
Intro
KI -Agenten sind autonome Programme, die Aufgaben ausführen, Entscheidungen treffen und mit anderen kommunizieren. Normalerweise verwenden sie eine Reihe von Instruments, um Aufgaben zu erledigen. In Genai -Anwendungen verarbeiten diese Agenten sequentielle Argumentation und können externe Instruments (wie Websuche oder Datenbankabfragen) verwenden, wenn das LLM -Wissen nicht ausreicht. Im Gegensatz zu einem grundlegenden Chatbot, der bei Unsicherheit zufälligen Textual content generiert, aktiviert ein AI -Agent Instruments, um genauere, spezifische Antworten zu liefern.
Wir rücken uns immer näher an das Konzept von Agenten AI: Systeme, die ein höheres Maß an Autonomie und Entscheidungsfähigkeit aufweisen, ohne direkte menschliche Intervention. Während die heutigen AI-Agenten reagierend auf menschliche Eingaben reagieren, beteiligt sich die Agent-AIS von morgen proaktiv auf Problemlösung und kann ihr Verhalten anhand der Scenario anpassen.
Heute wird es so einfach, Agenten von Grund auf neu zu bauen wie ein logistisches Regressionsmodell vor 10 Jahren. Damals damals, Scikit-Be taught bot eine einfache Bibliothek, um maschinelles Lernen mit nur wenigen Code -Zeilen schnell zu trainieren und einen Großteil der zugrunde liegenden Komplexität abzuziehen.
In diesem Tutorial werde ich zeigen, wie es geht Bauen Sie verschiedene Arten von AI -Agenten von Grund aufvon einfachen bis fortschrittlicheren Systemen. Ich werde einen nützlichen Python -Code präsentieren, der in ähnlichen Fällen leicht angewendet werden kann (einfach kopieren, einfügen, rennen) und jede Codezeile mit Kommentaren durchgehen, damit Sie dieses Beispiel replizieren können.
Aufstellen
Wie gesagt, kann jeder einen benutzerdefinierten Agenten ohne GPU- oder API -Schlüssel kostenlos ausführen lassen. Die einzige notwendige Bibliothek ist Ollama (pip set up ollama==0.4.7) Da Benutzer LLMs lokal ausführen können, ohne Cloud-basierte Dienste zu benötigen, um mehr Kontrolle über Datenschutz und Leistung zu erhalten.
Zuallererst müssen Sie herunterladen Ollama von der Web site.

Verwenden Sie dann auf der Eingabeaufforderung Ihres Laptops den Befehl, um das ausgewählte LLM herunterzuladen. Ich gehe mit Alibaba’s Qwenwie es sowohl klug als auch lite ist.
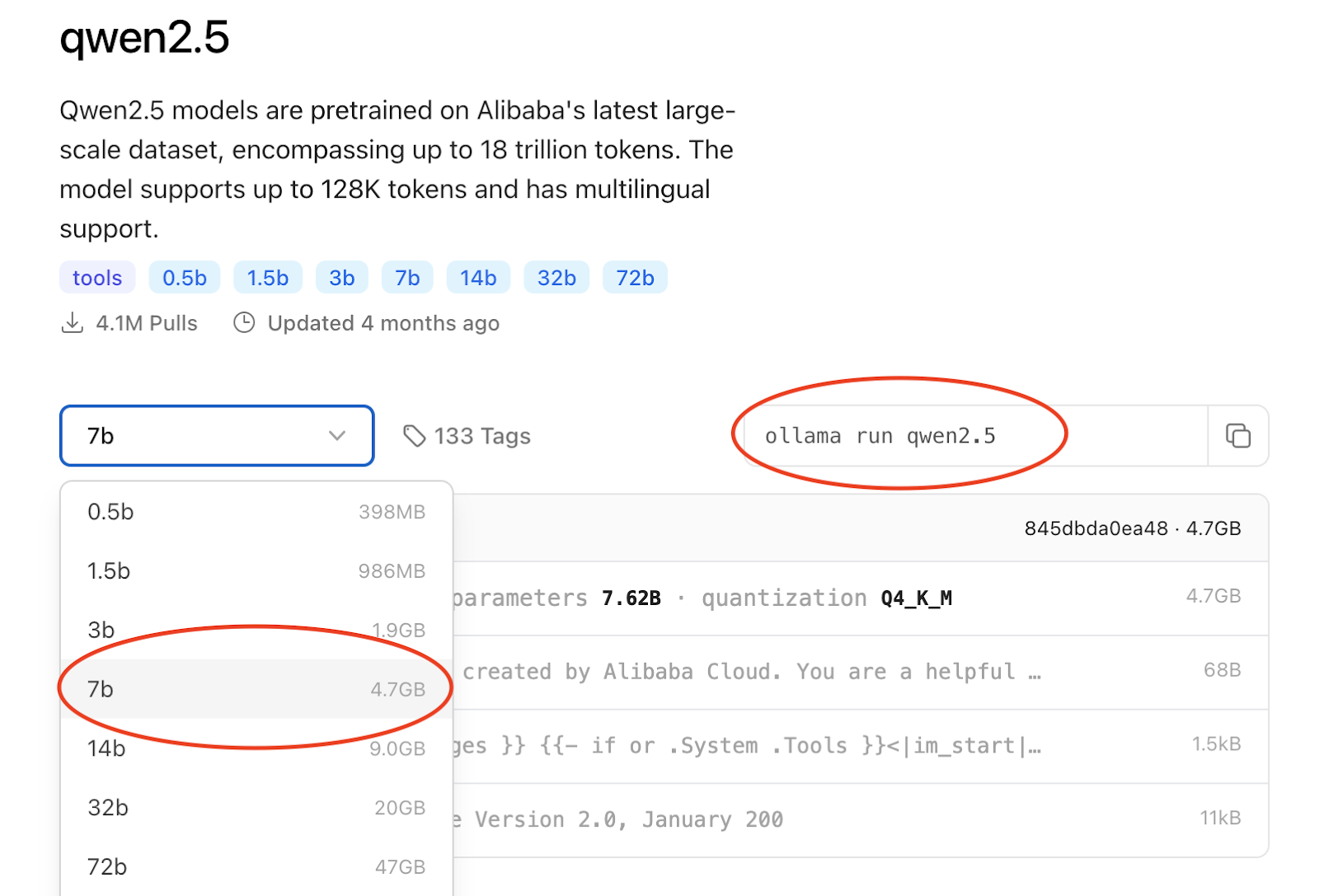
Nach Abschluss des Downloads können Sie zu Python übergehen und Code schreiben.
import ollama
llm = "qwen2.5"Testen wir die LLM:
stream = ollama.generate(mannequin=llm, immediate=""'what time is it?''', stream=True)
for chunk in stream:
print(chunk('response'), finish='', flush=True)
Offensichtlich ist das LLM per se sehr begrenzt und kann nicht viel zu plaudern. Daher müssen wir ihm die Möglichkeit geben, Maßnahmen zu ergreifen oder mit anderen Worten, um Werkzeuge aktivieren.
Eines der häufigsten Werkzeuge ist die Fähigkeit zu Suchen Sie im Web. In Python ist der einfachste Weg, dies zu tun, mit dem berühmten privaten Browser Duckduckgo (pip set up duckduckgo-search==6.3.5). Sie können die ursprüngliche Bibliothek direkt verwenden oder die importieren Langchain Wrapper (pip set up langchain-community==0.3.17).
Mit OllamaUm ein Device zu verwenden, muss die Funktion in einem Wörterbuch beschrieben werden.
from langchain_community.instruments import DuckDuckGoSearchResults
def search_web(question: str) -> str:
return DuckDuckGoSearchResults(backend="information").run(question)
tool_search_web = {'sort':'perform', 'perform':{
'title': 'search_web',
'description': 'Search the online',
'parameters': {'sort': 'object',
'required': ('question'),
'properties': {
'question': {'sort':'str', 'description':'the subject or topic to go looking on the net'},
}}}}
## check
search_web(question="nvidia")
Web -Suchanfragen könnten sehr breit sein, und ich möchte dem Agenten die Choice geben, präziser zu sein. Nehmen wir an, ich aircraft, diesen Agenten zu nutzen, um über finanzielle Updates zu erfahren, damit ich ihm ein bestimmtes Device für dieses Thema geben kann, z. B. nur eine Finanzwebsite anstelle des gesamten Webs zu durchsuchen.
def search_yf(question: str) -> str:
engine = DuckDuckGoSearchResults(backend="information")
return engine.run(f"web site:finance.yahoo.com {question}")
tool_search_yf = {'sort':'perform', 'perform':{
'title': 'search_yf',
'description': 'Seek for particular monetary information',
'parameters': {'sort': 'object',
'required': ('question'),
'properties': {
'question': {'sort':'str', 'description':'the monetary subject or topic to go looking'},
}}}}
## check
search_yf(question="nvidia")
Einfacher Agent (WebSearch)
Meiner Meinung nach sollte der grundlegendste Agent zumindest in der Lage sein, zwischen ein oder zwei Instruments zu wählen und die Ausgabe der Aktion erneut auszugeben, um dem Benutzer eine ordnungsgemäße und prägnante Antwort zu geben.
Zunächst müssen Sie eine Aufforderung schreiben, um den Zweck des Agenten zu beschreiben, desto detaillierter (meine ist sehr allgemein), und das ist die erste Nachricht im Chat -Verlauf mit dem LLM.
immediate=""'You're an assistant with entry to instruments, you have to resolve when to make use of instruments to reply person message.'''
messages = ({"position":"system", "content material":immediate})Um den Chat mit der KI am Leben zu erhalten, werde ich eine Schleife verwenden, die mit der Eingabe des Benutzers beginnt, und dann wird der Agent angerufen, um zu antworten (der ein Textual content aus der LLM oder die Aktivierung eines Instruments sein kann).
whereas True:
## person enter
attempt:
q = enter('🙂 >')
besides EOFError:
break
if q == "give up":
break
if q.strip() == "":
proceed
messages.append( {"position":"person", "content material":q} )
## mannequin
agent_res = ollama.chat(
mannequin=llm,
instruments=(tool_search_web, tool_search_yf),
messages=messages)Bis zu diesem Zeitpunkt könnte der Chat -Geschichte ungefähr so aussehen:

Wenn das Modell ein Device verwenden möchte, muss die entsprechende Funktion mit den vom LLM in seinem Antwortobjekt vorgeschlagenen Eingabeparametern ausgeführt werden:
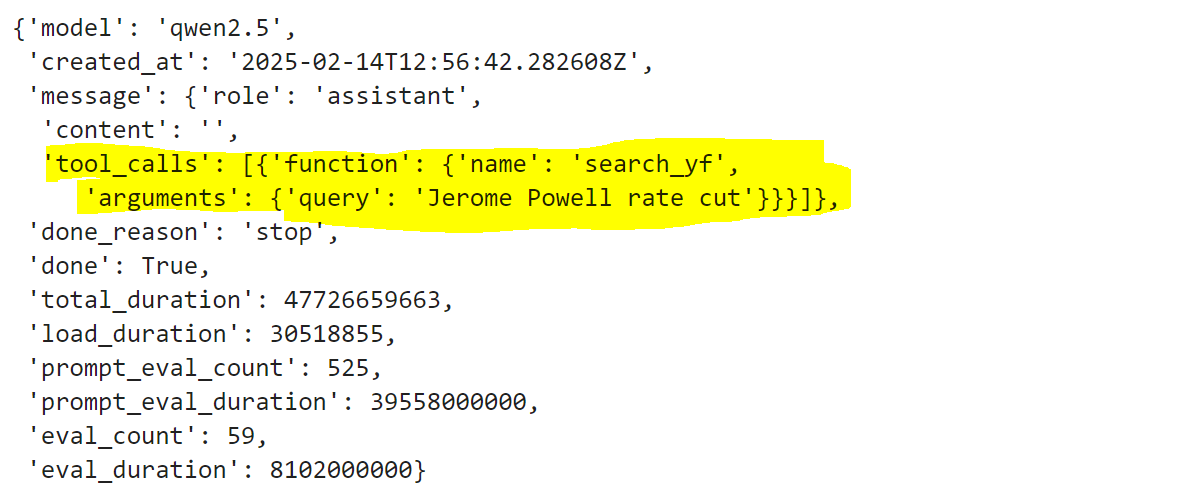
Daher muss unser Code diese Informationen abrufen und die Toolfunktion ausführen.
## response
dic_tools = {'search_web':search_web, 'search_yf':search_yf}
if "tool_calls" in agent_res("message").keys():
for instrument in agent_res("message")("tool_calls"):
t_name, t_inputs = instrument("perform")("title"), instrument("perform")("arguments")
if f := dic_tools.get(t_name):
### calling instrument
print('🔧 >', f"x1b(1;31m{t_name} -> Inputs: {t_inputs}x1b(0m")
messages.append( {"position":"person", "content material":"use instrument '"+t_name+"' with inputs: "+str(t_inputs)} )
### instrument output
t_output = f(**instrument("perform")("arguments"))
print(t_output)
### ultimate res
p = f'''Summarize this to reply person query, be as concise as doable: {t_output}'''
res = ollama.generate(mannequin=llm, immediate=q+". "+p)("response")
else:
print('🤬 >', f"x1b(1;31m{t_name} -> NotFoundx1b(0m")
if agent_res('message')('content material') != '':
res = agent_res("message")("content material")
print("👽 >", f"x1b(1;30m{res}x1b(0m")
messages.append( {"position":"assistant", "content material":res} )Wenn wir den vollständigen Code ausführen, können wir mit unserem Agenten chatten.

Erweiterter Agent (Codierung)
LLMs wissen, wie man codiert, indem sie einem großen Korpus von Code- und natürlicher Sprachtext ausgesetzt sind, in dem sie Muster, Syntax und Semantik lernen Programmierung Sprachen. Das Modell lernt die Beziehungen zwischen verschiedenen Teilen des Codes, indem es das nächste Token in einer Sequenz vorhergesagt. Kurz gesagt, LLMs können Python -Code generieren, können ihn jedoch nicht ausführen, Agenten können.
Ich werde ein Device vorbereiten, das dem Agenten erlaubt, um zu Code ausführen. In Python können Sie problemlos eine Shell erstellen, um Code als Zeichenfolge mit dem nativen Befehl auszuführen exec ().
import io
import contextlib
def code_exec(code: str) -> str:
output = io.StringIO()
with contextlib.redirect_stdout(output):
attempt:
exec(code)
besides Exception as e:
print(f"Error: {e}")
return output.getvalue()
tool_code_exec = {'sort':'perform', 'perform':{
'title': 'code_exec',
'description': 'execute python code',
'parameters': {'sort': 'object',
'required': ('code'),
'properties': {
'code': {'sort':'str', 'description':'code to execute'},
}}}}
## check
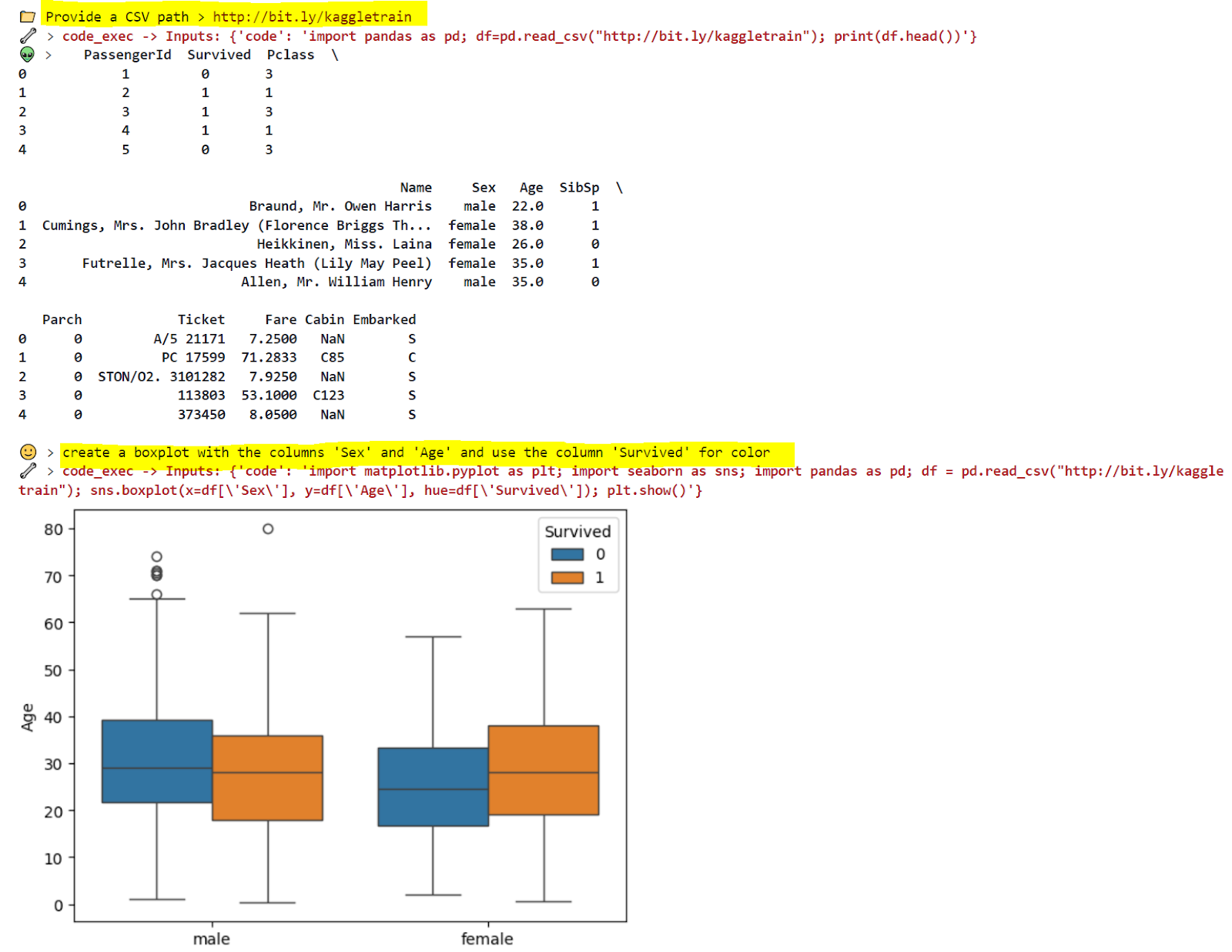
code_exec("a=1+1; print(a)")Genau wie zuvor werde ich eine Eingabeaufforderung schreiben, aber diesmal zu Beginn der Chat-Schleife werde ich den Benutzer bitten, einen Dateipfad bereitzustellen.
immediate=""'You're an knowledgeable knowledge scientist, and you've got instruments to execute python code.
To begin with, execute the next code precisely as it's: 'df=pd.read_csv(path); print(df.head())'
Should you create a plot, ALWAYS add 'plt.present()' on the finish.
'''
messages = ({"position":"system", "content material":immediate})
begin = True
whereas True:
## person enter
attempt:
if begin is True:
path = enter('📁 Present a CSV path >')
q = "path = "+path
else:
q = enter('🙂 >')
besides EOFError:
break
if q == "give up":
break
if q.strip() == "":
proceed
messages.append( {"position":"person", "content material":q} )Da Codierungsaufgaben für LLMs etwas schwieriger sein können, werde ich auch hinzufügen Speicherverstärkung. Standardmäßig gibt es während einer Sitzung keinen echten Langzeitgedächtnis. LLMs haben Zugriff auf den Chat -Verlauf, damit sie sich vorübergehend an Informationen erinnern und den Kontext und die Anweisungen verfolgen können, die Sie früher in der Konversation gegeben haben. Der Gedächtnis funktioniert jedoch nicht immer wie erwartet, insbesondere wenn die LLM klein ist. Eine gute Praxis besteht daher darin, das Gedächtnis des Modells zu verstärken, indem regelmäßige Erinnerungen in die Chat -Geschichte hinzugefügt werden.
immediate=""'You're an knowledgeable knowledge scientist, and you've got instruments to execute python code.
To begin with, execute the next code precisely as it's: 'df=pd.read_csv(path); print(df.head())'
Should you create a plot, ALWAYS add 'plt.present()' on the finish.
'''
messages = ({"position":"system", "content material":immediate})
reminiscence = '''Use the dataframe 'df'.'''
begin = True
whereas True:
## person enter
attempt:
if begin is True:
path = enter('📁 Present a CSV path >')
q = "path = "+path
else:
q = enter('🙂 >')
besides EOFError:
break
if q == "give up":
break
if q.strip() == "":
proceed
## reminiscence
if begin is False:
q = reminiscence+"n"+q
messages.append( {"position":"person", "content material":q} )Bitte beachten Sie, dass die Standardspeicherlänge in Ollama 2048 Zeichen beträgt. Wenn Ihre Maschine es verarbeiten kann, können Sie es erhöhen, indem Sie die Anzahl ändern, wenn das LLM aufgerufen wird:
## mannequin
agent_res = ollama.chat(
mannequin=llm,
instruments=(tool_code_exec),
choices={"num_ctx":2048},
messages=messages)In dieser Usecase ist die Ausgabe des Agenten hauptsächlich Code und Daten, daher möchte ich nicht, dass die LLM die Antworten erneut auszieht.
## response
dic_tools = {'code_exec':code_exec}
if "tool_calls" in agent_res("message").keys():
for instrument in agent_res("message")("tool_calls"):
t_name, t_inputs = instrument("perform")("title"), instrument("perform")("arguments")
if f := dic_tools.get(t_name):
### calling instrument
print('🔧 >', f"x1b(1;31m{t_name} -> Inputs: {t_inputs}x1b(0m")
messages.append( {"position":"person", "content material":"use instrument '"+t_name+"' with inputs: "+str(t_inputs)} )
### instrument output
t_output = f(**instrument("perform")("arguments"))
### ultimate res
res = t_output
else:
print('🤬 >', f"x1b(1;31m{t_name} -> NotFoundx1b(0m")
if agent_res('message')('content material') != '':
res = agent_res("message")("content material")
print("👽 >", f"x1b(1;30m{res}x1b(0m")
messages.append( {"position":"assistant", "content material":res} )
begin = FalseWenn wir den vollständigen Code ausführen, können wir mit unserem Agenten chatten.
Abschluss
Dieser Artikel hat die grundlegenden Schritte des Erstellens von Agenten von Grund auf mit nur mit Ollama. Mit diesen Bausteinen sind Sie bereits ausgestattet, um Ihre eigenen Agenten für verschiedene Anwendungsfälle zu entwickeln.
Bleib dran für Teil 2wo wir tiefer in fortgeschrittenere Beispiele eintauchen.
Voller Code für diesen Artikel: Github
Ich hoffe es hat dir gefallen! Wenden Sie sich an mich, um mich für Fragen und Suggestions zu kontaktieren oder einfach Ihre interessanten Projekte zu teilen.
👉 Lassen Sie uns eine Verbindung herstellen 👈
