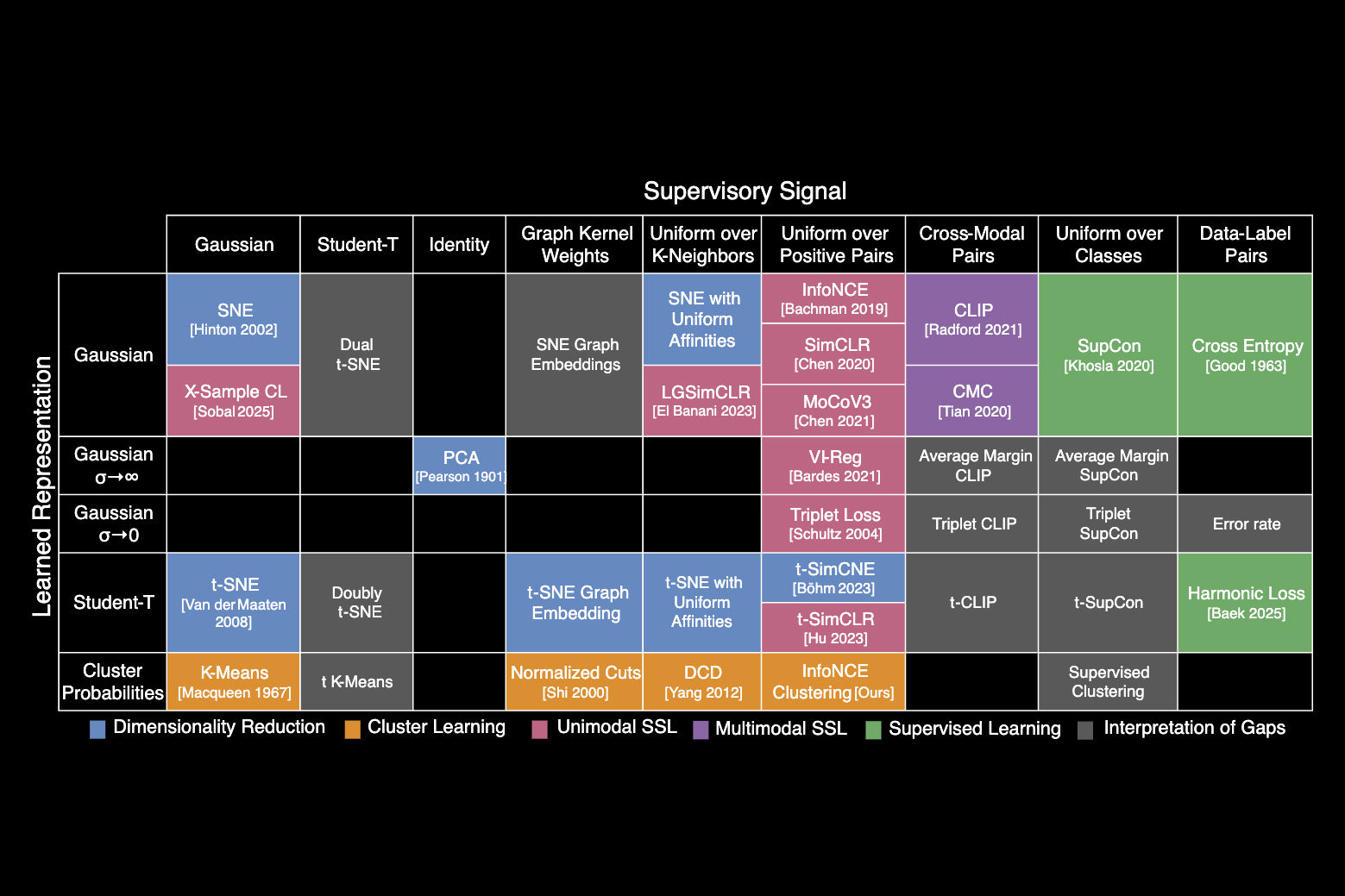
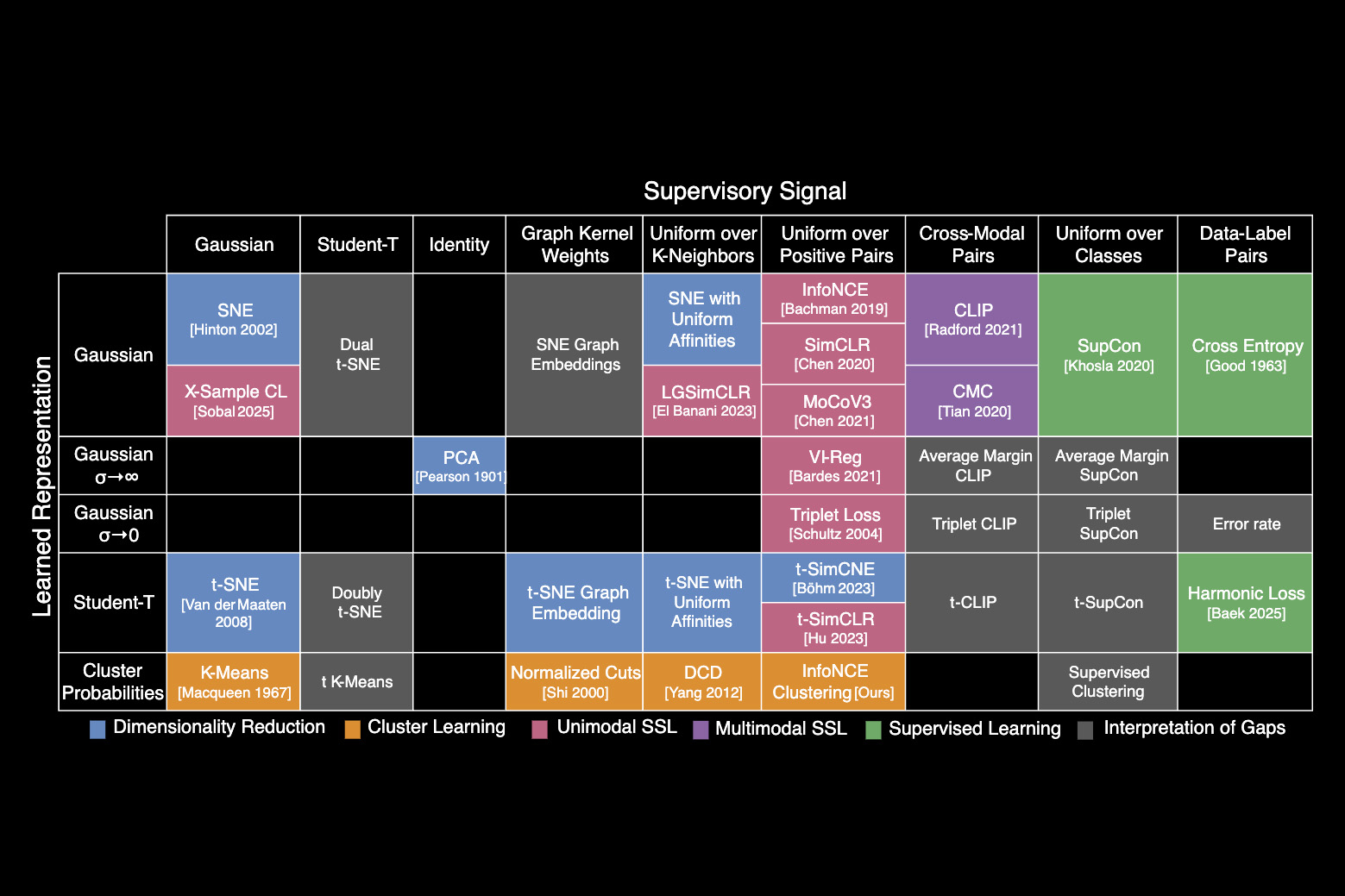
MIT-Forscher haben eine periodische Tabelle erstellt, die zeigt, wie mehr als 20 klassische Maschinenlernalgorithmen verbunden sind. Das neue Framework beleuchtet, wie Wissenschaftler Strategien aus verschiedenen Methoden zur Verbesserung vorhandener KI -Modelle oder neuen entwickeln können.
Beispielsweise verwendeten die Forscher ihren Rahmen, um Elemente von zwei verschiedenen Algorithmen zu kombinieren, um einen neuen Bildklassifizierungsalgorithmus zu erstellen, der 8 Prozent besser abfiel als aktuelle Stand der Technik.
Die Periodenzüchtertabelle stammt aus einer Schlüsselidee: Alle diese Algorithmen lernen eine bestimmte Artwork von Beziehung zwischen Datenpunkten. Während jeder Algorithmus dies auf etwas andere Weise erreichen kann, ist die Kernmathematik hinter jedem Ansatz gleich.
Aufbauend auf diesen Erkenntnissen identifizierten die Forscher eine einheitliche Gleichung, die vielen klassischen AI -Algorithmen zugrunde liegt. Sie verwendeten diese Gleichung, um beliebte Methoden neu zu gestalten und in eine Tabelle zu ordnen, wodurch sie jeweils auf den ungefähren Beziehungen kategorisiert wurden, die sie lernt.
Genau wie die periodische Tabelle chemischer Elemente, die zunächst leere Quadrate enthielt, die später von Wissenschaftlern ausgefüllt wurden, hat die periodische Tabelle des maschinellen Lernens auch leere Räume. Diese Räume sagen voraus, wo Algorithmen existieren sollen, die jedoch noch nicht entdeckt wurden.
Die Tabelle bietet Forschern ein Toolkit, um neue Algorithmen zu entwerfen, ohne Ideen aus früheren Ansätzen wiederzuentdecken, sagt Shadeden Alshammari, ein MIT -Doktorand und führender Autor von a Papier zu diesem neuen Rahmen.
„Es ist nicht nur eine Metapher“, fügt Alshammari hinzu. „Wir sehen maschinelles Lernen als ein System mit Struktur, der ein Raum ist, den wir erforschen können, anstatt uns nur durch den Weg zu erraten.“
Sie wird von John Hershey, einer Forscher bei Google AI Notion, auf der Zeitung begleitet. Axel Feldmann, ein MIT -Doktorand; William Freeman, Thomas und Gerd Perkins Professor für Elektrotechnik und Informatik sowie Mitglied des Labors der Informatik und des künstlichen Intelligenz (CSAIL); und Senior -Autor Mark Hamilton, MIT -Doktorand und Senior Engineering Supervisor bei Microsoft. Die Forschung wird auf der Internationalen Konferenz über Lernrepräsentationen vorgestellt.
Eine zufällige Gleichung
Die Forscher wollten nicht eine regelmäßige Tabelle des maschinellen Lernens erstellen.
Nach dem Eintritt in das Freeman-Labor begann Alshammari, Clustering zu studieren, eine maschinelle Lerntechnik, die Bilder klassifiziert, indem er lernt, ähnliche Bilder in nahe gelegene Cluster zu organisieren.
Sie erkannte, dass der Clustering-Algorithmus, den sie studierte, einem anderen klassischen maschinenlernenden Algorithmus, der als kontrastives Lernen bezeichnet wurde, ähnlich battle, und begann tiefer in die Mathematik zu graben. Alshammari stellte fest, dass diese beiden unterschiedlichen Algorithmen mit derselben zugrunde liegenden Gleichung neu gestaltet werden konnten.
„Wir sind zufällig zu dieser einheitlichen Gleichung gekommen. Sobald Shadeden entdeckte, dass zwei Methoden miteinander verbunden sind, haben wir gerade neue Methoden ausgedacht, um in diesen Rahmen einzusteigen. Quick jeder einzelne, den wir ausprobiert haben, konnte hinzugefügt werden“, sagt Hamilton.
Das von ihnen erstellte Framework, Informationskontrastive Lernen (I-Con), zeigt, wie eine Vielzahl von Algorithmen durch die Linse dieser einheitlichen Gleichung betrachtet werden kann. Es umfasst alles, von Klassifizierungsalgorithmen, die Spam bis hin zu den Deep -Lern -Algorithmen erkennen können, die LLMs betreiben.
Die Gleichung beschreibt, wie solche Algorithmen Verbindungen zwischen realen Datenpunkten finden und dann diese Verbindungen intern annähern.
Jeder Algorithmus zielt darauf ab, die Abweichung zwischen den Verbindungen zu minimieren, die er lernt, die annähernd und die tatsächlichen Verbindungen in seinen Trainingsdaten zu sein.
Sie beschlossen, I-Con in eine periodische Tabelle zu organisieren, um Algorithmen zu kategorisieren, basierend darauf, wie Punkte in realen Datensätzen verbunden sind, und die primären Möglichkeiten, wie Algorithmen diese Verbindungen anpassen können.
„Die Arbeit verlief schrittweise, aber als wir die allgemeine Struktur dieser Gleichung identifiziert hatten, battle es einfacher, unserem Rahmen mehr Methoden hinzuzufügen“, sagt Alshammari.
Ein Werkzeug zur Entdeckung
Als sie den Tisch arrangierten, begannen die Forscher, Lücken zu sehen, in denen Algorithmen existieren konnten, aber noch nicht erfunden worden waren.
Die Forscher füllten eine Lücke aus, indem sie Ideen aus einer maschinellen Lerntechnik ausleihen, die als kontrastives Lernen bezeichnet wird und sie auf das Bildclustering anwenden. Dies führte zu einem neuen Algorithmus, der unbezeichnete Bilder um 8 Prozent besser klassifizieren konnte als ein weiterer Stand der Technik.
Sie verwendeten auch die I-Con, um zu zeigen, wie eine Datendebiasing-Technik für kontrastives Lernen verwendet werden konnte, um die Genauigkeit von Clustering-Algorithmen zu steigern.
Darüber hinaus können Forscher mit der flexiblen Periodentabelle neue Zeilen und Spalten hinzufügen, um zusätzliche Arten von Datenpunktverbindungen darzustellen.
Letztendlich könnte die I-Con als Leitfaden dazu beitragen, Wissenschaftler für maschinelles Lernen über den Tellerrand hinaus zu denken und sie zu ermutigen, Ideen auf eine Weise zu kombinieren, an die sie nicht unbedingt gedacht hätten, sagt Hamilton.
„Wir haben gezeigt, dass nur eine sehr elegante Gleichung, die in der Wissenschaft der Data verwurzelt ist, reichhaltige Algorithmen über 100 Jahre Forschung im maschinellen Lernen gibt. Dies eröffnet viele neue Wege für die Entdeckung“, fügt er hinzu.
„Der vielleicht schwierigste Aspekt, heutzutage ein maschinell-lernender Forscher zu sein, ist die scheinbar unbegrenzte Anzahl von Papieren, die jedes Jahr auftreten. In diesem Zusammenhang sind Papiere, die vorhandene Algorithmen vereinen und verbinden, von großer Bedeutung. Sie sind äußerst selten. I-Con liefert ein hervorragendes Beispiel für einen einheitlichen Ansatz und wird hoffentlich andere inspirieren. Die hebräische Universität von Jerusalem, die nicht an dieser Forschung beteiligt battle.
Diese Forschung wurde zum Teil durch die Air Pressure Synthetic Intelligence Accelerator, das AI Institute für künstliche Intelligenz und grundlegende Interaktionen der Nationwide Science Basis sowie das Quanta -Laptop finanziert.