Haben Sie sich jemals gefragt, wie Sie Ihre Bins in einem Histogramm auswählen? Haben Sie sich jemals gefragt, ob es tiefere Gründe für Entscheidungen gibt, die über das bloße Aussehen hinausgehen? Während Histogramme das grundlegendste Werkzeug zur Datenvisualisierung sind, ist die Einstellung ihrer Auflösung wichtig, insbesondere wenn das Histogramm selbst für weitere Analysen verwendet wird. Histogramme werden häufig berechnet, um die Dichte der Daten zu visualisieren. In diesem Beitrag befassen wir uns mit der Mathematik der Dichteanpassung und untersuchen insbesondere, wie die Klassen kleiner werden sollten, wenn unser Datensatz wächst. Inspiriert durch angrenzende Gebiete wie die Störungstheorie in der Physik und Taylor-Entwicklungen in der Mathematik werden wir eine strenge Methode zur Konstruktion von Dichten finden.
Alle Bilder stammen vom Autor
Hintergrund
Annäherungen
Die Instinct ist einfach: Je mehr Daten Sie haben, desto mehr Particulars sollten Sie sehen können. Wenn Sie eine Stichprobe von zehn Beobachtungen betrachten, können Sie sich wahrscheinlich nur zwei oder drei breite Abschnitte leisten, bevor Ihre Visualisierung zu einer spärlichen Ansammlung leerer Lücken wird. Aber wenn Sie zehn Millionen Beobachtungen haben, fühlen sich diese breiten Bereiche wie ein pixeliges Foto mit niedriger Auflösung an. Sie möchten „vergrößern“, indem Sie die Anzahl der Behälter erhöhen. Die Frage ist jedoch: Wie genau sollen wir diese Auflösung skalieren?
Wenn wir in der Physik mit einem System konfrontiert sind, das zu komplex ist, um es genau zu lösen, wenden wir uns oft an Störungstheorie. In der Quantenelektrodynamik (QED) nähern wir uns beispielsweise komplexen Wechselwirkungen an, indem wir sie im Hinblick auf eine kleine Kopplungskonstante wie die Elektronenladung erweitern e. Diese „Interaktionsstärke“ bietet eine natürliche Hierarchie für unsere Näherungen. Aber was ist für ein Histogramm die analoge „Ladung“? Gibt es einen grundlegenden Parameter, der die Interaktion zwischen unseren diskreten Datenpunkten und der zugrunde liegenden Verteilung, die wir schätzen möchten, regelt?
Die Mathematik bietet einen anderen Weg: den Taylor-Erweiterung. Wenn wir davon ausgehen, dass die zugrunde liegende Dichtefunktion ausreichend glatt (analytisch) ist, können wir sie lokal mithilfe ihrer Ableitungen beschreiben. Dies scheint ein vielversprechender Hinweis zu sein, da nachgewiesen werden kann, dass die höheren Ordnungen verschwinden. Obwohl wir möglicherweise eine Beschränkung auf analytische Verteilungen akzeptieren möchten, ist nicht klar, wie dies zu einer bestimmten Klassengröße führt.
Alternativ könnten wir das Downside als eine Erweiterung in Basisfunktionen behandeln. So wie wir eine stückweise stetige Funktion mithilfe einer Fourier-Transformation oder Legendre-Polynomen darstellen können, könnten wir Histogramm-Bins als eine Menge von Basisfunktionen betrachten. Mit einem solchen Ansatz könnten wir die Funktion anhand von L2 approximieren. Dieser Ansatz bringt jedoch seine eigenen Hürden mit sich. Wie berechnen wir die Koeffizienten für diese Funktionen effizient? Und was noch wichtiger ist: Wie erfüllen wir die physikalischen Einschränkungen einer Wahrscheinlichkeitsdichtefunktion? Im Gegensatz zu einer allgemeinen Fourier-Reihe muss eine Dichtefunktion streng positiv-definit und auf eins normiert sein. Wir werden im Folgenden sehen, dass die aus der Informationstheorie abgeleitete Methode ähnliche Aspekte wie die Erweiterung in Basisfunktionen aufweist.
Informationstheorie
Priors und Posteriors
Für eine Einführung in die Bayes’sche Statistik oder Informationstheorie wird der Leser auf (Murphy, 2022) verwiesen. In einem Bayes’schen Ansatz ein Modell Wo X sind die Observablen, die wir modellieren wollen und sind unsere Parameter, enthält auch eine vorherige Verteilung 𝑃(𝜃|ℳ), die unsere Überzeugung über die Verteilung vor der Datenbeobachtung widerspiegelt. Nachdem die Daten beobachtet wurden, können wir die hintere Verteilung abschätzen
𝑃(𝜃|𝑋) = 𝑃(𝑋|𝜃)𝑃(𝜃|ℳ)/𝑃(𝑋)
Dieses Verfahren ist mathematisch elegant, da es zu 100 % sicher gegen Überanpassung ist. Es erfordert jedoch eine strenge Disziplin: Wir dürfen unser Modell oder unseren Prior nicht auswählen, nachdem wir die Daten gesehen haben. Wenn wir die Daten verwenden, um zu entscheiden, welche Modellstruktur verwendet werden soll, zerstören wir die zugrunde liegende Logik der Schlussfolgerung.
Das wahrscheinlichste Modell angesichts der Gewichtung der Daten im Vergleich zum Modell
Die Qualität eines Modells kann durch Berücksichtigung seiner Überraschung berechnet werden (siehe z. B. (Vries, 2026)).
log 𝑃(𝑋|ℳ) = −surprisal = Genauigkeit – Komplexität
Modelle mit einer übermäßigen Anzahl von Parametern (weil man versucht sein könnte, alle möglichen hypothetischen Wechselwirkungen einzubeziehen) erreichen möglicherweise eine unglaubliche Genauigkeit, werden jedoch durch den Nachteil ihrer eigenen Komplexität „getötet“. Das ideale Modell ist nicht das detaillierteste; Es ist diejenige, die die meisten Informationen mit der geringsten Menge an unnötigem Ballast erfasst.
Wenn man eine Reihe von Modellen betrachtet, kann man die Wahrscheinlichkeit jedes Modells im Vergleich zu den betrachteten Modellen berechnen
𝑃(ℳ𝑖 ∣ 𝑋) ~ 𝑃(𝑋 | ℳ𝑖) 𝑃(ℳ𝑖 )
Es ist verlockend, einfach das Modell mit der höchsten Wahrscheinlichkeit auszuwählen und weiterzumachen. Doch dieser „Gewinner nimmt alles“-Ansatz birgt Risiken:
- Statistische Schwankungen: Die Daten 𝑋 können einen zufälligen Zufall enthalten, der ein suboptimales Modell vorübergehend überlegen erscheinen lässt.
- Das Gewicht der Masse: Manchmal überwiegt die Summe vieler „weniger wahrscheinlicher“ Modelle tatsächlich die Wahrscheinlichkeit des einzelnen „besten“ Modells.
Aus diesem Grund besteht ein robusterer Weg darin, alle Modelle voranzutreiben und sie nach ihrer Wahrscheinlichkeit zu gewichten. Es ist wichtig zu beachten, dass es sich hierbei nicht um eine „Mischung“ verschiedener Wahrheiten handelt; Wir gehen immer noch davon aus, dass nur ein Modell tatsächlich wahr ist, nutzen aber die gesamte Verteilung der Möglichkeiten, um unserer eigenen Unsicherheit Rechnung zu tragen.
Dichten
Eine Dichte unter Verwendung des Bayes’schen Ansatzes
Um eine Dichte als formales Modell zu behandeln, betrachten wir jeden ihrer 𝐾-Bins als Parameter. Konkret weisen wir ein Gewicht zu zu jedem Bin, was die Wahrscheinlichkeit darstellt, dass ein Datenpunkt in dieses Intervall fällt. Da sich die Gesamtwahrscheinlichkeit auf eins summieren muss (), eine Dichte mit 𝐾 Klassen wird durch 𝐾 −1 unabhängige Parameter definiert, solche Modelle werden auch Mischungen genannt. In unserem Bayes’schen Rahmen müssen wir diesen Gewichten ein Prior zuweisen. Da es sich um kategoriale Proportionen handelt, deren Summe eins ergeben muss, ist die Dirichlet-Verteilung die mathematisch natürliche Wahl.
Auswahl der Hyperparameter
Die Dirichlet-Verteilung wird durch Hyperparameter bestimmt, die oft als 𝛼 bezeichnet werden. Diese Werte stellen unsere „Pseudozählungen“ dar – im Wesentlichen das, wie die Dichte unserer Meinung nach vor uns aussieht
habe sogar den ersten Datenpunkt gesehen. Wenn wir einen flachen Prior annehmen (wobei die Evidenz 𝑃(𝑋) konstant ist), ergeben sich zwei Hauptstrategien für die Auswahl von 𝛼:
- 𝛼 =1/𝐾 (The Sparse Alternative): Dies wird häufig verwendet, wenn wir eine hohe Datenkonzentration erwarten. Es geht von vornherein davon aus, dass die Mehrheit der Behälter leer sein wird, was es zu einem „sparsity-fördernden“ Prior macht.
- 𝛼 =1 (Die einheitliche Wahl): Auch bekannt als Flat oder Laplace-Priorität. Dabei wird davon ausgegangen, dass jede mögliche Gewichtsverteilung gleich wahrscheinlich ist. Es fügt im Wesentlichen jedem Bin eine „virtuelle“ Beobachtung hinzu, bevor die realen Daten eintreffen.
Um eine Standarddichte zu konstruieren, ist die zweite Wahl 𝛼 = 1 oft die natürlichste. Es stellt einen neutralen Ausgangspunkt dar, bei dem wir davon ausgehen, dass die Daten gleichmäßig über das Intervall verteilt sind, bis die Beweise das Gegenteil beweisen.
Indem wir unsere Bins auf diese Weise definieren, haben wir die „Pixelierung“ einer Dichte in ein strenges Modell umgewandelt. Wir haben jetzt einen festen Parametersatz (𝐾 − 1 Gewichtungen) und einen klaren Prior (𝛼 = 1). Der nächste Schritt besteht darin, die Daten zu verwenden, um die optimale Anzahl von Bins 𝐾 zu bestimmen, indem die Genauigkeit der Anpassung gegen die Komplexität der Parameter abgewogen wird.
Beispiel
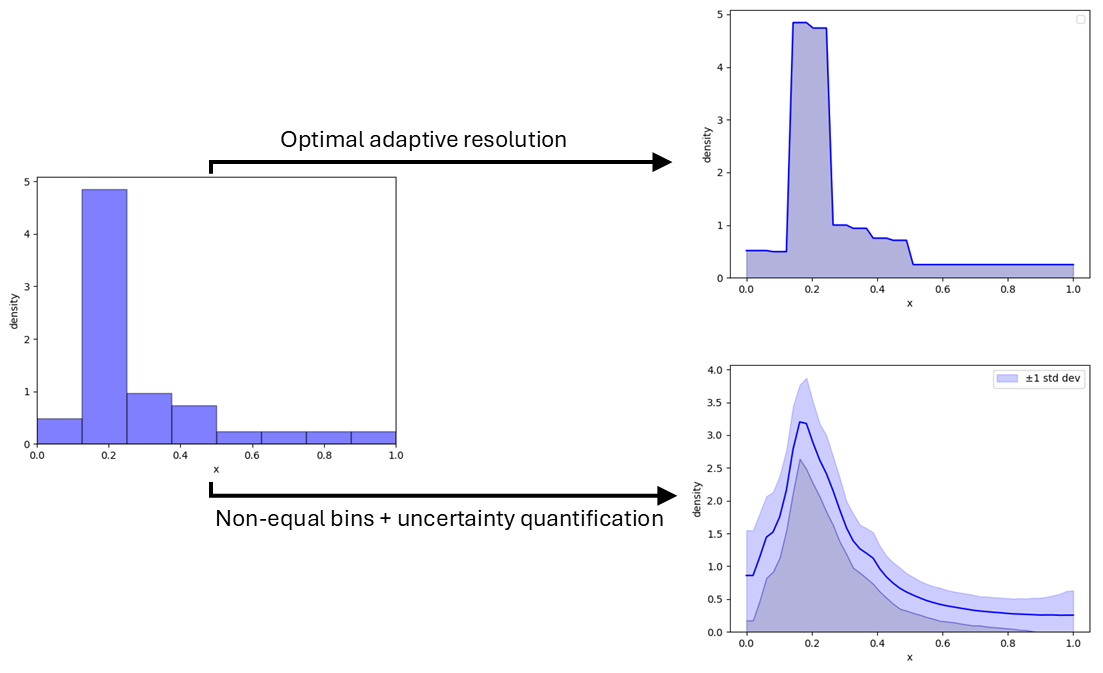
Bitte schauen Sie sich die Daten in der folgenden Abbildung an:

Bei Bestückung mit 8 Behältern erhalten wir:

Was man in dieser Dichte erkennen kann, ist, dass der Bereich ganz rechts über Null liegt, obwohl in diesem Bereich keine Datenpunkte vorhanden waren. Dies ist ein Ergebnis des Bayes’schen Ansatzes, der die angenommene Dichte auf der Grundlage unserer vorherigen Annahme und der von uns beobachteten Daten schätzt.
Zusammenfassend haben wir mithilfe eines Bayes’schen Ansatzes eine Dichte ermittelt. Wir haben einen Prior 𝑃(𝜃) definiert, der unsere Erwartung einer gleichmäßigen Dichte widerspiegelt. Dann haben wir die Daten genommen und den hinteren 𝑃(𝜃|𝑋) berechnet, der der resultierenden Dichte zugrunde liegt.
Gewichtete Dichten
Mit dem Ansatz des vorherigen Abschnitts können wir Dichten mit 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 und 1024 Klassen erstellen. Mehr Bins sorgen für eine genauere Anpassung der Daten, bringen aber auch zusätzliche Komplexität mit sich. Wie im vorherigen Abschnitt besprochen wurde, können Genauigkeit und Komplexität zur Berechnung der Beweise herangezogen werden. Wenn wir jede Dichte als Modell betrachten, können wir die Wahrscheinlichkeit, dass sie wahr ist, im Vergleich zu den von uns betrachteten Modellen berechnen. Daraus ergibt sich die folgende Abbildung:

Im vorherigen Abschnitt wurde besprochen, dass man das „beste“ Modell wählen kann, was in diesem Fall die Verwendung von 8 Behältern wäre. Es ist jedoch sicherer, eine gewichtete Summe über alle Modelle zu bilden. Das
Erträge:

Es ist wichtig zu erkennen, dass dies aus bayesianischer Sicht das Beste ist, was wir tun können. Beachten Sie auch, dass in diesem Diagramm eine Dichte von 1024 Behältern vorliegt. Schließlich kann man beweisen, dass die Dichten höherer Ordnungen N abnehmen.
Dichten mit ungleichen Behältern
Die zuvor erhaltene Dichte oben sieht etwas blockig aus, was auf die Wahl der Verwendung gleicher Bins zurückzuführen ist. Es stehen auch andere Optionen zur Verfügung, z. B. die Annahme zufälliger Teilungen (und die Kompensation der vorherigen Teilung). Daraus ergibt sich die folgende Grafik:

Dichten mit Fehlerbalken
Um nun die Konstruktion von Dichten abzuschließen, könnte es von Interesse sein, unsere Unsicherheit in diesen Dichten zu visualisieren. Obwohl die Berechnung numerisch aufwändig ist, ist der Ausdruck zur Berechnung der Standardabweichung in der Dichte bemerkenswert einfach (F. Pijlman, 2023).
Daraus ergeben sich folgende Dichten:


Schlussfolgerungen
Wir begannen mit einer einfachen Frage: Gibt es eine mathematische Grundlage für die Auswahl der Klassen in einem Histogramm? Da das Konzept der Bins Datenpunkte von Natur aus mit Dichten verbindet, haben wir untersucht, wie das geht
um Behälter für Dichten auszuwählen.
Mithilfe eines Bayes’schen Ansatzes (Informationstheorie) können Dichten angepasst werden, ohne dass eine Überanpassung befürchtet werden muss (zu viele Abschnitte zeigen zu viele Particulars). Obwohl man die „beste“ Bin-Breite berechnen kann, haben wir Folgendes gesehen:
- Durch die Modellgewichtung können wir mehrere Auflösungen kombinieren und so eine glattere und ehrlichere Darstellung der Daten ermöglichen.
- Dirichlet Priors geben uns eine rigorose Möglichkeit, unsere anfänglichen Annahmen über die Datenverteilung auszudrücken.
So wie die Störungstheorie eine Hierarchie für physikalische Wechselwirkungen bereitstellt, bietet dieses Bayes’sche Framework eine Hierarchie für die Datenauflösung. Die Auflösung skaliert natürlich, wenn mehr Daten verfügbar sind. Beachten Sie, dass solche Ideen auch beim Erlernen von Modellen verwendet werden können, bei denen es zu einer Erweiterung der Interaktionen kommt.
Die Methode zum Kombinieren von Dichten verschiedener Auflösungen wurde auch für den Fall untersucht, dass zufällige Bins ausgewählt werden. Dies führte zu glatten Histogrammen, die für die meisten Daten natürlicher erscheinen könnten
Sätze.
Wir haben auch die Verwendung von Standardabweichungen in Histogrammen vorgestellt. Obwohl die Berechnung der Standardabweichungen für Bayes-Modelle abgeleitet wurde, lässt ihr Berechnungsverfahren eine breitere Anwendbarkeit vermuten. Daher kann es zur Visualisierung der verbleibenden Unsicherheiten in der Dichte dienen.
Danksagungen
Das EdgeAI-Projekt „Edge AI Applied sciences for Optimized Efficiency Embedded Processing“ wurde vom Key Digital Applied sciences Joint Endeavor (KDT JU) im Rahmen der Fördervereinbarung Nr. 101097300 gefördert. Das KDT JU erhält Unterstützung vom Forschungs- und Innovationsprogramm Horizon Europe der Europäischen Union sowie von Österreich, Belgien, Frankreich, Griechenland, Italien, Lettland, Luxemburg, den Niederlanden und Norwegen.
Referenzen
- F. Pijlman, JL (2023). Varianz der Wahrscheinlichkeit von Daten. https://sitb2023.ulb.be/proceedings/, 34/37.
- Murphy, Okay. (2022). Probabilistisches maschinelles Lernen: Eine Einführung. MIT Press.
- Vries, B. d. (2026). Aktive Inferenz für physische KI-Agenten. arXiv.
Bio
Fetze Pijlman ist leitender Wissenschaftler bei Signify Analysis in Eindhoven, Niederlande. Sein Forschungsschwerpunkt umfasst probabilistisches maschinelles Lernen, Bayes’sche Inferenz und Signalverarbeitung, mit besonderem Interesse an der Anwendung dieser mathematischen Frameworks auf IoT, Sensorik und intelligente Systeme.