
Ein egozentrischer Datensatz ist eine strukturierte Sammlung von Video- und Sensoraufzeichnungen aus der ersten Particular person – aufgenommen von einer Kopf-, Brust- oder Handgelenkkamera – und wird verwendet, um Robotik und verkörperte KI-Systeme darauf zu trainieren, wie Menschen sehen, sich bewegen und handeln. Es entspricht am ehesten dem, was die Bordkamera eines Roboters während des Betriebs sieht, weshalb es zu einer Grundlage für das Coaching von Imaginative and prescient-Language-Motion-Modellen (VLA) geworden ist.
Ein Roboter, der nur auf Laboraufnahmen trainiert wird, stürzt häufig am ersten Tag ab, an dem er das Labor verlässt. Der Grund liegt selten im Modell. Es sind die Daten.
Die meisten Schulungsvideos werden mit einem Stativ oder einer Deckenkamera aufgenommen. Solche Aufnahmen zeigen den Raum, aber nicht die Arbeit. Nicht die Hand. Nicht das Objekt. Nicht der genaue Winkel, den die Bordkamera eines Roboters sieht, wenn er tatsächlich eine Tasse aufnimmt oder eine Schublade öffnet. Um diese Lücke zu schließen, wurde ein egozentrischer Datensatz erstellt.
In diesem Leitfaden erfahren Sie, was ein egozentrischer Datensatz ist, warum First-Particular person-Daten zur Grundlage moderner Robotik und verkörperter KI geworden sind, wie gute Daten tatsächlich aussehen und worauf Groups achten sollten, bevor sie einen solchen lizenzieren oder in Auftrag geben.
Was ist ein egozentrischer Datensatz?
Ein egozentrischer Datensatz ist eine strukturierte Sammlung von Video- und Sensordaten, die aus der Ich-Perspektive erfasst werden. Die Kamera sitzt auf dem Kopf, der Brust oder dem Handgelenk der Particular person, die eine Aufgabe ausführt – manchmal auch auf dem Roboter selbst –, sodass die Aufnahme die Welt genau so zeigt, wie der Schauspieler sie sieht.
„Egozentrisch“ bedeutet einfach vom Selbst. Eine Third-Particular person-Kamera zeigt, was in einem Raum passiert. Eine egozentrische Kamera zeigt, was die Hände, Augen und Werkzeuge des Schauspielers tun, während es passiert. Dieser Unterschied klingt gering. Für Robotikteams ist es alles.
Die meisten modernen egozentrischen Datensätze kombinieren Video mit zusätzlichen Signalen – Tiefe, Bewegung, Audio und manchmal Augen- oder Handverfolgung –, sodass ein einzelner Second aus mehreren Blickwinkeln gleichzeitig untersucht werden kann.
Warum egozentrische Daten für Robotik und verkörperte KI wichtig sind

Roboter versagen in der realen Welt aus einer kleinen Liste von Gründen. Der falsche Standpunkt sitzt oben.
Die Bordkamera eines Roboters sieht die Welt von dort aus, wo der Roboter steht. Wenn Sie es mit Overhead- oder Seitenwinkelvideos trainieren, muss das Modell bei jeder Aktion eine Lücke schließen und eine Szene aus der dritten Particular person in eine Entscheidung aus der ersten Particular person übersetzen. In dieser Lücke passieren Fehler: ein falscher Griff, ein verpasster Kontaktpunkt, eine Hand, die einen Schlag zu früh schließt.
Durch Schulungen zu First-Particular person-Daten entfällt dieser Übersetzungsschritt. Das Modell lernt aus derselben Ansicht, die es später verwenden wird. Jüngste Forschungen zum Roboterlernen haben gezeigt, dass Richtlinien, die auf Daten aus der ersten Particular person trainiert werden, bei Manipulationsaufgaben je nach Aufgabentyp die von Dritten trainierten Richtlinien um 15–30 % übertreffen können. Der Gewinn zeigt sich in der Arbeit selbst: sauberere Griffe, besseres Hand-Auge-Timing, intelligentere Reaktionen auf Unordnung und Teilansichten.
Aus diesem Grund stehen auch First-Particular person-Daten im Mittelpunkt Physische KI Systeme und die neue Welle von Imaginative and prescient-Sprach-Aktionsmodelle – Systeme, die eine visuelle Eingabe und eine gesprochene oder schriftliche Anweisung entgegennehmen und dann eine reale Aktion in der physischen Welt ausgeben.
In einem hochwertigen egozentrischen Datensatz
Rohvideo allein reicht nicht aus. Eine qualitativ hochwertige egozentrische Datenerfassung kombiniert Ego-Movies mit mehreren anderen Signalen:
- Synchronisiertes Video in guter Auflösung, oft aus mehr als einem Winkel (Kopf, Brust oder Handgelenk)
- Tiefendaten Dies hilft einem Modell zu verstehen, wie weit ein Objekt entfernt ist und nicht nur, wo es im Bild erscheint
- Daten des Bewegungssensors (IMU). das Kopf- und Körperbewegungen Bild für Bild verfolgt
- Audio – das überraschend viel Kontext enthält, wie ein Messer auf einem Brett oder eine Particular person, die in der Nähe spricht
- Hand- oder Augenverfolgung Für Aufgaben, bei denen Aufmerksamkeit und Griffigkeit wichtig sind
Der Haken an der Sache ist, dass das alles auf die Millisekunde genau sein muss. Wenn der Tiefenstrom eine Viertelsekunde hinter dem Video zurückbleibt, lernt das Modell die falsche Ursache und Wirkung. Solider Egozentriker Datenanmerkung Zusätzlich zu einer intestine kalibrierten Erfassung werden Rohaufzeichnungen in Trainingsdaten umgewandelt.
Laboraufnahmen vs. Aufnahmen aus der realen Welt
Es hilft, sich ein anderes Trainingsproblem vorzustellen.
Stellen Sie sich vor, Sie bringen jemandem das Fahrradfahren bei, indem Sie ihm nur Drohnenaufnahmen vorspielen, die von oben aufgenommen wurden. Sie würden das Fahrrad, die Straße und den Weg sehen. Sie würden das Wackeln des Lenkers, die Artwork und Weise, wie die Augen in Kurven nach vorne blicken, oder die Artwork und Weise, wie sich die Karosserie vor einer Kurve bewegt, nicht bemerken. Sie würden technisch gesehen wissen, was Radfahren ist sieht aus wie. Sie würden nicht wissen, wie es geht Tun Es.
Bei Labordaten tritt im großen Maßstab das gleiche Downside auf. Saubere Beleuchtung, ein Objekt auf einem sauberen Tisch, eine Aufgabe professional Clip – es ist aufgeräumt, aber es ist nicht die Welt, in die ein Roboter eindringt. Modelle, die anhand von Laboraufnahmen trainiert wurden, funktionieren oft am ersten Tag und scheitern am dreißigsten Tag, wenn das Licht flackert, sich die Wege zweier Personen kreuzen oder drei Artikel auf demselben Regal stehen.
Die egozentrische Erfassung in der realen Welt bringt den Lärm wieder ins Spiel. Dieser Lärm sorgt dafür, dass Modelle nach dem Einsatz standhalten.
Die vier Schichten eines egozentrischen Datensatzstapels
Unterschiedliche Probleme erfordern unterschiedliche Datenschichten. Ein für einen Auftrag erstellter Datensatz deckt selten einen anderen Brunnen ab. Hier ist eine einfache Möglichkeit, sich die Schichten vorzustellen, die die meisten physischen KI-Groups stapeln, um einen vollständigen verkörperten KI-Datensatz zu erstellen:
Die meisten Produktionsteams greifen auf mehr als eine Ebene zurück. Ein Humanoid, der beispielsweise eine Spülmaschine beladen muss, greift auf mindestens drei Dinge zurück: menschliche Demonstrationen, feine Manipulation und eine schrittweise Aufgabenstruktur.
Wo egozentrische Daten die echte Nachfrage antreiben

Stellen Sie sich ein mittelgroßes Lager vor, in dem im letzten Quartal ein Choose-and-Place-Roboter eingeführt wurde. Anhand sauberer Laboraufnahmen hat es in der ersten Woche gepasst. Dann kam es zu einem saisonalen Anstieg. In seltsamen Winkeln gestapelte Kisten, flackerndes Neonlicht, zwei Arbeiter überqueren den Gang. Der Roboter geriet ins Stocken – nicht weil das Modell kaputt ging, sondern weil nichts in seinem Coaching wie eine echte Veränderung aussah.
Diese Artwork von Lücke zeigt sich branchenübergreifend und ist der Grund dafür, dass die Nachfrage nach First-Particular person-Trainingsdaten an bestimmten Stellen steigt:
- Humanoide und Heimroboter. Kochen, putzen, Lebensmittel einräumen. Aufgaben, die einfach aussehen, bis Sie einem Roboter dabei zusehen, wie er sie ausführt.
- Autonome Mobilität. Fahren, Verhalten in der Kabine, Zustellung auf der letzten Meile. Die First-Particular person-Erfassung schließt die Lücke zwischen Simulation und realen Straßen.
- Industrielle egozentrische Datensätze. Fabrikhallen, Montagelinien, Öl- und Gasstandorte – werden zum Trainieren von Sicherheitserkennung, ergonomischer Nachverfolgung und arbeiterunterstützender Robotik verwendet.
- Chirurgische Videodaten aus der ersten Particular person. Erfassung von Eingriffen mithilfe von am Kopf montierten Kameras, die von Chirurgen getragen werden und zum Trainieren von Assistenzmodellen und medizinischen AR-Systemen verwendet werden.
- Egozentrische Daten zum Verbraucherverhalten im Einzelhandel. Tragbare Aufnahmen von Käufern in echten Geschäften, mit denen Aufmerksamkeit, Navigation und Entscheidungsfindung am Regal untersucht werden.
Unterschiedliche Branchen, das gleiche Grundbedürfnis: Daten, die wie Arbeit aussehen, nicht wie das Labor.
Was macht einen egozentrischen Datensatz modellreif?
Unabhängig davon, ob Sie intern bauen oder egozentrische Datenanbieter bewerten, fünf Dinge unterscheiden forschungsfähige Daten von Daten, die in der Produktion Bestand haben:
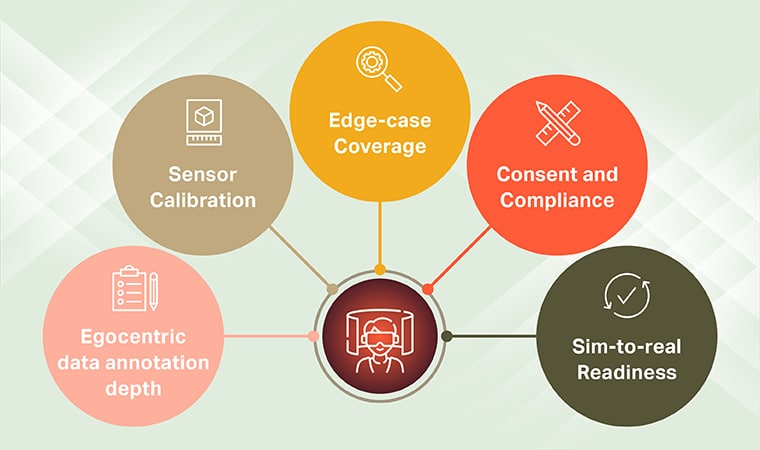
- Egozentrische Datenannotationstiefe. Nicht nur Begrenzungsrahmen. Handhaltungen, Objektzustände, Handlungsschritte und Absichten – alles auf den richtigen Rahmen ausgerichtet.
- Sensorkalibrierung. Zeitsynchronisierung von Video, Tiefe, Audio und Bewegung, sodass das Modell einen kohärenten Second sieht und nicht fünf fließende Ströme.
- Edge-Case-Abdeckung. Schwaches Licht, Verdunkelung, überfüllte Szenen, seltene Ereignisse. Die Fälle, in denen Labordaten stillschweigend Lücken hinterlassen. In Käuferbefragungen aus der Industrie werden die Annotationsqualität und die Randfallabdeckung durchweg als die beiden wichtigsten Kriterien bei der Bewertung von Datenpartnern eingestuft.
- Einwilligung und Compliance. First-Particular person-Movies sind per Definition sensibel. Für Datensätze ist eine dokumentierte Einwilligung der Teilnehmer, ggf. eine Anonymisierung erforderlich und eine Übereinstimmung mit Rahmenwerken wie DSGVO und HIPAA erforderlich. Anbieterkontrollen wie ISO 27001 und SOC 2 Typ II fügen die verfahrenstechnische Ebene hinzu, die Rechtsteams von Unternehmen erwarten.
- Sim-to-Actual-Bereitschaft. Reales Filmmaterial, das sauber mit synthetischen Daten kombiniert wird, sodass Groups das Coaching skalieren können, ohne die Grundlagen zu verlieren, die Modelle zuverlässig machen.
Qualität Datenerfassung ist der Teil, der später am schwierigsten zu reparieren ist. Wenn Sie es direkt an der Quelle angehen, wird der Relaxation der Pipeline einfacher.
Wichtige Erkenntnisse
- Ein egozentrischer Datensatz besteht aus First-Particular person-Video- und Sensordaten – aus der Sicht des Schauspielers aufgenommen – wird dazu verwendet, Robotik und verkörperte KI-Modelle so zu trainieren, wie sie die Welt im Einsatz tatsächlich sehen werden.
- First-Particular person-Daten schließen die Wahrnehmungs-Handlungs-Lücke Das führt dazu, dass im Labor trainierte Roboter in realen Schichten versagen.
- Hochwertige egozentrische Daten sind multimodal – Video, Tiefe, Audio, Bewegung und Monitoring – auf die Millisekunde genau synchronisiert.
- Produktionsbereit bedeutet mehr als nur Annotation – es bedeutet Randfallabdeckung, reale Umgebungen, Sim-to-Actual-Bereitschaft und einen dokumentierten Compliance-Path.
Wie Shaip helfen kann
Wenn Ihr Crew die Section „Brauchen wir egozentrische Daten?“ hinter sich gelassen hat und sich mit der Frage „Wie bekommen wir sie eigentlich?“ befasst, ist Shaip genau das Richtige für Sie.
Wir betreiben die gesamte Datenpipeline hinter physischen KI-Programmen – First-Particular person-Erfassung in realen Umgebungen, VLA-Annotation, synthetische Daten, RLHF und Bewertungsbenchmarks im Rahmen eines Auftrags. Ein paar Besonderheiten:
- Aufnahmen aus der realen Welt, keine Laboraufnahmen. Am Kopf montierte Kameras, Datenbrillen und Wearables in Küchen, Lagerhäusern, Fabriken, Gesundheitseinrichtungen und Geschäften.
- Multisensor-Synchronisation. Video, IMU, LiDAR, Audio und Tiefe – auf die Millisekunde genau kalibriert und zeitlich ausgerichtet.
- Für das VLA-Coaching erstellte Anmerkung. Objekte, Aktionen, Hand-Objekt-Interaktionen, Absicht und räumlicher Kontext.
- Sim-to-Actual-Unterstützung. Synthetische Erzeugung und Real2Sim-Pipelines, die die Abdeckung erweitern, ohne die reale Erdung zu verlieren.
- Compliance vom ersten Tag an. ISO 27001, SOC 2 Typ II, HIPAA-bereit und DSGVO – mit Einwilligung-zuerst-Erhebung und revisionssicherer Datenherkunft.
Wenn dies die Richtung Ihres physischen KI-Programms widerspiegelt, würden wir gerne einen Pilotversuch planen.
Abschluss
Ein egozentrischer Datensatz ist nicht nur ein Ego-Video. Dabei handelt es sich um eine strukturierte Methode, Maschinen beizubringen, so zu sehen und zu handeln, wie Menschen es tun. Für Robotik- und verkörperte KI-Groups ist es der Unterschied zwischen einem Modell, das sich intestine demonstrieren lässt, und einem Modell, das ausgeliefert werden kann. Unabhängig davon, ob das Ziel Humanoide, Autonomie oder intelligente Fabriken sind, werden egozentrische Daten für die Robotik- und KI-Entwicklung zu einer Kernschicht jeder ernsthaften verkörperten KI-Datensatzstrategie – und nicht zu einer optionalen. Die Groups, die es richtig machen, sind diejenigen, die Daten – Sammlung, Annotation, Validierung und Compliance – als Kernbestandteil des Techniques und nicht als einen Schritt davor behandeln.