In diesem Artikel erfahren Sie, wie Sie Race Situations in Multi-Agent-Orchestrierungssystemen identifizieren, verstehen und entschärfen.
Zu den Themen, die wir behandeln werden, gehören:
- Wie Race Situations in Umgebungen mit mehreren Agenten aussehen
- Architekturmuster zur Verhinderung von Shared-State-Konflikten
- Praktische Strategien wie Idempotenz, Sperren und Parallelitätstests
Kommen wir gleich zur Sache.
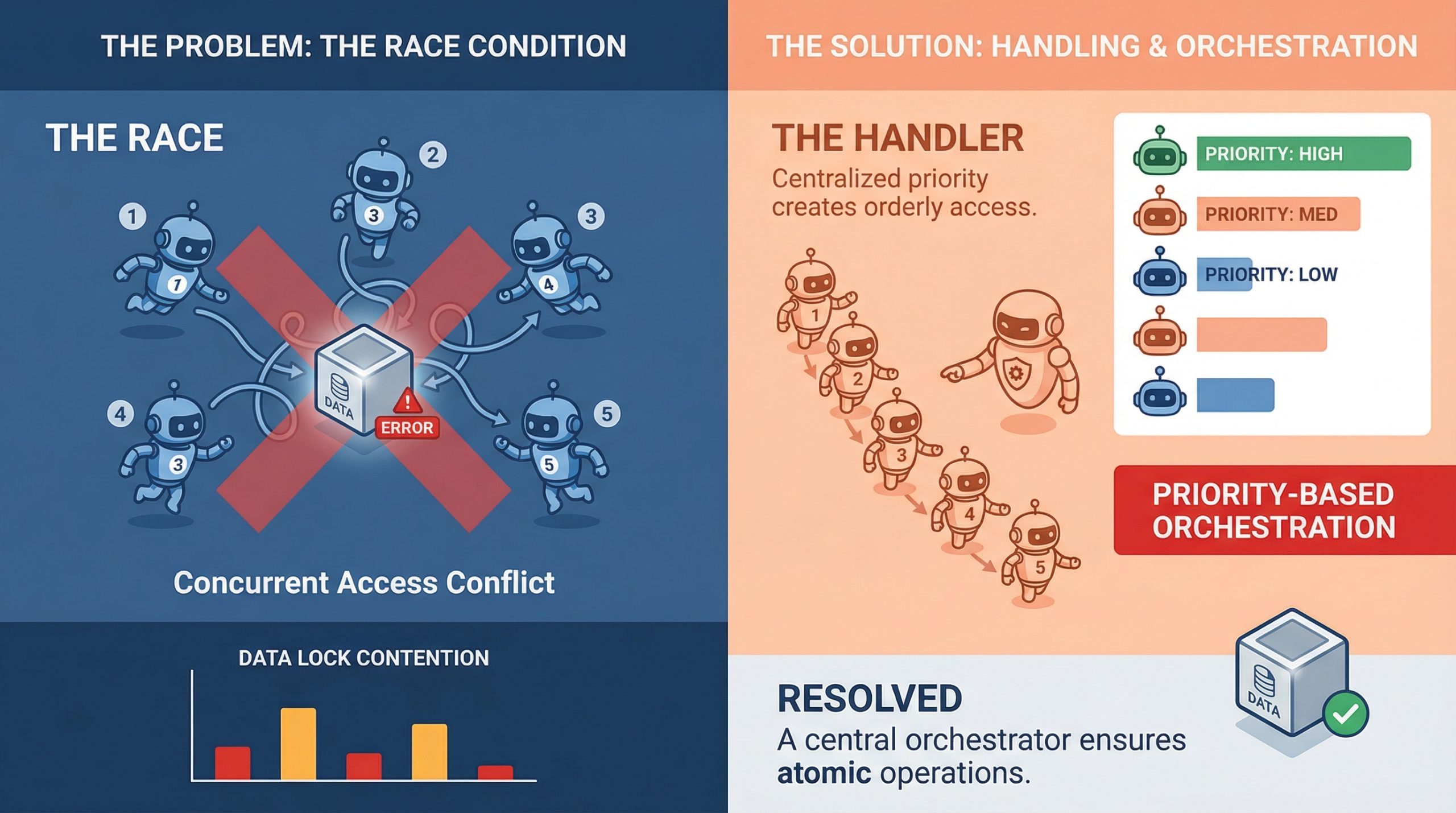
Umgang mit Race Situations in der Multi-Agent-Orchestrierung
Bild vom Herausgeber
Wenn Sie schon einmal beobachtet haben, wie zwei Agenten gleichzeitig souverän auf dieselbe Ressource schreiben und etwas produzieren, das keinen Sinn ergibt, wissen Sie bereits, wie sich eine Race Situation in der Praxis anfühlt. Es ist einer dieser Fehler, der in Unit-Checks nicht auftaucht, sich im Staging perfekt verhält und dann in der Produktion während Ihres Fensters mit dem höchsten Datenverkehr explodiert.
In Systemen mit mehreren Agenten, in denen es auf die parallele Ausführung ankommt, sind Race Situations keine Grenzfälle. Sie sind erwartete Gäste. Um zu verstehen, wie man mit ihnen umgeht, geht es weniger darum, defensiv zu sein, als vielmehr darum, Systeme aufzubauen, die standardmäßig Chaos annehmen.
Wie Race Situations in Multi-Agent-Systemen tatsächlich aussehen
Eine Race-Bedingung tritt auf, wenn zwei oder mehr Agenten gleichzeitig versuchen, den gemeinsamen Standing zu lesen, zu ändern oder zu schreiben Das Endergebnis hängt davon ab, wer zuerst dort ankommt. In einer Single-Agent-Pipeline ist das beherrschbar. In einem System mit fünf Agenten, die gleichzeitig laufen, ist das ein ganz anderes Drawback.
Das Schwierige daran ist, dass es bei den Rennbedingungen nicht immer zu offensichtlichen Unfällen kommt. Manchmal schweigen sie. Agent A liest ein Dokument, Agent B aktualisiert es eine halbe Sekunde später und Agent A schreibt eine veraltete Model zurück, ohne dass irgendwo ein Fehler ausgegeben wird. Das System sieht intestine aus. Die Daten sind kompromittiert.
Was macht das noch schlimmer? speziell in Pipelines für maschinelles Lernen liegt darin, dass Agenten häufig an veränderlichen gemeinsam genutzten Objekten arbeiten, sei es ein gemeinsam genutzter Speicher, eine Vektordatenbank, ein Instrument-Ausgabecache oder eine einfache Aufgabenwarteschlange. Jedes davon kann zu einem Streitpunkt werden, wenn mehrere Agenten gleichzeitig damit beginnen, von ihnen zu profitieren.
Warum Multi-Agent-Pipelines besonders anfällig sind
Die traditionelle gleichzeitige Programmierung verfügt über jahrzehntelange Instruments rund um Race Situations: Threads, Mutexe, Semaphoren und atomare Operationen. Multiagenten-LLM-Systeme (Massive Language Mannequin) sind neuer, und sie basieren oft auf asynchronen FrameworksNachrichtenbroker und Orchestrierungsebenen, die Ihnen nicht immer eine detaillierte Kontrolle über die Ausführungsreihenfolge ermöglichen.
Es gibt auch das Drawback des Nichtdeterminismus. LLM-Agenten Nehmen Sie sich nicht immer gleich viel Zeit, um eine Aufgabe zu erledigen. Ein Agent ist möglicherweise in 200 ms fertig, während ein anderer 2 Sekunden benötigt, und der Orchestrator muss damit elegant umgehen. Wenn dies nicht der Fall ist, beginnen die Agenten, sich gegenseitig auszunutzen, und es entsteht ein beschädigter Zustand oder widersprüchliche Schreibvorgänge, die das System stillschweigend akzeptiert.
Auch hier spielen die Kommunikationsmuster der Agenten eine große Rolle. Wenn Agenten den Standing über ein zentrales Objekt oder eine gemeinsam genutzte Datenbankzeile teilen, anstatt Nachrichten weiterzuleiten, ist es quick sicher, dass sie in großem Umfang auf Schreibkonflikte stoßen. Hierbei handelt es sich sowohl um ein Designmuster- als auch um ein Parallelitätsproblem, und die Behebung beginnt normalerweise auf der Architekturebene, bevor Sie überhaupt mit dem Code in Berührung kommen.
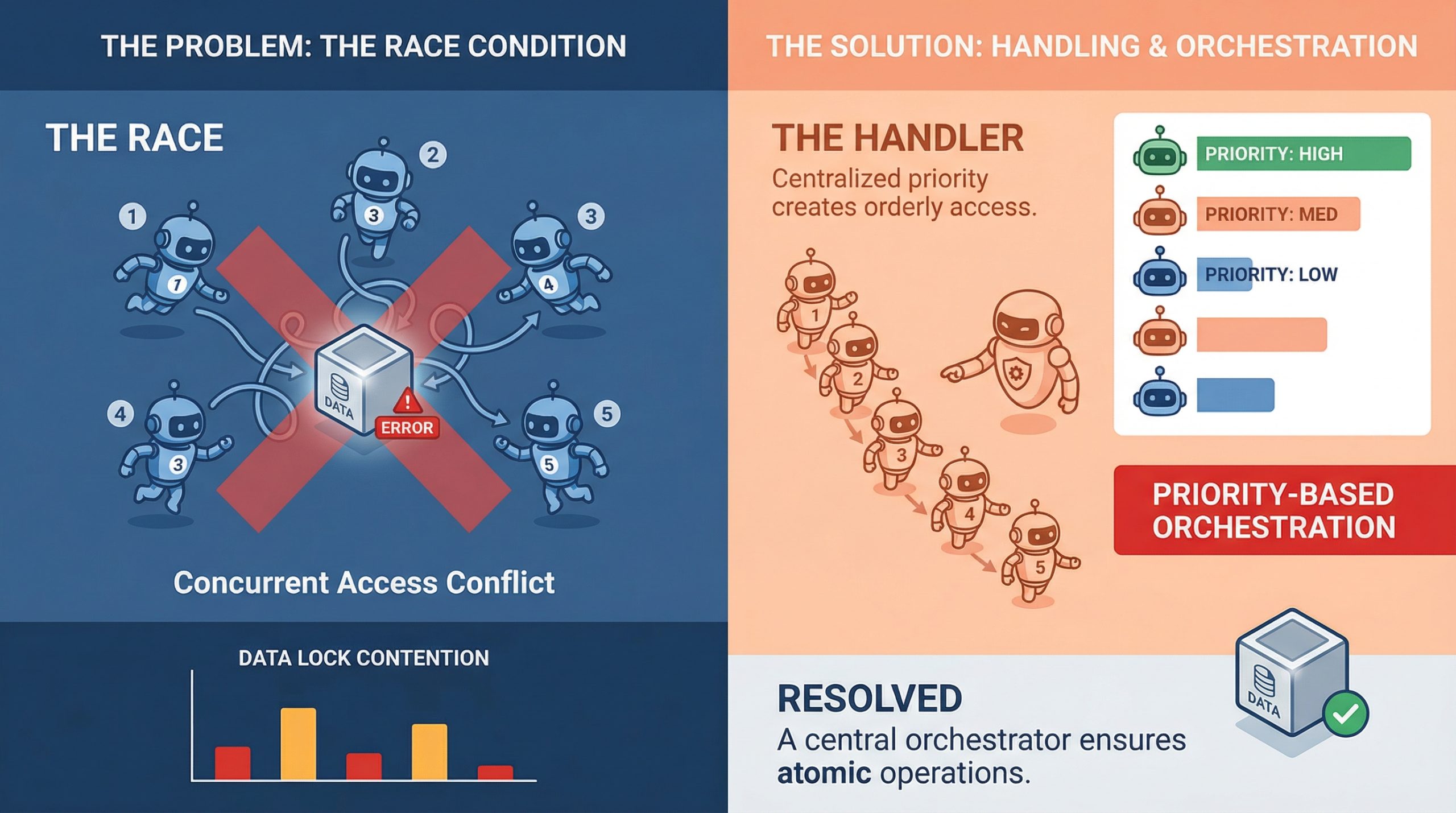
Sperren, Warteschlangen und ereignisgesteuertes Design
Der direkteste Weg zur Bewältigung gemeinsamer Ressourcenkonflikte erfolgt durch Verriegelung. Optimistisches Sperren funktioniert intestine, wenn Konflikte selten sind: Jeder Agent liest neben den Daten ein Variations-Tag, und wenn sich die Model zum Zeitpunkt des Schreibversuchs geändert hat, schlägt der Schreibvorgang fehl und es wird ein neuer Versuch unternommen. Pessimistisches Sperren ist aggressiver und reserviert die Ressource vor dem Lesen. Bei beiden Ansätzen gibt es Kompromisse. Welcher Ansatz passt, hängt davon ab, wie oft Ihre Agenten tatsächlich kollidieren.
Warteschlangen sind ein weiterer solider Ansatz, insbesondere für die Aufgabenzuweisung. Anstatt dass mehrere Agenten direkt eine gemeinsame Aufgabenliste abfragen, schieben Sie Aufgaben in eine Warteschlange und lassen die Agenten sie einzeln bearbeiten. Systeme wie Redis Streams, RabbitMQ, oder sogar eine einfache Postgres-Beratungssperre kann damit intestine umgehen. Die Warteschlange wird zu Ihrem Serialisierungspunkt, wodurch das Rennen um dieses bestimmte Zugriffsmuster aus der Gleichung genommen wird.
Ereignisgesteuerte Architekturen gehen noch weiter. Anstatt dass Agenten aus dem gemeinsamen Standing lesen, reagieren sie auf Ereignisse. Agent A beendet seine Arbeit und gibt ein Ereignis aus. Agent B wartet auf dieses Ereignis und greift von dort aus auf. Dies führt zu einer lockeren Kopplung und verringert natürlich das Überlappungsfenster, in dem zwei Agenten möglicherweise gleichzeitig dasselbe ändern.
Idempotenz ist dein bester Freund
Selbst wenn eine solide Verriegelung und Warteschlange vorhanden sind, geht immer noch etwas schief. Netzwerkprobleme treten auf, es kommt zu Zeitüberschreitungen und Agenten versuchen fehlgeschlagene Vorgänge erneut. Wenn diese Wiederholungsversuche nicht idempotent sind, kommt es am Ende zu doppelten Schreibvorgängen, doppelt verarbeiteten Aufgaben oder zusammengesetzten Fehlern, deren Fehlerbehebung im Nachhinein schwierig ist.
Idempotenz bedeutet, dass die mehrmalige Ausführung derselben Operation zum gleichen Ergebnis führt wie die einmalige Ausführung. Für Agenten bedeutet das oft, bei jedem Schreibvorgang eine eindeutige Vorgangs-ID anzugeben. Wenn der Vorgang bereits angewendet wurde, erkennt das System die ID und überspringt das Duplikat. Es handelt sich um eine kleine Designentscheidung mit erheblichen Auswirkungen auf die Zuverlässigkeit.
Es lohnt sich Idempotenz von Anfang an auf Agentenebene einbauen. Ein späteres Nachrüsten ist schmerzhaft. Agenten, die in Datenbanken schreiben, Datensätze aktualisieren oder nachgelagerte Arbeitsabläufe auslösen, sollten alle über eine Kind der Deduplizierungslogik verfügen, da sie das gesamte System widerstandsfähiger gegen die Unordnung der realen Ausführung macht.
Testen Sie die Rennbedingungen, bevor sie Sie testen
Der Der schwierige Teil der Rennbedingungen besteht darin, sie zu reproduzieren. Sie sind zeitabhängig, was bedeutet, dass sie häufig nur unter Final oder in bestimmten Ausführungssequenzen auftreten, die in einer kontrollierten Testumgebung nur schwer reproduzierbar sind.
Ein nützlicher Ansatz sind Stresstests mit absichtlicher Parallelität. Starten Sie mehrere Agenten gleichzeitig für eine gemeinsam genutzte Ressource und beobachten Sie, was kaputt geht. Instruments wie Locust, pytest-asyncio mit gleichzeitigen Aufgaben oder sogar einer einfachen ThreadPoolExecutor kann dabei helfen, die Artwork der überlappenden Ausführung zu simulieren, die Konfliktfehler eher beim Staging als bei der Produktion aufdeckt.
Eigenschaftsbasierte Checks werden in diesem Zusammenhang zu wenig genutzt. Wenn Sie Invarianten definieren können, die unabhängig von der Ausführungsreihenfolge immer gelten sollen, können Sie randomisierte Checks ausführen, die versuchen, diese zu verletzen. Es wird nicht alles erfasst, aber es wird viele der subtilen Konsistenzprobleme ans Licht bringen, die bei deterministischen Checks völlig übersehen werden.
Ein konkretes Beispiel für eine Rennbedingung
Es hilft, dies zu konkretisieren. Stellen Sie sich einen einfachen gemeinsamen Zähler vor, den mehrere Agenten aktualisieren. Dabei kann es sich um etwas Reales handeln, etwa um zu verfolgen, wie oft ein Dokument verarbeitet wurde oder wie viele Aufgaben abgeschlossen wurden.
Hier ist eine Minimalversion des Issues im Pseudocode:
|
# Geteilter Zustand Schalter = 0 # Agentenaufgabe def Inkrementzähler(): international Schalter Wert = Schalter # Schritt 1: lesen Wert = Wert + 1 # Schritt 2: Ändern Schalter = Wert # Schritt 3: Schreiben |
Stellen Sie sich nun vor, dass zwei Agenten dies gleichzeitig ausführen:
- Agent A liest
counter = 0 - Agent B liest
counter = 0 - Agent A schreibt
counter = 1 - Agent B schreibt
counter = 1
Sie haben erwartet, dass der Endwert 2 ist. Stattdessen ist er 1. Keine Fehler, keine Warnungen – nur stillschweigend falscher Zustand. Das ist eine Rennbedingung in ihrer einfachsten Kind.
Abhängig von Ihrem Systemdesign gibt es verschiedene Möglichkeiten, dies zu mildern.
Possibility 1: Sperren des kritischen Abschnitts
Die direkteste Lösung besteht darin, sicherzustellen, dass jeweils nur ein Agent die gemeinsam genutzte Ressource ändern kann, hier im Pseudocode gezeigt:
|
sperren.erwerben() Wert = Schalter Wert = Wert + 1 Schalter = Wert sperren.freigeben() |
Dies garantiert Korrektheit, geht jedoch mit einer verringerten Parallelität einher. Wenn viele Agenten um dieselbe Sperre konkurrieren, kann der Durchsatz schnell sinken.
Possibility 2: Atomare Operationen
Wenn Ihre Infrastruktur dies unterstützt, sind atomare Updates eine sauberere Lösung. Anstatt den Vorgang in Lese-, Änderungs- und Schreibschritte zu unterteilen, delegieren Sie ihn an das zugrunde liegende System:
|
Schalter = atomares_Inkrement(Schalter) |
Datenbanken, Schlüsselwertspeicher und einige In-Reminiscence-Systeme bieten dies standardmäßig an. Es entfernt das Rennen vollständig, indem es das Replace unteilbar macht.
Possibility 3: Idempotente Schreibvorgänge mit Versionierung
Ein anderer Ansatz besteht darin, widersprüchliche Updates mithilfe der Versionierung zu erkennen und abzulehnen:
|
# Mit Model lesen Wert, Model = read_counter() # Schreibversuch Erfolg = write_counter(Wert + 1, erwartete_Version=Model) Wenn nicht Erfolg: wiederholen() |
Dies ist in der Praxis eine optimistische Verriegelung. Wenn ein anderer Agent den Zähler zuerst aktualisiert, schlägt Ihr Schreibvorgang fehl und es wird mit dem neuen Standing erneut versucht.
In echten Multiagentensystemen ist der „Zähler“ selten so einfach. Dabei kann es sich um ein Dokument, einen Speicher oder ein Workflow-Statusobjekt handeln. Aber das Muster ist dasselbe: Jedes Mal, wenn Sie einen Lese- und Schreibvorgang auf mehrere Schritte aufteilen, entsteht ein Fenster, in dem ein anderer Agent eingreifen kann.
Das Schließen dieses Fensters durch Sperren, atomare Operationen oder Konflikterkennung ist der Kern des praktischen Umgangs mit Race Situations.
Letzte Gedanken
Race-Bedingungen in Multiagentensystemen sind beherrschbar, erfordern jedoch eine bewusste Gestaltung. Die Systeme, die damit intestine umgehen, sind nicht diejenigen, die mit dem Timing Glück hatten; Sie gingen davon aus, dass Parallelität Probleme verursachen würde, und planten entsprechend.
Idempotente Operationen, ereignisgesteuerte Kommunikation, intelligente Sperren und eine ordnungsgemäße Warteschlangenverwaltung sind kein Over-Engineering. Sie bilden die Grundlage für jede Pipeline, in der Agenten parallel arbeiten sollen, ohne sich gegenseitig zu beeinträchtigen. Wenn diese Grundlagen richtig sind, wird der Relaxation weitaus vorhersehbarer.