Das „Gruppen sind bemerkenswert clever und oft schlauer als die klügsten Leute in ihnen.“ Er schrieb über Entscheidungsfindungaber das gleiche Prinzip gilt auch für die Klassifizierung: Beschreiben Sie genügend Personen, um dasselbe Phänomen zu beschreiben, und es entsteht eine Taxonomie, auch wenn keine zwei Personen es auf die gleiche Weise formulieren. Die Herausforderung besteht darin, dieses Sign aus dem Rauschen zu extrahieren.
Ich hatte mehrere tausend Zeilen mit Freitextdaten und musste genau das tun. In jeder Zeile befand sich eine kurze Erläuterung in natürlicher Sprache warum eine automatisierte Sicherheitsfeststellung irrelevant strugglewelche Funktionen für einen Repair verwendet werden sollen oder welche Codierungspraktiken zu befolgen sind. Eine Individual hat geschrieben „Das ist Testcode, der nirgendwo bereitgestellt wird.“ Ein anderer schrieb „Nicht-Produktionsumgebung, kann man getrost ignorieren.“ Ein Dritter schrieb „Läuft nur während Integrationstests in der CI/CD-Pipeline.“ Alle drei meinten dasselbe, aber keiner teilte mehr als ein oder zwei Worte miteinander.
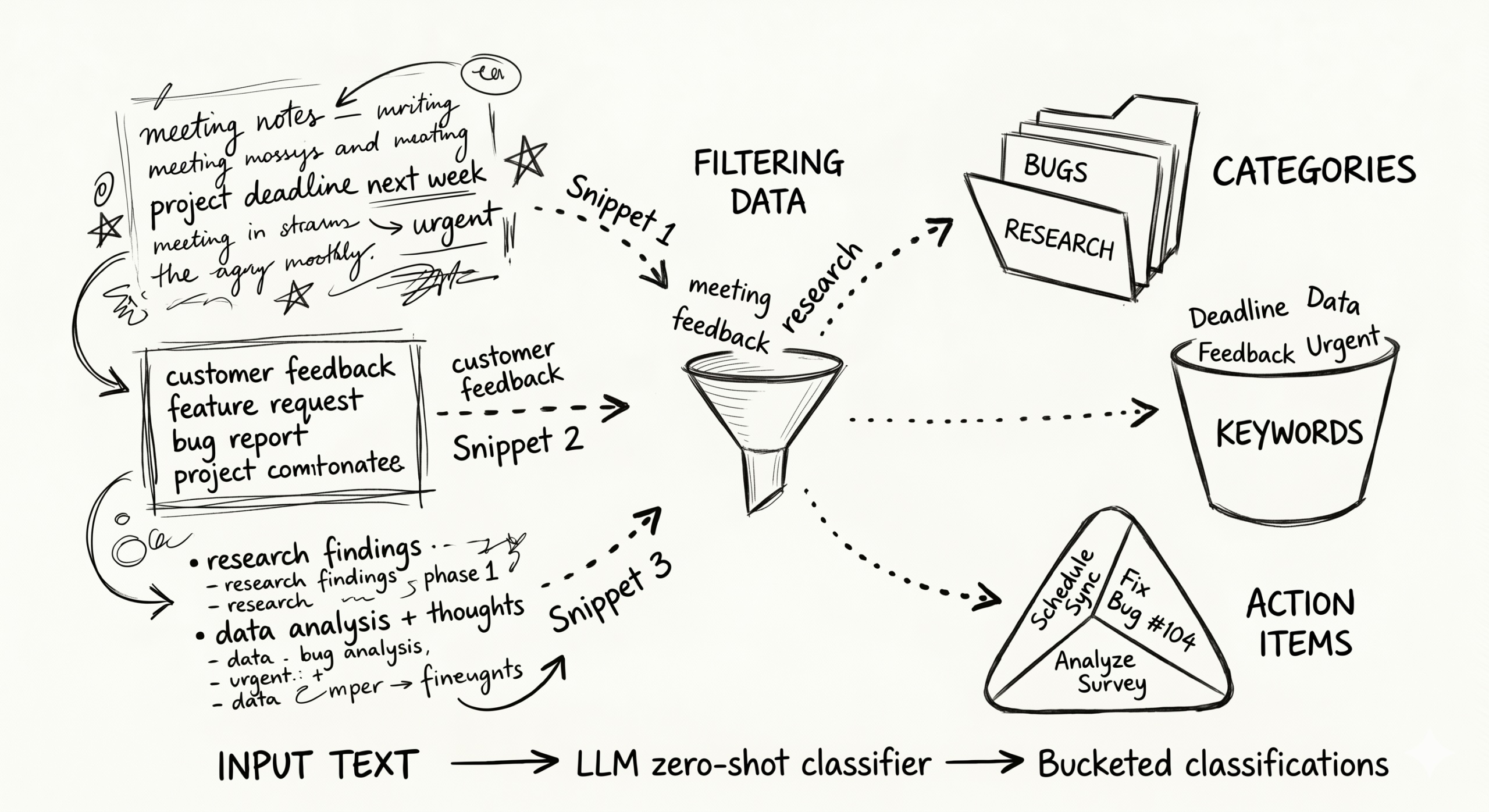
Die Taxonomie struggle da drin. Ich brauchte nur das richtige Werkzeug, um es zu extrahieren. Herkömmliches Clustering und Key phrase-Matching kamen mit der Paraphrase-Variante nicht zurecht, additionally habe ich etwas ausprobiert, über das noch nicht viel diskutiert wurde: Verwendung eines lokal gehosteten LLM als Zero-Shot-Klassifikator. In diesem Weblog-Beitrag geht es um die Leistung und Funktionsweise sowie um einige Tipps für die eigene Verwendung und Bereitstellung dieser Systeme.
Warum traditionelles Clustering mit kurzen Freitexten zu kämpfen hat
Standardmäßiges unbeaufsichtigtes Clustering funktioniert durch die Suche nach mathematischer Nähe in einem bestimmten Merkmalsraum. Bei langen Dokumenten ist dies normalerweise in Ordnung. In Wortfrequenzen oder Einbettungsvektoren ist genügend Sign vorhanden, um kohärente Gruppen zu bilden. Aber kurze, semantisch dichte Texte widerlegen diese Annahmen auf einige spezifische Arten.
Durch die Einbettung von Ähnlichkeit werden unterschiedliche Bedeutungen vermischt. „Dieser Schlüssel wird nur in der Entwicklung verwendet“ Und „Dieser API-Schlüssel ist der Einfachheit halber fest codiert„Erzeugen Sie ähnliche Einbettungen, da sich das Vokabular überschneidet. Bei einem geht es jedoch um eine Nicht-Produktionsumgebung und bei dem anderen um einen absichtlichen Sicherheitskompromiss. Ok-bedeutet oder DBSCAN kann sie nicht unterscheiden, weil die Vektoren zu nahe beieinander liegen.
Themenmodelle bringen Wörter zum Vorschein, keine Konzepte. Latente Dirichlet-Zuordnung (LDA) und seine Varianten finden Muster des gleichzeitigen Vorkommens von Wörtern. Wenn Ihr Korpus aus Ein-Satz-Anmerkungen besteht, ist das Sign für das gemeinsame Vorkommen von Wörtern zu spärlich, um sinnvolle Themen zu bilden. Sie erhalten Cluster, die definiert sind durch „prüfen“ oder „Code“ oder „Sicherheit” statt kohärenter Themen.
Regex und Key phrase-Matching können Paraphrasenvariationen nicht verarbeiten. Sie könnten Regeln zum Fangen schreiben.Testcode“ Und „Nichtproduktion„Aber du würdest es vermissen“Wird nur während der CI verwendet„ „nie eingesetzt„ „Nur für die Entwicklung vorgesehenes Gerät“ und Dutzende anderer Formulierungen, die alle dieselbe Grundidee zum Ausdruck bringen.
Der rote Faden besteht darin, dass diese Methoden eher auf Oberflächenmerkmalen (Tokens, Vektoren, Mustern) als auf semantischen Bedeutungen basieren. Für Klassifizierungsaufgaben, bei denen die Bedeutung wichtiger ist als der Wortschatz, benötigen Sie etwas, das die Sprache versteht.
LLMs als Zero-Shot-Klassifikatoren
Die wichtigste Erkenntnis ist einfach: Anstatt einen Algorithmus mit der Entdeckung von Clustern zu beauftragen, definieren Sie Ihre Kandidatenkategorien basierend auf Domänenwissen und bitten Sie ein Sprachmodell, jeden Eintrag zu klassifizieren.
Dies funktioniert, weil LLMs semantische Bedeutungen verarbeiten und nicht nur Tokenmuster. „Dieser Schlüssel wird nur in der Entwicklung verwendet“ Und „Nicht-Produktionsumgebung, die Sie ignorieren können„Enthalten quick keine überlappenden Wörter, aber ein Sprachmodell erkennt, dass sie dieselbe Idee ausdrücken. Dies ist nicht nur eine Instinct. Chae und Davidson (2025) verglichen 10 Modelle mit Null-Schuss-, Wenig-Schuss- und fein abgestimmten Trainingsprogrammen und stellten fest, dass große LLMs im Null-Schuss-Modus mit fein abgestimmtem BERT bei Haltungserkennungsaufgaben konkurrenzfähig waren. Wang et al. (2023) fanden heraus, dass LLMs modernste Klassifizierungsmethoden bei drei von vier Benchmark-Datensätzen übertrafen, indem sie ausschließlich Zero-Shot-Prompts verwendeten und keine gekennzeichneten Trainingsdaten erforderlich waren.
Das Setup besteht aus drei Komponenten:
- Kandidatenkategorien. Eine Liste sich gegenseitig ausschließender Kategorien, die aus Domänenwissen definiert werden. In meinem Fall habe ich mit etwa 10 erwarteten Themen begonnen (Testcode, Eingabevalidierung, Framework-Schutz, Nicht-Produktionsumgebungen usw.) und nach Durchsicht eines Beispiels auf 20 Kandidaten erweitert.
- Eine Eingabeaufforderung zur Klassifizierung. Strukturiert, um eine Kategoriebezeichnung und einen kurzen Grund zurückzugeben. Niedrige Temperatur (0,1) für Konsistenz. Kurze maximale Ausgabe (100 Token), da wir nur ein Etikett und keinen Aufsatz benötigen.
- Ein lokales LLM. Ich habe verwendet Ollama um Modelle lokal auszuführen. Keine API-Kosten, keine Daten verlassen meinen Pc und schnell genug für Tausende von Klassifizierungen.
Hier ist der Kern der Klassifizierungsaufforderung:
CLASSIFICATION_PROMPT = """
Classify this textual content into considered one of these themes:
{themes}
Textual content:
"{content material}"
Reply with ONLY the theme quantity and identify, and a quick cause.
Format: THEME_NUMBER. THEME_NAME | Cause
Classification:
"""Und der Ollama-Ruf:
response = ollama.generate(
mannequin="gemma2",
immediate=immediate,
choices={
"temperature": 0.1, # Low temp for constant classification
"num_predict": 100, # Quick response, we simply want a label
}
)Zwei Dinge sind zu beachten. Zunächst kommt es auf die Temperatureinstellung an. Bei 0,7 oder höher kann die gleiche Eingabe in verschiedenen Läufen zu unterschiedlichen Klassifizierungen führen. Bei 0,1 ist das Modell nahezu deterministisch, was zu einer reibungslosen Klassifizierung beiträgt. Zweitens, einschränkend num_predict verhindert, dass das Modell Erklärungen generiert, die Sie nicht benötigen, was den Durchsatz erheblich beschleunigt.
Bau der Pipeline
Die vollständige Pipeline besteht aus drei Schritten: Vorverarbeitung, Klassifizierung, Analyse.
Vorverarbeitung Entfernt Inhalte, die Token hinzufügen, ohne ein Klassifizierungssignal hinzuzufügen. URLs, Standardphrasen („Weitere Informationen finden Sie unter…“) und alle Formatierungsartefakte werden entfernt. Allgemeine Begriffe werden normalisiert („falsch positiv„ wird zu „FP„ „Produktion„ wird zu „Prod„), um die Token-Variation zu reduzieren. Durch die Deduplizierung durch Content material-Hash werden exakte Wiederholungen entfernt. Dieser Schritt reduzierte mein Token-Price range ungefähr 30 % und die Klassifizierung konsistenter gemacht.
Einstufung führt jeden Eintrag mit den Kandidatenkategorien durch das LLM. Für ca. 7.000 Einträge dauerte dies auf einem MacBook Professional etwa 45 Minuten Gemma 2 (9B Parameter). Habe ich auch getestet Lama 3.2 (3B), das in Grenzfällen, in denen zwei Kategorien nahe beieinander lagen, schneller, aber etwas ungenauer struggle. Gemma 2 verarbeitete mehrdeutige Eingaben deutlich besser.
Ein praktisches Downside: Lange Läufe können auf halbem Weg scheitern. Die Pipeline speichert alle 100 Klassifizierungen Prüfpunkte, sodass Sie dort weitermachen können, wo Sie aufgehört haben.
Analyse fasst die Ergebnisse zusammen und generiert ein Verteilungsdiagramm. So sah die Ausgabe aus:

Das Diagramm erzählt eine klare Geschichte. Über ein Viertel aller Einträge beschrieb Code, der nur in Nicht-Produktionsumgebungen läuft. Weitere 21,9 % beschrieben Fälle, in denen ein Sicherheitsrahmen das Risiko bereits bewältigt. Allein diese beiden Kategorien machen die Hälfte des Datensatzes aus. Das ist die Artwork von Erkenntnissen, die auf andere Weise aus unstrukturiertem Textual content nur schwer zu extrahieren sind.
Wenn dieser Ansatz nicht die richtige Lösung ist
Diese Technik funktioniert am besten in einer bestimmten Nische: mittelgroße Datensätze (Hunderte bis Zehntausende Einträge), semantisch komplexer Textual content und Situationen, in denen Sie über genügend Domänenwissen verfügen, um Kandidatenkategorien zu definieren, aber keine gekennzeichneten Trainingsdaten.
Es ist nicht Das richtige Werkzeug, wenn:
- Ihre Kategorien sind schlüsselwortdefiniert (verwenden Sie einfach Regex),
- wenn Sie Trainingsdaten gekennzeichnet haben (trainieren Sie einen überwachten Klassifikator; das geht schneller und billiger),
- wenn Sie eine Latenzzeit von weniger als einer Sekunde im großen Maßstab benötigen (verwenden Sie Einbettungen und eine Suche nach dem nächsten Nachbarn),
- oder wenn Sie wirklich nicht wissen, welche Kategorien existieren. Führen Sie in diesem Fall zunächst eine explorative Themenmodellierung durch, um die Instinct zu entwickeln, und wechseln Sie dann zur LLM-Klassifizierung, sobald Sie Kategorien definieren können.
Die andere Einschränkung ist der Durchsatz. Selbst auf einer schnellen Maschine bedeutet die Klassifizierung eines Eintrags professional Sekundenbruchteil, dass 7.000 Einträge quick eine Stunde dauern. Für Datensätze mit mehr als 100.000 Einträgen benötigen Sie ein API-gehostetes Modell oder eine Batch-Strategie.
Andere Anwendungen, die einen Versuch wert sind
Die Pipeline lässt sich auf jedes Downside verallgemeinern, bei dem Sie unstrukturierten Textual content haben und strukturierte Kategorien benötigen.
Kundenfeedback. NPS-Antworten, Help-Tickets und offene Umfragen haben alle das gleiche Downside: unterschiedliche Formulierungen für eine begrenzte Anzahl zugrunde liegender Themen. „Ihre App stürzt jedes Mal ab, wenn ich die Einstellungen öffne“ und „SDie Einstellungsseite ist unter iOS defekt„gehören zur gleichen Kategorie, aber die Key phrase-Übereinstimmung wird das nicht erfassen.
Triage von Fehlerberichten. Freitext-Fehlerbeschreibungen können automatisch nach Komponente, Grundursache oder Schweregrad kategorisiert werden. Dies ist besonders nützlich, wenn die Individual, die den Fehler meldet, nicht weiß, welche Komponente dafür verantwortlich ist.
Klassifizierung der Codeabsicht. Dies ist etwas, das ich noch nicht ausprobiert habe, das ich aber überzeugend finde: Codefragmente klassifizieren, Semgrep-Regelnoder Konfigurationsregeln nach Zweck (Authentifizierung, Datenzugriff, Fehlerbehandlung, Protokollierung). Es gilt die gleiche Technik. Definieren Sie die Kategorien, schreiben Sie eine Klassifizierungsaufforderung und führen Sie den Korpus durch ein lokales Modell aus.
Erste Schritte
Die Pipeline ist unkompliziert: Definieren Sie Ihre Kategorien, schreiben Sie eine Klassifizierungsaufforderung und lassen Sie Ihre Daten durch ein lokales Modell laufen.
Der schwierigste Teil ist nicht der Code. Es geht darum, Kategorien zu definieren, die sich gegenseitig ausschließen und kollektiv erschöpfend sind. Mein Rat: Beginnen Sie mit einer Stichprobe von 100 Einträgen, klassifizieren Sie diese manuell, achten Sie darauf, nach welchen Kategorien Sie immer wieder greifen, und verwenden Sie diese als Kandidatenliste. Lassen Sie dann das LLM das Muster skalieren.
Ich habe diese Technik als Teil eines verwendet umfassendere Analyse darüber, wie Sicherheitsteams Schwachstellen beheben. Die Klassifizierungsergebnisse haben dazu beigetragen, herauszufinden, welche Arten von Sicherheitskontexten in Unternehmen am häufigsten vorkommen, und die obige Tabelle ist eines der Ergebnisse dieser Arbeit. Wenn Sie sich für den Sicherheitsaspekt interessieren, finden Sie den vollständigen Bericht unter diesem Hyperlink.