In diesem Artikel lernen Sie die architektonischen Unterschiede zwischen strukturierten Ausgaben und Funktionsaufrufen in modernen Sprachmodellsystemen kennen.
Zu den Themen, die wir behandeln werden, gehören:
- Wie strukturierte Ausgaben und Funktionsaufrufe unter der Haube funktionieren.
- Wann die einzelnen Ansätze in realen maschinellen Lernsystemen verwendet werden sollten.
- Die Kompromisse zwischen Leistung, Kosten und Zuverlässigkeit zwischen beiden.
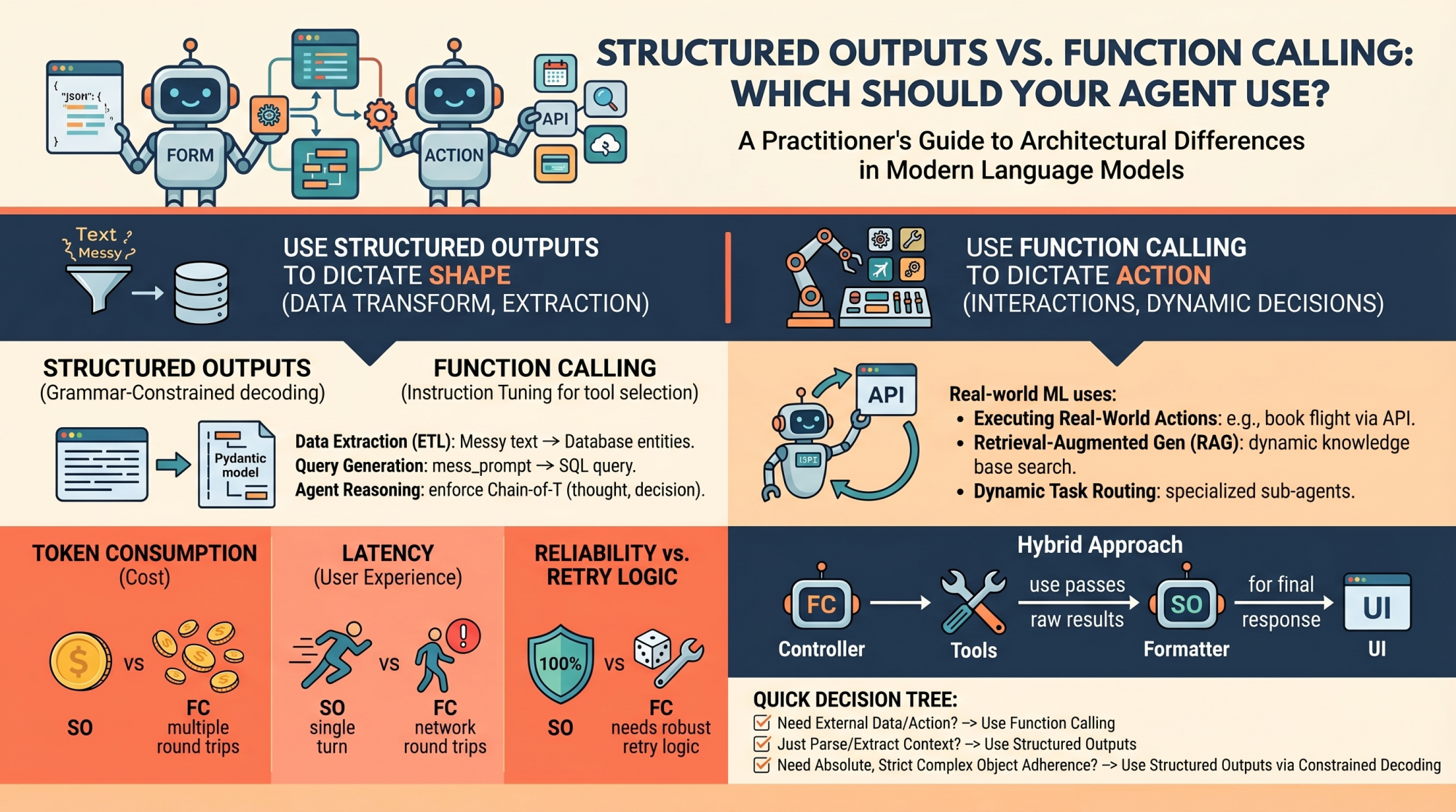
Strukturierte Ausgaben vs. Funktionsaufrufe: Was sollte Ihr Agent verwenden?
Bild vom Herausgeber
Einführung
Sprachmodelle (LMs) sind im Kern Textual content-In- und Textual content-Out-Systeme. Für einen Menschen, der sich über eine Chat-Schnittstelle mit jemandem unterhält, ist das vollkommen in Ordnung. Aber für Praktiker des maschinellen Lernens, die autonome Agenten und zuverlässige Software program-Pipelines erstellen, ist die Analyse, Weiterleitung und Integration von rohem, unstrukturiertem Textual content in deterministische Systeme ein Albtraum.
Um zuverlässige Agenten zu entwickeln, benötigen wir vorhersehbare, maschinenlesbare Ausgaben und die Fähigkeit, nahtlos mit externen Umgebungen zu interagieren. Um diese Lücke zu schließen, haben moderne LM-API-Anbieter (wie OpenAI, Anthropic und Google Gemini) zwei Hauptmechanismen eingeführt:
- Strukturierte Ausgaben: Erzwingen einer Antwort des Modells durch genaue Einhaltung eines vordefinierten Schemas (am häufigsten ein JSON-Schema oder ein Python-Pydantic-Modell)
- Funktionsaufruf (Werkzeugverwendung): Statten Sie das Modell mit einer Bibliothek funktionaler Definitionen aus, die es basierend auf dem Kontext der Eingabeaufforderung dynamisch aufrufen kann
Auf den ersten Blick sehen diese beiden Fähigkeiten sehr ähnlich aus. Beide basieren typischerweise auf der Übergabe von JSON-Schemata an die API unter der Haube, und beide führen dazu, dass das Modell strukturierte Schlüssel-Wert-Paare anstelle von Konversationsprosa ausgibt. Allerdings dienen sie grundsätzlich unterschiedlichen architektonischen Zwecken im Agentendesign.
Beides zu verwechseln, ist eine häufige Gefahr. Die Wahl des falschen Mechanismus für eine Funktion kann zu brüchigen Architekturen, übermäßiger Latenz und unnötig hohen API-Kosten führen. Lassen Sie uns die architektonischen Unterschiede zwischen diesen Methoden aufschlüsseln und einen Entscheidungsrahmen für die Verwendung der einzelnen Methoden bereitstellen.
Die Mechanik auspacken: Wie sie unter der Haube funktioniert
Um zu verstehen, wann diese Funktionen verwendet werden sollten, ist es notwendig zu verstehen, wie sie sich auf mechanischer und API-Ebene unterscheiden.
Mechanik strukturierter Ausgänge
In der Vergangenheit warfare es auf promptes Engineering angewiesen, um ein Modell zur Ausgabe von Roh-JSON zu bringen („Sie sind ein hilfreicher Assistent, der *nur* in JSON spricht…“). Dies warfare fehleranfällig und erforderte umfangreiche Wiederholungslogik und Validierung.
Moderne „strukturierte Ausgaben“ ändern dies grundlegend grammatikbeschränkte Dekodierung. Bibliotheken mögen Umrisseoder native Funktionen wie Strukturierte Ausgaben von OpenAIschränken die Token-Wahrscheinlichkeiten zum Zeitpunkt der Generierung mathematisch ein. Wenn das gewählte Schema vorschreibt, dass das nächste Token ein Anführungszeichen oder ein bestimmter boolescher Wert sein muss, werden die Wahrscheinlichkeiten aller nicht konformen Token ausgeblendet (auf Null gesetzt).
Dabei handelt es sich um eine Single-Flip-Technology, die sich strikt auf die Entwicklung konzentriert bilden. Das Modell antwortet direkt auf die Eingabeaufforderung, sein Vokabular ist jedoch auf die genaue Struktur beschränkt, die Sie definiert haben, mit dem Ziel, eine nahezu 100-prozentige Schemakonformität sicherzustellen.
Funktionsaufrufmechanik
Der Funktionsaufruf hingegen ist stark abhängig von Anleitung zum Tuning. Während des Trainings wird das Modell so abgestimmt, dass es Situationen erkennt, in denen es nicht über die notwendigen Informationen verfügt, um eine Eingabeaufforderung abzuschließen, oder wenn die Eingabeaufforderung es explizit zu einer Aktion auffordert.
Wenn Sie einem Modell eine Liste mit Werkzeugen bereitstellen, sagen Sie ihm: „Bei Bedarf können Sie Ihre Textgenerierung anhalten, ein Werkzeug aus dieser Liste auswählen und die notwendigen Argumente generieren, um es auszuführen.“
Dies ist ein von Natur aus interaktiver Ablauf mit mehreren Runden:
- Das Modell beschließt, ein Software aufzurufen und gibt den Toolnamen und die Argumente aus.
- Das Modell pausiert. Der Code selbst kann nicht ausgeführt werden.
- Ihr Anwendungscode führt die ausgewählte Funktion lokal unter Verwendung der generierten Argumente aus.
- Ihre Anwendung gibt das Ergebnis der Funktion an das Modell zurück.
- Das Modell synthetisiert diese neuen Informationen und generiert weiterhin seine endgültige Antwort.
Wann sollten Sie strukturierte Ausgaben wählen?
Strukturierte Ausgaben sollten Ihr Standardansatz sein, wenn das Ziel eine reine Datentransformation, -extraktion oder -standardisierung ist.
Hauptanwendungsfall: Das Modell verfügt über alle notwendigen Informationen im Eingabeaufforderungs- und Kontextfenster; es muss nur umgestaltet werden.
Beispiele für Praktiker:
- Datenextraktion (ETL): Verarbeiten Sie rohen, unstrukturierten Textual content wie ein Kundensupport-Transkript und extrahieren Sie Entitäten &emdash; Namen, Daten, Beschwerdearten und Stimmungswerte &emdash; in ein striktes Datenbankschema.
- Abfragegenerierung: Konvertieren einer chaotischen Benutzeraufforderung in natürlicher Sprache in eine strenge, validierte SQL-Abfrage oder eine GraphQL-Nutzlast. Wenn das Schema fehlerhaft ist, schlägt die Abfrage fehl, sodass eine 100-prozentige Einhaltung erforderlich ist.
- Begründung des internen Agenten: Die „Gedanken“ eines Agenten strukturieren, bevor er handelt. Sie können a durchsetzen Pydantisch Modell, das eine erfordert
thought_processFeld, einassumptionsFeld und schließlich aresolutionFeld. Dies erzwingt a Gedankenkette Prozess, der von Ihren Backend-Protokollierungssystemen problemlos analysiert werden kann.
Das Urteil: Verwenden Sie strukturierte Ausgaben, wenn die „Aktion“ lediglich in der Formatierung besteht. Da es keine Interaktion der mittleren Technology mit externen Systemen gibt, gewährleistet dieser Ansatz eine hohe Zuverlässigkeit, geringere Latenz und keine Schema-Parsing-Fehler.
Wann sollte man sich für den Funktionsaufruf entscheiden?
Funktionsaufrufe sind der Motor der Agentenautonomie. Wenn strukturierte Ausgaben dies vorschreiben Type der Daten bestimmt der Funktionsaufruf Kontrollfluss der Bewerbung.
Hauptanwendungsfall: Externe Interaktionen, dynamische Entscheidungsfindung und Fälle, in denen das Modell Informationen abrufen muss, über die es derzeit nicht verfügt.
Beispiele für Praktiker:
- Ausführen realer Aktionen: Auslösen externer APIs basierend auf der Konversationsabsicht. Wenn ein Benutzer sagt: „Buche meinen üblichen Flug nach New York“, löst das Modell mithilfe von Funktionsaufrufen die Aktion aus
book_flight(vacation spot="JFK")Werkzeug. - Retrieval-Augmented Technology (RAG): Anstelle einer naiven RAG-Pipeline, die immer eine Vektordatenbank durchsucht, kann ein Agent eine verwenden
search_knowledge_baseWerkzeug. Das Modell entscheidet dynamisch Was Die zu verwendenden Suchbegriffe werden je nach Kontext ausgewählt oder es wird entschieden, überhaupt nicht zu suchen, wenn die Antwort bereits bekannt ist. - Dynamische Aufgabenweiterleitung: Bei komplexen Systemen könnte ein Router-Modell Funktionsaufrufe verwenden, um den am besten spezialisierten Subagenten auszuwählen (z. B. Calling).
delegate_to_billing_agentgegendelegate_to_tech_support), um eine bestimmte Abfrage zu bearbeiten.
Das Urteil: Wählen Sie den Funktionsaufruf, wenn das Modell mit der Außenwelt interagieren, versteckte Daten abrufen oder Softwarelogik mitten im Gedanken bedingt ausführen muss.
Auswirkungen auf Leistung, Latenz und Kosten
Bei der Bereitstellung von Agenten in der Produktion wirkt sich die architektonische Wahl zwischen diesen beiden Methoden direkt auf die Wirtschaftlichkeit Ihrer Einheit und das Benutzererlebnis aus.
- Token-Verbrauch: Funktionsaufrufe erfordern oft mehrere Roundtrips. Sie senden die Systemaufforderung, das Modell sendet Werkzeugargumente, Sie senden die Werkzeugergebnisse zurück und das Modell sendet schließlich die Antwort. Jeder Schritt wird an das Kontextfenster angehängt und sammelt die Verwendung von Eingabe- und Ausgabe-Tokens. Strukturierte Ausgaben werden normalerweise in einer einzigen, kostengünstigeren Runde gelöst.
- Latenzaufwand: Die mit Funktionsaufrufen verbundenen Roundtrips führen zu einer erheblichen Netzwerk- und Verarbeitungslatenz. Ihre Anwendung muss auf das Modell warten, lokalen Code ausführen und erneut auf das Modell warten. Wenn Ihr primäres Ziel lediglich darin besteht, Daten in ein bestimmtes Format zu bringen, sind strukturierte Ausgaben wesentlich schneller.
- Zuverlässigkeit vs. Wiederholungslogik: Streng strukturierte Ausgaben (über eingeschränkte Dekodierung) bieten nahezu 100 % Schematreue. Sie können der Ausgabeform ohne komplexe Parsing-Blöcke vertrauen. Der Funktionsaufruf ist jedoch statistisch unvorhersehbar. Das Modell könnte ein Argument halluzinieren, das falsche Werkzeug auswählen oder in einer Diagnoseschleife stecken bleiben. Funktionsaufrufe in Produktionsqualität erfordern eine robuste Wiederholungslogik, Fallback-Mechanismen und eine sorgfältige Fehlerbehandlung.
Hybride Ansätze und Finest Practices
In fortschrittlichen Agentenarchitekturen verschwimmt die Grenze zwischen diesen beiden Mechanismen häufig, was zu hybriden Ansätzen führt.
Die Überschneidung:
Es ist erwähnenswert, dass es tatsächlich moderne Funktionsaufrufe gibt verlässt sich auf strukturierten Ausgaben unter der Haube, um sicherzustellen, dass die generierten Argumente mit Ihren Funktionssignaturen übereinstimmen. Umgekehrt können Sie einen Agenten entwerfen, der nur strukturierte Ausgaben verwendet, um ein JSON-Objekt zurückzugeben, das eine Aktion beschreibt, die Ihr deterministisches System ausführen soll nach die Generierung ist abgeschlossen &emdash; Effektive Täuschung der Werkzeugnutzung ohne Multi-Flip-Latenz.
Architekturberatung:
- Das „Controller“-Muster: Verwenden Sie Funktionsaufrufe für den Orchestrator oder „Gehirn“-Agenten. Lassen Sie es frei Instruments aufrufen, um Kontext zu sammeln, Datenbanken abzufragen und APIs auszuführen, bis es überzeugt ist, dass es den erforderlichen Standing erreicht hat.
- Das „Formatter“-Muster: Sobald die Aktion abgeschlossen ist, leiten Sie die Rohergebnisse an ein endgültiges, kostengünstigeres Modell weiter, das nur strukturierte Ergebnisse verwendet. Dies garantiert, dass die endgültige Antwort perfekt Ihren UI-Komponenten oder nachgelagerten REST-API-Erwartungen entspricht.
Zusammenfassung
LM Engineering vollzieht einen raschen Übergang von der Entwicklung von Konversations-Chatbots hin zur Entwicklung zuverlässiger, programmatischer und autonomer Agenten. Der Schlüssel zu diesem Übergang liegt darin, zu verstehen, wie Sie Ihre Modelle einschränken und lenken.
TL;DR
- Verwenden strukturierte Ausgaben diktieren Type der Daten
- Verwenden Funktionsaufruf diktieren Aktionen und Interaktionen
Der Entscheidungsbaum des Praktikers
Gehen Sie beim Erstellen einer neuen Funktion diese kurze dreistufige Checkliste durch:
- Benötige ich während des Denkens externe Daten oder muss ich eine Aktion ausführen? ⭢ Verwenden Sie Funktionsaufrufe
- Analysiere, extrahiere oder übersetze ich nur unstrukturierten Kontext in strukturierte Daten? ⭢ Verwenden Sie strukturierte Ausgaben
- Benötige ich eine absolute, strikte Einhaltung eines komplex verschachtelten Objekts? ⭢ Verwenden Sie strukturierte Ausgaben über eingeschränkte Dekodierung
Letzter Gedanke
Die effektivsten KI-Ingenieure betrachten Funktionsaufrufe als eine leistungsstarke, aber unvorhersehbare Fähigkeit, die sparsam eingesetzt und von einer robusten Fehlerbehandlung begleitet werden sollte. Umgekehrt sollten strukturierte Ergebnisse als zuverlässiger, grundlegender Klebstoff betrachtet werden, der moderne KI-Datenpipelines zusammenhält.