Zu verstehen, was in einem Audioclip passiert, ist ein täuschend schwieriges Drawback. Das Transkribieren gesprochener Wörter ist der einfache Teil. Ein wirklich leistungsfähiges System muss außerdem erkennen, wer spricht, seinen emotionalen Zustand erkennen, Hintergrundgeräusche interpretieren, Musikinhalte analysieren und zeitbezogene Fragen wie „Was hat der Sprecher nach zwei Minuten gesagt?“ beantworten. Um all das zu bewältigen, mussten mehrere spezialisierte Systeme zusammengefügt werden.
Das OpenMOSS-Group, MOSI.AI und das Shanghai Innovation Institute veröffentlicht MOSS-Audio: ein Open-Supply-Audio-Verständnismodell, das alle diese Funktionen in einem einzigen Basismodell vereinen soll.
Was MOSS-Audio tatsächlich macht
MOSS-Audio unterstützt Sprachverständnis, Verständnis von Umgebungsgeräuschen, Musikverständnis, Audiountertitelung, zeitbewusste Qualitätssicherung und komplexes Denken über reales Audio. Sein Leistungsumfang gliedert sich in mehrere unterschiedliche Bereiche. Sprach- und Inhaltsverständnis Erkennt und transkribiert gesprochene Inhalte präzise und unterstützt die Zeitstempelausrichtung sowohl auf Wort- als auch auf Satzebene. Sprecher-, Feelings- und Ereignisanalyse identifiziert Sprechereigenschaften, analysiert emotionale Zustände anhand von Ton, Klangfarbe und Kontext und erkennt wichtige akustische Ereignisse im Audio. Szenen- und Sound-Cue-Extraktion zieht aussagekräftige Signale aus Hintergrundgeräuschen, Umgebungsgeräuschen und Nicht-Sprachsignalen, um auf Szenenkontext und Atmosphäre zu schließen. Musikverständnis analysiert Musikstil, emotionale Entwicklung und Instrumentierung. Beantwortung und Zusammenfassung von Audiofragen Beantwortet Fragen und Zusammenfassungen in Reden, Podcasts, Besprechungen und Interviews. Endlich, Komplexes Denken führt Multi-Hop-Argumentation über Audioinhalte durch, unterstützt durch Gedankenkettentraining und verstärkendes Lernen.
In der Praxis kann ein einziges MOSS-Audio-Modell alle oben genannten Aufgaben erfüllen, ohne zwischen verschiedenen Spezialsystemen wechseln zu müssen.
Vier Modellvarianten
Das Group veröffentlichte zum Begin vier Varianten: MOSS-Audio-4B-Anleitung, MOSS-Audio-4B-Denken, MOSS-Audio-8B-AnleitungUnd MOSS-Audio-8B-Denken. Es lohnt sich, die Namenskonvention zu verstehen, wenn Sie entscheiden, welche verwendet werden soll. Der Anweisen Varianten sind für die direkte Befolgung von Anweisungen optimiert und eignen sich daher intestine für Produktionspipelines, in denen Sie vorhersehbare, strukturierte Ausgaben wünschen. Der Denken Varianten bieten stärkere Denkkettenfähigkeiten und eignen sich besser für Aufgaben, die Multi-Hop-Inferenz erfordern. Die 4B-Modelle verwenden Qwen3-4B als LLM-Spine und die 8B-Modelle nutzen Qwen3-8BDies führt zu Gesamtmodellgrößen von etwa 4,6 B bzw. 8,6 B Parametern.
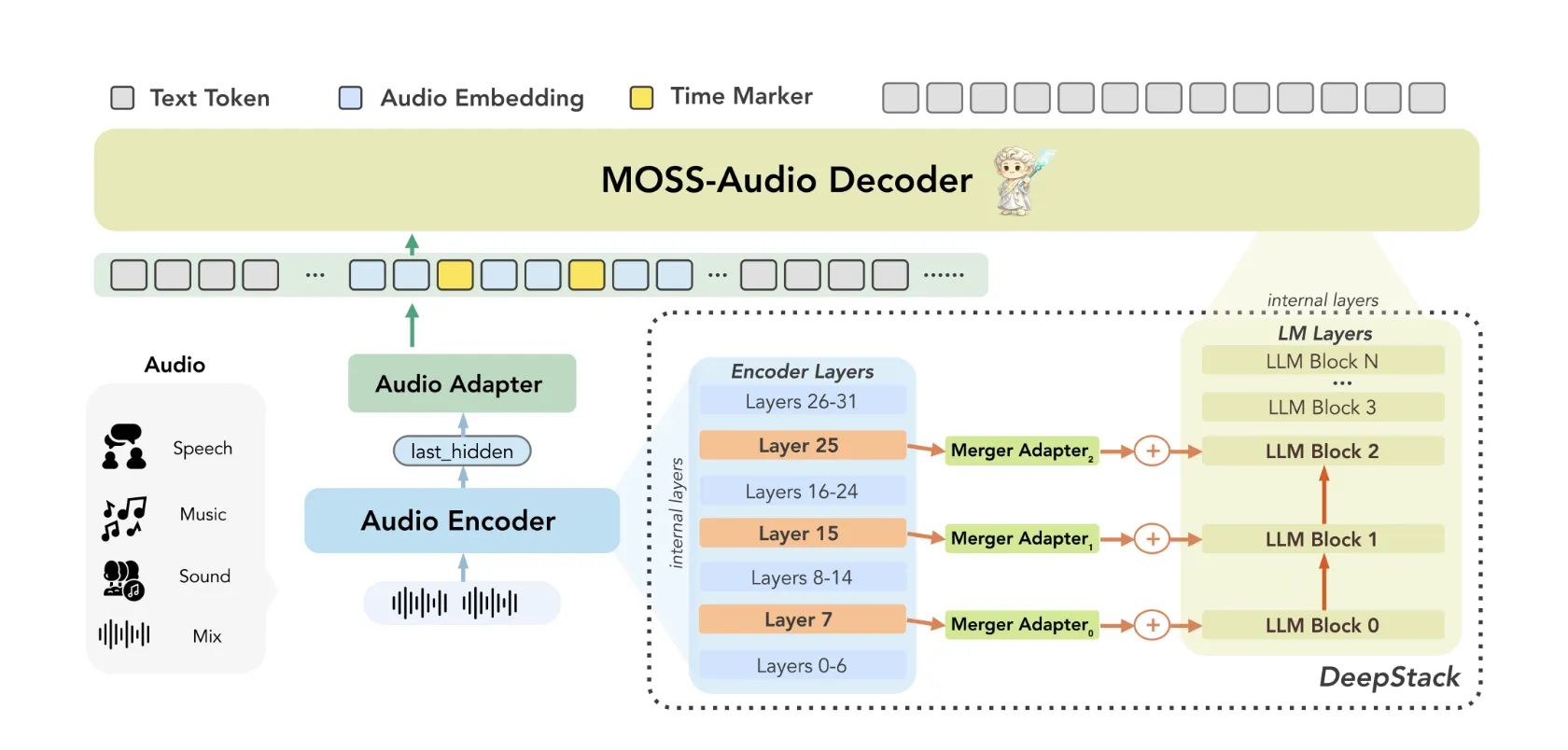
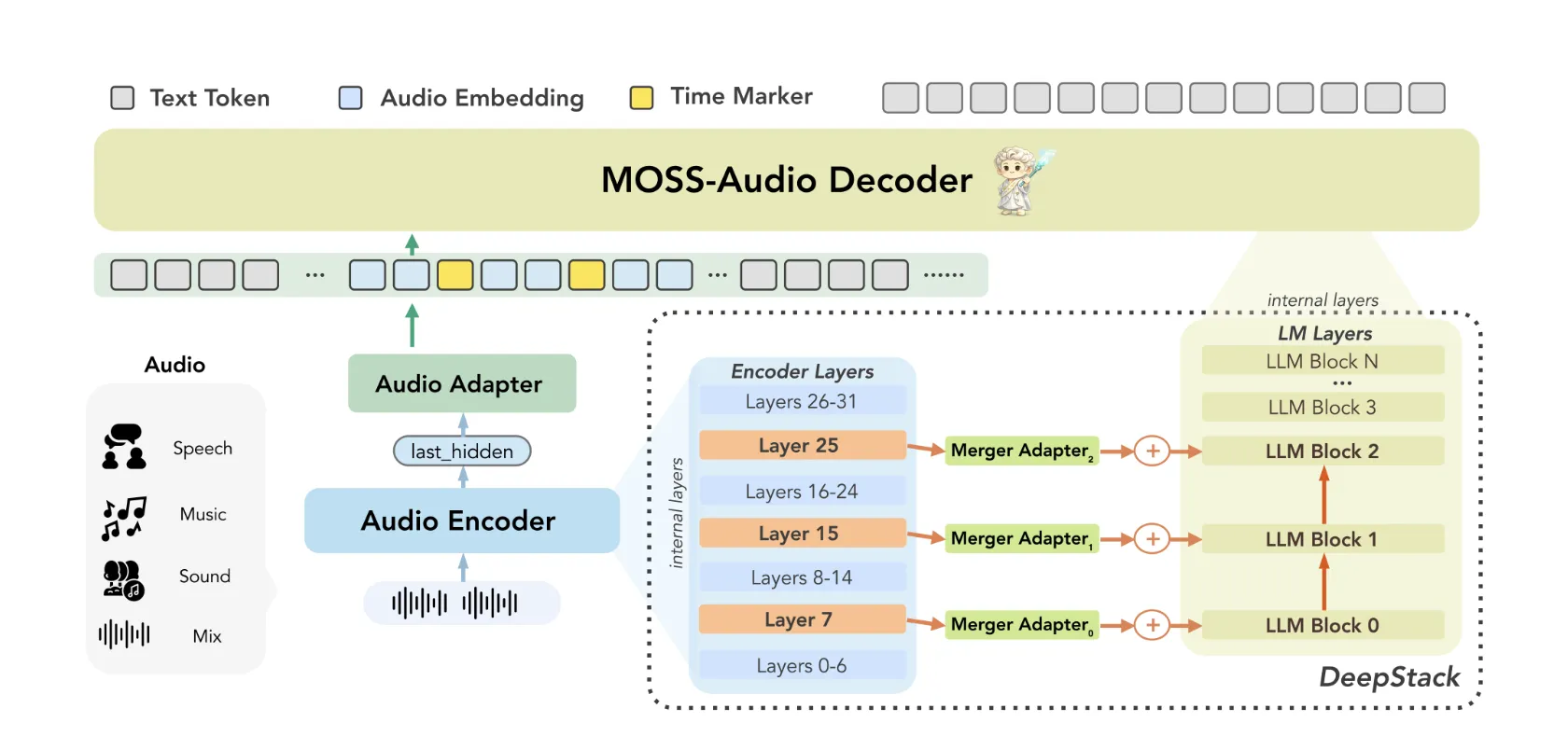
Die Architektur: Drei Komponenten arbeiten zusammen
MOSS-Audio folgt a Modularer Aufbau bestehend aus drei Komponenten: einem Audio-Encoder, einem Modalitätsadapter und einem großen Sprachmodell. Rohes Audio wird zunächst von kodiert MOSS-Audio-Encoder in kontinuierliche zeitliche Darstellungen um 12,5 Hz. Diese Darstellungen werden dann über den Adapter in den Einbettungsraum des Sprachmodells projiziert und schließlich vom LLM zur automatischen Regressionstextgenerierung verwendet.
Das Forschungsteam trainierte den Encoder von Grund auf, anstatt sich auf handelsübliche Audio-Frontends zu verlassen. Ihre Begründung: Ein dedizierter Encoder liefert robustere Sprachdarstellungen, eine engere zeitliche Ausrichtung und eine bessere Erweiterbarkeit über akustische Bereiche hinweg.
Zwei architektonische Neuerungen in MOSS-Audio sind es wert, im Element verstanden zu werden.
DeepStack Cross-Layer-Function-Injection: Eine häufige Schwäche von Audiomodellen besteht darin, dass es dazu kommt, dass akustische Informationen auf niedriger Ebene verloren gehen, beispielsweise Prosodie, transiente Ereignisse und lokale Zeit-Frequenz-Strukturen, wenn man sich nur auf die Funktionen der obersten Ebene des Encoders verlässt. MOSS-Audio begegnet diesem Drawback mit einem DeepStack-inspiriertes schichtübergreifendes Injektionsmodul zwischen dem Encoder und dem Sprachmodell: Zusätzlich zur Endschichtausgabe des Encoders werden Merkmale aus früheren und Zwischenschichten ausgewählt, unabhängig projiziert und in die frühen Schichten des Sprachmodells injiziert. Dadurch bleiben Multigranularitätsinformationen erhalten, die von akustischen Particulars auf niedriger Ebene bis hin zu semantischen Abstraktionen auf hoher Ebene reichen, und helfen dem Modell, Rhythmus, Klangfarbe, Transienten und Hintergrundstruktur beizubehalten, die eine einzelne Darstellung auf hoher Ebene nicht vollständig erfassen kann.
Zeitbewusste Darstellung: Zeit ist eine kritische Dimension im Audiobereich, für die Textmodelle von Natur aus nicht gerüstet sind. MOSS-Audio begegnet diesem Drawback durch a Einfügen von Zeitmarken Strategie während des Vortrainings: In festen Zeitintervallen werden explizite Zeittoken zwischen Audio-Body-Darstellungen eingefügt, um zeitliche Positionen anzuzeigen. Dadurch kann das Modell lernen, „was wann passiert ist“ innerhalb eines einheitlichen Textgenerierungsrahmens, der natürlich Zeitstempel-ASR, Ereignislokalisierung, zeitbasierte Qualitätssicherung und lange Audiorückblicke unterstützt – ohne dass ein separater Lokalisierungskopf oder eine Nachbearbeitungspipeline erforderlich ist.
Benchmark-Leistung
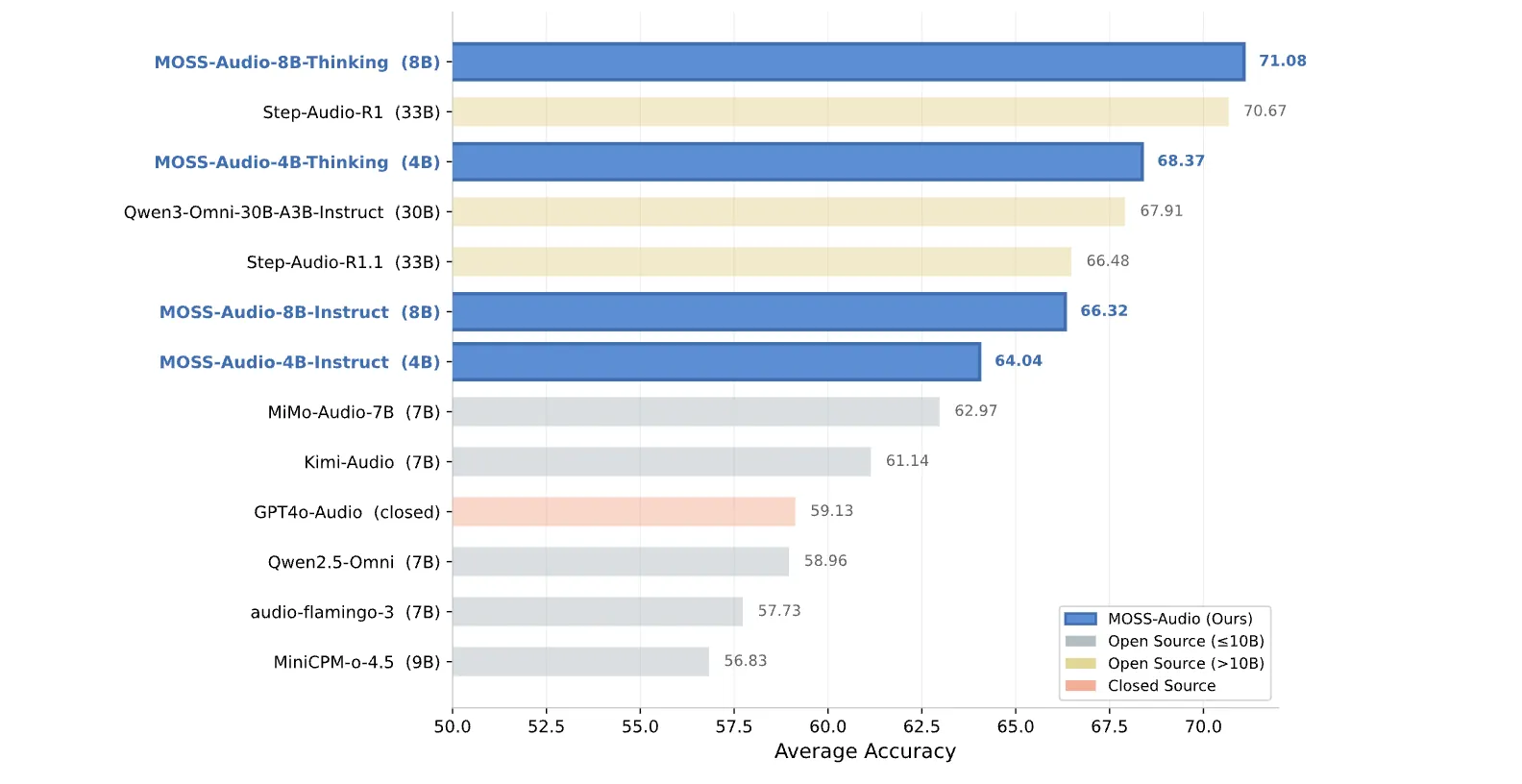
Die Zahlen sind stark. Zum allgemeinen Audioverständnis: MOSS-Audio-8B-Pondering erreicht eine durchschnittliche Genauigkeit von 71,08 über vier Benchmarks hinweg – 77,33 auf MMAU, 64,92 auf MMAU-Professional, 66,53 auf MMARUnd 75,52 auf MMSUübertrifft die meisten Open-Supply-Modelle. Dazu gehören auch größere Modelle: Step-Audio-R1 mit 33B erreicht 70,67 Punkte und Qwen3-Omni-30B-A3B-Instruct mit 30B Punkte 67,91. Im weiteren Kontext erzielt Kimi-Audio (7B) einen Wert von 61,14 und MiMo-Audio-7B einen Wert von 62,97 im gleichen Durchschnitt. Die 4B-Pondering-Variante erzielt einen Wert von 68,37, was bedeutet, dass das kleinere Modell mit Gedankenkettentraining alle größeren Open-Supply-Konkurrenten, die nur Instruktionen anbieten, übertrifft.
An Untertitel der Redebewertet mit einer LLM-as-a-Choose-Methodik in 13 feinkörnigen Dimensionen, darunter Geschlecht, Alter, Akzent, Tonhöhe, Lautstärke, Geschwindigkeit, Textur, Klarheit, Geläufigkeit, Emotion, Ton, Persönlichkeit und Zusammenfassung. MOSS-Audio-Instruct-Varianten führen in 11 von 13 Dimensionen, wobei MOSS-Audio-8B-Instruct die beste durchschnittliche Gesamtpunktzahl erreicht 3.7252.
An Automatische Spracherkennung (ASR) MOSS-Audio-8B-Instruct umfasst 12 Bewertungsdimensionen – darunter Gesundheitszustand, Codewechsel, Dialekt, Gesang und Nicht-Sprachszenarien – und erreicht dies niedrigste Gesamt-CER (Character Error Charge) von 11,30 über alle getesteten Modelle hinweg.
Wichtige Erkenntnisse
- Einzelmodell, vollständiger Audio-Stack: MOSS-Audio vereint Sprachtranskription, Sprecher- und Emotionsanalyse, Verständnis von Umgebungsgeräuschen, Musikanalyse, Audiountertitelung, zeitbewusste Qualitätssicherung und komplexe Argumentation in einem Open-Supply-Modell, wodurch die Notwendigkeit entfällt, mehrere spezialisierte Systeme miteinander zu verketten.
- Zwei architektonische Innovationen steigern die Leistung: DeepStack Cross-Layer Function Injection bewahrt akustische Multigranularitätsinformationen durch die direkte Injektion von Options aus Zwischen-Encoderschichten in die frühen Schichten des LLM, während das Einfügen von Zeitmarkern während des Vortrainings dem Modell explizite zeitliche Aufmerksamkeit für zeitstempelbasierte Aufgaben verleiht.
- Erstklassige Benchmark-Ergebnisse im effizienten Maßstab: MOSS-Audio-8B-Pondering erreicht eine durchschnittliche Genauigkeit von 71,08 bei allgemeinen Audio-Verständnis-Benchmarks und übertrifft damit alle Open-Supply-Modelle, einschließlich 30B+-Systeme, während die 4B Pondering-Variante allein jeden größeren Open-Supply-Nur-Anleitungs-Konkurrenten übertrifft.
- Dominante Zeitstempel-ASR-Genauigkeit: MOSS-Audio-8B-Instruct erreicht 35,77 AAS bei AISHELL-1 und 131,61 AAS bei LibriSpeech und übertrifft damit sowohl Qwen3-Omni-30B-A3B-Instruct (833,66) als auch das Closed-Supply-Gerät Gemini-3.1-Professional (708,24) bei demselben Benchmark deutlich.
Schauen Sie sich das an Modellgewichte Und Repo. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 130.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Möchten Sie mit uns zusammenarbeiten, um Ihr GitHub-Repo ODER Ihre Hugging Face Web page ODER Produktveröffentlichung ODER Ihr Webinar usw. zu bewerben?Vernetzen Sie sich mit uns
Der Beitrag OpenMOSS veröffentlicht MOSS-Audio: ein Open-Supply-Grundlagenmodell für Sprache, Ton, Musik und zeitbewusstes Audio-Denken erschien zuerst auf MarkTechPost.