
Standardisierte Assessments können Ihnen Aufschluss darüber geben, ob ein Schüler sich mit Evaluation auskennt oder eine Textpassage analysieren kann. Was sie Ihnen nicht zuverlässig sagen können, ist, ob dieser Schüler eine Meinungsverschiedenheit mit einem Teamkollegen lösen, unter Druck wirklich originelle Ideen entwickeln oder ein fehlerhaftes Argument kritisch entkräften kann. Dies sind die sogenannten dauerhaften Fähigkeiten – Zusammenarbeit, Kreativität und kritisches Denken – und sie haben sich jahrzehntelang einer strengen, skalierbaren Messung widersetzt. Eine neue Studie von Google Analysis schlägt eine technisch neuartige Lösung namens Vantage vor: orchestrierte große Sprachmodelle, die sowohl authentische Gruppeninteraktionen simulieren als auch die Ergebnisse mit einer Genauigkeit bewerten können, die mit menschlichen Experten-Bewertern mithalten kann.

Das Kernproblem: Ökologische Validität vs. psychometrische Strenge
Um zu verstehen, warum dies technisch interessant ist, ist es hilfreich, das Messparadoxon zu verstehen, das das Forschungsteam zu knacken versuchte. Die effektive Messung dauerhafter Fähigkeiten erfordert zwei widersprüchliche Eigenschaften. Einerseits muss die Bewertung ökologisch valide sein – sie sollte sich wie ein reales Szenario anfühlen, denn genau in diesem Kontext werden diese Fähigkeiten ausgeübt. Andererseits ist psychometrische Genauigkeit erforderlich: standardisierte Bedingungen, Reproduzierbarkeit und kontrollierbare Reize, damit die Ergebnisse aller Testteilnehmer vergleichbar sind.
Frühere groß angelegte Versuche, wie der PISA 2015 Collaborative Drawback Fixing-Take a look at, versuchten, dieses Drawback zu lösen, indem die Probanden über A number of-Selection-Fragen mit simulierten Teamkollegen interagieren mussten. Das garantiert Kontrolle, geht aber auf Kosten der Authentizität. Beurteilungen von Mensch zu Mensch bewirken das Gegenteil. LLMs, so argumentiert das Forschungsteam, sind in der einzigartigen Lage, beide Anforderungen gleichzeitig zu erfüllen – sie können naturalistische, ergebnisoffene Gesprächsinteraktionen erzeugen und werden dennoch programmatisch auf bestimmte Bewertungsziele ausgerichtet.
Das Government LLM: Eine Koordinationsebene über KI-Agenten
Der technisch herausragendste Beitrag dieser Forschung ist die Government LLM-Architektur. Anstatt mehrere unabhängige LLM-Agenten zu erzeugen – einen professional KI-Teamkollegen – verwendet das System einen einzigen LLM, um Antworten für alle KI-Teilnehmer an der Konversation zu generieren. Dies ist aus zwei Gründen wichtig.
Erstens ermöglicht es die Koordination. Der Government LLM hat Zugriff auf dieselbe pädagogische Rubrik, die später zur Bewertung des menschlichen Teilnehmers verwendet wird. Diese Rubrik wird nicht nur passiv, sondern aktiv genutzt, um das Gespräch auf Szenarien zu lenken, die Hinweise auf bestimmte Fähigkeiten liefern. Wenn die Zieldimension beispielsweise Konfliktlösung ist, kann das Government LLM eine seiner KI-Personas anweisen, eine Meinungsverschiedenheit hervorzurufen und diese aufrechtzuerhalten, bis der menschliche Teilnehmer eine Konfliktlösungsstrategie demonstriert (oder nicht demonstriert). Dies ist funktionell vergleichbar mit der Artwork und Weise, wie ein computergestützter adaptiver Take a look at (CAT) den Schwierigkeitsgrad eines Gegenstands basierend auf der Laufleistung eines Testteilnehmers dynamisch anpasst – mit der Ausnahme, dass es sich hier bei den „Aufgaben“ um Wendungen in einem Dwell-Gespräch handelt.
Zweitens erwies sich die Basislinie der unabhängigen Agenten (separate LLMs ohne Koordination) als nachweislich schwächer. Ohne Steuerung liefern Gespräche möglicherweise einfach nicht die richtigen Beweise – wenn sich die Teammitglieder natürlich einig sind, gibt es keinen Konflikt zu lösen, und die Bewertung erfährt nichts über diese Teilkompetenz.
Gemini 2.5 Professional wurde als Modell verwendet, das dem Government LLM für die wichtigsten Kollaborationsexperimente zugrunde liegt, während Gemini 3 die Module für Kreativität und kritisches Denken unterstützte.
Was die Experimente tatsächlich zeigen
Das Forschungsteam rekrutierte über die Prolific-Plattform 188 Teilnehmer im Alter von 18 bis 25 Jahren, englische Muttersprachler mit Sitz in den Vereinigten Staaten. Jeder Teilnehmer generierte zwei Gespräche mit insgesamt 373 Transkripten (drei wurden aufgrund technischer Probleme gefiltert). Alle Teilnehmer arbeiteten 30 Minuten professional Gespräch mit einer Gruppe von KI-Personas an gemeinsamen Aufgaben – entweder einem Entwurf eines wissenschaftlichen Experiments oder einer strukturierten Debatte.
Zwei Teilkompetenzen der Zusammenarbeit wurden bewertet: Konfliktlösung (CR) und Projektmanagement (PM). Die Gespräche wurden sowohl von zwei humanpädagogischen Bewertern der New York College als auch von einem KI-Bewerter (Gemini 3.0) bewertet, der jeden Teilnehmerzug 20 Mal bewertete. Eine Runde wurde als NA erklärt, wenn eine der 20 Vorhersagen NA ergab; Ansonsten conflict die endgültige Bezeichnung die häufigste Nicht-NA-Stufe unter den 20 Läufen. Anschließend wurde ein Regressionsmodell – linear für Scores, logistisch für NA-Entscheidungen – auf diese Flip-Stage-Labels trainiert, um einen Konversations-Stage-Rating zu erstellen, wobei die Leistung mithilfe einer ausgelassenen Kreuzvalidierung bewertet wurde.
Die Hauptergebnisse sind in mehrfacher Hinsicht überzeugend. Die Evidenzraten für fähigkeitsrelevantes Verhalten auf Flip- und Konversationsebene waren in den Government LLM-Bedingungen in beiden Teilkompetenzen signifikant höher als in der Unbiased Brokers-Bedingung. Die Informationsraten auf Konversationsebene erreichten 92,4 % für Projektmanagement und 85 % für Konfliktlösung, wenn das auf die Fähigkeiten abgestimmte Government LLM verwendet wurde. Bemerkenswert ist, dass die einfache Aufforderung an die Teilnehmer, sich auf eine Fertigkeit zu konzentrieren, keinen signifikanten Einfluss auf die Evidenzraten hatte (alle p > 0,6), was bestätigt, dass die Steuerung von der KI-Seite kommen muss.
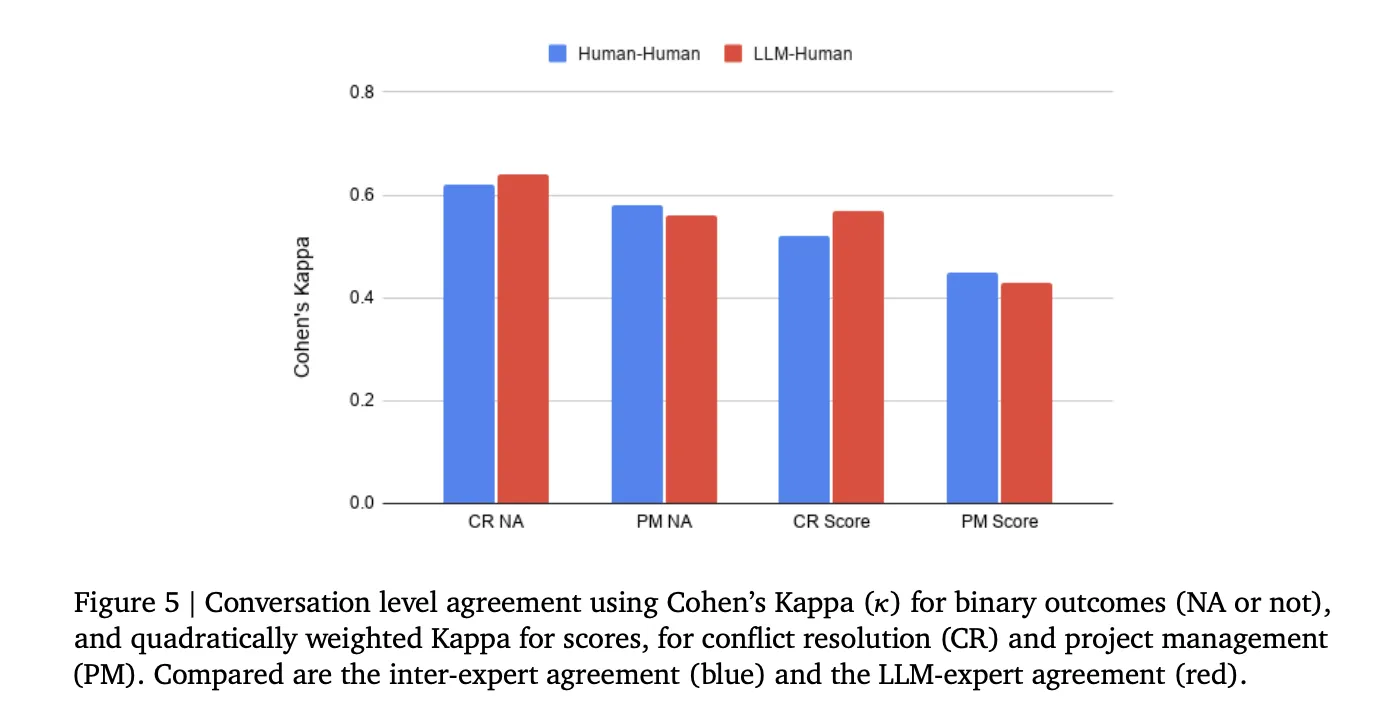
In Bezug auf die Bewertungsgenauigkeit conflict die Übereinstimmung zwischen den Bewertern zwischen dem KI-Bewerter und menschlichen Experten – gemessen mit Cohens Kappa – vergleichbar mit der zwischenmenschlichen Übereinstimmung, die bei beiden Fähigkeiten und beiden Bewertungsaufgaben zwischen moderat (κ = 0,45–0,64) lag.
Simulation als Entwicklungs-Sandbox
Eine praktisch nützliche Erkenntnis für ML-Ingenieure, die ähnliche Systeme entwickeln, ist die Validierung der LLM-basierten Simulation als Ersatz für menschliche Probanden während der Protokollentwicklung. Das Forschungsteam verwendete Gemini, um menschliche Teilnehmer mit bekannten Fähigkeitsniveaus (1–4 in jeder Rubrikendimension) zu simulieren, und maß dann den Wiederherstellungsfehler – die mittlere absolute Differenz zwischen dem Floor-Reality-Niveau und dem abgeleiteten Niveau des Autors. Der Government LLM erzeugte sowohl für CR als auch für PM einen deutlich geringeren Wiederherstellungsfehler als unabhängige Agenten. Qualitative Muster in den simulierten Daten stimmten weitgehend mit denen aus realen menschlichen Gesprächen überein, was darauf hindeutet, dass eine auf Rubriken basierende Simulation das Risiko des Bewertungsdesigns vor der kostspieligen Erfassung menschlicher Daten verringern kann.
Die Evidenzraten erstrecken sich auf Kreativität und kritisches Denken
Für Kreativität und kritisches Denken wurden die ersten Evidenzraten anhand simulierter Probanden bewertet. Die Ergebnisse zeigen, dass der Government LLM unabhängige Agenten in allen acht getesteten Dimensionen übertrifft – allen sechs Kreativitätsdimensionen (Flüssigkeit, Originalität, Qualität, Aufbau auf Ideen, Ausarbeiten und Auswählen) und beiden Dimensionen des kritischen Denkens (Interpretieren und Analysieren; Bewerten und Beurteilen) – wobei alle Unterschiede statistisch signifikant sind. Das Forschungsteam stellte fest, dass die Erfassung menschlicher Bewertungen für diese beiden Fähigkeiten noch nicht abgeschlossen ist und die Ergebnisse in zukünftigen Arbeiten geteilt werden. Die Simulationsergebnisse legen jedoch nahe, dass der Government LLM-Ansatz über die Zusammenarbeit hinaus verallgemeinert wird.
Kreativitätsbewertung bei 0,88 Pearson-Korrelation
In einer separaten Partnerschaft mit OpenMic, einer Establishment, die KI-gestützte Instruments zur dauerhaften Kompetenzbewertung entwickelt, evaluierte das Forschungsteam seinen auf Gemini basierenden Kreativitäts-Autorater anhand komplexer Multimedia-Aufgaben, die von 280 Oberstufenschülern gelöst wurden. Zu den Aufgaben gehörte die Gestaltung eines Nachrichtensegments auf der Grundlage einer Kurzgeschichte, einschließlich der Erstellung von Fragen für Charakterinterviews. Entscheidend ist, dass zunächst 100 Einsendungen verwendet wurden, um die Gemini-Eingabeaufforderung und die pädagogischen Expertenrubriken zu verfeinern, während die verbleibenden 180 zurückgehaltenen Einsendungen für die abschließende Genauigkeitsbewertung verwendet wurden. Die auf Rubriken basierende Bewertung durch OpenMic-Experten und der Autorater stimmten auf Cohens Kappa = 0,66 (gute Übereinstimmung) auf Itemebene überein. Noch auffälliger ist, dass beim Vergleich der Gesamtpunktzahlen der Einreichungen die Pearson-Korrelation zwischen den Gesamtwerten der Autoren und menschlichen Experten 0,88 betrug – ein Maß an Übereinstimmung, das selbst zwischen menschlichen Bewertern bei subjektiven kreativen Aufgaben schwer zu erreichen ist.
Schließen der Rückkopplungsschleife
Über die Bewertung hinaus stellt Vantage den Benutzern Ergebnisse anhand einer quantitativen Fähigkeitskarte zur Verfügung, die die Kompetenzniveaus aller Fähigkeiten und Unterfähigkeiten zeigt, mit der Choice, einen Drilldown zu bestimmten Auszügen aus dem Gespräch durchzuführen, die jede numerische Bewertung untermauern. Dies macht die Beweise für die Bewertung clear und umsetzbar – eine sinnvolle Entwurfsüberlegung für jeden, der ähnliche Bewertungspipelines erstellt, bei denen es auf die Interpretierbarkeit automatisierter Bewertungen ankommt.
Wichtige Erkenntnisse
- Ein einzelner „Government LLM“ übertrifft mehrere unabhängige Agenten bei der Kompetenzbewertung: Anstatt ein LLM professional KI-Teammitglied auszuführen, verwendet Googles Vantage ein einziges koordinierendes LLM, das Antworten für alle KI-Teilnehmer generiert. Dies ermöglicht es, Gespräche mithilfe einer pädagogischen Rubrik aktiv zu steuern – indem es Konflikte herbeiführt, Ideen zurückdrängt oder Planungsengpässe schafft –, um beobachtbare Beweise für bestimmte Fähigkeiten zu liefern, die auf natürliche Weise möglicherweise nie zum Vorschein kommen.
- Die LLM-basierte Bewertung ist mittlerweile mit der Bewertung durch menschliche Experten vergleichbar: Die Übereinstimmung des AI Evaluators mit menschlichen Bewertern conflict vergleichbar mit der Übereinstimmung zwischen zwei menschlichen Experten selbst, die selbst nach mehreren Kalibrierungsrunden nur einen moderaten Cohen-Kappa (0,45–0,64) erreichten. Dies macht die automatisierte LLM-Bewertung zu einer wirklich skalierbaren Various zur teuren menschlichen Annotation für komplexe, offene Konversationsaufgaben.
- Den Benutzern zu sagen, sie sollen sich auf eine Fertigkeit konzentrieren, bringt nichts – die Steuerung muss von der KI-Seite kommen: Teilnehmer, die ausdrücklich angewiesen wurden, auf Konfliktlösung oder Projektmanagement zu achten, zeigten keine statistisch signifikante Verbesserung der Evidenzraten (alle p > 0,6) im Vergleich zu Teilnehmern, denen keine Anweisungen gegeben wurden. Nur die aktive Steuerung des Government LLM lieferte messbar umfangreichere Bewertungsdaten.
- Die LLM-Simulation kann als kostengünstige Sandbox vor der Durchführung von Studien mit echten Menschen dienen: Durch die Simulation von Teilnehmern mit bekannten Fähigkeitsniveaus und die Messung, wie genau das System diese Niveaus wiederherstellte, validierte das Forschungsteam sein Bewertungsprotokoll, ohne teure Budgets für menschliche Probanden zu verschwenden. Simulierte und reale Gesprächsmuster waren qualitativ ähnlich, was dies zu einem praktischen Ansatz für die Iteration von Rubriken und Eingabeaufforderungen zu Beginn der Entwicklung macht.
- Die KI-Kreativitätsbewertung erreichte eine Pearson-Korrelation von 0,88 mit menschlichen Experten bei realer studentischer Arbeit: In einem realen Take a look at mit 180 zurückgehaltenen Einreichungen von Oberstufenschülern verglich ein auf Gemini basierender Autor die Bewertungen menschlicher Experten mit einer Pearson-Korrelation von 0,88 bei der Gesamtbeurteilung der Kreativität – was zeigt, dass die automatisierte Bewertung komplexer, subjektiver Multimedia-Aufgaben nicht nur theoretisch möglich, sondern auch empirisch validiert ist.
Schauen Sie sich das an Papier Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 130.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Möchten Sie mit uns zusammenarbeiten, um Ihr GitHub-Repo ODER Ihre Hugging Face Web page ODER Produktveröffentlichung ODER Ihr Webinar usw. zu bewerben? Vernetzen Sie sich mit uns

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.