
Bei der Bereitstellung der KI-Modelle für Einzelhandelsumgebungen kann es einige praktische Einschränkungen geben. Einzelhandelsumgebungen können Systeme auf Filialebene, Edge-Geräte und eine budgetbewusste Einrichtung umfassen, insbesondere für kleine und mittlere Einzelhandelsunternehmen. Ein solcher wichtiger Anwendungsfall ist die Bedarfsprognose für die Bestandsverwaltung oder Regaloptimierung. Das bereitgestellte Modell muss klein, schnell und genau sein.
Genau daran werden wir hier arbeiten. In diesem Artikel werde ich Sie Schritt für Schritt durch drei Komprimierungstechniken führen. Wir beginnen mit der Erstellung eines Foundation-LSTM. Dann messen wir seine Größe und Genauigkeit und wenden sie dann jeweils an Komprimierungsmethode nacheinander, um zu sehen, wie es das Modell verändert. Am Ende werden wir alles in einem direkten Vergleich zusammenführen.
Additionally, ohne Verzögerung, lasst uns gleich loslegen.
Das Downside: Einzelhandels-KI am Edge
Da sich jetzt alles an den Rand verlagert, bewegt sich der Einzelhandel auch in Richtung mobiler Apps, Geräte und IoT-Sensoren auf Filialebene, die die Modelle ausführen und die Prognose lokal vorhersagen können, anstatt jedes Mal die Cloud-APIs aufzurufen.
A Prognosemodell Die Ausführung auf einem Ladengerät oder einer mobilen App, wie z. B. einem Regalsensor oder Scanner, kann mit Einschränkungen wie begrenztem Speicher und begrenztem Akku verbunden sein und erfordert eine geringe Netzwerklatenz.
Selbst bei Cloud-Bereitstellungen können die Kosten gesenkt werden, wenn die Modellgröße kleiner ist. Vor allem, wenn Sie täglich Tausende von Vorhersagen für einen riesigen Produktkatalog durchführen. Ein Modell mit einer Größe von 4 KB kostet deutlich weniger als ein Modell mit einer Größe von 64 KB
Nicht nur die Kosten, sondern auch die Inferenzgeschwindigkeit beeinflusst die Entscheidungen in Echtzeit. Eine schnellere Modellvorhersage kann der Bestandsoptimierung und Wiederauffüllungswarnungen zugute kommen.
Benchmarking-Setup
Für das Experiment habe ich den Prognosedatensatz zur Artikelnachfrage von Kaggle auf Filialebene verwendet. Die Daten erstrecken sich über 5 Jahre täglicher Verkäufe in 10 Geschäften und 50 Artikeln. Dieser öffentliche Datensatz weist ein Einzelhandelsmuster mit wöchentlicher Saisonalität, Traits und Lärm auf.
Dazu habe ich Beispieldaten von 5 Filialen und 10 Artikeln verwendet und 50 separate Zeitreihen erstellt. Jede der Filialartikelkombinationen generiert ihre eigenen Sequenzen, was zu insgesamt 72.000 Trainingsbeispieldaten führt. Das Modell prognostiziert die Verkaufsdaten des nächsten Tages basierend auf der Verkaufshistorie der letzten 14 Tage, was eine übliche Konfiguration für Nachfrageprognosedaten ist.
Das Experiment wurde dreimal durchgeführt und für zuverlässige Ergebnisse gemittelt.
| Parameter | Particulars |
|---|---|
| Datensatz | Datensatz zur Bedarfsprognose für Kaggle Retailer-Artikel |
| Probe | 5 Geschäfte × 10 Artikel = 50 Zeitreihen |
| Trainingsbeispiele | ~72.000 Gesamtproben |
| Sequenzlänge | 14 Tage vergangene Daten |
| Aufgabe | Tägliche Umsatzprognose in einem Schritt |
| Metrisch | Mittlerer absoluter prozentualer Fehler (MAPE) |
| Läuft professional Modell | 3 Mal, gemittelt |
Schritt 1: Erstellen des Foundation-LSTM
Bevor wir etwas komprimieren, benötigen wir einen Referenzpunkt. Unsere Basislinie ist ein Customary-LSTM mit 64 versteckten Einheiten, die auf dem oben beschriebenen Datensatz trainiert werden.
Basiscode:
from tensorflow.keras.fashions import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
def build_lstm(models, seq_length):
"""Construct LSTM with specified hidden models."""
mannequin = Sequential((
LSTM(models, activation='tanh', input_shape=(seq_length, 1)),
Dropout(0.2),
Dense(1)
))
mannequin.compile(optimizer="adam", loss="mse")
return mannequin
# Baseline: 64 hidden models
baseline_model = build_lstm(64, seq_length=14) Grundleistung:
| Verfahren | Modell | Größe (KB) | MAPE (%) | MAPE-Customary (%) |
|---|---|---|---|---|
| Grundlinie | LSTM-64 | 66,25 | 15.92 | ±0,10 |
Das ist unser Bezugspunkt. Das LSTM-64-Modell ist 66,25 KB groß und hat einen MAPE von 15,92 %. Jede unten aufgeführte Komprimierungstechnik wird anhand dieser Zahlen gemessen.
Schritt 2: Komprimierungstechnik 1 – Architekturdimensionierung
Bei diesem Ansatz reduzieren wir die Modellkapazität um einige versteckte Einheiten. Anstelle eines LSTM mit 64 Einheiten trainieren wir ein Modell mit 32/16 Einheiten von Grund auf und sehen, wie es funktioniert. Dies ist der einfachere Ansatz unter den dreien.
Code:
# Utilizing the identical build_lstm perform from baseline
# Evaluate: 64 models (66KB) vs 32 models vs 16 models
model_32 = build_lstm(32, seq_length=14)
model_16 = build_lstm(16, seq_length=14)Ergebnisse:
| Verfahren | Modell | Größe (KB) | MAPE (%) | MAPE-Customary (%) |
|---|---|---|---|---|
| Grundlinie | LSTM-64 | 66,25 | 15.92 | ±0,10 |
| Architektur | LSTM-32 | 17.13 | 16.22 | ±0,09 |
| Architektur | LSTM-16 | 4,57 | 16.74 | ±0,46 |
Analyse: Das LSTM-16-Modell ist 14,5-mal kleiner als das 64-Bit-Modell (4,57 KB gegenüber 66,25 KB), während MAPE nur um 0,82 % erhöht wird. Bei vielen Anwendungen im Einzelhandel ist dieser Unterschied minimal, während das LSTM 32-Modell mit 3,9-facher Komprimierung und einem Genauigkeitsverlust von 0,3 % einen Mittelweg bietet.
Schritt 3: Kompressionstechnik 2 – Größenbeschneidung
Beschneidung besteht darin, Gewichte von geringer Bedeutung aus dem Modelltraining zu entfernen. Die Kernidee besteht darin, dass die Beiträge vieler neuronaler Netzwerkverbindungen minimal sind und ignoriert oder auf Null gesetzt werden können. Nach dem Beschneiden wird das Modell feinabgestimmt, um die Genauigkeit wiederherzustellen.
Code:
import numpy as np
from tensorflow.keras.optimizers import Adam
def apply_magnitude_pruning(mannequin, target_sparsity=0.5):
"""Apply per-layer magnitude pruning, skip biases"""
masks = ()
for layer in mannequin.layers:
weights = layer.get_weights()
layer_masks = ()
new_weights = ()
for w in weights:
if w.ndim == 1: # Bias - do not prune
layer_masks.append(None)
new_weights.append(w)
else: # Kernel - prune per-layer
threshold = np.percentile(np.abs(w), target_sparsity * 100)
masks = (np.abs(w) >= threshold).astype(np.float32)
layer_masks.append(masks)
new_weights.append(w * masks)
masks.append(layer_masks)
layer.set_weights(new_weights)
return masks
# After pruning, fine-tune with decrease studying charge
mannequin.compile(optimizer=Adam(learning_rate=0.0001), loss="mse")
mannequin.match(X_train, y_train, epochs=50, callbacks=(maintain_sparsity))Ergebnisse:
| Verfahren | Modell | Größe (KB) | MAPE (%) | MAPE-Customary (%) |
|---|---|---|---|---|
| Grundlinie | LSTM-64 | 66,25 | 15.92 | ±0,10 |
| Beschneidung | Beschnitten – 30 % | 11,99 | 16.04 | ±0,09 |
| Beschneidung | Beschnitten – 50 % | 8.56 | 16.20 | ±0,08 |
| Beschneidung | Beschnitten – 70 % | 5.14 | 16.84 | ±0,16 |
Analyse: Mit Magnitude Pruning bei 50 % Sparsity ist die Modellgröße auf 8,56 KB gesunken, mit nur 0,28 % Genauigkeitsverlust im Vergleich zur Basislinie. Selbst bei 70 % Beschneidung lag der MAPE unter 17 %.
Die wichtige Erkenntnis, dass das Pruning bei LSTMs funktioniert, warfare die Verwendung von Schwellenwerten auf jeder Ebene anstelle eines globalen Schwellenwerts, das Überspringen von Bias-Gewichten (wobei nur Kernel-Gewichte verwendet wurden) und auch die Verwendung einer niedrigeren Lernrate während der Feinabstimmung. Ohne diese kann sich die LSTM-Leistung aufgrund der gegenseitigen Abhängigkeit wiederkehrender Gewichtungen erheblich verschlechtern.
Schritt 4: Komprimierungstechnik 3 – INT8-Quantisierung
Bei der Quantisierung geht es um die Konvertierung von 32-Bit-Gleitkommagewichten in 8-Bit-Ganzzahlen nach dem Coaching, wodurch die Modellgröße um das Vierfache reduziert wird, ohne viel an Genauigkeit zu verlieren.
Code:
def simulate_int8_quantization(mannequin):
"""Simulate INT8 quantization on mannequin weights."""
for layer in mannequin.layers:
weights = layer.get_weights()
quantized = ()
for w in weights:
w_min, w_max = w.min(), w.max()
if w_max - w_min > 1e-10:
# Quantize to INT8 vary (0, 255)
scale = (w_max - w_min) / 255.0
zero_point = np.spherical(-w_min / scale)
w_int8 = np.spherical(w / scale + zero_point).clip(0, 255)
# Dequantize
w_quant = (w_int8 - zero_point) * scale
else:
w_quant = w
quantized.append(w_quant.astype(np.float32))
layer.set_weights(quantized)Für den Produktionseinsatz wird empfohlen, die integrierte Quantisierung von TensorFlow Lite zu verwenden:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_keras_model(mannequin)
converter.optimizations = (tf.lite.Optimize.DEFAULT)
tflite_model = converter.convert()Ergebnisse:
| Verfahren | Modell | Größe (KB) | MAPE (%) | MAPE-Customary (%) |
|---|---|---|---|---|
| Grundlinie | LSTM-64 | 66,25 | 15.92 | ±0,10 |
| Quantisierung | INT8 | 4.28 | 16.21 | ±0,22 |
Analyse: Die INT8-Quantisierung hat die Modellgröße von 66,25 KB auf 4,28 KB reduziert (15,5-fache Komprimierung) und die Genauigkeit um 0,29 % erhöht. Dies ist das kleinste Modell mit einer Genauigkeit, die mit dem unbeschnittenen LSTM 32-Modell vergleichbar ist. Speziell für Bereitstellungen wird die INT8-Inferenz unterstützt und ist die beste der drei Techniken.
Alles zusammenbringen: Direkter Vergleich
Hier sehen Sie, wie jede Technik im Vergleich zur LSTM-64-Basislinie abschneidet:
| Technik | Kompressionsverhältnis | Auswirkungen auf die Genauigkeit |
|---|---|---|
| LSTM-32 | 3,9x | +0,30 % MAP |
| LSTM-16 | 14,5x | +0,82 % MAP |
| Beschnitten – 30 % | 5,5x | +0,12 % MAP |
| Beschnitten – 50 % | 7,7x | +0,28 % MAP |
| Beschnitten – 70 % | 12,9x | +0,92 % MAP |
| INT8-Quantisierung | 15,5x | +0,29 % MAP |
Die vollständigen Benchmark-Ergebnisse für alle Techniken:
| Verfahren | Modell | Größe (KB) | MAPE (%) | MAPE-Customary (%) |
|---|---|---|---|---|
| Grundlinie | LSTM-64 | 66,25 | 15.92 | ±0,10 |
| Architektur | LSTM-32 | 17.13 | 16.22 | ±0,09 |
| Architektur | LSTM-16 | 4,57 | 16.74 | ±0,46 |
| Beschneidung | Beschnitten – 30 % | 11,99 | 16.04 | ±0,09 |
| Beschneidung | Beschnitten – 50 % | 8.56 | 16.20 | ±0,08 |
| Beschneidung | Beschnitten – 70 % | 5.14 | 16.84 | ±0,16 |
| Quantisierung | INT8 | 4.28 | 16.21 | ±0,22 |
Jede der oben genannten Techniken bringt ihre eigenen Kompromisse mit sich. Durch die Architekturdimensionierung kann die Modellgröße reduziert werden, es ist jedoch eine Neuschulung des Modells erforderlich. Durch das Beschneiden bleibt die Architektur erhalten, es werden jedoch die Verbindungen gefiltert. Die Quantisierung kann schnell erfolgen, erfordert jedoch kompatible Inferenzlaufzeiten.
Die richtige Technik wählen
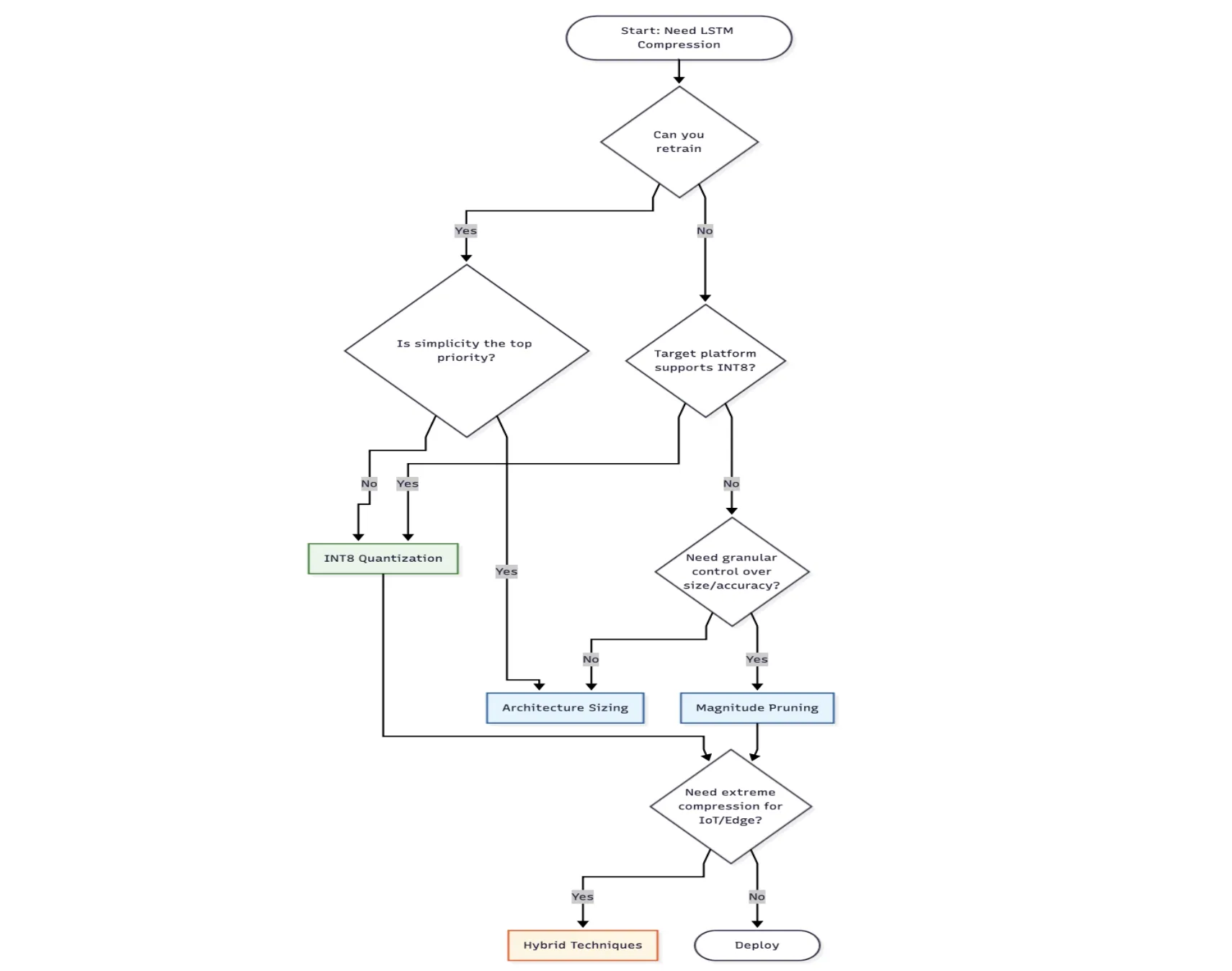
Wählen Sie Architekturdimensionierung, wenn:
- Du fängst bei Null an und kannst trainieren
- Einfachheit ist wichtiger als maximale Komprimierung
Wählen Sie Beschneiden, wenn:
- Sie haben bereits ein trainiertes Modell und suchen nach einer Modellkomprimierung
- Sie benötigen eine detaillierte Kontrolle über den Kompromiss zwischen Genauigkeit und Größe
Entscheiden Sie sich für Quantisierung, wenn:
- Sie benötigen maximale Komprimierung bei minimalem Genauigkeitsverlust
- Ihre Zielbereitstellungsplattform verfügt über eine INT8-Optimierung (Ex, Mobilgeräte, Edge-Geräte).
- Sie wollen eine schnelle Lösung ohne Umschulung von Anfang an.
Wählen Sie Hybridtechniken, wenn:
- Starke Komprimierung ist erforderlich (Edge-Bereitstellung, IoT)
- Sie können Zeit in die Iteration der Komprimierungspipeline investieren
Was Sie bei der Bereitstellung im Einzelhandel beachten sollten
Die Modellkomprimierung ist nur ein Teil des Puzzles. Bei Einzelhandelssystemen sind noch weitere Faktoren zu berücksichtigen, wie unten aufgeführt.
- Ein größeres Modell ist immer besser als ein kleineres Modell, das veraltet ist. Bauen Sie Umschulungen in Ihre Pipeline ein, wenn sich die Einzelhandelsmuster je nach Saison, Traits, Werbeaktionen usw. ändern.
- Benchmarks von einem lokalen Laptop können nicht mit einem Gerät in der Produktionsumgebung abgeglichen werden. Insbesondere können sich die quantisierten Modelle auf verschiedenen Plattformen unterschiedlich verhalten.
- Die Überwachung ist ein Schlüsselelement in der Produktion, da die Komprimierung zu einer geringfügigen Verschlechterung der Genauigkeit führen kann. Alle erforderlichen Alarme und Paging-Funktionen müssen vorhanden sein.
- Berücksichtigen Sie immer die gesamten Systemkosten, da ein 4-KB-Modell, das eine spezielle Runtime mit geringer Dichte erfordert, möglicherweise mehr kostet als die Bereitstellung eines regulären 17-KB-Modells, das überall läuft.
Abschluss
Zusammenfassend lässt sich sagen, dass alle drei Komprimierungstechniken zu erheblichen Größenreduzierungen bei gleichzeitiger Beibehaltung der richtigen Genauigkeit führen können.
Dimensionierung der Architektur ist die einfachste unter drei. Ein LSTM-16 liefert eine 14,5-fache Komprimierung mit weniger als 1 % Genauigkeitsverlust.
Beschneidung bietet mehr Kontrolle. Bei ordnungsgemäßer Ausführung (Schwellenwerte professional Schicht, Überspringungsverzerrungen, Feinabstimmung bei niedriger Lernrate) wird durch 70-prozentiges Bereinigen eine 12,9-fache Komprimierung erreicht.
INT8-Quantisierung erreicht den besten Kompromiss mit 15,5-facher Komprimierung bei nur 0,29 % Steigerung der Genauigkeit.
Die Wahl der besten Technik hängt von Ihren Einschränkungen und Einschränkungen ab. Wenn eine einfache Lösung benötigt wird, beginnen Sie mit der Dimensionierung der Architektur. Wenn Sie ein maximales Maß an Komprimierung bei minimalem Genauigkeitsverlust benötigen, entscheiden Sie sich für Quantisierung. Wählen Sie das Beschneiden hauptsächlich dann, wenn Sie eine detaillierte Kontrolle über den Komprimierungsgenauigkeitskompromiss benötigen.
Bei Edge-Bereitstellungen, die die Geräte, Tablets, Regalsensoren oder Scanner im Geschäft unterstützen, kann die Modellgröße (4 KB vs. 66 KB) bestimmen, ob Ihre KI läuft lokal auf dem Gerät oder erfordern eine kontinuierliche Cloud-Konnektivität.
Ravi Teja Pagidoju ist ein leitender Ingenieur mit mehr als 9 Jahren Erfahrung
Aufbau von KI/ML-Systemen zur Optimierung des Einzelhandels und der Lieferkette. Er hat einen MS in Informatik und hat Forschungsergebnisse zu hybriden LLM-Optimierungsansätzen in IEEE- und Springer-Publikationen veröffentlicht.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.