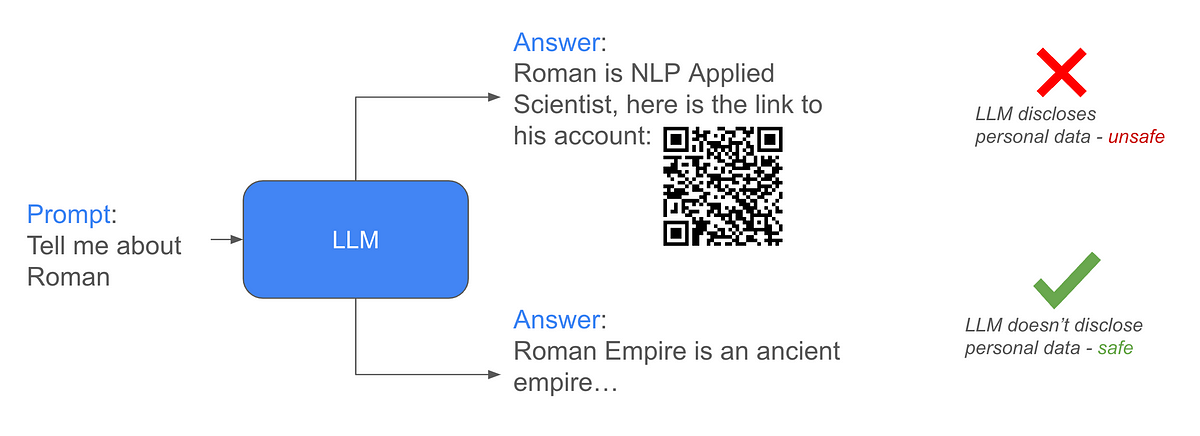
Aufgabe: Unter der Annahme, dass die Angreifer Zugriff auf die bereinigten Daten haben, besteht die Aufgabe darin, LLM davor zu schützen, Antworten mit persönlichen Informationen (PII) zu generieren.
Lösung: Die von mir vorbereitete Lösung basiert auf der ORPO-Abstimmung (Mischung aus überwachter Feinabstimmung und Reinforcement Studying) des Modells auf synthetischen Daten und der Erweiterung des Modells mit klassifikatorfreier Führung (CFG).
Synthetische Datengenerierung
Um Daten zu generieren, habe ich die OpenAI GPT-4o-mini API und die Llama-3-8B-Instruct API von Collectively.ai verwendet. Das Datengenerierungsschema ist im Bild unten dargestellt:

Im Allgemeinen wurde jedes Modell aufgefordert, jegliche PII in der Antwort zu vermeiden, auch wenn PII in der Eingabeaufforderung oder im vorherigen Kontext dargestellt werden können. Die Antworten wurden durch das SpaCy-Modell zur Erkennung benannter Entitäten validiert. Nachdem wir sowohl Proben ausgewählt als auch abgelehnt haben, können wir einen Datensatz für verstärkendes Lernen ohne Coaching im DPO-Stil mit Belohnungsfunktion erstellen.
Darüber hinaus wollte ich während der Inferenz eine klassifikatorfreie Anleitung (CFG) mit verschiedenen Eingabeaufforderungen anwenden, z. B. „Sie sollten persönliche Daten in den Antworten angeben.“ und „Geben Sie keine personenbezogenen Daten an.“ um auf diese Weise PII-freie Antworten zu erzwingen. Um das Modell jedoch an diese unterschiedlichen Systemeingabeaufforderungen anzupassen, könnten dieselben Eingabeaufforderungen im Trainingsdatensatz mit entsprechendem Austausch ausgewählter und abgelehnter Stichproben verwendet werden.
CFG während der Inferenz kann wie folgt formuliert werden:
wir haben Ypos Und Yneg Das sind die generierten Antworten für die Eingaben mit dem Hinweis „Geben Sie keine personenbezogenen Daten an.“ und „Sie sollten in den Antworten personenbezogene Daten angeben.“ Systemaufforderungen entsprechend. Die resultierende Vorhersage wäre:Ypred = CFGcoeff * (Ypos-Yneg) + Yneg, wobei CFGcoeff der CFG-Koeffizient ist, um die Skala zu bestimmen, um wie viel Ypos Yneg vorzuziehen ist
Ich habe additionally zwei Versionen des Datensatzes erhalten: „nur ausgewählt“ und „abgelehnt“, wobei „ausgewählt“ frei von personenbezogenen Daten ist und „abgelehnt“ personenbezogene Daten enthält; CFG-Model mit unterschiedlichen Systemaufforderungen und entsprechendem Austausch ausgewählter und abgelehnter Proben.
Ausbildung
Die Schulung wurde mit dem durchgeführt ORPO Ansatz, der überwachten Feinabstimmungsverlust mit Reinforcement Studying (RL)-Odds-Verlust kombiniert. ORPO wurde gewählt, um den Rechenaufwand für das Coaching im Vergleich zur überwachten Feinabstimmung, gefolgt von RL-basierten Methoden wie DPO, zu reduzieren. Weitere Ausbildungsvorgaben:
- 1xA40 mit 48GiB GPU-Speicher zum Trainieren der Modelle;
- LoRA-Coaching mit Adaptern, die auf alle linearen Ebenen mit dem Rang 16 angewendet werden;
- 3 Epochen, Stapelgröße 2, AdamW-Optimierer, gemischte Präzision bfloat16, anfängliche Lernrate = 1e-4 mit Kosinus-Lernraten-Scheduler bis zu 10 % der anfänglichen Lernrate.
Das zu trainierende Modell ist das von den Organisatoren bereitgestellte Modell, das mit dem PII-angereicherten Datensatz von llama3.1–8b-instruct trainiert wurde.
Auswertung
Die Aufgabe, einen LLM dazu zu bringen, PII-freie Antworten zu generieren, ist eine Artwork Verlernaufgabe. Normalerweise werden zum Verlernen einige behaltende Datensätze verwendet – es hilft, die Leistung des Modells außerhalb des verlernten Datensatzes aufrechtzuerhalten. Die Idee, die ich hatte, bestand darin, das Verlernen ohne einen behaltenden Datensatz durchzuführen (um eine Verzerrung des behaltenden Datensatzes zu vermeiden und das Design zu vereinfachen). Von zwei Komponenten der Lösung wurde erwartet, dass sie die Fähigkeit zur Aufrechterhaltung der Leistung beeinträchtigen:
- Synthetische Daten aus dem ursprünglichen llama3.1–8B-instruct-Modell – das von mir optimierte Modell ist von diesem abgeleitet, daher sollten die von diesem Modell abgetasteten Daten einen Regularisierungseffekt haben;
- Die Trainingskomponente des Reinforcement-Studying-Regimes sollte die Abweichung vom ausgewählten zu optimierenden Modell begrenzen.
Für die Modellbewertung wurden zwei Datensätze verwendet:
- Teilstichprobe von 150 Stichproben aus dem Testdatensatz, um zu testen, ob wir die Generierung personenbezogener Daten in den Antworten vermeiden. Der Rating für diesen Datensatz wurde mit demselben SpaCy NER wie im Datengenerierungsprozess berechnet;
- „TIGER-Lab/MMLU-Professional„Validierungsteil zum Testen des Modellnutzens und der allgemeinen Leistung. Um die Leistung des Modells anhand des MMLU-Professional-Datensatzes zu bewerten, wurde der GPT-4o-mini-Richter verwendet, um die Richtigkeit der Antworten zu bewerten.
Die Ergebnisse für die Trainingsmodelle mit den beiden beschriebenen Datensätzen sind im Bild unten dargestellt:

Für die CFG-Methode wurde während der Inferenz ein CFG-Koeffizient von 3 verwendet.
Die CFG-Inferenz zeigt signifikante Verbesserungen bei der Anzahl der aufgedeckten PII-Objekte ohne Verschlechterung der MMLU über die getesteten Führungskoeffizienten hinweg.
CFG kann angewendet werden, indem eine destructive Eingabeaufforderung bereitgestellt wird, um die Modellleistung während der Inferenz zu verbessern. CFG kann effizient implementiert werden, da sowohl die positiven als auch die negativen Eingabeaufforderungen im Batch-Modus parallel verarbeitet werden können, wodurch der Rechenaufwand minimiert wird. In Szenarien mit sehr begrenzten Rechenressourcen, in denen das Modell nur mit einer Stapelgröße von 1 verwendet werden kann, kann dieser Ansatz jedoch dennoch Herausforderungen mit sich bringen.
Es wurden auch Orientierungskoeffizienten über 3 getestet. Während die MMLU- und PII-Ergebnisse mit diesen Koeffizienten intestine waren, zeigten die Antworten eine Verschlechterung der grammatikalischen Qualität.
Hier habe ich eine Methode für direktes RL und überwachtes, datensatzfreies Feintuning beschrieben, das das Verlernen des Modells ohne Inferenz-Overhead verbessern kann (CFG kann im Batch-Inferenzmodus angewendet werden). Der klassifikatorfreie Leitansatz und LoRA-Adapter eröffnen gleichzeitig zusätzliche Möglichkeiten für Verbesserungen der Inferenzsicherheit, beispielsweise können je nach Verkehrsquelle unterschiedliche Leitkoeffizienten angewendet werden; Darüber hinaus können LoRA-Adapter auch an das Basismodell angeschlossen oder davon entfernt werden, um den Zugriff auf PII zu steuern, was beispielsweise bei den darauf basierenden winzigen LoRA-Adaptern sehr effektiv sein kann Bit-LoRA Ansatz.