
Heutzutage steuern die meisten Webagenten einen Browser jeweils eine Aktion nach der anderen. Das Modell empfängt den aktuellen Seitenstatus – als Screenshot oder DOM-Textual content – und sagt den nächsten Klick, Tastendruck oder Bildlauf voraus. Dieses aktionsbasierte Design machte Sinn, als Sprachmodelle nur über begrenzte Argumentationsfähigkeiten verfügten. Da Modelle besser in der Lage sind, Code zu schreiben und zu debuggen, ist diese starre Schleife eher zu einer Einschränkung als zu einer hilfreichen Struktur geworden.
Das AI Frontiers-Labor von Microsoft Analysis hat einen anderen Ansatz entwickelt. Ihr neues Open-Supply-Framework, Webwrightgibt dem Agenten ein Terminal anstelle einer zustandsbehafteten Browsersitzung. Der Agent schreibt Playwright-Code zur Steuerung von Browsern, führt Bash-Befehle aus, überprüft Protokolle und verfeinert iterativ Skripte. Playwright ist eine Open-Supply-Browserautomatisierungsbibliothek, ebenfalls von Microsoft, die die programmgesteuerte Steuerung von Chromium-, Firefox- und WebKit-Browsern unterstützt.
Was Webwright anders macht
Webwright trennt den Agenten vom Browser und behandelt den Browser als etwas, das der Agent starten, prüfen und verwerfen kann, während er ein Programm entwickelt. Das persistente Artefakt ist nicht die Browsersitzung, sondern der Code und die Protokolle im lokalen Arbeitsbereich.
Dies ist das gleiche Modell, das ein Entwickler beim Schreiben eines RPA-Skripts (Robotic Course of Automation) verwendet. Anstatt jedes Mal manuell durch eine Website zu klicken, schreiben sie einmalig ein Skript. Dieses Skript kann erneut ausgeführt, angepasst und geteilt werden. Webwright wendet dies auf LLM-basierte Agenten an.
Das System hat drei Kernkomponenten: ein Runner, ein Modellendpunkt und eine Terminalumgebung. Der Runner umfasst etwa 150 Zeilen Code, die Modellschnittstelle etwa 550 Zeilen und die Umgebung etwa 300 Zeilen. Es gibt keine Multi-Agenten-Orchestrierung oder komplexe Planungshierarchie – nur eine einzelne Agentenschleife.
Der gesamte Zwischencode, alle Protokolle, Screenshots und Ergebnisse werden im Arbeitsbereich gespeichert, sodass jeder Lauf leicht zu überprüfen ist.
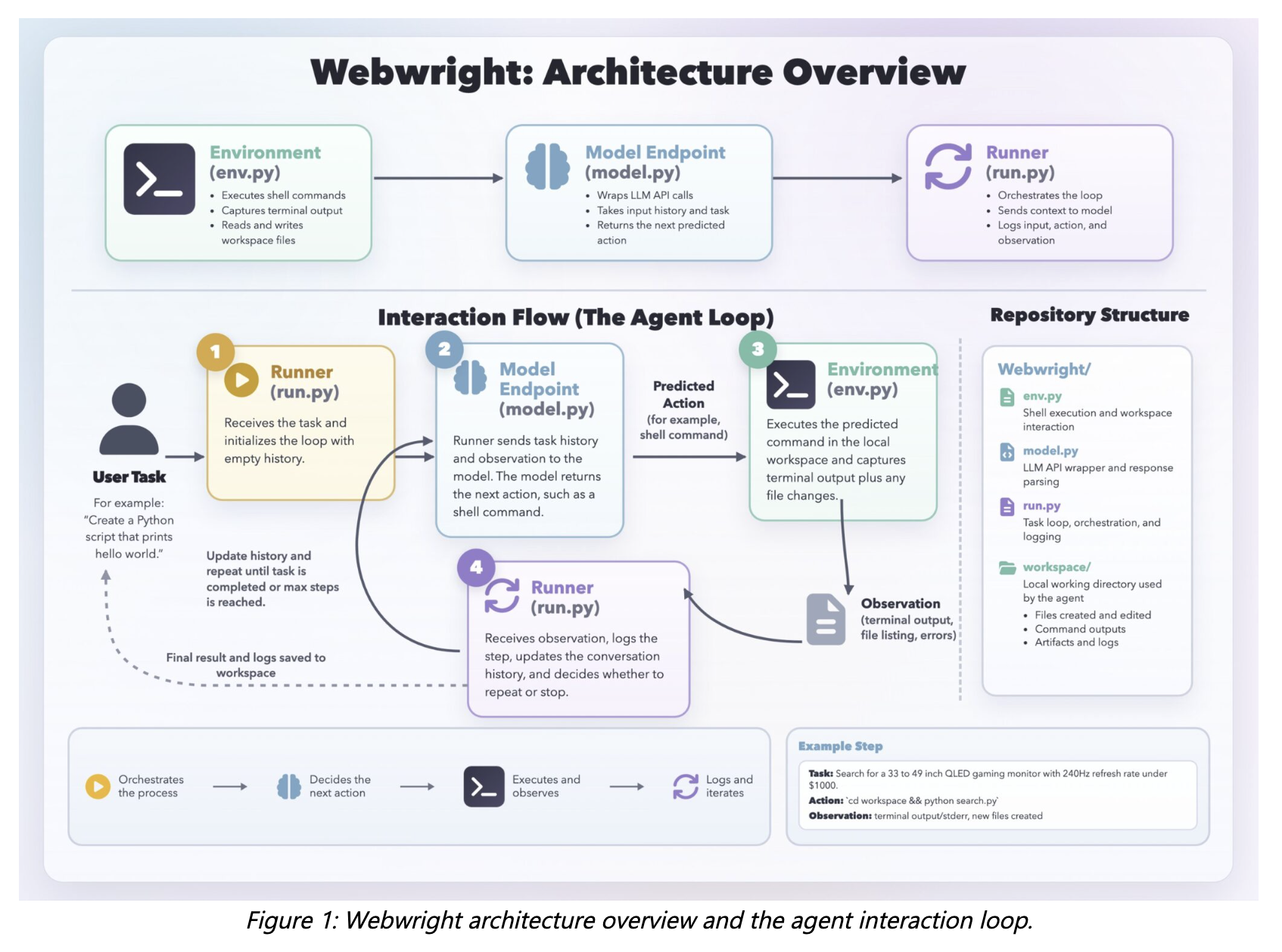
Die Agentenschleife
Der Runner sendet den aktuellen Kontext an das Modell. Das Modell gibt einen Denkblock und einen Shell-Befehl zurück. Dieser Befehl wird in der Umgebung ausgeführt, die Terminalausgaben, Protokolle, Screenshots oder Fehlerrückverfolgungen zurückgibt. Diese Beobachtungen werden wieder in den Kontext gebracht und die Schleife geht weiter.
Anstatt jeweils eine einfache Aktion auszuführen, kann ein Codierungsagent auf natürliche Weise mehrstufige Interaktionen – wie die Auswahl eines Datums oder das Ausfüllen eines gesamten Formulars – als kompaktes Programm ausdrücken. Schleifen, Funktionen und Abstraktionen ermöglichen es dem Agenten, über ähnliche Aufgaben hinweg zu verallgemeinern, ohne wiederholt ähnliche Abfolgen von Schritten auf niedriger Ebene vorherzusagen.
Zwei technische Herausforderungen
Vorzeitiges „erledigt“ und Kontextexplosion sind die beiden Kernthemen. Bei Bash-Aktionen mit offenem Ende muss das Modell selbst den Abschluss melden und behauptet oft, dass es erfolgreich sei, ohne es tatsächlich abzuschließen. Sie fügten ein Gate hinzu: Der Agent muss eine Selbstreflexionskonfiguration generieren, ein endgültiges Skript in einem neuen Ordner mit Protokollen und Screenshots ausführen und sein eigenes Selbstreflexionsurteil fällen, das vor der Ausgabe Erfolg oder Misserfolg ausgibt finished: true. Andernfalls wird die Markierung gelöscht und es wird ein neuer Versuch unternommen.
Was die Kontextlänge betrifft, überschreiten lange Codierungsverläufe schnell die Kontextgrenzen, sodass der Verlauf alle 20 Schritte in einer einzigen Zusammenfassung komprimiert wird.
Benchmark-Ergebnisse
Webwright wurde anhand von zwei Benchmarks bewertet: On-line-Mind2Web und Odysseys.
On-line-Mind2Web enthält 300 Aufgaben auf 136 weit verbreiteten Web sites und verwendet ein automatisiertes LLM-as-a-Decide-Bewertungsframework. GPT-5.4 erreicht eine Gesamtgenauigkeit von 86,67 % und stellt damit die höchste unter allen Open-Supply-Harness-Rezepten in der AutoEval-Kategorie des On-line-Mind2Web-Benchmarks mit einem Funds von 100 Schritten dar. Claude Opus 4.7 erreichte insgesamt 84,7 %, schnitt aber bei schwierigen Aufgaben mit N=100 Schritten besser ab – 80,5 % gegenüber 76,6 % für GPT-5.4.
Sie reproduzierten außerdem eine GPT-5.4-Basislinie in einer herkömmlichen, auf Screenshots basierenden Agenteneinstellung, bei der das Modell XY-Koordinaten für Klicks und Tippaktionen vorhersagt. Unter Verwendung desselben zugrunde liegenden Modells erzielt Webwright in allen drei Schwierigkeitskategorien erhebliche Fortschritte, was den Vorteil des codegesteuerten terminalbasierten Ansatzes gegenüber der schrittweisen Koordinatenvorhersage hervorhebt.
Odysseys wertet Shopping-Aufgaben über einen langen Zeitraum aus, die sich über mehrere Web sites erstrecken. Die Aufgaben umfassen durchschnittlich 272,3 Wörter an Anweisungen. In der Rangliste vom April 2026 battle das Modell Opus 4.6 mit einer Höchstpunktzahl von 44,5 das leistungsstärkste Modell. Webwright powered by GPT-5.4 erreicht 60,1 %, was einer relativen Verbesserung von 35,1 % gegenüber dem vorherigen Stand der Technik entspricht. Im Vergleich zur GPT-5.4-Basisleistung von 33,5 % entspricht dies einer relativen Verbesserung von 79,4 % – oder 26,6 absoluten Punkten.
Kostenanalyse
Claude Opus 4.7 ist hinsichtlich der Anzahl der Schritte zur Lösung jeder Aufgabe effizienter (durchschnittlich 21,9 Schritte) im Vergleich zu GPT-5.4 (durchschnittlich 26,3 Schritte). Allerdings ist Claude Opus 4.7 im Vergleich zu GPT-5.4 deutlich teurer (5 $ vs. 2,50 $ professional 1 Mio. Enter-Tokens und 25 $ vs. 15,00 $ professional 1 Mio. Output-Tokens, April 2026), wodurch die durchschnittlichen Kosten professional Aufgabe im Vergleich zu GPT-5.4 höher sind (2,37 $ vs. 6,09 $). Die ersten 50 Schritte liefern eine Genauigkeit von 82 % und die nächsten 50 Schritte liefern 3–4 zusätzliche Punkte.
Kleine Modellleistung
Das Forschungsteam testete Qwen3.5-9B auch auf dem Exhausting Cut up von On-line-Mind2Web. Wenn Aufgaben mit vorgefertigten wiederverwendbaren Device-Skripten erweitert werden, erreicht Qwen3.5-9B 66,2 % auf On-line-Mind2Web-Web sites mit mehr als fünf Instruments. Dies zeigt, dass kleinere, kostengünstigere Modelle in Kombination mit einer vorgefertigten Toolbibliothek komplexe Webaufgaben bewältigen können.
Der visuelle Erklärer von Marktechpost
Webwright
Kurzanleitung
Was ist Webwright?
Webwright ist ein terminal-natives Open-Supply-Webagenten-Framework von Microsoft-Forschung. Anstatt jeweils einen Browserklick vorherzusagen, schreibt der Agent Dramatiker Code, führt Bash-Befehle aus und speichert wiederverwendbare Skripte in einem lokalen Arbeitsbereich.
- ~1.000 Zeilen von Harness-Code über 3 Module hinweg – keine versteckte Orchestrierung
- Einzelagentenschleife: Runner, Modellendpunkt und Terminalumgebung
- 86,7 % auf On-line-Mind2Web | 60,1 % auf Odysseys mit GPT-5.4
- Backends: OpenAI, Anthropic, OpenRouter
- Skripte wiederverwendbar in Claude Code, Codex, OpenClaw
# GitHub repository
github.com/microsoft/Webwright
Was Sie vor der Set up benötigen
Stellen Sie sicher, dass Folgendes bereit ist, bevor Sie Installationsbefehle ausführen.
- Python 3.10+ — erforderliche Mindestlaufzeit
- Chrom — im nächsten Schritt über Playwright installiert
- API-Schlüssel – OpenAI, Anthropic oder OpenRouter
- Git – um das Repository zu klonen
# Verify your Python model python --version # Should return Python 3.10 or greater
Klonen und installieren Sie Webwright
Klonen Sie das Repo, installieren Sie es im bearbeitbaren Modus und installieren Sie dann Chromium für die Playwright-Browsersteuerung.
# 1. Clone the repository git clone https://github.com/microsoft/Webwright cd Webwright # 2. Set up the package deal in editable mode pip set up -e . # 3. Set up Chromium for Playwright playwright set up chromium
Der -e Flag bedeutet, dass Änderungen an der lokalen Quelle sofort und ohne Neuinstallation übernommen werden.
Führen Sie Ihre erste Webaufgabe aus
Exportieren Sie Ihren API-Schlüssel und übergeben Sie dann eine Aufgabenanweisung und eine Begin-URL an die CLI.
# Export your key export OPENAI_API_KEY="sk-..." export ANTHROPIC_API_KEY="sk-ant-..." # Run a activity python -m webwright.run.cli -c base.yaml -c model_openai.yaml -t "Discover least expensive economic system flight SEA to JFK on 2026-05-15" --start-url https://www.google.com/flights --task-id demo_openai -o outputs/default
| Flagge | Beschreibung |
|---|---|
| -C | Konfigurationsdatei von src/webwright/config/ – stapelbar |
| -T | Aufgabenanweisung in einfachem Englisch |
| –Begin-URL | Ursprüngliche URL für die Browsersitzung |
| –Aufgaben-ID | Identify des Ausgabe-Unterordners |
| -O | Root-Ausgabeverzeichnis für Protokolle und Skripte |
Nutzen Sie Webwright als Claude-Code-Fähigkeit
Webwright bietet eine integrierte Claude-Code-Fähigkeit. Über Ihr Claude Code-Abonnement hinaus ist kein separater LLM-API-Schlüssel erforderlich. Claude Code liest PNG-Screenshots nativ.
# Challenge-scoped (inside this repo solely) mkdir -p .claude/abilities .claude/instructions ln -s "$PWD/abilities/webwright" .claude/abilities/webwright ln -s "$PWD/abilities/webwright/instructions" .claude/instructions/webwright # Consumer-scoped (all initiatives) mkdir -p ~/.claude/abilities ~/.claude/instructions ln -s "$PWD/abilities/webwright" ~/.claude/abilities/webwright ln -s "$PWD/abilities/webwright/instructions" ~/.claude/instructions/webwright
Starten Sie Claude Code nach der Set up neu und verwenden Sie dann Slash-Befehle:
# One-shot activity /webwright:run search Google Flights SEA to JFK 2026-05-15 # Reusable parameterized CLI device /webwright:craft search a ticket from LAX to SFO depart June 7
Wichtige Erkenntnisse
- Webwright verwendet eine Terminalschleife, in der der Agent Playwright-Code schreibt und ausführt, anstatt jeweils eine Browseraktion vorherzusagen.
- GPT-5.4 erreichte 86,7 % bei On-line-Mind2Web (100-Schritte-Funds) und 60,1 % bei Odysseys – 26,6 Punkte über dem GPT-5.4-Basiswert von 33,5 %.
- Der Kabelbaum umfasst ca. 1.000 Leitungen in drei Modulen ohne Multi-Agent-Orchestrierung.
- Qwen3.5-9B erreichte 66,2 % beim harten Cut up von On-line-Mind2Web, wenn es mit vorgefertigten Device-Skripten erweitert wurde.
- Aufgabenskripte werden als wiederverwendbare CLIs gepackt und können von Claude Code, Codex und OpenClaw gemeinsam genutzt werden.
Schauen Sie sich das an Repo Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 150.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Möchten Sie mit uns zusammenarbeiten, um Ihr GitHub-Repo ODER Ihre Hugging Face Web page ODER Produktveröffentlichung ODER Ihr Webinar usw. zu bewerben? Vernetzen Sie sich mit uns