Der Aufbau eines RAG-Programs ist jetzt viel einfacher. Das Dateisuchtool von Google für die Gemini-API übernimmt jetzt die schwere Arbeit, LLMs mit Ihren Daten zu verbinden. Chunking, Einbettung und Indizierung werden für Sie erledigt. Und mit dem neuesten Replace ist es multimodal geworden. Sie können jetzt sowohl Textual content als auch Bilder in einer einzigen Pipeline durchsuchen, mit integrierter benutzerdefinierter Metadatenfilterung und Zitaten auf Seitenebene. In diesem Leitfaden erklären wir Ihnen, wie die Dateisuche funktioniert, und implementieren sie anhand praktischer Beispiele.
Was bewirkt die Dateisuche?
Mit der Dateisuche kann Gemini auf Informationen aus Ihren Datenquellen wie Berichten, Dokumenten, Forschungsarbeiten, Code und privaten Wissensdatenbanken zugreifen und diese nutzen.
Wenn Sie eine Datei hochladen, zerlegt Gemini sie in kleinere Teile, sogenannte „Chunks“, und erstellt Einbettungen für diese. Bei diesen Einbettungen handelt es sich um numerische Darstellungen, die die Bedeutung des Inhalts erfassen und Zwillingen helfen, den Kontext zu verstehen. Anschließend werden sie zum einfachen Abrufen in einem Dateisuchspeicher gespeichert.
Wenn Sie eine Frage stellen, durchsucht Gemini die gespeicherten Einbettungen nach den relevantesten Teilen und verwendet sie als Kontext, um Antworten zu generieren. Dies ist die Essenz der Retrieval Augmented Technology (RAG).
Gemini File Search geht über den reinen Textual content hinaus. Es unterstützt auch multimodales RAG, sodass Textual content und Bilder gemeinsam indiziert und durchsucht werden können. Das bedeutet, dass Sie mithilfe natürlichsprachlicher Abfragen Informationen aus PDFs, Bildern, Diagrammen, Screenshots und mehr abrufen können.
Für multimodale Aufgaben verwendet Gemini Zwillinge-Einbettung-2 für Bild- und multimodale Einbettungen, whereas gemini-embedding-001 kümmert sich um Texteinbettungen. Beachten Sie, dass Audio- und Videoformate noch nicht unterstützt werden.
Lesen Sie auch: Erstellen eines LLM-Modells mit der Google Gemini API
Wie funktioniert die Dateisuche?
Die Dateisuche basiert auf der semantischen Vektorsuche. Anstatt Wörter direkt zuzuordnen, werden Informationen basierend auf Bedeutung und Kontext gefunden. Dies bedeutet, dass die Dateisuche relevante Informationen für Sie finden kann, selbst wenn der Wortlaut der Suchanfrage unterschiedlich ist.
Benötigte Zeit: 4 Minuten
So funktioniert es Schritt für Schritt:
- Laden Sie eine Datei hoch
Die Datei wird in kleinere Abschnitte unterteilt, die als „Chunks“ bezeichnet werden.
- Einbettungsgenerierung
Jeder Block würde in einen numerischen Vektor umgewandelt, der die Bedeutung dieses Blocks darstellt.
- Lagerung
Die Einbettungen werden in einem File Search Retailer gespeichert, einem eingebetteten Speicher, der speziell für den Abruf entwickelt wurde.
- Abfrage
Wenn ein Benutzer eine Frage stellt, wandelt File Search diese Frage in eine Einbettung um.
- Abruf
Der Abrufschritt vergleicht die Einbettung der Frage mit den gespeicherten Einbettungen und findet heraus, welche Blöcke am ähnlichsten sind (falls vorhanden).
- Erdung
Der Eingabeaufforderung des Gemini-Modells werden relevante Teile hinzugefügt, sodass die Antwort auf den Sachdaten aus den Dokumenten basiert.
Dieser gesamte Prozess wird über die Gemini-API abgewickelt. Der Entwickler muss keine zusätzliche Infrastruktur oder Datenbanken verwalten.
Setup-Anforderungen
Um das Dateisuchtool nutzen zu können, benötigen Entwickler einige grundlegende Komponenten. Sie benötigen Python 3.9 oder höher, die Google-Genai-Clientbibliothek und einen gültigen Gemini-API-Schlüssel, der Zugriff auf entweder gemini-2.5-pro oder gemini-2.5-flash hat.
Installieren Sie die Consumer-Bibliothek, indem Sie Folgendes ausführen:
pip set up google-genai -U Legen Sie dann Ihre Umgebungsvariable für den API-Schlüssel fest:
export GOOGLE_API_KEY="your_api_key_here"Erstellen eines Dateisuchspeichers
In einem Dateisuchspeicher speichert und indiziert Gemini Einbettungen, die aus Ihren hochgeladenen Dateien erstellt wurden. Sobald eine Datei hochgeladen und indiziert wurde, bleiben die indizierten Daten zum Abruf verfügbar, bis Sie sie manuell löschen.
Für Nur-Textual content-RAG können Sie einen normalen Dateisuchspeicher erstellen. Für multimodale RAGs, in denen Sie sowohl Dokumente als auch Bilder hochladen und durchsuchen möchten, erstellen Sie den Retailer mit fashions/gemini-embedding-2.
from google import genai
from google.genai import varieties
import time
import os
from pathlib import Path
# Don't hardcode your API key within the pocket book.
# Set it as an atmosphere variable as a substitute.
os.environ("GOOGLE_API_KEY") = "enter_your_api_key"
consumer = genai.Consumer(api_key=os.environ("GOOGLE_API_KEY"))
file_search_store = consumer.file_search_stores.create(
config={
"display_name": "my_multimodal_rag_store",
"embedding_model": "fashions/gemini-embedding-2"
}
)
print("File Search Retailer created:", file_search_store.title)Ausgabe:

Dieses Replace ist wichtig, da in den offiziellen Dokumenten „embedding_model: fashions/gemini-embedding-2“ beim Erstellen eines Dateisuchspeichers für die multimodale Nutzung angezeigt wird.
Laden Sie eine Datei hoch
Nachdem der Dateisuchspeicher erstellt wurde, können Sie Dateien dorthin hochladen. Wenn eine Datei hochgeladen wird, teilt Gemini File Search den Inhalt automatisch auf, generiert Einbettungen und indiziert ihn für einen schnellen Abruf.
Für textbasierte RAG unterstützt die Dateisuche Dokumente wie PDF, DOCX, TXT, JSON und Programmierdateien wie .py und .js.
Für multimodale RAG unterstützt die Dateisuche auch Bilddateien. Das bedeutet, dass Sie Dokumente und Bilder in denselben Dateisuchspeicher hochladen und Fragen stellen können, die sowohl einen Textual content- als auch einen visuellen Kontext erfordern. Sie können beispielsweise eine Forschungsarbeit, ein Produktbild und ein Diagramm hochladen und Gemini dann bitten, die Arbeit zusammenzufassen und die zugehörigen visuellen Informationen zu erläutern.
Stellen Sie beim Hochladen von Bildern sicher, dass der File Search Retailer mit erstellt wurde fashions/gemini-embedding-2. Laut offizieller Dokumentation sind die unterstützten Bildformate PNG und JPEG. Bilddateien dürfen höchstens 4K x 4K Pixel groß sein und eine Anfrage kann maximal 6 Bilder enthalten.
Laden Sie eine Dokumentdatei hoch
# Add and import a doc into the File Search Retailer.
# The show title shall be seen in citations.
operation = consumer.file_search_stores.upload_to_file_search_store(
file="/content material/Paper2Agent.pdf",
file_search_store_name=file_search_store.title,
config={
"display_name": "Paper2Agent.pdf",
}
)
# Wait till import is full
whereas not operation.executed:
time.sleep(5)
operation = consumer.operations.get(operation)
print("Doc efficiently uploaded and listed.")Ausgabe:

Nach diesem Schritt wird das Dokument in Stücke aufgeteilt, eingebettet, indiziert und ist zum Abruf bereit.
Laden Sie eine Bilddatei für den multimodalen Abruf hoch
Sie können auch eine Bilddatei in denselben Dateisuchspeicher hochladen. Dies ist nützlich, wenn Ihre Anwendung Informationen aus Produktbildern, Screenshots, Diagrammen, Diagrammen oder anderen visuellen Inhalten abrufen muss.
# Add a picture file for multimodal retrieval.
operation = consumer.file_search_stores.upload_to_file_search_store(
file="/content material/product_image.jpg",
file_search_store_name=file_search_store.title,
config={
"display_name": "product_image.jpg",
}
)
# Wait till import is full
whereas not operation.executed:
time.sleep(5)
operation = consumer.operations.get(operation)
print("Picture efficiently uploaded and listed."Ausgabe:

Sobald das Bild indiziert ist, kann Gemini es während der Dateisuche abrufen, wenn die Anfrage des Benutzers für das Bild related ist.
Laden Sie mehrere Dokumente und Bilder hoch
In realen Anwendungen möchten Sie möglicherweise mehrere Dateien gleichzeitig hochladen. Diese Dateien können sowohl Textdokumente als auch Bilder enthalten.
from pathlib import Path
import time
files_to_upload = (
"/content material/Paper2Agent.pdf",
"/content material/product_image.jpg",
"/content material/sales_chart.png"
)
for file_path in files_to_upload:
operation = consumer.file_search_stores.upload_to_file_search_store(
file=file_path,
file_search_store_name=file_search_store.title,
config={
"display_name": Path(file_path).title,
}
)
whereas not operation.executed:
time.sleep(5)
operation = consumer.operations.get(operation)
print(f"Uploaded and listed: {file_path}")Ausgabe:

Nach dem Add-Schritt werden alle Dateien in Blöcke aufgeteilt, eingebettet, indiziert und stehen zum Abruf bereit. Wenn der File Search Retailer sowohl Dokumente als auch Bilder enthält, kann Gemini relevanten Kontext aus beiden Quellen abrufen und gleichzeitig Benutzerfragen beantworten.
Stellen Sie Fragen zur Datei
Sobald Ihre Dateien indiziert sind, kann Gemini Fragen beantworten und dabei die hochgeladenen Dokumente und Bilder als Kontext verwenden. Es durchsucht den Dateisuchspeicher, ruft die relevantesten Blöcke ab und generiert daraus eine fundierte Antwort.
Für einen Nur-Textual content-Anwendungsfall können Sie eine Frage zum hochgeladenen PDF stellen:
response = consumer.fashions.generate_content(
mannequin="gemini-3-flash-preview",
contents="Summarize what's there within the analysis paper.",
config=varieties.GenerateContentConfig(
instruments=(
varieties.Software(
file_search=varieties.FileSearch(
file_search_store_names=(file_search_store.title)
)
)
)
)
)
print("Mannequin Response:n")
print(response.textual content)Ausgabe:

Hier wird die Dateisuche als Software innerhalb von generic_content() verwendet. Das Modell durchsucht zunächst Ihre gespeicherten Einbettungen, ruft die relevantesten Abschnitte ab und generiert dann eine Antwort basierend auf diesem Kontext.
Für einen multimodalen Anwendungsfall können Sie eine Frage stellen, die sowohl das Dokument als auch das Bild verwendet:
response = consumer.fashions.generate_content(
mannequin="gemini-3-flash-preview",
contents="""
Primarily based on the uploaded analysis paper, and the photographs,
summarize the important thing concept from the paper and clarify what the photographs exhibits.
""",
config=varieties.GenerateContentConfig(
instruments=(
varieties.Software(
file_search=varieties.FileSearch(
file_search_store_names=(file_search_store.title)
)
)
)
)
)
print("Multimodal Response:n")
print(response.textual content)Ausgabe:

Hier wird die Dateisuche als Werkzeug innerhalb von generic_content() verwendet. Das Modell durchsucht die gespeicherten Einbettungen, ruft den relevantesten Textual content- oder Bildkontext ab und generiert dann eine Antwort basierend auf den abgerufenen Informationen.
Passen Sie die Chunking-Funktion an
Standardmäßig entscheidet die Dateisuche, wie Dateien in Blöcke aufgeteilt werden. Sie können dieses Verhalten jedoch steuern, um eine bessere Suchgenauigkeit zu erzielen.
operation = consumer.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.title,
file="path/to/your/file.txt",
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
) Diese Konfiguration legt jeden Block auf 200 Token mit 20 überlappenden Token fest, um eine reibungslosere Kontextkontinuität zu gewährleisten. Kürzere Abschnitte liefern feinere Suchergebnisse, während größere Abschnitte eine allgemeinere Bedeutung behalten, die für Forschungsarbeiten und Codedateien nützlich ist.
Zitate für abgerufenen Kontext anzeigen
Sie können auch Zitatinformationen ausdrucken, um zu überprüfen, welche Dateien oder Blöcke Gemini beim Generieren der Antwort verwendet hat. In den offiziellen Dokumenten heißt es, dass Zitierinformationen über „grounding_metadata“ verfügbar sind und Bildreferenzen Particulars zu Medienzitaten enthalten können.
grounding_metadata = response.candidates(0).grounding_metadata
print("nRetrieved Context:n")
if grounding_metadata and grounding_metadata.grounding_chunks:
for chunk in grounding_metadata.grounding_chunks:
context = chunk.retrieved_context
if context:
print("Supply:", getattr(context, "title", "Unknown"))
print("Textual content:", getattr(context, "textual content", "No textual content accessible"))
if getattr(context, "page_number", None):
print("Web page Quantity:", context.page_number)
if getattr(context, "media_id", None):
print("Media ID:", context.media_id)
print("-" * 50)
else:
print("No grounding metadata discovered.")Ausgabe:

Dadurch wird der praktische Abschnitt stärker, da die Leser nicht nur die Antwort, sondern auch den von Gemini verwendeten Quellkontext sehen können.
Verwalten Sie Ihre Dateisuchspeicher
Mithilfe der API können Sie Dateisuchspeicher ganz einfach auflisten, anzeigen und löschen.
print("n Accessible File Search Shops:")
for s in consumer.file_search_stores.checklist():
print(" -", s.title)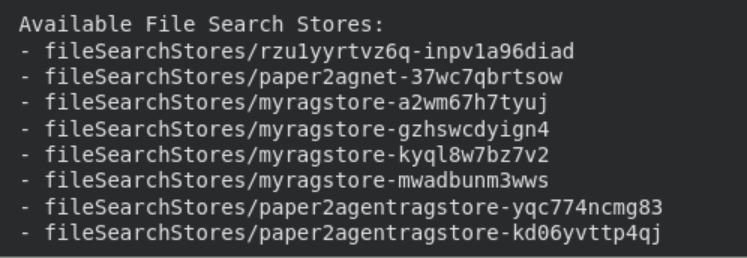
# Get detailed information
particulars = consumer.file_search_stores.get(title=file_search_store.title)
print("n Retailer Particulars:n", particulars
# Delete the shop (optionally available cleanup)
consumer.file_search_stores.delete(title=file_search_store.title, config={'pressure': True})
print("File Search Retailer deleted.")
Diese Verwaltungsoptionen tragen dazu bei, Ihre Umgebung organisiert zu halten. Indizierte Daten bleiben bis zur manuellen Löschung gespeichert, während über die temporäre Datei-API hochgeladene Dateien nach 48 Stunden automatisch entfernt werden.
Lesen Sie auch: 12 Dinge, die Sie mit der kostenlosen Gemini-API tun können
Unterstützung und Einschränkungen für die Dateisuche
Die Dateisuche ist mit den folgenden Gemini-Modellen verfügbar: Gemini 3.1 Professional Preview, Gemini 3.1 Flash-Lite Preview, Gemini 3 Flash Preview, Gemini 2.5 Professional und Gemini 2.5 Flash-Lite.
Mit Gemini 3-Modellen können Sie die Dateisuche per Funktionsaufruf mit benutzerdefinierten Instruments kombinieren. Allerdings wird die Dateisuche in der Reside-API noch nicht unterstützt und kann nicht mit bestimmten integrierten Instruments wie Grounding mit Google Search oder URL Context verwendet werden.
Die Dateisuche unterstützt eine Vielzahl von Dateiformaten, darunter PDFs, Phrase-Dokumente, Tabellenkalkulationen, Präsentationen, JSON, CSV, HTML, XML, Markdown, YAML, Codedateien, ZIP-Dateien und Jupyter-Notizbücher. Für multimodale RAG werden auch PNG- und JPEG-Bilder unterstützt, wenn der Retailer mit fashions/gemini-embedding-2 erstellt wird.
Dateigrößen- und Speicherbeschränkungen
| Benutzerebene | Dateigrößenbeschränkung | Speicherkapazitätsgrenze |
|---|---|---|
| Frei | 100 MB professional Datei | 1 GB |
| Stufe 1 | 100 MB professional Datei | 10 GB |
| Stufe 2 | 100 MB professional Datei | 100 GB |
| Stufe 3 | 100 MB professional Datei | 1 TB |
Empfohlen: Halten Sie jeden Speicher unter 20 GB, um eine bessere Abrufleistung und eine geringere Latenz zu erzielen.
Was die Preisgestaltung betrifft, so werden Einbettungen zum Zeitpunkt der Indizierung berechnet. Speicherung und Einbettungen zur Abfragezeit sind kostenlos und abgerufene Dokument-Tokens werden als normale Kontext-Tokens abgerechnet.
Lesen Sie auch: Wie kann ich auf die Gemini-API zugreifen und sie verwenden?
Abschluss
Durch die Dateisuche entfällt der Infrastrukturaufwand beim Aufbau von RAG-Systemen. Keine externen Vektordatenbanken, keine benutzerdefinierten Einbettungspipelines. Laden Sie einfach Ihre Dateien hoch und beginnen Sie mit der Abfrage. Mit der neuen multimodalen Unterstützung können Sie jetzt dokumenten- und bildübergreifend gemeinsam suchen. Mithilfe der Metadatenfilterung können Sie die Ergebnisse genau auf das Relevante beschränken, und Zitate auf Seitenebene sorgen dafür, dass jede Antwort bis zu ihrer Quelle zurückverfolgt werden kann. Unabhängig davon, ob Sie Prototypen erstellen oder für die Produktion bauen, bietet File Search Ihnen eine solide, verwaltete Grundlage, auf der Sie aufbauen können. Beginnen Sie mit Google AI Studio oder über die im Artikel verlinkten Gemini-API-Dokumente.
Hallo, ich bin Janvi, ein leidenschaftlicher Information-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.