
Die Entwicklung einer Roboterrichtlinie, die in der realen Welt funktioniert, ist kein Computerproblem mehr – es ist ein Datenproblem. Verkörperte KI-Groups haben drei Möglichkeiten, ihre Modelle anzutreiben: Teleoperation, Simulation und menschliches Video. Jedes hat eine andere Kostenkurve, ein anderes Wiedergabetreueprofil und eine andere Obergrenze dafür, was Ihr Roboter letztendlich lernen kann. Die Wahl der falschen Primärquelle kann sechs Monate und ein siebenstelliges Price range verschlingen, bevor Sie es herausfinden. In diesem Leitfaden wird jede Datenquelle für verkörperte KI aufgeschlüsselt, wo sie gewinnt, wo sie scheitert und wie sie zu einer Strategie für Robotertrainingsdaten in Produktionsqualität kombiniert werden kann.
Wichtige Erkenntnisse
- Die Teleoperation liefert die Daten mit der höchsten Wiedergabetreue, weist jedoch bei 5–50 Episoden professional Bedienerstunde einen Engpass auf.
- Die Simulation generiert kostengünstig Millionen von Episoden, führt jedoch zu einer Lücke zwischen Simulation und Realität, die bei kontaktreichen Aufgaben fehlschlägt.
- Menschliche Movies lassen sich mühelos skalieren, weisen jedoch keine Bezeichnungen für Roboteraktionen auf und weisen eine Verkörperungslücke auf.
- Aktuelle Untersuchungen zeigen, dass etwa 8 Simulationsbeispiele für domäneninterne Aufgaben den Wert eines teleoperierten Beispiels liefern.
- Die meisten in der Produktion verkörperten KI-Pipelines kombinieren alle drei Quellen, anstatt eine auszuwählen.
Warum sind Daten der Flaschenhals in der verkörperten KI?
Daten sind der Engpass in der verkörperten KI, da es im Internetmaßstab keine aktionsgepaarten sensomotorischen Daten gibt. Ein Sprachmodell kann eine Billion Textual content-Tokens aus dem Internet aufnehmen. Eine Roboterrichtlinie benötigt synchronisierte Gelenkwinkel, Greifkräfte, Kamerabilder und Aufgabenkontext – alles aufgezeichnet während der physischen Manipulation. Nichts davon gibt es kostenlos.
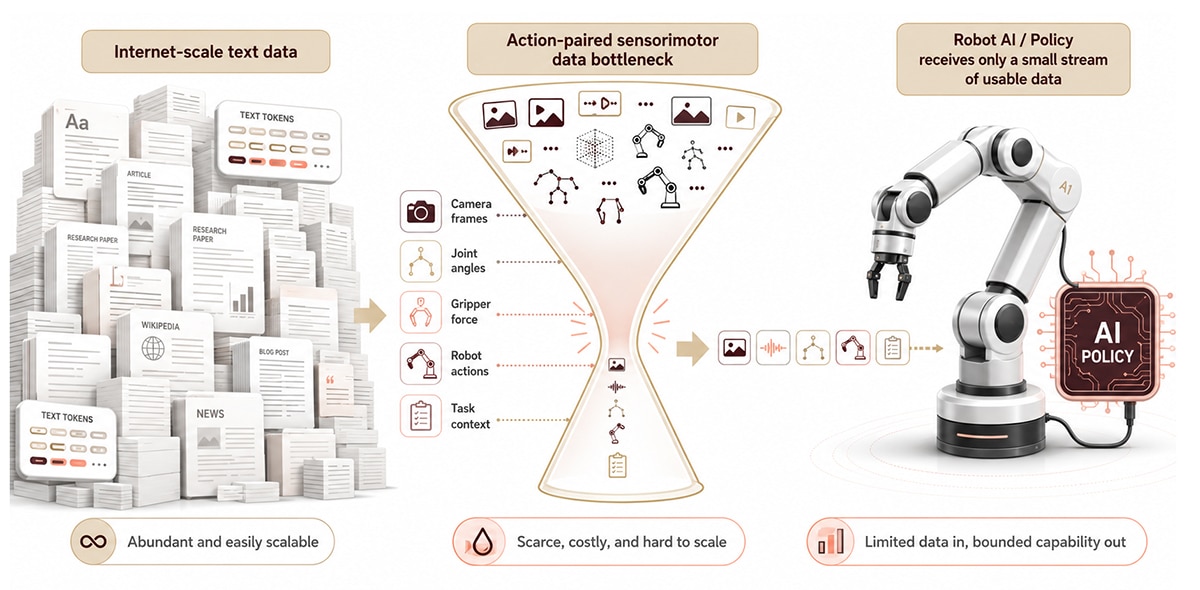
Der Skalenunterschied ist groß. Über 3,9 Millionen Industrieroboter sind weltweit im Einsatz (IFR World Robotics, 2024), doch der größte offene Robotermanipulationsdatensatz enthält etwa 1 Million Episoden (Open X-Embodiment, Padalkar et al., 2023). Die {Hardware} ist überall; die Daten sind es nicht. Jede neue Ausführungsform – einarmiger Manipulator, bimanueller Humanoid, cellular Foundation mit Arm – setzt die Datenanforderungen effektiv zurück, da auf einem Formfaktor trainierte Richtlinien selten sauber auf einen anderen übertragen werden.
Verkörperungslücke: Der Leistungsverlust, der auftritt, wenn eine auf die physische Konfiguration eines Roboters trainierte Richtlinie auf einem anderen Roboter bereitgestellt wird.
Aus diesem Grund denken Robotic-Studying-Groups heute an Datenstrategien und nicht nur an der Datenerfassung. Die richtige Mischung aus Teleoperation, Simulation und menschlichem Video bestimmt, was Ihr Modell kann, wie schnell es versendet wird und wie viel Sie für die Anreise ausgeben.
Was sind Teleoperationsdaten und wann setzen sie sich durch?
Teleoperationsdaten werden aufgezeichnet, wenn ein menschlicher Bediener einen Roboter in Echtzeit über einen Führungsarm, ein VR-Headset, ein Exoskelett oder eine am Handgelenk montierte Schnittstelle steuert, während das System jeden Gelenkwinkel, jeden Kraftmesswert und jedes Kamerabild synchron protokolliert.

Teleoperation: Menschliche Echtzeitsteuerung eines Roboters mit synchronisierten sensomotorischen Daten, die während der Manipulation aufgezeichnet werden.
Teleoperation gewinnt durch Treue. Da die Daten von einem erfahrenen Menschen generiert werden, der genau die Aufgabe am exakten Roboter ausführt, ist die Übereinstimmung zwischen Aktion und Zustand perfekt und die Verkörperungslücke beträgt Null. Nachahmungslernen, Verhaltensklonen und Feinabstimmung von Richtlinien profitieren alle von sauberen Teleop-Demonstrationen.
Die Kosten zeigen sich im Maßstab. Ein erfahrener Teleoperator produziert je nach Komplexität der Aufgabe 5–50 Episoden professional Stunde, wobei die Qualität mit zunehmender Ermüdung des Bedieners abnimmt. Ein Roboter, ein Bediener – das ist die Obergrenze, und deshalb haben sich offene Plattformen wie ALOHA, UMI und Exoskelett-basierte humanoide Bohrinseln (AgiBot, Fourier GR-1) alle auf Kostensenkung und Durchsatzsteigerung statt auf radikale Skalierung konzentriert.
Shaips Physische KI-Datendienste Betreiben Sie Teleoperationszellen neben multimodalen Erfassungsabläufen, sodass Robotikteams keine Operator-Pipelines von Grund auf aufbauen müssen.
Was sind Simulationsdaten und wo werden sie skaliert?
Simulationsdaten werden von Physik-Engines – MuJoCo, NVIDIA Isaac Sim, Isaac Lab, PyBullet – generiert, die virtuelle Roboter rendern, die Aufgaben über Tausende von parallelen Instanzen ausführen. Ein einzelner GPU-Cluster kann über Nacht Millionen von Episoden zu Grenzkosten nahe Null produzieren.
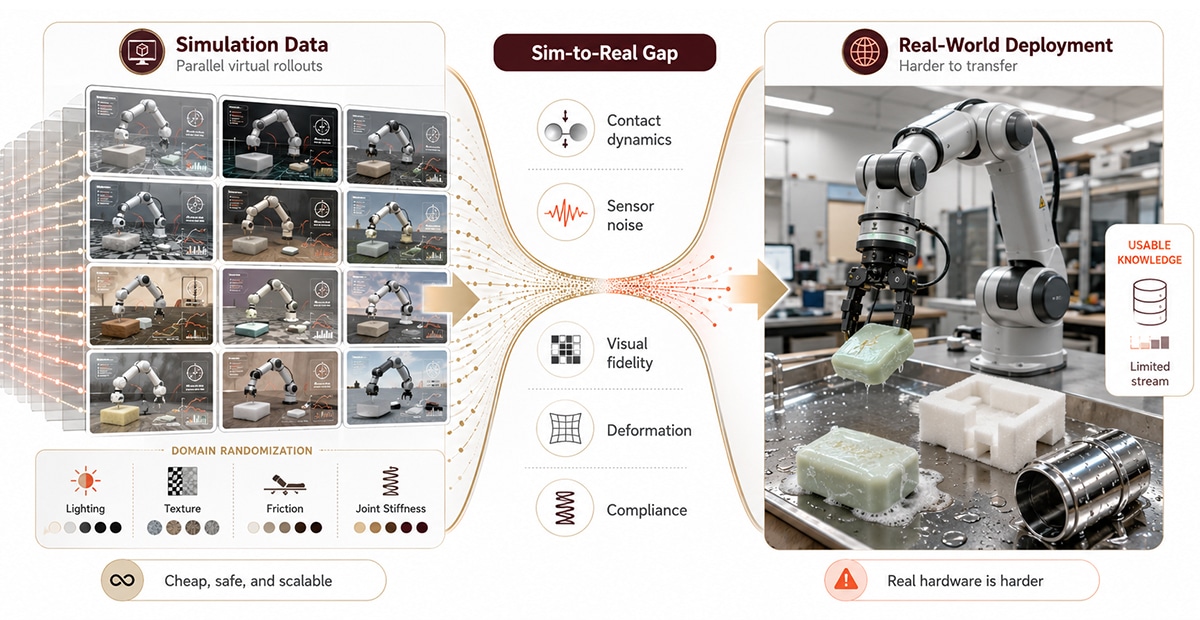
Simulation gewinnt in Bezug auf Maßstab und Sicherheit. Grenzfälle, Kollisionsfehler und gefährliche Konfigurationen können alle untersucht werden, ohne dass die {Hardware} beschädigt wird. Die Domänen-Randomisierung – zufällige Variation von Beleuchtung, Texturen, Reibung und Gelenksteifheit während des Trainings – führt zu Richtlinien, die reale Variationen überstehen, anstatt sich übermäßig an eine einzelne visuelle Konfiguration anzupassen.
Sim-zu-Actual-Lücke: Der Leistungsabfall, wenn eine in der Simulation trainierte Richtlinie auf physischer {Hardware} bereitgestellt wird, wird normalerweise durch Kontaktdynamik, Sensorrauschen und Unterschiede in der visuellen Wiedergabetreue verursacht.
Die Kosten werden bei der Bereitstellung angezeigt. Simulatoren modellieren nicht die Reibung eines feuchten Seifenstücks, das Nachgeben einer Schaumstoffverpackung oder die visuelle Variation von spiegelndem Metall unter Neonbeleuchtung. Bei kontaktreichen Aufgaben scheitert Sim-to-Actual am häufigsten. Eine im Jahr 2025 veröffentlichte Studie hat den Kompromiss quantifiziert: Ungefähr 8 Simulationsproben bieten den gleichen Nutzen wie eine teleoperierte Probe für domäneninterne Manipulationsaufgaben (Information Utilization Regulation for Robotic Manipulation, 2025).
Fotorealistische Rendering-Plattformen wie NVIDIA Cosmos und 3D Gaussian Splatting verringern die visuelle Lücke, aber die Dynamiklücke – Reibung, Verformung, Nachgiebigkeit – bleibt das schwierigere Downside.
Was sind menschliche Videodaten und was wird dadurch freigeschaltet?
Menschliche Videodaten sind Aufnahmen von Menschen, die Manipulationsaufgaben ausführen – Wäsche falten, Geschirr stapeln, Komponenten zusammenbauen –, aufgenommen von egozentrischen Kameras, Überwachungswinkeln oder kuratierten Demonstrationssets.
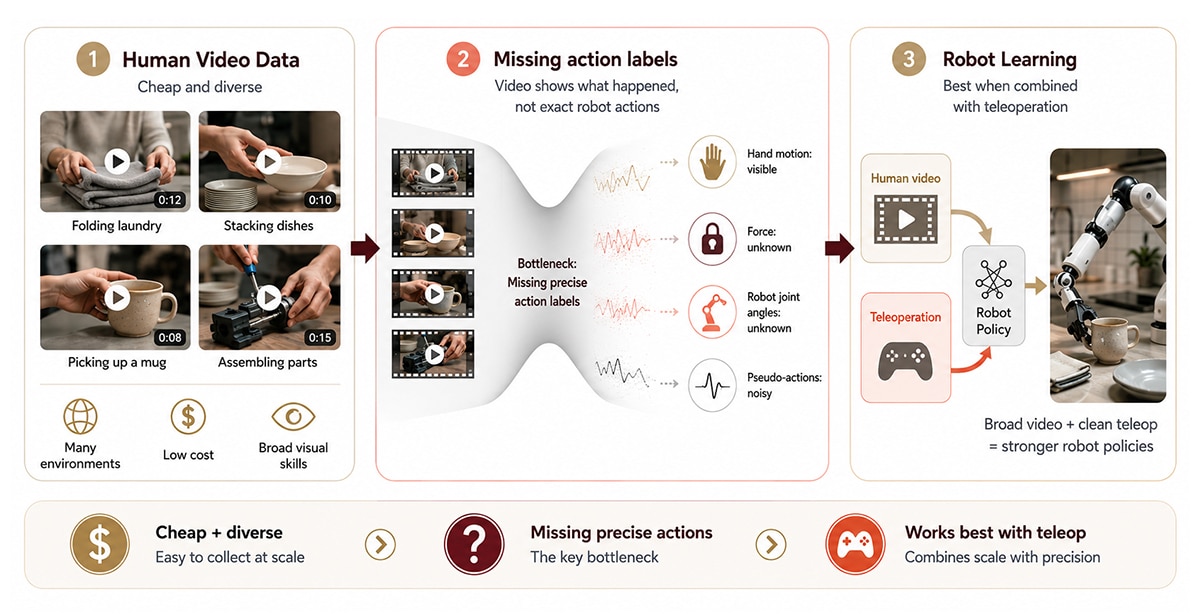
Menschliches Video überzeugt durch Kosten und Vielfalt. Ein einzelner Mitarbeiter mit einem Smartphone kann an einem einzigen Nachmittag Hunderte von Demonstrationen in Küchen, Garagen, Fabriken und Büros aufzeichnen. Kein Roboter erforderlich, kein Labor erforderlich, keine Bedienerschulung erforderlich. Große Imaginative and prescient-Sprachmodelle, die vorab anhand menschlicher Movies trainiert wurden, erwerben ein allgemeines Szenenverständnis, das vor der Feinabstimmung sinnvoll auf Roboterrichtlinien übertragen werden kann.
Die Einschränkung ist die fehlende Aktionsbezeichnung. Das Video zeigt eine Hand, die eine Tasse ergreift; Es zeichnet weder die ausgeübte Kraft noch die Gelenkwinkel auf, die ein Roboterarm benötigen würde, um die Bewegung nachzubilden. Inverse-Dynamics-Modelle und Hand-to-Finish-Effektor-Retargeting können diese Bezeichnungen teilweise ableiten, die resultierenden Pseudoaktionen sind jedoch verrauscht.
Stellen Sie sich ein Startup vor, das einen Küchenroboter baut. Sie haben 80.000 Greenback zum Ausgeben. Zwanzig Stunden geschickter Teleoperation könnten ihnen 200 saubere Episoden auf ihrem Zielarm bescheren. Zwanzig Stunden Videosammlung von Mitwirkenden aus verschiedenen Küchen zu Hause bescheren ihnen mehrere tausend egozentrische Clips. Das Telefongerät ist schärfer. Das Videoset ist breiter. Der Roboter benötigt beides, in unterschiedlichen Verhältnissen in unterschiedlichen Trainingsstadien.
Teleoperation vs. Simulation vs. menschliches Video: ein direkter Vergleich
Wie wählt man die richtige Datenstrategie für verkörperte KI?
Die Auswahl der richtigen Datenstrategie für das Robotertraining beginnt mit dem Bereitstellungsziel, nicht mit der Datenquelle. Ein Choose-and-Place-Roboter in der Fabrik, ein humanoider Haushalt und ein chirurgischer Assistent haben völlig unterschiedliche Anforderungen an Treue, Sicherheit und Verkörperung – und daher völlig unterschiedliche ideale Datenmischungen.
Ein praktischer dreistufiger Rahmen:
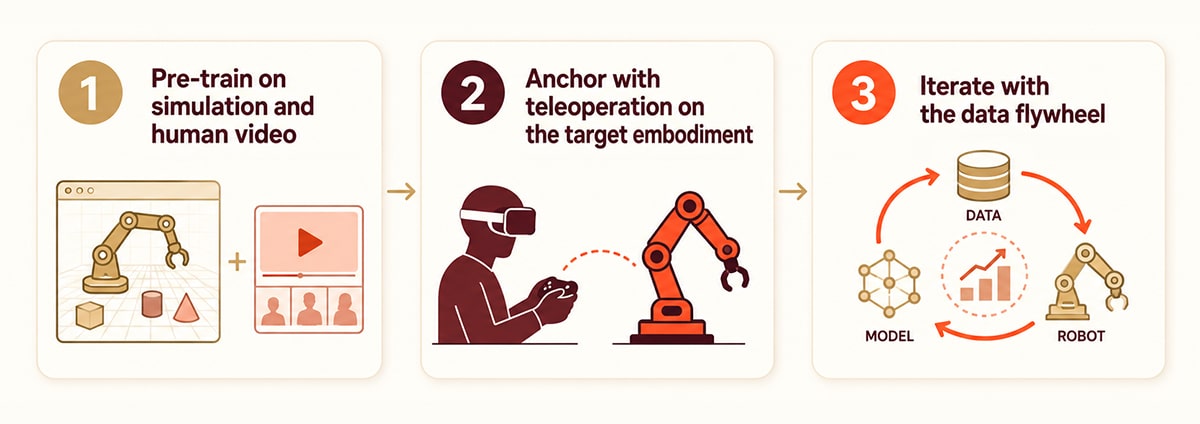
- Machen Sie sich vorab mit Simulation und menschlichem Video vertraut. Nutzen Sie die Simulation für eine umfassende Abdeckung von Szenen, Objekten und Sicherheitskantenfällen. Fügen Sie egozentrische menschliche Movies hinzu, um natürliche Manipulationsvoraussetzungen und reale visuelle Vielfalt zu erzielen. Diese Section ist günstig und umfassend.
- Anker mit Teleoperation an der Zielverkörperung. Sammeln Sie 500–2.000 hochwertige Teleop-Episoden über genau den Roboter, den Sie einsetzen möchten. Diese Section ist teuer, aber unersetzlich – sie verleiht der Politik eine echte Dynamik.
- Iterieren Sie mit dem Datenschwungrad. Erfassen Sie nach der Bereitstellung autonome Rollouts und Fehlerfälle. Füttere sie zusammen mit frischen Teleop- und Menschenvideos wieder in den nächsten Trainingszyklus.
Stellen Sie sich das wie die Ausbildung eines Kochs vor. Simulation ist eine Kochschule – umfassend, billig, fehlertolerant. Ein menschliches Video sieht sich Tausende von Kochvideos an – breiter Kontext, keine eigene Küche. Teleoperation ist das praktische Praktikum in der Küche, in der Sie arbeiten – langsam, teuer, unersetzlich. Kein ernsthafter Koch lässt einen der drei aus.
Shaips multimodale Datenerfassung Und Anmerkungsworkflows sind so konzipiert, dass sie alle drei Ebenen unterstützen – Teleop-Zellenbetrieb, Simulationskennzeichnung und egozentrische Videosammlung durch ein globales Netzwerk von über 500.000 Mitwirkenden –, sodass Robotikteams eine Hybridstrategie orchestrieren können, ohne fünf Anbieter zusammenzufügen.
Abschluss
Die Debatte Teleoperation vs. Simulation vs. menschliches Video hat im Jahr 2026 eine klare Antwort: Es ist keine Wahl, es ist ein Stack. Teleoperation gibt Ihnen Treue. Durch Simulation erhalten Sie Maßstab. Menschliches Video bietet Ihnen Vielfalt. Produktionsverkörperte KI-Pipelines kombinieren alle drei, gewichtet nach dem Bereitstellungsziel, der Verkörperung und dem Price range. Die Groups, die das nächste Jahrzehnt des Roboterlernens gewinnen, werden nicht diejenigen sein, die sich für die günstigste Quelle entscheiden – sie werden diejenigen sein, die die intelligenteste Mischung organisieren.