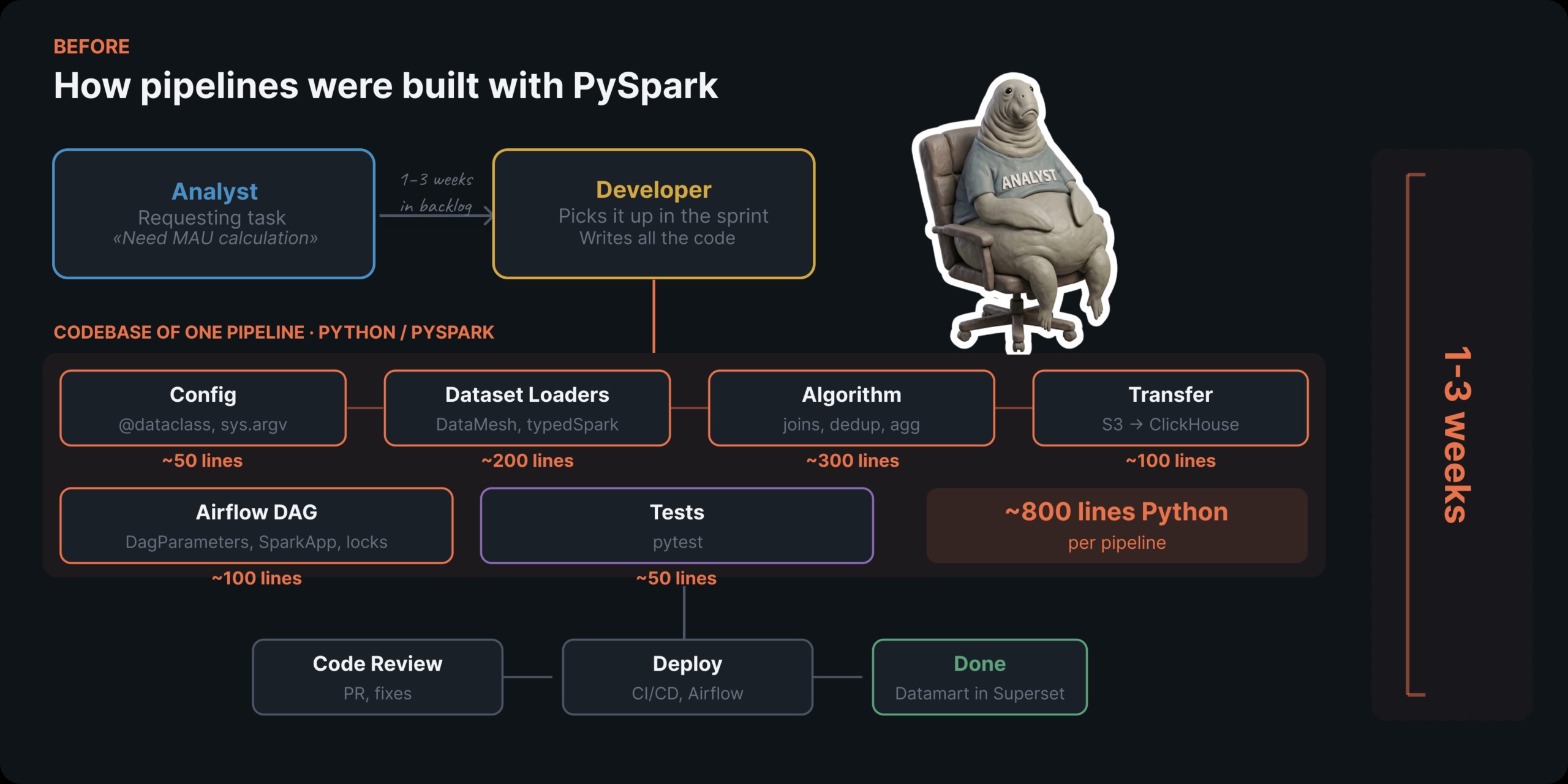
Es dauerte drei Wochen, bis wir eine einzelne Datenpipeline auslieferten. Heutzutage erledigt ein Analyst ohne Python-Erfahrung dies an einem Tag. So sind wir dorthin gekommen.
Ich bin Kiril Kazlou, Dateningenieur bei Mindbox. Unser Group berechnet regelmäßig Geschäftskennzahlen für Kunden neu. Das bedeutet, dass wir ständig Datenmarts für Abrechnungen und Analysen erstellen und dabei auf Dutzende verschiedener Quellen zurückgreifen.
Lange Zeit haben wir uns bei der gesamten Datenverarbeitung auf PySpark verlassen. Das Drawback? Ohne Python-Erfahrung kann man nicht wirklich mit PySpark arbeiten. Jede neue Pipeline erforderte einen Entwickler. Und das bedeutete Warten – manchmal wochenlang.
In diesem Beitrag erkläre ich Ihnen, wie wir eine interne Datenplattform aufgebaut haben, auf der ein Analyst oder Produktmanager durch das Schreiben von nur vier YAML-Dateien eine regelmäßig aktualisierte Pipeline aufbauen kann.
Warum PySpark uns verlangsamte
Lassen Sie mich den Schmerz anhand eines Lehrbuchbeispiels veranschaulichen – der Berechnung von MAU (Month-to-month Lively Customers).
Oberflächlich betrachtet fühlt sich das wie ein einfacher SQL-Job an: COUNT(DISTINCT customerId) über ein paar Tische hinweg über ein Zeitfenster hinweg. Aber wegen des ganzen Infrastrukturaufwands – PySpark, Airflow DAG-Einrichtung, Spark-Ressourcenzuweisung, Checks – mussten wir ihn den Entwicklern überlassen. Das Ergebnis? Eine ganze Woche allein für den Versand eines MAU-Zählers.
Die Bereitstellung jeder neuen Metrik dauerte ein bis drei Wochen. Und jedes Mal sah der Prozess gleich aus:
- Ein Analyst definierte die Geschäftsanforderungen, fand einen verfügbaren Entwickler und übergab den Kontext.
- Der Entwickler klärte Particulars, schrieb PySpark-Code, führte eine Codeüberprüfung durch, konfigurierte die DAG und stellte sie bereit.
Was wir eigentlich wollten, warfare, dass Analysten und Produktmanager – die Leute, die die Geschäftslogik am besten verstehen und fließend SQL und YAML beherrschen – sich selbst darum kümmern. Kein Python. Kein PySpark.

Wodurch wir PySpark ersetzt haben: YAML und SQL sind alles, was Sie brauchen
Um einen deklarativen Ansatz zu verfolgen, haben wir unsere Datenschicht in drei Teile aufgeteilt und für jeden das richtige Software ausgewählt:
- dlt (Datenladetool) – Nimmt Daten von externen APIs und Datenbanken in den Objektspeicher auf. Komplett über eine YAML-Datei konfiguriert. Kein Code erforderlich.
- dbt (Datenerstellungstool) auf Trino – transformiert Daten mit reinem SQL. Es verknüpft Modelle über
ref()erstellt automatisch ein Abhängigkeitsdiagramm und verarbeitet inkrementelle Aktualisierungen. - Luftstrom + Kosmos – orchestriert die Pipelines. Der Airflow DAG wird automatisch generiert
dag.yamlund das dbt-Projekt.
Wir verwendeten Trino bereits als Abfrage-Engine für Advert-hoc-Abfragen und hatten es in Superset für BI integriert. Es hatte sich bereits bewährt: Bei Abfragen mit Standardlogik verarbeitete es riesige Datenmengen schneller und mit weniger Ressourcen als Spark. Darüber hinaus unterstützt Trino nativ den Verbundzugriff auf mehrere Datenspeicher über eine einzige SQL-Abfrage. Für 90 % unserer Pipelines passte Trino perfekt.

So laden wir Daten: dlt.yaml
Die erste YAML-Datei beschreibt, wo und wie Daten für die Weiterverarbeitung geladen werden. Hier ist ein Beispiel aus der Praxis – Laden von Rechnungsdaten von einer internen API:
product: sg-team
characteristic: billing
schema: billing_tarification
dag:
dag_id: dlt_billing_tarification
schedule: "0 4 * * *"
description: "Day by day refresh of tarification knowledge"
tags:
- billing
alerts:
enabled: true
severity: warning
supply:
kind: rest_api
shopper:
base_url: "https://internal-api.instance.com"
auth:
kind: bearer
token: dlt-billing.token
assets:
- identify: tarification_data
endpoint:
path: /tarificationData
methodology: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
pricingPlanLine: CurrentPlan
write_disposition: change
processing_steps:
- map: dlt_custom.billing_tarification_data.map
- identify: charges_raw
columns:
staffUserName:
data_type: textual content
nullable: true
endpoint:
path: /data-feed/costs
methodology: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
write_disposition: change
- identify: discounts_raw
endpoint:
path: /data-feed/reductions
methodology: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
write_disposition: changeDiese Konfiguration definiert vier Ressourcen aus einer einzigen API. Für jeden geben wir den Endpunkt, Anforderungsparameter und eine Schreibstrategie an – in unserem Fall change bedeutet „Jedes Mal überschreiben“. Sie können außerdem Verarbeitungsschritte hinzufügen, Spaltentypen definieren und Warnungen konfigurieren.
Die gesamte Konfiguration ist 40 Zeilen YAML. Ohne DLT wäre jeder Connector ein Python-Skript, das Anforderungen, Paginierung, Wiederholungsversuche, Serialisierung in das Delta-Desk-Format und Uploads in den Speicher verarbeitet.
Wie wir Daten mit SQL transformieren: dbt_project.yaml und assets.yaml
Der nächste Schritt ist die Konfiguration des DBT-Modells. Bei Trino bedeutet das SQL-Abfragen.
Hier ist ein Beispiel dafür, wie wir die MAU-Berechnung einrichten. So sieht Eventvorbereitung aus einer Hand aus:
-- int_mau_events_visits.sql (simplified)
{{ config(materialized='desk') }}
WITH interval AS (
-- Rolling window: final 5 months to present
SELECT
YEAR(CURRENT_DATE - INTERVAL '5' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '5' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
occasions AS (
-- Pull go to occasions inside the interval window
SELECT src._tenant, src.unmergedCustomerId,
'visits' AS src_type, src.endpoint
FROM {{ supply('last', 'customerstracking_visits') }} src
CROSS JOIN interval p
WHERE src.unmergedCustomerId IS NOT NULL
AND /* ...timestamp filtering by 12 months/month bounds... */
),
events_with_customer AS (
-- Resolve merged buyer IDs
SELECT e._tenant,
COALESCE(mc.mergedCustomerId, e.unmergedCustomerId) AS customerId,
e.src_type, e.endpoint
FROM occasions e
LEFT JOIN {{ ref('int_merged_customers') }} mc
ON e._tenant = mc._tenant
AND e.unmergedCustomerId = mc.unmergedCustomerId
)
-- Hold solely precise (non-deleted) prospects
SELECT ewc._tenant, ewc.customerId, ewc.src_type, ewc.endpoint
FROM events_with_customer ewc
WHERE EXISTS (
SELECT 1 FROM {{ ref('int_actual_customers') }} ac
WHERE ewc._tenant = ac._tenant
AND ewc.customerId = ac.customerId
)Alle 10 Ereignisquellen folgen genau dem gleichen Muster. Die einzigen Unterschiede sind die Quelltabelle und die Filter. Dann verschmelzen die Modelle zu einem einzigen Stream:
-- int_mau_events.sql (union of all sources)
SELECT * FROM {{ ref('int_mau_events_inapps_targetings') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_inapps_clicks') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_visits') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_orders') }}
-- ...plus 6 extra sourcesUnd schließlich der Knowledge Mart, in dem alles aggregiert wird:
-- mau_period_datamart.sql
{{ config(
materialized='incremental',
incremental_strategy='merge',
unique_key=('_tenant', 'start_year', 'start_month', 'end_year', 'end_month')
) }}
int -%
WITH interval AS (
SELECT
YEAR(CURRENT_DATE - INTERVAL '{{ months_back }}' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '{{ months_back }}' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
events_resolved AS (
SELECT * FROM {{ ref('int_mau_events') }}
),
metrics_by_tenant AS (
SELECT
er._tenant,
COUNT(DISTINCT CASE WHEN src_type = 'visits'
THEN customerId END) AS CustomersTracking_Visits,
COUNT(DISTINCT CASE WHEN src_type = 'orders'
THEN customerId END) AS ProcessingOrders_Orders,
COUNT(DISTINCT CASE WHEN src_type = 'mailings'
THEN customerId END) AS Mailings_MessageStatuses,
-- ...different metrics
COUNT(DISTINCT customerId) AS MAU
FROM events_resolved er
GROUP BY er._tenant
)
SELECT m.*, p.start_year, p.start_month, p.end_year, p.end_month
FROM metrics_by_tenant m
CROSS JOIN interval pFür die Knowledge-Mart-Konfiguration verwenden wir incremental_strategy='merge'. dbt generiert automatisch die Zusammenführungsabfrage und ersetzt die unique_key für upsert. Es ist nicht erforderlich, das inkrementelle Laden manuell zu implementieren.
Um die Modelle in einem einzigen Projekt zu verknüpfen, haben wir eingerichtet dbt_project.yaml:
identify: mau_period
model: '1.0.0'
fashions:
mau_period:
+on_table_exists: change
+on_schema_change: append_new_columnsUnd sources.yamldas die Eingabetabellen beschreibt:
sources:
- identify: last
database: data_platform
schema: last
tables:
- identify: inapps_targetings_v2
- identify: inapps_clicks_v2
- identify: customerstracking_visits
- identify: processingorders_orders
- identify: cdp_mergedcustomers_v2
# ...Das Ergebnis ist dieselbe Geschäftslogik wie in PySpark, jedoch in reinem SQL: sources.yaml ersetzt typedspark-Schemas, {{ ref() }} Und {{ supply() }} ersetzen .get_table()und die automatische Ausführungsreihenfolge über das Abhängigkeitsdiagramm ersetzt die manuelle Optimierung der Spark-Ressourcen.
So konfigurieren wir Airflow: dag.yaml
Die vierte Konfigurationsdatei definiert, wann und wie Airflow die Pipeline ausführt:
product: sg-team
characteristic: billing
schema: mau
schedule: "15 21 * * *" # each day at 00:15 MSK
params:
- identify: start_date
description: "Begin date (YYYY-MM-DD). Depart empty for auto"
default: ""
- identify: end_date
description: "Finish date (YYYY-MM-DD). Depart empty for auto"
default: ""
- identify: months_back
description: "Months to look again (default: 5)"
default: 5
alerts:
enabled: true
severity: warningDann wird unser Python-Skript analysiert dag.yaml Und dbt_project.yaml und nutzt die Cosmos-Bibliothek, um einen voll funktionsfähigen Airflow DAG zu generieren. Das ist das einziger Teil des Python-Codes im gesamten Setup. Es wird einmal geschrieben und funktioniert für jedes DBT-Projekt. Hier ist der Schlüsselteil:
def _build_dbt_project_dags(project_path: Path, environ: dict) -> record(DbtDag):
config_dict = yaml.safe_load(dag_config_path.read_text())
config = DagConfig.model_validate(config_dict)
# YAML params → Airflow Params
params = {}
operator_vars = {}
for param in config.params:
params(param.identify) = Param(
default=param.default if param.default shouldn't be None else "",
description=param.description,
)
operator_vars(param.identify) = f"{{{{ params.{param.identify} }}}}"
# Cosmos creates the DAG from the dbt mission
with DbtDag(
dag_id=f"dbt_{project_path.identify}",
schedule=config.schedule,
params=params,
project_config=ProjectConfig(dbt_project_path=project_path),
profile_config=ProfileConfig(
profile_name="default",
target_name=project_name,
profile_mapping=TrinoLDAPProfileMapping(
conn_id="trino_default",
profile_args={
"database": profile_database,
"schema": profile_schema,
},
),
),
operator_args={"vars": operator_vars},
) as dag:
# Create schema earlier than operating fashions
create_schema = SQLExecuteQueryOperator(
task_id="create_schema",
conn_id="trino_default",
sql=f"CREATE SCHEMA IF NOT EXISTS {profile_database}.{profile_schema} ...",
)
# Connect to root duties
for unique_id, _ in dag.dbt_graph.filtered_nodes.gadgets():
job = dag.tasks_map(unique_id)
if not job.upstream_task_ids:
create_schema >> jobKosmos liest manifest.json aus dem dbt-Projekt analysiert das Modellabhängigkeitsdiagramm und erstellt für jedes Modell eine separate Airflow-Aufgabe. Aufgabenabhängigkeiten werden automatisch basierend darauf erstellt ref() Aufrufe im SQL.
Wie Analysten Pipelines ohne Entwickler aufbauen
Wenn ein Analyst nun eine neue wiederkehrende Pipeline benötigt, kann er diese in wenigen Schritten zusammenstellen:
Schritt 1. Erstellen Sie einen Ordner im Repo: dbt-projects/my_new_pipeline/.
Schritt 2. Wenn eine externe Datenaufnahme erforderlich ist, schreiben Sie eine YAML-Konfiguration für dlt.
Schritt 3. Schreiben Sie SQL-Modelle in die fashions/ Ordner und beschreiben Sie die Quellen in sources.yaml.
Schritt 4. Erstellen dbt_project.yaml Und dag.yaml.
Schritt 5. Auf Git übertragen, Überprüfung durchführen, zusammenführen.
CI/CD erstellt das dbt-Projekt und sendet Artefakte an S3. Airflow liest die DAG-Dateien von dort, Cosmos analysiert das DBT-Projekt und generiert das Aufgabendiagramm. Pünktlich führt dbt die Modelle auf Trino in der richtigen Reihenfolge aus. Das Endergebnis ist ein aktualisierter Knowledge Mart im Warehouse, auf den über Superset zugegriffen werden kann.
Was sich nach der Migration geändert hat

Damit Analysten selbst Pipelines aufbauen können, müssen sie verstehen ref() Und supply() Konzepte, der Unterschied zwischen desk Und incremental Materialisierung und die Grundlagen von Git. Wir haben einige interne Workshops durchgeführt und Schritt-für-Schritt-Anleitungen für jeden Aufgabentyp zusammengestellt.
Warum der neue Stack PySpark nicht vollständig ersetzt
Für etwa 10 % unserer Pipelines ist PySpark immer noch die einzige Possibility – wenn eine Transformation einfach nicht in SQL passt. dbt unterstützt Jinja-Makros, aber das ist kein Ersatz für vollwertiges Python. Und es wäre unehrlich, die Grenzen der neuen Instruments außer Acht zu lassen.
dlt + Delta: experimentelle Upsert-Unterstützung. Wir verwenden das Delta-Format in unserer Speicherschicht. Der Delta-Connector von dlt ist als experimentell gekennzeichnet, daher hat die Zusammenführungsstrategie nicht sofort funktioniert. Wir mussten Workarounds finden – in einigen Fällen haben wir sie genutzt change anstatt merge (Opfer der Inkrementalität), und in anderen haben wir Brauch geschrieben processing_steps.
Trinos begrenzte Fehlertoleranz. Trino verfügt zwar über einen Fehlertoleranzmechanismus, dieser funktioniert jedoch durch das Schreiben von Zwischenergebnissen in S3. Bei unseren Datenmengen im Terabyte-Bereich ist dies unpraktisch – die schiere Anzahl der S3-Vorgänge macht es unerschwinglich teuer. Ohne aktivierte Fehlertoleranz schlägt die gesamte Abfrage fehl, wenn ein Trino-Employee ausfällt. Im Gegensatz dazu startet Spark nur die fehlgeschlagene Aufgabe neu. Wir haben dieses Drawback mit Wiederholungsversuchen auf DAG-Ebene und durch die Zerlegung schwerer Modelle in Ketten mittelschwerer Modelle behoben.
UDFs und benutzerdefinierte Logik. In Spark können Sie benutzerdefinierte Logik in Python direkt in der Pipeline schreiben – tremendous praktisch. Mit der neuen Architektur ist dies viel schwieriger. dbt auf Trino hilft nicht: Jinja generiert nur SQL und die Python-Modelle von dbt funktionieren nur mit Snowflake, Databricks und BigQuery. Sie können UDFs in Trino schreiben, aber nur in Java – mit dem gesamten damit verbundenen Aufwand: einem separaten Repo, einer Construct-Pipeline und der Bereitstellung von JARs für alle Employee. Wenn additionally eine Transformation nicht in SQL passt, entsteht entweder ein nicht wartbares SQL-Monster oder ein eigenständiges Skript, das die Abstammungslinie unterbricht.
Was kommt als Nächstes: Checks, Modellvorlagen und Schulungen
Bessere Checks. Wir hatten solide Pipeline-Checks in PySpark, aber die neue Architektur holt immer noch auf. In den letzten dbt-Versionen wurden Unit-Checks eingeführt – Sie können jetzt die SQL-Modelllogik anhand von Scheindaten validieren, ohne die gesamte Pipeline hochfahren zu müssen. Wir möchten DBT-Checks sowohl auf Modellebene als auch als separate Überwachungsebene hinzufügen.
Wiederverwendbare Vorlagen für gängige Muster. Viele unserer dbt-Modelle sehen gleich aus. Eine einzelne Konfiguration könnte ein Dutzend Modelle mit demselben Muster beschreiben – nur die Quelltabelle und die Filter unterscheiden sich. Wir planen, die gemeinsame Logik in DBT-Makros zu extrahieren.
Erweiterung der Nutzerbasis der Plattform. Wir möchten, dass mehr Ingenieure und Analysten unabhängig mit Daten arbeiten. Wir planen regelmäßige interne Schulungen, Dokumentationen und Onboarding-Leitfäden, damit neue Benutzer sich schnell einarbeiten und mit der Erstellung ihrer eigenen Modelle beginnen können.
Wenn Ihr Group in der gleichen Schleife „Analysten warten auf Entwickler“ feststeckt, würde ich gerne hören, wie Sie das Drawback lösen. Vernetzen Sie sich mit mir auf LinkedIn und vergleichen wir unsere Notizen.
Alle Bilder in diesem Artikel stammen vom Autor, sofern nicht anders angegeben.