Generieren Sie im Handumdrehen konsistente Aufgaben in verschiedenen Implementierungsumgebungen

Ein zentraler Bestandteil der Durchführung eines Experiments besteht darin, einer Versuchseinheit (z. B. einem Kunden) eine bestimmte Behandlung (Zahlungsbutton-Variante, Gestaltung einer Advertising and marketing-Push-Benachrichtigung) zuzuweisen. Oft muss diese Zuweisung die folgenden Bedingungen erfüllen:
- Es muss zufällig sein.
- Es muss stabil sein. Wenn der Kunde zum Bildschirm zurückkehrt, muss ihm dieselbe Zahlungsschaltflächenvariante angezeigt werden.
- Es muss sehr schnell abgerufen oder generiert werden.
- Es muss nach der eigentlichen Zuweisung verfügbar sein, damit es in nachgelagerten Analysen verwendet werden kann.
Wenn Organisationen zum ersten Mal mit Experimenten beginnen, besteht ein gängiges Muster darin, Zuweisungen vorab zu generieren, sie in einer Datenbank zu speichern und sie dann zum Zeitpunkt der Zuweisung abzurufen. Dies ist eine absolut gültige Methode und funktioniert hervorragend, wenn Sie gerade erst anfangen. Wenn Sie jedoch beginnen, die Kunden- und Experimentvolumina zu skalieren, wird es immer schwieriger, diese Methode zu warten und zuverlässig zu verwenden. Sie müssen (a) die Komplexität der Speicherung verwalten und (b) sicherstellen, dass die Zuweisungen tatsächlich zufällig sind. innerhalb Und über Experimente und (c) die Aufgabe zuverlässig abrufen. All dies ist im großen Maßstab schwierig.
Verwenden von Hash-Leerzeichen hilft, einige dieser Probleme zu lösen. Es ist eine einfache Lösung, aber nicht so bekannt, wie es wahrscheinlich sein sollte. Dieser Weblog ist ein Versuch, die Technik zu erklären. Am Ende gibt es Hyperlinks zu Code in verschiedenen Sprachen. Wenn Sie möchten, können Sie jedoch auch direkt hier zum Code springen.
Wir führen ein Experiment durch, um zu testen, welche Variante eines Fortschrittsbalkens in unserer Kunden-App das meiste Engagement erzeugt. Es gibt drei Varianten: Kontrolle (die Standarderfahrung), Variante A und Variante B.
Wir haben 10 Millionen Kunden, die unsere App jede Woche nutzen, und wir möchten sicherstellen, dass diese 10 Millionen Kunden zufällig einer der drei Varianten zugewiesen werden. Jedes Mal, wenn der Kunde zur App zurückkehrt, sollte er dieselbe Variante sehen. Wir möchten, dass die Kontrolle mit einer Wahrscheinlichkeit von 50 % zugewiesen wird, Variante 1 mit einer Wahrscheinlichkeit von 30 % und Variante 2 mit einer Wahrscheinlichkeit von 20 %.
probability_assignments = {"Management": 50, "Variant 1": 30, "Variant 2": 20}
Um es einfacher zu machen, beginnen wir mit 4 Kunden. Diese Kunden haben IDs, die wir verwenden, um auf sie zu verweisen. Diese IDs sind im Allgemeinen entweder GUIDs (etwa "b7be65e3-c616-4a56-b90a-e546728a6640") oder Ganzzahlen (wie 1019222, 1028333). Jeder dieser ID-Typen würde funktionieren, aber der Einfachheit halber nehmen wir einfach an, dass diese IDs lauten: „Kunde1“, „Kunde2“, „Kunde3“, „Kunde4“.

Diese Methode basiert in erster Linie auf der Verwendung von Hash-Algorithmen, die einige sehr wünschenswerte Eigenschaften aufweisen. Hash-Algorithmen nehmen eine Zeichenfolge beliebiger Länge und bilden sie auf einen „Hash“ fester Länge ab. Am einfachsten lässt sich dies anhand einiger Beispiele verstehen.
Eine Hash-Funktion nimmt einen String und bildet ihn auf einen konstanten Hash-Raum ab. Im folgenden Beispiel wird eine Hash-Funktion (in diesem Fall md5) nimmt die Wörter „Hallo“, „Welt“, „Hallo Welt“ und „Hallo Welt“ (beachten Sie das große L) und ordnet sie einer alphanumerischen Zeichenfolge mit 32 Zeichen zu.

Einige wichtige Hinweise:
- Die Hashes sind alle gleich lang.
- Ein kleiner Unterschied in der Eingabe (großes L statt kleines L) ändert den Hash.
- Hashes sind hexadezimale Zeichenfolgen. Das heißt, sie bestehen aus den Zahlen 0 bis 9 und den ersten sechs Buchstaben des Alphabets (a, b, c, d, e und f).
Wir können dieselbe Logik verwenden und Hashes für unsere vier Kunden erhalten:
import hashlibrepresentative_customers = ("Customer1", "Customer2", "Customer3", "Customer4")
def get_hash(customer_id):
hash_object = hashlib.md5(customer_id.encode())
return hash_object.hexdigest()
{buyer: get_hash(buyer) for buyer in representative_customers}
# {'Customer1': 'becfb907888c8d48f8328dba7edf6969',
# 'Customer2': '0b0216b290922f789dd3efd0926d898e',
# 'Customer3': '2c988de9d49d47c78f9f1588a1f99934',
# 'Customer4': 'b7ca9bb43a9387d6f16cd7b93a7e5fb0'}

Hexadezimale Zeichenfolgen sind lediglich Darstellungen von Zahlen in der Foundation 16. Wir können Konvertieren Sie sie in Ganzzahlen in Foundation 10.
⚠️ Ein wichtiger Hinweis hier: Wir müssen selten den vollständigen Hash verwenden. In der Praxis (zum Beispiel im verlinkten Code) verwenden wir einen viel kleineren Teil des Hashs (die ersten 10 Zeichen). Hier verwenden wir den vollständigen Hash, um die Erklärungen etwas einfacher zu machen.
def get_integer_representation_of_hash(customer_id):
hash_value = get_hash(customer_id)
return int(hash_value, 16){
buyer: get_integer_representation_of_hash(buyer)
for buyer in representative_customers
}
# {'Customer1': 253631877491484416479881095850175195497,
# 'Customer2': 14632352907717920893144463783570016654,
# 'Customer3': 59278139282750535321500601860939684148,
# 'Customer4': 244300725246749942648452631253508579248}

Diese ganzen Zahlen haben zwei wichtige Eigenschaften:
- Diese ganzen Zahlen sind stabil: Bei einer festen Eingabe („Kunde1“) liefert der Hashing-Algorithmus immer dieselbe Ausgabe.
- Diese ganzen Zahlen sind gleichmäßig verteilt: Dies wurde bisher nicht erklärt und bezieht sich hauptsächlich auf kryptografische Hash-Funktionen (wie MD5). Einheitlichkeit ist eine Designanforderung für diese Hash-Funktionen. Wenn sie nicht gleichmäßig verteilt wären, wäre die Wahrscheinlichkeit von Kollisionen (das Erhalten derselben Ausgabe für unterschiedliche Eingaben) höher und würde die Sicherheit des Hashs schwächen. Es gibt einige Erkundungen des Gleichmäßigkeit Eigentum.
Jetzt haben wir eine Ganzzahldarstellung jeder ID, die stabil ist (immer den gleichen Wert hat) und gleichmäßig verteiltwir können es verwenden, um zu einer Aufgabe zu gelangen.
Zurück zu unseren Wahrscheinlichkeitszuweisungen: Wir möchten Kunden Varianten mit der folgenden Verteilung zuordnen:
{"Management": 50, "Variant 1": 30, "Variant 2": 20}
Wenn wir 100 Slots hätten, könnten wir sie in drei Buckets unterteilen, wobei die Anzahl der Slots die Wahrscheinlichkeit darstellt, die wir diesem Bucket zuweisen möchten. In unserem Beispiel unterteilen wir beispielsweise den ganzzahligen Bereich 0–99 (100 Einheiten) in 0–49 (50 Einheiten), 50–79 (30 Einheiten) und 80–99 (20 Einheiten).

def divide_space_into_partitions(prob_distribution):
partition_ranges = ()
begin = 0
for partition in prob_distribution:
partition_ranges.append((begin, begin + partition))
begin += partition
return partition_rangesdivide_space_into_partitions(prob_distribution=probability_assignments.values())
# word that that is zero listed, decrease certain inclusive and higher certain unique
# ((0, 50), (50, 80), (80, 100))
Wenn wir nun einen Kunden zufällig einem der 100 Slots zuweisen, sollte die resultierende Verteilung unserer beabsichtigten Verteilung entsprechen. Man kann sich das auch so vorstellen: Wenn wir zufällig eine Zahl zwischen 0 und 99 wählen, besteht eine 50-prozentige Probability, dass sie zwischen 0 und 49 liegt, eine 30-prozentige Probability, dass sie zwischen 50 und 79 liegt, und eine 20-prozentige Probability, dass sie zwischen 80 und 99 liegt.
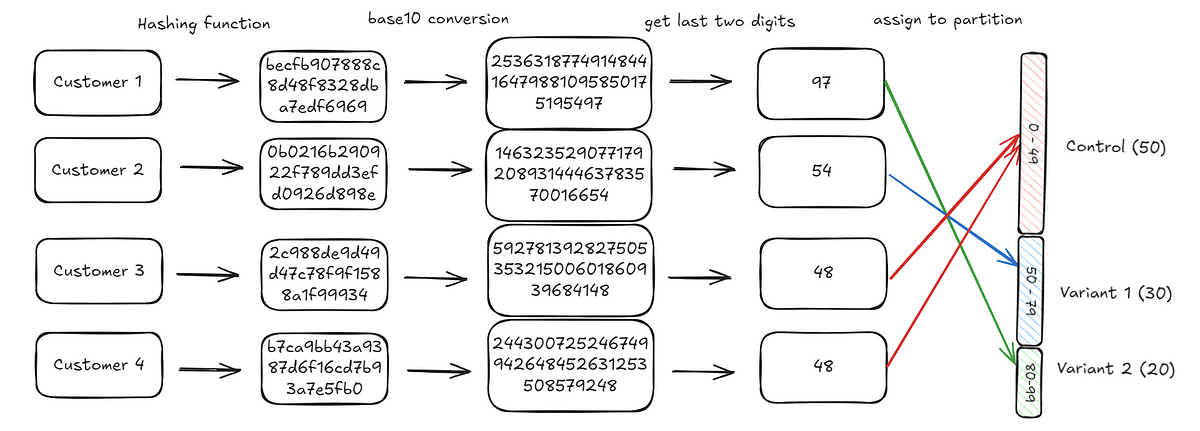
Der einzige verbleibende Schritt besteht darin, die von uns generierten Kundenzahlen einem dieser hundert Slots zuzuordnen. Dies tun wir, indem wir die letzten beiden Ziffern der generierten Ganzzahl extrahieren und diese als Zuweisung verwenden. Beispielsweise lauten die letzten beiden Ziffern für Kunde 1 97 (siehe Diagramm unten). Dies fällt in den dritten Bucket (Variante 2) und daher wird der Kunde der Variante 2 zugewiesen.
Wir wiederholen diesen Prozess iterativ für jeden Kunden. Wenn wir mit allen unseren Kunden fertig sind, sollten wir feststellen, dass die Endverteilung unseren Erwartungen entspricht: 50 % der Kunden haben die Kontrolle, 30 % bei Variante 1, 20 % bei Variante 2.
def assign_groups(customer_id, partitions):
hash_value = get_relevant_place_value(customer_id, 100)
for idx, (begin, finish) in enumerate(partitions):
if begin <= hash_value < finish:
return idx
return Nonepartitions = divide_space_into_partitions(
prob_distribution=probability_assignments.values()
)
teams = {
buyer: checklist(probability_assignments.keys())(assign_groups(buyer, partitions))
for buyer in representative_customers
}
# output
# {'Customer1': 'Variant 2',
# 'Customer2': 'Variant 1',
# 'Customer3': 'Management',
# 'Customer4': 'Management'}
Der verlinktes Wesentliches hat eine Reproduktion des oben Gesagten für 1.000.000 Kunden, wobei wir beobachten können, dass die Kunden in den erwarteten Anteilen verteilt sind.
# ensuing proportions from a simulation on 1 million prospects.
{'Variant 1': 0.299799, 'Variant 2': 0.199512, 'Management': 0.500689