
Vor einigen Jahren warfare die Auswahl eines KI-Modells relativ einfach. Wahrscheinlich kannten Sie den Begriff „KI-Modell“ noch nicht einmal ChatGPT wurde synonym dazu verwendet. Es warfare damals die offensichtliche (und vielleicht einzige) Wahl.
Aber Die Zeiten haben sich geändert. ChatGPT ist nicht mehr die zentrale Anlaufstelle für KI-Modelle. Claude, Grok, Gemini, Deepseek, Qwen, Kimi, Llama … und viele mehr stehen zur Verfügung. Diese Wahl sollte die Benutzer stärken. Aber das hier ist Realität hat den gegenteiligen Effekt gehabt!
Dies liegt daran, dass diese Modelle gleich aussehen und sich gleich anfühlen (dieselbe Chatbot-Oberfläche) und sich in einem vergleichbaren Tempo weiterentwickeln. Die eigentliche Frage lautet additionally nicht mehr: „Welches Modell ist das beste?“
Es ist: Welches Modell ist das Beste für mich?
Und basierend auf dem, was ich gesehen habe, ist dies der Ort Die meisten Leute verstehen es falsch.
Das Drawback
ChatGPT kann für Sie ausgefeilte E-Mails schreiben. Aber das können auch Claude, DeepSeek, Gemini und quick jedes andere KI-Modell heute.
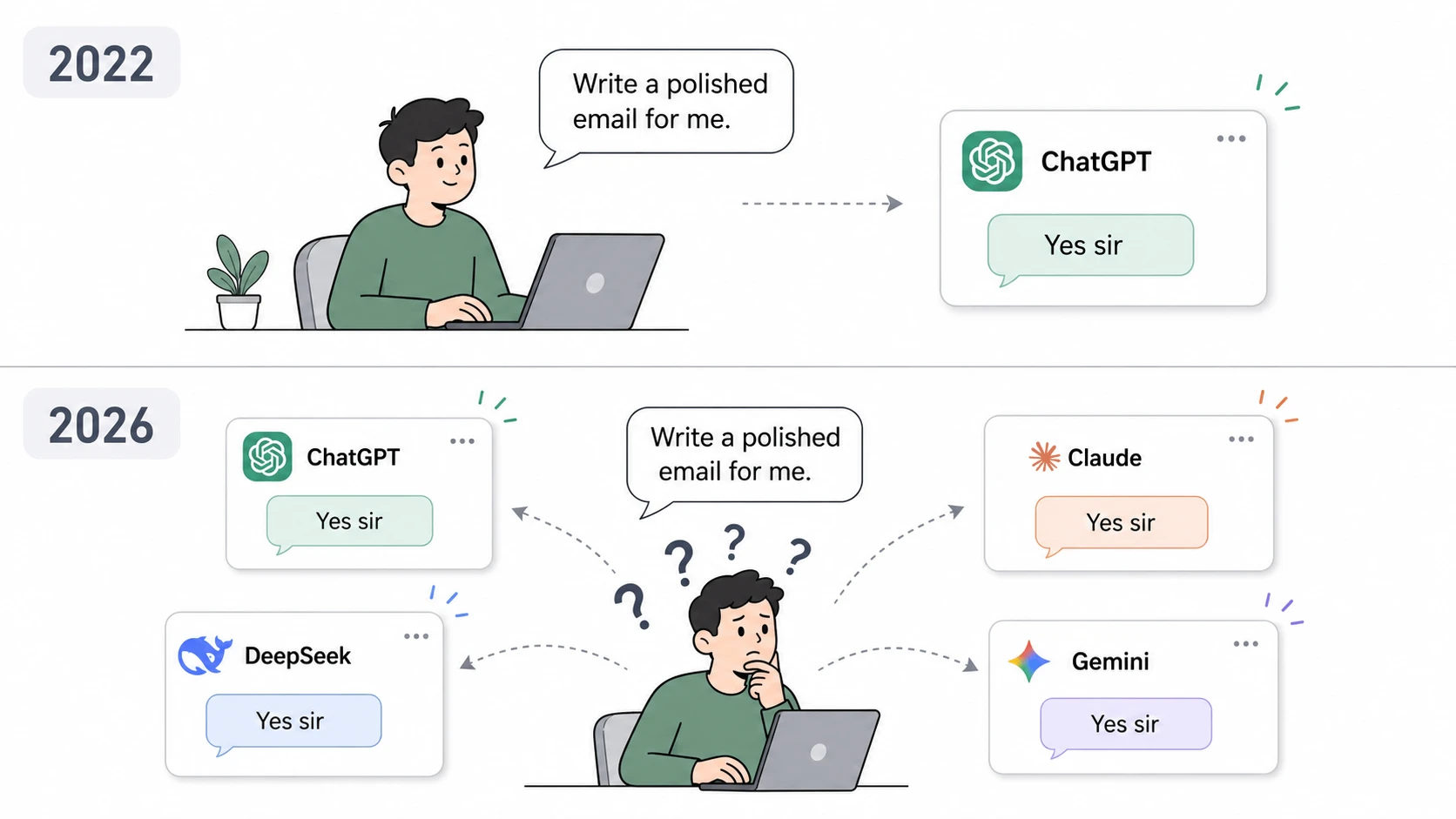
Das ist das Drawback.
Auf der Oberfläche sind diese Modelle austauschbar. Sie alle können Dokumente zusammenfassen, Konzepte erklären, Code schreiben und Fragen beantworten. Für den Durchschnittsnutzer sind die Unterschiede nicht sofort ersichtlich.
Daher fangen die Leute aus den falschen Gründen an, sich für Modelle zu entscheiden:
- Ihr Freund hat es empfohlen.
- Letzte Woche ging es in den sozialen Medien viral.
- Es hat einen KI-Benchmark übertroffen (was nicht immer ein guter Indikator ist)
- Es warfare das erste Modell, das sie ausprobierten.
- Dies ist zufällig die Standardoption in einer App, die sie bereits verwenden.
Keiner dieser Gründe ist schrecklich. Aber besonders nachdenklich sind sie auch nicht.
Der bessere Weg, ein KI-Modell auszuwählen, besteht darin, nicht mehr zu fragen, welches insgesamt das beste ist, sondern zu fragen was das Modell eigentlich leisten soll. Doch bevor wir darauf eingehen, was bei der Auswahl eines Modells zu beachten ist, werfen wir einen Blick auf einige Dinge, die man nicht tun sollte.
Benchmarks: Die Nebelwand
Die meisten Menschen beginnen aus einem Hauptgrund mit der Nutzung eines Chatbots. Vielleicht brauchen sie Hilfe beim Schreiben, Codieren, Recherchieren oder Brainstorming.
Und wenn Sie hier sind das Beste vom Besten In einer bestimmten Domäne können Sie diese Tabelle als Leitfaden für die Auswahl Ihres Modells verwenden:
Wenn nun die vorherige Tabelle Ihre Modellwahl beeinflussen konnte, Das ist genau das Drawback, auf das ich mich bezog.
Denn diese Ergebnisse wurden mit der Flaggschiff-Model der aufgeführten Modelle erzielt, die alle sind bezahlt. Für diejenigen, die ein Abonnement dieser Modelle haben, ist das vielleicht kein Drawback, aber für diejenigen, die kein Abonnement haben, ändert sich die Gleichung wie folgt:
- Claude Opus: Ohne kostenpflichtiges Abonnement nicht zugänglich.
- GPT-5.5-Denken: Kostenlose Benutzer erhalten 10 GPT-5.5-Nachrichten alle 5 Stundendann wechseln Chats zum Mini-Modell: Ich denke, der Zugriff ist viel eingeschränkter als bei kostenpflichtigen Stufen.
- Gemini 3.1 Professional: Google verwendet rechenbasierte Grenzwerte das erfrischt jeden 5 Stunden bis eine wöchentliche Obergrenze erreicht ist: Ein höherer Zugriff auf Gemini 3.1 Professional ist an Google AI Professional/Extremely-Pläne gebunden.
- GPT-Bild 2: ChatGPT Free beinhaltet die Bildgenerierung, OpenAI listet sie jedoch als auf begrenzt und langsamer.
Man sieht deutlich, dass diese Modelle keine Wahl mehr sind, wenn man kein Abonnement hat.
Wenn man bedenkt, dass die meisten Benutzer eines KI-Modells das kostenlose Kontingent nutzen, ist die Ungleichheit im Servicemodell bemerkenswert.
Notiz: Dies sollte Sie auf Benchmarks oder Metriken für ein Modell aufmerksam machen. Denn die meisten davon werden über die SOTA-Varianten der üblicherweise kostenpflichtigen Modelle bezogen. Ihre kostenlosen Varianten lassen zu wünschen übrig.
Die Perspektive: Was funktioniert für uns?
Die Auswahl eines Modells ausschließlich auf der Grundlage von Benchmark-Rankings ähnelt der Auswahl eines Autos ausschließlich auf der Grundlage seiner Höchstgeschwindigkeit. Die Zahl magazine korrekt sein, aber Sie suchen möglicherweise nach Sicherheit und Komfort (was es irgendwie sinnlos macht).
In der Praxis haben Faktoren wie Preise, Ratenlimits, Kontextfenster, Ökosystemintegrationen und sogar bevorzugte Antwortstile oft einen größeren Einfluss auf die Benutzererfahrung als ein paar Prozentpunkte auf einer Bestenliste.

Aus diesem Grund können zwei Personen genau die gleichen Benchmark-Ergebnisse betrachten und dennoch zu völlig unterschiedlichen Modellentscheidungen kommen.
- Ein Softwareentwickler mit einem KI-Modellabonnement
- Ein Scholar, der kostenlose Instruments verwendet
- Ein Vermarkter, der bereits in das Google-Ökosystem eingebettet ist
Diese lösen unterschiedliche Probleme unter unterschiedlichen Einschränkungen.
Bevor Sie sich additionally für ein Modell entscheiden, sollten Sie die Bestenlisten hinter sich lassen und die Faktoren berücksichtigen, die Ihr Alltagserlebnis tatsächlich prägen.
Die Wahl: Ihr eigenes Framework
Anstatt uns auf einen Benchmark oder ein Framework zu verlassen, das jemand on-line veröffentlicht hat, erstellen wir unsere eigene Bewertungsmetrik.
Beginnen Sie mit etwas Einfachem: Hear Sie die drei häufigsten Aufgaben auf, für die Sie einen Chatbot verwenden.
Ihre eigentlichen Aufgaben.
Für mich wäre das:
- Einen ersten Entwurf eines Artikels schreiben.
- Mehrere Optionen vergleichen (auf Amazon) und eine empfehlen.
- Durch ein Hin- und Her-Gespräch etwas Neues lernen.
Es geht darum, die Bewertung zu begründen unsere eigene Realität.
Es ist Ihnen egal, ob ein Modell an der Spitze einer Benchmark-Bestenliste steht, wenn es bei den Dingen, die Sie eigentlich von ihm erwarten, versagt.
- Claude ist vielleicht das klügste Modell auf dem Papier, aber wenn Sie eine Bildgenerierung benötigen und diese keine Bilder erstellen kann, ist sie nutzlos.
- Zwillinge könnten bei Codierungs-Benchmarks außergewöhnlich intestine abschneiden, sind aber schlecht darin, Kaufentscheidungen zu treffen, was sie zu einer schlechten Wahl macht.
Anstatt additionally zu fragen „Welches Modell ist das beste?“, stellen wir eine viel engere Frage:
Welches Modell ist das Beste für mich?
Nachdem Sie Ihre Aufgaben ausgewählt haben, erstellen Sie eine einfache Bewertungsrubrik.
Bewerten Sie das Modell für jede Aufgabe auf einer Skala von 1 bis 5. Die genauen Kriterien spielen keine Rolle. Vielleicht legen Sie Wert auf Genauigkeit. Es geht um die Geschwindigkeit, oder es interessiert Sie vielleicht, wie oft das Modell Anweisungen falsch versteht.
Stellen Sie einfach sicher, dass Sie bei jedem Modell die gleichen Dinge messen. Führen Sie dann jede Aufgabe über jeden Chatbot aus, den Sie bewerten.
Meine Wahl
In meinem Fall ergab die Bewertung der derzeit drei besten Modelle in meinem Arbeitspensum folgende Ergebnisse:
| Aufgabe | GPT | Claude | Zwillinge |
| Schreiben | ★★★★★ | ★★★★☆ | ★★☆☆☆ |
| Forschung | ★★★★★ | ★★★★☆ | ★★★★☆ |
| Lernen | ★★★★☆ | ★★★★☆ | ★★★★☆ |
| Endergebnis |
14/15 Gewinner |
15.12 | 15.10 |
GPT-5.5 hat sich bei meiner Arbeitsbelastung durchgesetzt, weil es bei allen drei Aufgaben durchweg nützlich warfare.
Abschluss
Es gibt kein allgemein bestes KI-Modell. Die richtige Wahl hängt von Ihren Vorlieben und Ihrer Arbeit ab. Benchmarks können Ihnen Orientierung geben, aber sie Ich kann Ihnen diese Entscheidung nicht abnehmen.
Der sicherste Ansatz ist einfach: Testen Sie einige Modelle anhand von drei Aufgaben, die Sie regelmäßig ausführen, bewerten Sie sie regelmäßig und wählen Sie das Modell aus, das für Ihren Anwendungsfall am besten geeignet ist. Dadurch bleibt Ihre Entscheidung auf der Grundlage von Beweisen und nicht von Hype.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.