Einführung
Dieser Artikel behandelt die Erstellung eines mehrsprachigen Chatbots für mehrsprachige Gebiete wie Indien unter Verwendung große Sprachmodelle. Das System verbessert die Kundenreichweite und Personalisierung, indem es LLMs verwendet, um Fragen zwischen lokalen Sprachen und Englisch zu übersetzen. Wir gehen auf die Architektur, Implementierungsdetails, Vorteile und erforderlichen Maßnahmen ein. Nachfolgende Forschungsbemühungen werden sich auf mögliche Weiterentwicklungen und eine breitere Implementierung dieser Lösung konzentrieren.
Lernziele
- Verstehen Sie die Rolle und Funktionen von Giant Language Fashions (LLMs) bei der Verbesserung des Kundenerlebnisses und der Personalisierung.
- Erfahren Sie, wie Sie mit LLMs zur Übersetzung und Abfragebearbeitung einen mehrsprachigen Chatbot entwickeln.
- Erkunden Sie die Architektur und Implementierungsdetails eines mehrsprachigen Chatbots mit Instruments wie Gradio, Databricks, Langchain und MLflow.
- Erfahren Sie mehr über Einbettungstechniken und die Erstellung einer Vektordatenbank für durch Abruf erweiterte Generierung (RAG) mit personenbezogenen Daten.
- Identifizieren Sie potenzielle Fortschritte und zukünftige Verbesserungen bei der Skalierung und Feinabstimmung LLM-basierter mehrsprachiger Chatbots für breitere Anwendungen.
Dieser Artikel erschien im Rahmen der Information Science-Blogathon.
Aufstieg der Technologie und Chat-GPT
Mit der aufkommenden Technologie und der Einführung von Chat-GPT hat die Welt ihren Fokus auf die Nutzung großer Sprachmodelle verlagert. Unternehmen nutzen große Sprachmodelle schnell, um den Geschäftswert zu steigern. Unternehmen nutzen sie ständig, um das Kundenerlebnis zu verbessern, Personalisierung hinzuzufügen und die Kundenreichweite zu verbessern.
Rolle großer Sprachmodelle
Ein LLM ist ein Computerprogramm, das mit genügend Beispielen gefüttert wurde, um menschliche Sprache oder andere Arten komplexer Daten erkennen und interpretieren zu können. Viele Organisationen trainieren LLMs anhand von Daten aus dem Web – Tausende oder Millionen Gigabyte an Textual content. Die Qualität der Beispiele wirkt sich jedoch darauf aus, wie intestine LLMs natürliche Sprache lernen, sodass die Programmierer eines LLMs möglicherweise einen besser kuratierten Datensatz verwenden.
Große Sprachmodelle (LLMs) verstehen
LLMs verwenden eine Artwork maschinellen Lernens namens Deep Studying, um zu verstehen, wie Zeichen, Wörter und Sätze zusammen funktionieren. Deep Studying beinhaltet die Wahrscheinlichkeitsanalyse unstrukturierter Daten, die es dem Deep-Studying-Modell schließlich ermöglicht, Unterschiede zwischen Inhaltsteilen ohne menschliches Eingreifen zu erkennen.
Darüber hinaus trainieren Programmierer LLMs durch Tuning, Feinabstimmung oder Immediate-Tuning, um sie für die Ausführung bestimmter Aufgaben wie das Interpretieren von Fragen, das Generieren von Antworten oder das Übersetzen von Textual content von einer Sprache in eine andere zu schulen.
Motivation für einen mehrsprachigen Chatbot
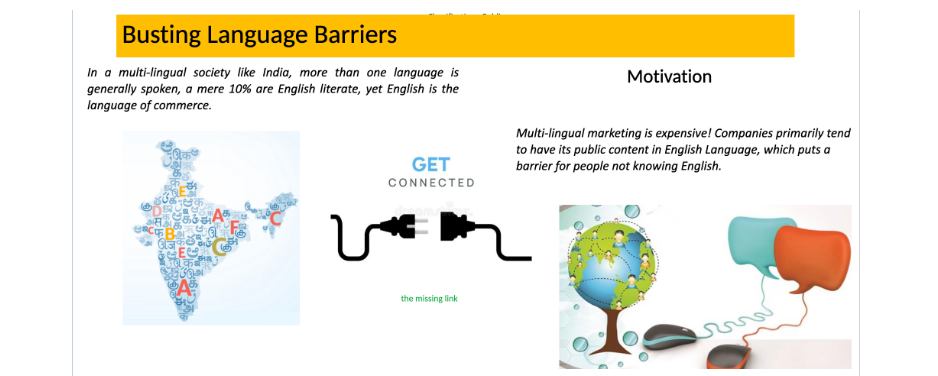
In vielen geografischen Regionen der Welt werden mehrere Sprachen gesprochen. Indien ist ein mehrsprachiges Land, in dem mehrere Sprachen gesprochen werden, wobei nur 10 % Englisch können. Hier wird in der Gemeinschaft eine einzige gemeinsame Sprache für eine ordnungsgemäße Kommunikation verwendet. Dies kann jedoch dazu führen, dass eine Sprache gegenüber anderen dominiert, was für Sprecher anderer Sprachen ein Nachteil sein kann.
Dies kann auch zum Verschwinden einer Sprache, ihrer unverwechselbaren Kultur und Denkweise führen. Für nationale/internationale Unternehmen ist es eine kostspielige Angelegenheit, ihre Geschäfts-/Marketinginhalte in mehreren Sprachen zu verfassen. Daher bleiben die meisten von ihnen bei einer Handelssprache – Englisch. Dies kann auch bedeuten, dass sie die Möglichkeit verlieren, besser mit dem lokalen Publikum in Kontakt zu treten und somit potenzielle Kunden verlieren. Obwohl die Verwendung von Englisch nicht grundsätzlich falsch ist, schließt sie diejenigen, die diese Sprache nicht beherrschen, von der Teilnahme am Mainstream-Handel aus.
Vorgeschlagene Lösung
Die vorgeschlagene Lösung ermöglicht es Benutzern, Abfragen in ihrer Landessprache zu stellen, LLMs zu verwenden, um Informationen auf Englisch zu verstehen und abzurufen, und sie dann wieder in die Landessprache zu übersetzen. Diese Lösung nutzt die Leistungsfähigkeit großer Sprachmodelle für die Übersetzung und Abfragebearbeitung.
Wichtige Merkmale und Funktionen
- Übersetzung von der Landessprache ins Englische und umgekehrt.
- Suchen der ähnlichsten Abfrage in der Datenbank.
- Beantwortung von Anfragen über das Foundation-LLM, wenn keine ähnliche Anfrage gefunden wird.
Mithilfe dieser Lösung können Unternehmen, insbesondere Banken, eine breitere Bevölkerungsschicht erreichen und Bankdienstleistungen nutzen, um der breiten Bevölkerung zu helfen und so ihre finanziellen Aussichten zu verbessern.

Vorteile eines mehrsprachigen Chatbots
- Größere Kundenreichweite: Durch die Unterstützung mehrerer Sprachen kann ein Chatbot ein breiteres Publikum erreichen und Benutzern Hilfe anbieten, die möglicherweise nicht dieselbe Sprache sprechen. Informationen und Dienste – insbesondere wichtige Dienste wie Bankgeschäfte – werden den Menschen leichter zugänglich gemacht. Dies kommt sowohl den Menschen als auch dem Unternehmen zugute.
- Verbesserte Personalisierung: Mehrsprachige Chatbots können Benutzern basierend auf ihren Sprach- und Kulturpräferenzen personalisierte Empfehlungen und maßgeschneiderte Erlebnisse bieten.
- Verbesserter Kundenservice: Chatbots können einen besseren Kundenservice bieten und dabei helfen, Probleme effizienter zu lösen, was zu einer höheren Kundenzufriedenheit führt.
Architektur des mehrsprachigen Chatbots
- Der Benutzer öffnet die Gradio-App und hat die Möglichkeit, die Daten in der lokalen Sprache einzugeben
- Übersetzung: Verwenden der angegebenen Eingabeaufforderung in der angegebenen lokalen Sprache mithilfe von LLM (Llama-70b-chat) über die MLflow-Route.
- Das System konvertiert die übersetzte Eingabeaufforderung mithilfe von Teacher-xl-Einbettungen in Einbettungen und sucht sie in der erstellten Vektordatenbank (Chroma) aus den personalisierten Daten in der Landessprache.
- Das System übergibt die Eingabeaufforderung mit dem Kontext (ähnlichste Einbettungen aus der semantischen Suche) für das Ergebnis an das LLM.
- Übersetzung: Übersetzung des Ergebnisses in die Landessprache.

Implementierungsdetails
- Gradio wird zum Erstellen des Entrance-Ends der App verwendet.
- Für die Codierung wurde Databricks verwendet. Das gesamte Framework wurde in Databricks entwickelt.
- Als ausgewähltes großes Sprachmodell wurde LLAMA-2 70b-Chat verwendet. Um die Chat-Abschlussausgabe aus der Eingabeaufforderung zu erhalten, wurde MosaicML-Inferenz verwendet.
- Die Anwendung führte Einbettungen mithilfe des Teacher-xl-Modells durch.
- Die Anwendung speicherte die Einbettungen in der ChromaDb-Vektordatenbank.
- Das Framework und die Pipeline der App nutzten Langchain und MLflow.
Code-Implementierung
Lassen Sie uns jetzt einen mehrsprachigen Chatbot mithilfe des Giant Language Mannequin implementieren.
Schritt 1: Installieren der erforderlichen Pakete
Die Pakete sind leicht zugänglich, indem man sie umarmt.
%pip set up mlflow
%pip set up --upgrade langchain
%pip set up faiss-cpu
%pip set up pydantic==1.10.9
%pip set up chromadb
%pip set up InstructorEmbedding
%pip set up gradioLaden der CSV für die RAG-Implementierung und Konvertieren in Textblöcke
LAPPEN ist ein KI-Framework zum Abrufen von Fakten aus einer externen Wissensdatenbank, um große Sprachmodelle (LLMs) auf den genauesten und aktuellsten Informationen zu basieren und Benutzern Einblick in den generativen Prozess von LLMs zu geben.
Forscher und Entwickler verwenden Retrieval-Augmented Era (RAG), um die Qualität der von LLM generierten Antworten zu verbessern, indem sie das Modell auf externen Wissensquellen basieren und so die interne Informationsdarstellung des LLM ergänzen.
Die Daten waren Frage-Antwort-Kombinationen in Hindi. Man kann den Frage-Antwort-Satz für jede beliebige Sprache generieren und ihn als Enter für die RAG-Implementierung verwenden.
Schritt 2: Laden und Vorbereiten von Daten für RAG
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/Workspace/DataforRAG_final1.csv",
encoding="utf-8", csv_args={'delimiter': ','})
knowledge = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
#from langchain.text_splitter import CharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
text_chunks = text_splitter.split_documents(knowledge)
Laden der Teacher-Xl-Einbettungen
Wir haben die Teacher-XL-Einbettungen von der Hugging Face-Website heruntergeladen.
Schritt 3: Einbettungen erstellen und speichern
from langchain.embeddings import HuggingFaceInstructEmbeddings
instructor_embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-xl",
model_kwargs={"gadget": "cuda"})Wir haben die Chroma-Vektordatenbank verwendet, um die für die RAG-Daten erstellten Einbettungen zu speichern. Wir haben die Teacher-XL-Einbettungen für den personalisierten Datensatz erstellt.
# Embed and retailer the texts
# Supplying a persist_directory will retailer the embeddings on disk
from langchain.vectorstores import Chroma
persist_directory = 'db'
## Right here is the nmew embeddings getting used
embedding = instructor_embeddings
vectordb = Chroma.from_documents(paperwork=text_chunks,
embedding=embedding,
persist_directory=persist_directory)
# persiste the db to disk
vectordb.persist()
vectordb = None
# Now we are able to load the persevered database from disk, and use it as regular.
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding)
Schritt 4: Definieren der Eingabeaufforderungsvorlage
from langchain.llms import MlflowAIGateway
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
import gradio as gr
from mlflow.gateway import set_gateway_uri, create_route, question,delete_route
set_gateway_uri("databricks")
mosaic_completion_route = MlflowAIGateway(
gateway_uri="databricks",
route="completion"
)
# Wrap the immediate and Gateway Route into a sequence
template = """(INST) <>
You're Banking Query Answering Machine. Reply Accordingly
<>
{context}
{query} (/INST)
"""
immediate = PromptTemplate(input_variables=('context', 'query'),
template=template)
retrieval_qa_chain = RetrievalQA.from_chain_type(llm=mosaic_completion_route, chain_type="stuff",
retriever=vectordb.as_retriever(), chain_type_kwargs={"immediate": immediate})
def generating_text(immediate,route_param,token):
# Create a Route for textual content completions with MosaicML Inference API
create_route(
title=route_param,
route_type="llm/v1/completions",
mannequin={
"title": "llama2-70b-chat",
"supplier": "mosaicml",
"mosaicml_config": {
"mosaicml_api_key": "3abc"
}
}
)
response1 = question(
route=route_param,
knowledge={"immediate": immediate,"temperature": 0.1,
"max_tokens": token}
)
return(response1)Schritt 5: Entwicklung der Gradio-App
Das Frontend haben wir mit dem Gradio-Paket entwickelt. Es verfügt über eine feste Vorlage, die nach Bedarf angepasst werden kann.

import string
import random
# initializing measurement of string
N = 7
def greet(Enter,chat_history):
RouteName1="text1"
RouteName2="text2"
system="""you're a translator which converts english to hindi.
Please translate the given textual content to hindi language and
solely return the content material translated. no rationalization"""
system1="""you're a translator which converts hindi to english.
Please translate the given textual content to english language from hindi language and
solely return the content material translated.
no rationalization"""
immediate=f"(INST) <> {system1} <> {Enter}(/INST)"
delete_route("text1")
consequence=generating_text(immediate,RouteName1,400)
res=consequence('candidates')(0)('textual content')
t=retrieval_qa_chain.run(res)
prompt2=f"(INST) <> {system} <> {t} (/INST)"
delete_route("text2")
token=800
result1=generating_text(prompt2,RouteName2,token)
chat_history.append((Enter, result1('candidates')(0)('textual content')))
return "", chat_history
with gr.Blocks(theme=gr.themes.Tender(primary_hue=gr.themes.colours.blue,
secondary_hue=gr.themes.colours.crimson)) as demo:
gr.Markdown("## सखा- भाषा अब कोई बाधा नहीं है")
chatbot = gr.Chatbot(top=400) #simply to suit the pocket book
msg = gr.Textbox(label="Immediate",placeholder="अपना प्रश्न हिंदी में यहां दर्ज करें",max_lines=2)
with gr.Row():
btn = gr.Button("Submit")
clear = gr.ClearButton(elements=(msg, chatbot), worth="Clear console")
# btn = gr.Button("Submit")
# clear = gr.ClearButton(elements=(msg, chatbot), worth="Clear console")
btn.click on(greet, inputs=(msg, chatbot), outputs=(msg, chatbot))
msg.submit(greet, inputs=(msg, chatbot), outputs=(msg, chatbot))
gr.Examples((("एचडीएफसी बैंक का कस्टमर केयर नंबर क्या है?"),
("गोल्ड लोन क्या है??"),('गोल्ड लोन के लिए आवश्यक दस्तावेज।')),
inputs=(msg,chatbot))
gr.close_all()
demo.launch(share=True,debug=True)
#import csvWeitere Fortschritte
Lassen Sie uns nun weitere Weiterentwicklungen des mehrsprachigen Chatbots erkunden.
Skalierung auf verschiedene Regionalsprachen
Derzeit haben wir zu Demozwecken die Lösung für die Sprache Hindi erstellt. Diese kann für verschiedene Regionalsprachen skaliert werden.
Feinabstimmung des LLAMA-2 70b-Chatmodells
- Feinabstimmung des Modells mit benutzerdefinierten Daten auf Hindi.
- Ausweitung der Feinabstimmung auf andere lokale Muttersprachen.
Mögliche Verbesserungen und zukünftige Arbeiten
- Einbindung zusätzlicher Options und Funktionen.
- Verbesserung der Genauigkeit und Effizienz von Übersetzungen und Antworten.
- Erkundung der Integration fortgeschrittenerer LLMs und Einbettungstechniken.
Abschluss
Mithilfe von Giant Language Fashions (LLMs) ließe sich ein mehrsprachiger Chatbot erstellen, der die Zugänglichkeit und Kommunikation in sprachlich vielfältigen Gebieten wie Indien verändern würde. Diese Technologie verbessert die Kundenbindung, indem sie sprachliche Hürden überwindet. Zukünftige Entwicklungen der LLM-Funktionen und die Skalierung auf zusätzliche Sprachen werden das Benutzererlebnis noch weiter verbessern und die globale Reichweite mehrsprachiger Chatbots erhöhen.
Die zentralen Thesen
- Mehrsprachige Chatbots, die LLMs nutzen, überbrücken Sprachbarrieren und verbessern die Zugänglichkeit und das Engagement der Benutzer.
- Die Integration von Gradio, Databricks, Langchain und MLflow optimiert die Entwicklung mehrsprachiger Chatbots.
- Der Einsatz von Retrieval-Augmented Era (RAG) verbessert die Antwortqualität durch Nutzung externer Wissensquellen.
- Personalisierte Erlebnisse und eine größere Kundenreichweite werden durch sprachspezifische Einbettungen und Vektordatenbanken ermöglicht.
- Zukünftige Fortschritte zielen darauf ab, LLMs zu skalieren und zu optimieren, um eine größere sprachliche Vielfalt und verbesserte Effizienz zu erreichen.
Häufig gestellte Fragen
A. Ein mehrsprachiger Chatbot ist ein KI-gestütztes Device, das mehrere Sprachen verstehen und in ihnen antworten kann und so die Kommunikation über unterschiedliche sprachliche Hintergründe hinweg erleichtert.
A. LLMs ermöglichen mehrsprachigen Chatbots, Anfragen zu übersetzen, den Kontext zu verstehen und Antworten in verschiedenen Sprachen mit hoher Genauigkeit und Natürlichkeit zu generieren.
A. LLMs verbessern die Kundenreichweite, indem sie auf unterschiedliche Sprachpräferenzen eingehen, die Personalisierung durch maßgeschneiderte Interaktionen verbessern und die Effizienz bei der Bearbeitung mehrsprachiger Anfragen steigern.
A. Unternehmen können ihren Kundenstamm erweitern, indem sie Dienste in der bevorzugten Sprache der Kunden anbieten, die Kundenzufriedenheit durch personalisierte Interaktionen verbessern und ihre Abläufe auf den globalen Märkten optimieren.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.