüberwachung, Drifterkennung, Evaluierungsdesign – sind mittlerweile Kernerwartungen statt Boni in Stellenausschreibungen im Bereich Knowledge Science.
Ein Blick auf jede große Jobbörse bestätigt es: Neben KI-Kenntnissen werden regelmäßig Stellen mit der Bezeichnung „Knowledge Scientist“ aufgeführt Schneeflocke, dbt, Luftstromund ETL-Pipeline-Besitz als Anforderungen, nicht als nette Dinge.
Es gibt vier Fähigkeiten, die Ihnen wahrscheinlich fehlen. Dies sind die neuen Unterscheidungsmerkmale auf dem aktuellen Arbeitsmarkt.
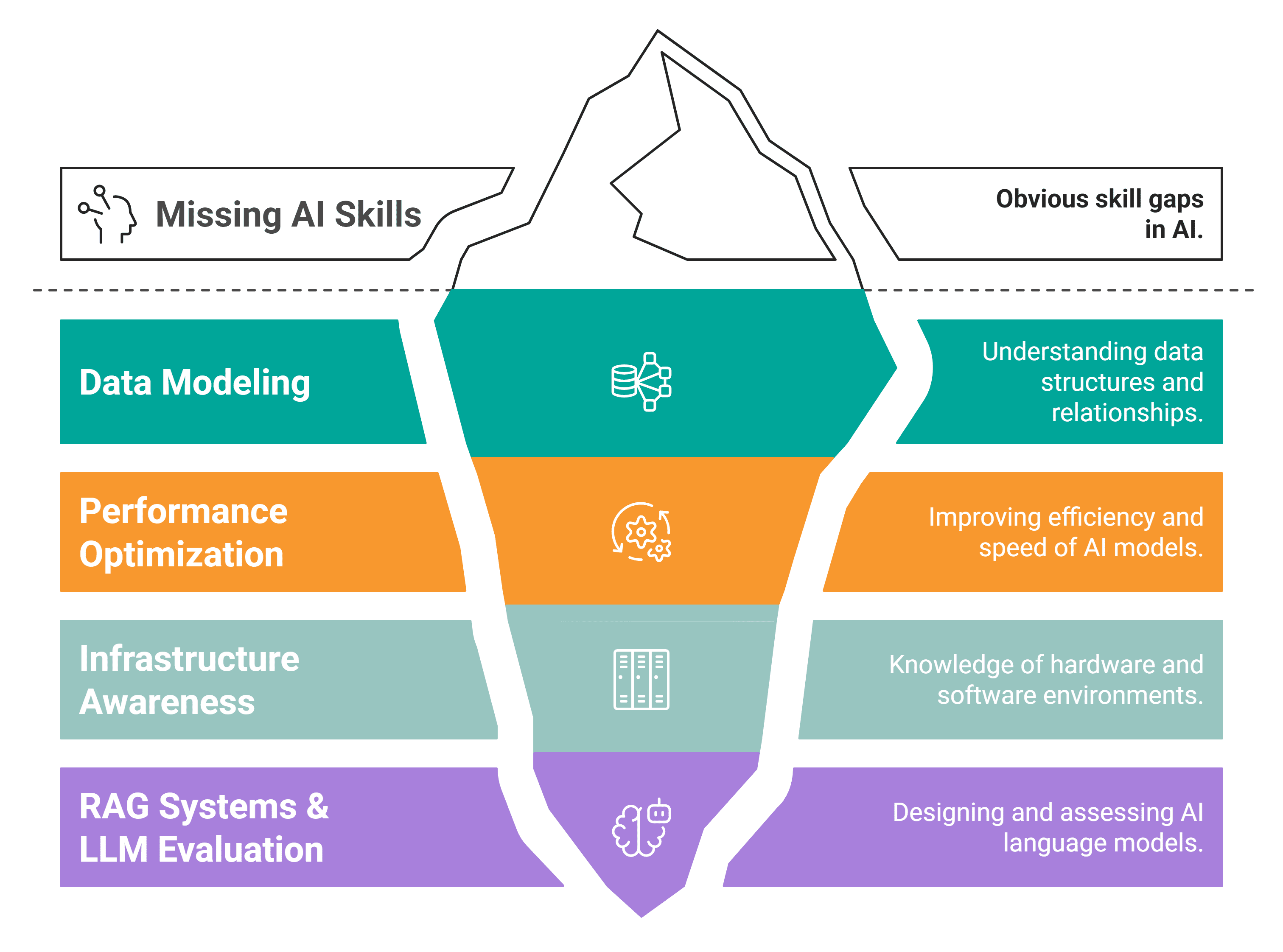
# Fähigkeit Nr. 1: Datenmodellierung
// Was es ist
Datenmodellierung ist die Fähigkeit dazu Entwerfen Sie, wie Daten strukturiert, verknüpft und gespeichert werden sollen. Betrachten Sie es als die Entscheidung, welche Tabellen erstellt werden sollen, was sie darstellen und wie sie zueinander in Beziehung stehen.
// Warum es zu einem Unterscheidungsmerkmal wurde
Werkzeugverbesserungen veränderten die Landschaft. Schneeflocke, dbtUnd BigQuery All das machte es Datenwissenschaftlern relativ einfach Besitzen Sie die Datentransformationsschicht. Mit anderen Worten: Modellierungsentscheidungen, die früher den Dateningenieuren vorbehalten waren, werden jetzt den Datenwissenschaftlern übergeben.
Wenn Sie ein Datenschema falsch verstehen, befinden Sie sich in gefährlichen Gewässern. Typischerweise fallen diese Fehler nicht sofort ins Auge. Sobald sie offensichtlich werden, ist es zu spät. Ihre maschinelle Lernarbeit wurde bereits durch Characteristic-Engineering beeinträchtigt, das auf Daten mit der falschen Granularität basiert – eine direkte Folge einer schlecht modellierten Grundlage.
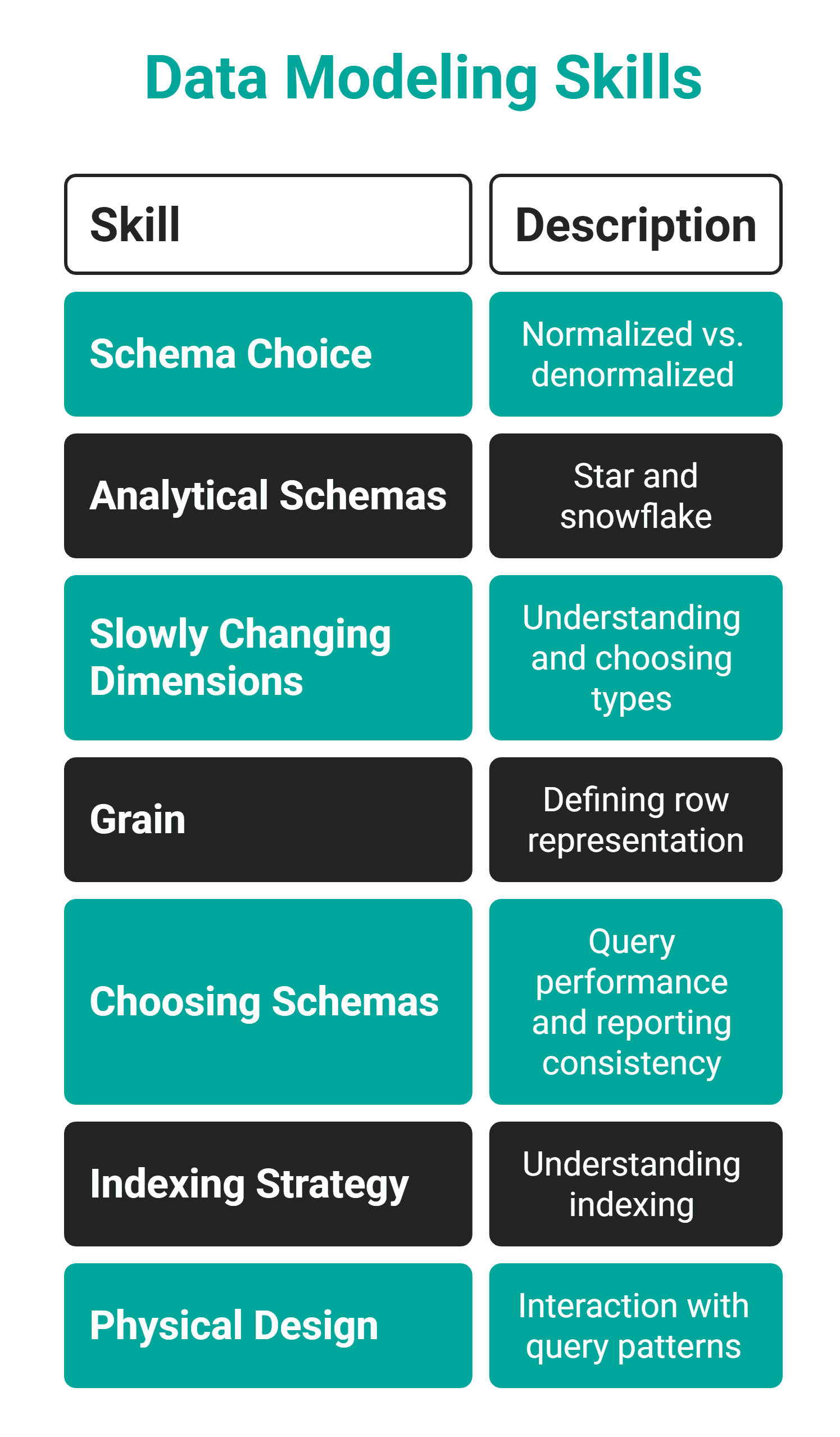
// So erwerben Sie es
Nehmen Sie einen echten Datensatz, mit dem Sie arbeiten, und entwerfen Sie dessen Schema von Grund auf neu. Stellen Sie sich diese Fragen:
- Was sind die Entitäten?
- Worauf beziehen sie sich?
- Welches Getreide ist sinnvoll?
- Welche Abfragen werden am häufigsten ausgeführt?
Lesen Sie anschließend mehr über dimensionale Modellierung. Kimballs Ansatzausführlich in seinem Buch Das Knowledge Warehouse Toolkitbleibt ein nützlicher Bezugspunkt.
# Fähigkeit Nr. 2: Leistungsoptimierung
// Was es ist
Leistungsoptimierung ist Verständnis Warum eine Abfrage so ausgeführt wird, wie sie ausgeführt wird, und wie sie schneller, kostengünstiger oder in größerem Umfang ausgeführt werden kann. Du kannst Optimieren Sie SQL-Abfragenaber auch Python-Pipelines Und Daten-Workflows Im Allgemeinen besitzen Datenwissenschaftler sie zunehmend durchgängig.
// Warum es zu einem Unterscheidungsmerkmal wurde
Erste, Die Datenmengen sind gewachsen Bis zu dem Punkt, an dem eine korrekte, aber ineffiziente Abfrage Hunderte von Greenback kosten und zu Produktionsausfällen führen kann.
Zweitens, wie bereits erwähnt, Datenwissenschaftler müssen jetzt viel mehr von der Pipeline besitzen als sie es zuvor getan haben. Ihr Code muss produktionsbereit sein und darf nicht nur in Jupyter-Notebooks ausgeführt werden.
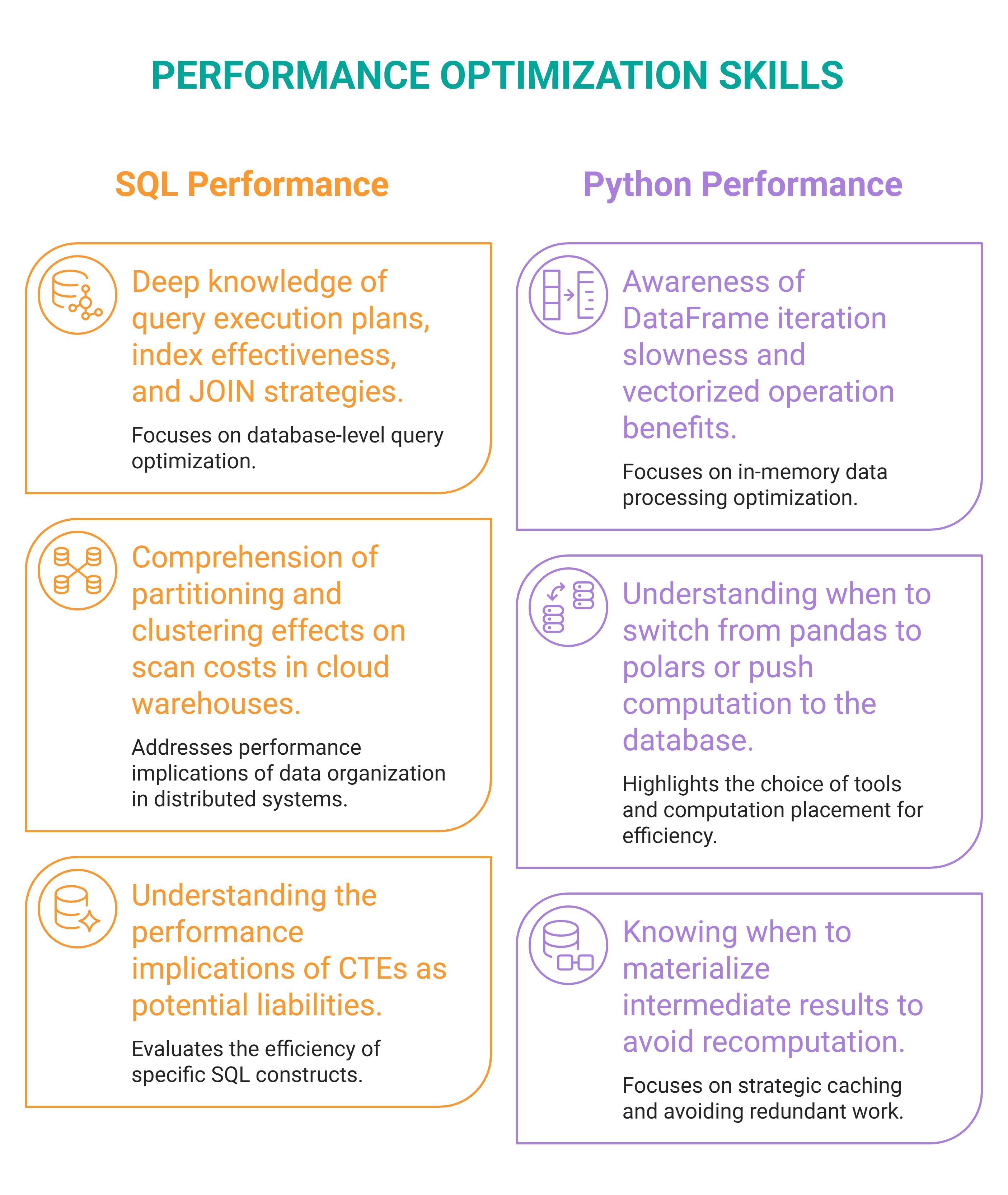
// So erwerben Sie es
Wählen Sie mehrere komplexe SQL-Abfragen aus, die Sie geschrieben haben, und führen Sie sie aus EXPLAIN ANALYZE darauf und lesen Sie, was der Abfrageplaner tatsächlich getan hat. Dann Verwenden Sie dies, um die Abfrage zu optimieren. Sie werden wahrscheinlich mindestens einen Index, eine Umstrukturierung oder eine Umschreibung finden, die jede Abfrage verbessert.
Für einen langsame Python-Pipeline, Profilieren Sie es. Es gibt zwei Hauptwerkzeuge für die Zeit:
- cProfile: Führen Sie es mit aus
python -m cProfile -s cumulative your_script.pyUnd sehen Sie sich oben in der Ausgabe die Funktionen an, die insgesamt die meiste Zeit verbrauchen. - line_profiler: Geht tiefer, indem die Ausführungszeit Zeile für Zeile innerhalb einer bestimmten Funktion angezeigt wird. Verwenden Sie es, sobald cProfile es Ihnen mitgeteilt hat welche Funktion ist langsam und Sie müssen es wissen Warum.
Zur Erinnerungverwenden Memory_profiler.
Finden Sie den Engpass – Ist es langsam, weil eine Python-Schleife vektorisiert werden sollte? Werden die Daten auf einmal und nicht in Blöcken in den Speicher geladen? – Reparieren Sie es und messen Sie den Unterschied.
# Fähigkeit Nr. 3: Infrastrukturbewusstsein
// Was es ist
Mit dieser Fähigkeit sind Sie gemeint Verstehen Sie die Systeme, in denen Daten leben und durch die sie sich bewegen. Zu diesen Systemen gehören Cloud-Plattformen, verteiltes Computing, Datenpipelines, Speicherformate und Kostenmodelle.
Sie sollten genug über die Infrastruktur wissen, um Systeme zu entwerfen, die darin einsetzbar sind.
// Warum es zu einem Unterscheidungsmerkmal wurde
Nochmals, weil ein großer Teil der Arbeit eines Dateningenieurs in den Schoß eines Datenwissenschaftlers gefallen ist. Wenn Sie bei jeder Infrastrukturentscheidung auf Dateningenieure angewiesen sind, schaffen Sie effektiv einen Engpass – und das ist nicht das, wonach Personalmanager suchen.
Das Infrastrukturbewusstsein umfasst diese wichtigsten miteinander verbundenen Bereiche.
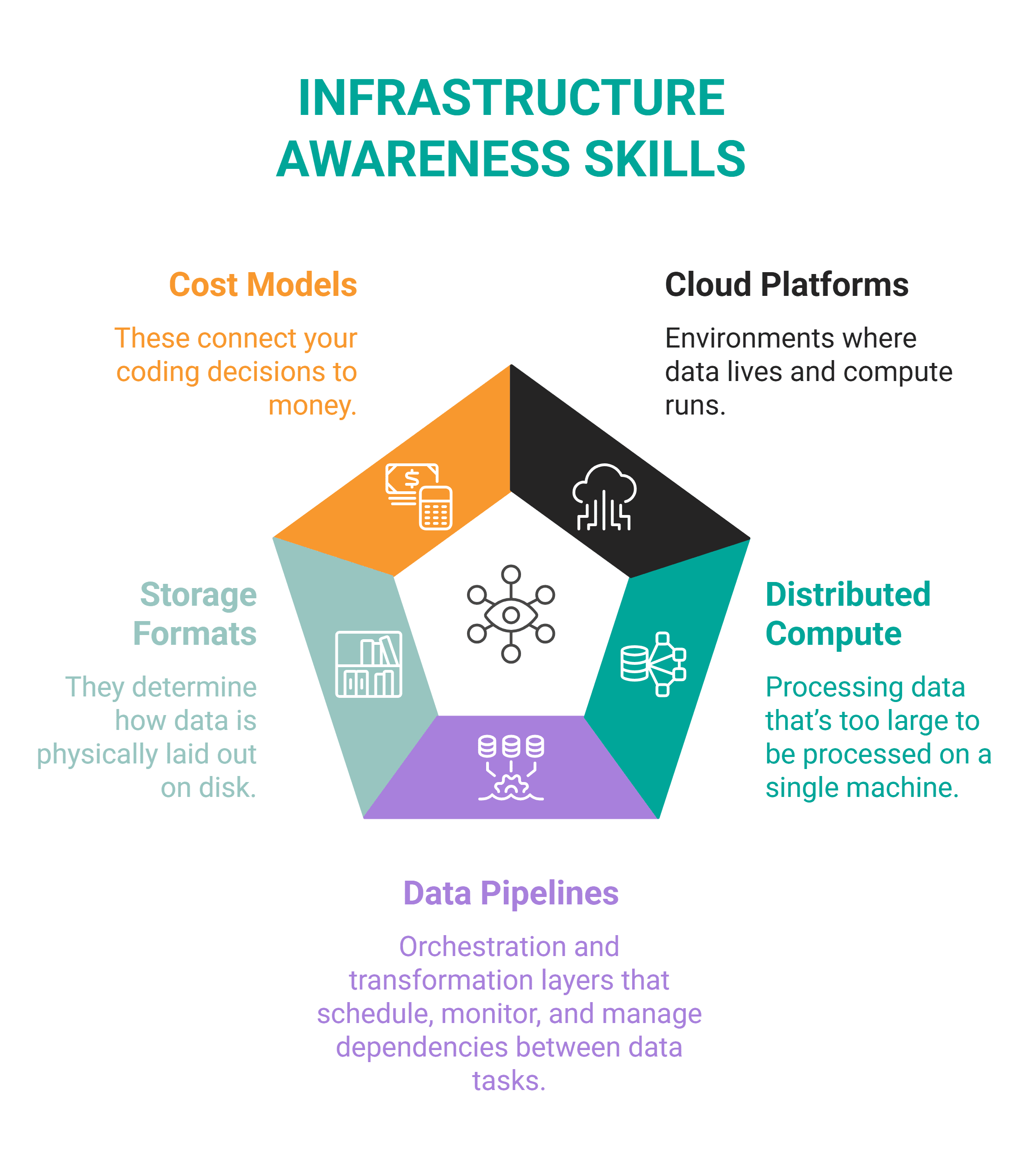
Sie müssen sich höchstwahrscheinlich mit diesen Instruments vertraut machen.
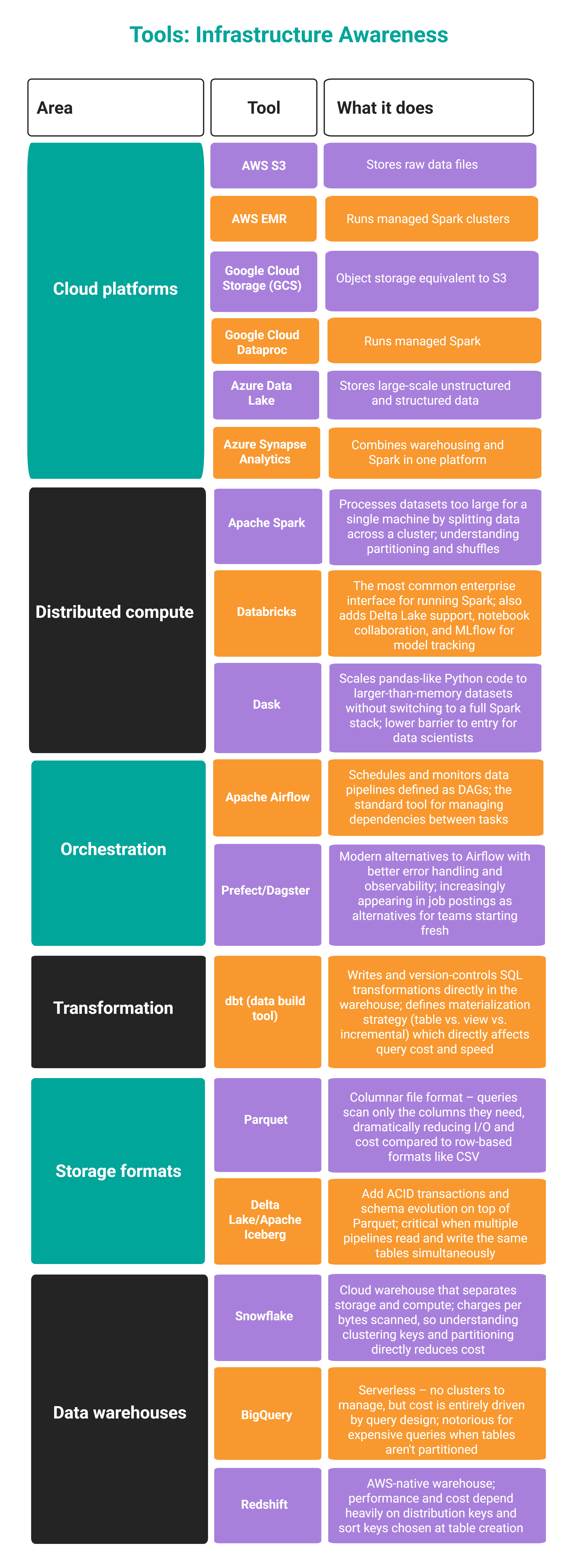
// So erwerben Sie es
Vereinbaren Sie eine Sitzung mit Ihrem Knowledge-Engineering-Workforce. Setzen Sie sich zu ihnen und bitten Sie sie darum Wir führen Sie durchgängig durch eine Pipeline. Verstehen Wo Daten gespeichert sind, wie sie partitioniert sind und was passiert, wenn etwas kaputt geht.
Dann kommen Sie vorbei Bau einer kleinen Pipeline Sie selbst: Nutzen Sie eine kostenlose Cloud-Stufe, verstehen Sie die Kosten- und Ausführungskennzahlen und unterbrechen Sie dann absichtlich die Pipeline, um zu verstehen, warum sie ausfällt.
# Fähigkeit Nr. 4: RAG-Systeme entwerfen, LLM-Ausgaben bewerten und KI-Experimente durchführen
// Was es ist
Dieser Kompetenzcluster bezieht sich auf praktische KI-Arbeit. Sie müssen wissen, wie man Retrieval-Augmented Era (RAG)-Systeme entwirft (die LLMs mit realen Datenquellen verbinden), Bewertungsframeworks erstellt (um zu messen, ob eine LLM-gestützte Funktion tatsächlich funktioniert) und Experimente mit KI-Funktionen durchzuführen.
// Warum es zu einem Unterscheidungsmerkmal wurde
KI-Instruments sind der Grund. Sie ermöglichten den Aufbau einer RAG-Pipeline ohne umfangreiche Forschungskenntnisse. Frameworks wie LangChain Und LamaIndexIn Kombination mit Cloud-nativen Vektordatenbanken wurde die Hürde deutlich gesenkt.
Die Frage ist additionally nicht mehr, ob es gebaut werden kann – ja, es kann sein. Aber kann es intestine gebaut, bewertet und in der Produktion vertrauenswürdig sein? Um diese Frage zu beantworten, müssen Sie in der Lage sein: Metriken definieren, Experimente entwerfen und Ergebnisse messen.
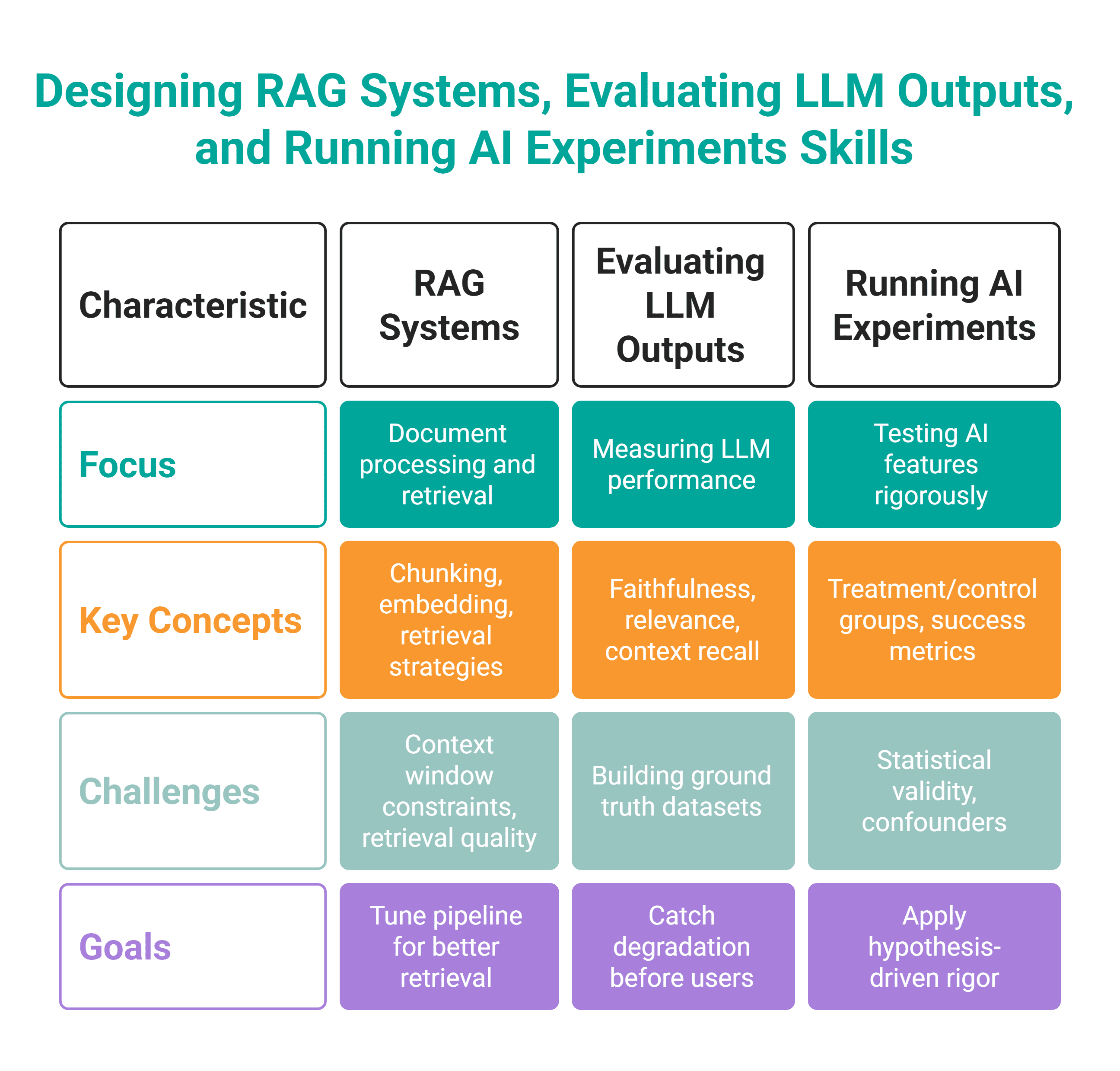
Bei der Anwendung dieser Fähigkeiten werden Sie diese Werkzeuge nutzen.

// So erwerben Sie es
Finden Sie welche Interviewfragen um Ihnen zu helfen, Ihr KI-Denken zu verfeinern. Hier sind einige Beispiele von Fragen zu AI-Produkt- und GenAI-Interviews auf StrataScratch.
Beispiel Nr. 1: Messung der Einführung von KI-Funktionen in Einzelhandelsgeschäften
Wie würden Sie die Auswirkungen der Einführung eines KI-gestützten Bestandsempfehlungssystems in einer Stichprobe von Einzelhandelsgeschäften messen? Wie würden Sie das Experiment gestalten und die Variation auf Filialebene berücksichtigen?
Beispiel #2: RAG-Systemarchitektur
Beschreiben Sie, wie Sie ein RAG-System von Grund auf aufbauen würden. Welche Komponenten werden benötigt und wie lässt sich die Abrufqualität optimieren?
Nachdem Sie Ihre Gedanken klar zum Ausdruck gebracht haben, Erstellen Sie eine kleine RAG-Anwendung: Wählen Sie eine Domäne, betten Sie einen Dokumentenkorpus ein, verknüpfen Sie den Abruf und bewerten Sie die Ergebnisse anhand einer strukturierten Metrik.
Entwerfen Sie außerdem ein Experiment: Schreiben Sie eine Hypothese auf, definieren Sie die Metriken und überlegen Sie sich einen gültigen Take a look at, um sie zu bewerten.
# Abschluss
Die vier Fähigkeiten – Datenmodellierung, Leistungsoptimierung, Infrastrukturbewusstsein und praktische KI-Fähigkeiten – bilden die Lücke zwischen Ihnen und dem Arbeitsmarkt. Hoffentlich fallen Sie nicht hinein. Um sicherzustellen, dass dies nicht der Fall ist, finden Sie in diesem Artikel praktische Ratschläge zum Erwerb der einzelnen Exemplare.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Tendencies auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.