veröffentlichte eine Demo ihres neuesten Sprachmodells. Ein Konversations -KI -Agent, der ist Wirklich Intestine im Sprechen, sie geben relevante Antworten, sie sprechen mit Ausdrücken und sind ehrlich gesagt sehr lustig und interaktiv zu spielen.
Beachten Sie, dass ein technisches Papier noch nicht herauskommt, aber eine haben eine Kurzer Weblog -Beitrag Dies liefert viele Informationen zu den von ihnen verwendeten Techniken und früheren Algorithmen, auf denen sie aufgebaut sind.
Zum Glück lieferten sie genügend Informationen, um diesen Artikel zu schreiben und eine zu machen YouTube Video aus dem heraus. Lesen Sie weiter!
Schulung eines Konversationssprachmodells
Sesam ist a Konversationssprachmodelloder ein CSM. Es gibt sowohl Textual content als auch Audio ein und generiert Sprache als Audio. Obwohl sie ihre Trainingsdatenquellen in den Artikeln nicht enthüllt haben, können wir immer noch versuchen, eine solide Vermutung zu erraten. Der Weblog -Beitrag zitiert stark ein weiteres CSM, 2024 Moshiund zum Glück enthüllten die Macher von Moshi ihre Datenquellen in ihren Papier. Moshi verwendet 7 Millionen Stunden von unbeaufsichtigten Sprachdaten, 170 Stunden von natürlichen und geschriebenen Gesprächen (für das mehrstreamische Coaching) und 2000 weitere Stunden von Telefongesprächen (Fischer -Datensatz).

Aber was braucht es wirklich, um Audio zu generieren?
In Rohform ist Audio nur eine lange Abfolge von Amplitudenwerten– eine Wellenform. Wenn Sie beispielsweise Audio bei 24 kHz probieren, erfassen Sie jede Sekunde 24.000 Float -Werte.

Natürlich ist es ziemlich ressourcenintensiv, 24000 Float-Werte für nur eine Sekunde Daten zu verarbeiten vor allem, weil Transformator berechnet, quadratisch mit der Sequenzlänge skalieren. Es wäre großartig, wenn wir dieses Sign komprimieren und die Anzahl der zur Verarbeitung des Audio erforderlichen Proben reduzieren könnten.
Wir werden einen tiefen Eintauchen in die Mimi -Encoderund speziell Restvektorquantizer (RVQ)die das Rückgrat der Audio-/Sprachmodellierung in sind Tiefes Lernen Heute. Wir werden den Artikel beenden, indem wir erfahren, wie Sesame mit seiner speziellen Doppeltransformer-Architektur Audio generiert.
Vorverarbeitung von Audio
Komprimierende und Merkmalextraktion hilft uns mit der Faltung. Sesam verwendet den Mimi -Sprachcodierer, um Audio zu verarbeiten. Mimi wurde in die oben genannten Einführung eingeführt Moshi -Papier sowie . Mimi ist ein selbstbewertetes Audio-Encoder-Decoder-Modell, das Audiowellenformen zuerst in diskrete „latente“ Token umwandelt und dann das ursprüngliche Sign rekonstruiert. Sesam verwendet nur den Encoder -Abschnitt von Mimi, um die Eingabe -Audio -Token zu tokenisieren. Lassen Sie uns lernen, wie.
MIMI gibt die rohe Sprachwellenform bei 24 kHz ein, führt sie durch mehrere Fahrschichten durch, um das Sign mit einem Schrittfaktor von 4, 5, 6, 8 und 2. zu verkleinern. Dies bedeutet, dass der erste CNN -Block die Audio um 4x, dann 5x, dann 6x und so weiter abnimmt. Am Ende verkleinert es sich um den Faktor von 1920 und reduzierte es auf nur 12,5 Bilder professional Sekunde.
Die Faltungsblöcke projizieren auch die ursprünglichen Float -Werte in eine Einbettungsdimension von 512. Die Einbettung aggregiert die lokalen Merkmale der ursprünglichen 1D -Wellenform. 1 Sekunde Audio wird jetzt als etwa 12 Vektoren der Größe 512 dargestellt. Auf diese Weise reduziert Mimi die Sequenzlänge von 24000 auf nur 12 und wandelt sie in dichte kontinuierliche Vektoren um.

Was ist Audioquantisierung?
Angesichts der kontinuierlichen Einbettungen, die nach der Faltungsschicht erhalten wurden, möchten wir die Eingabemaßnahme ankündigen. Wenn wir Sprache als Abfolge von Token darstellen können, können wir Commonplace -Lerntransformatoren für Sprachlernen anwenden, um generative Modelle zu trainieren.
Mimi verwendet a Restvektorquantizer oder RVQ -TokenizerUm dies zu erreichen. Wir werden bald über den Restteil sprechen, aber zuerst schauen wir uns an, was ein einfacher Vanillevektorquantizer tut.
Vektorquantisierung
Die Idee hinter der Vektorquantisierung ist einfach: Sie schulen ein Codebuch, bei dem es sich um eine Sammlung von 1000 zufälligen Vektor -Codes handelt, die alle Größe 512 (wie Ihre Einbettungsdimension) codiert.

Angesichts des Eingangsvektors werden wir ihn dann dem nächstgelegenen Vektor in unserem Codebuch zuordnen und im Grunde genommen einen Punkt in das nächste Cluster -Middle einstellen. Dies bedeutet, dass wir effektiv ein festes Vokabular von Token erstellt haben, um jeden Audio -Rahmen darzustellen, da wir sie auch mit dem nächsten Cluster -Zentroid darstellen können. Wenn Sie mehr über die Vektorquantisierung erfahren möchten, lesen Sie mein Video zu diesem Thema, wo ich viel tiefer bin.
https://www.youtube.com/watch?v=ezdsRevdgnq
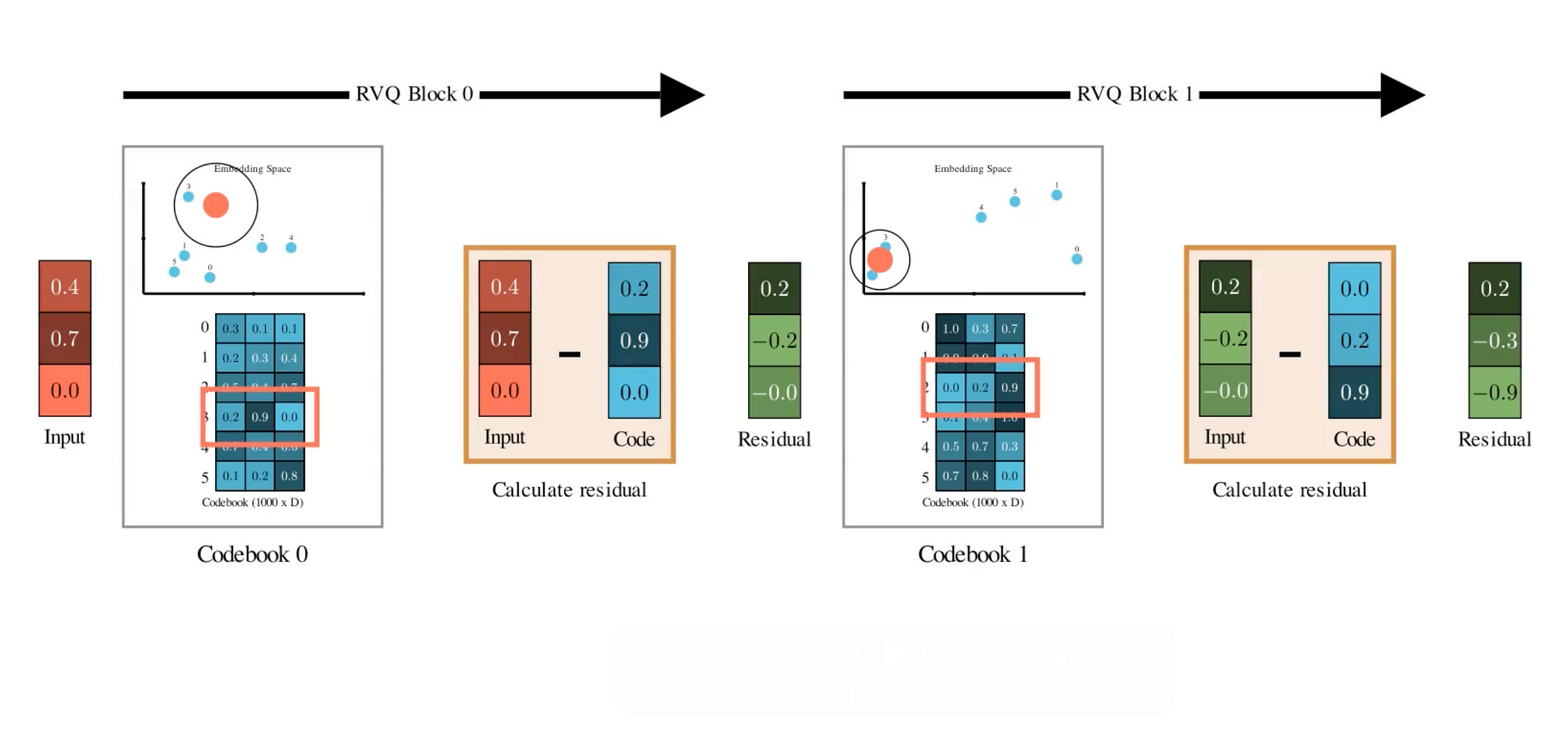
Restvektorquantisierung
Das Drawback bei der einfachen Vektorquantisierung ist, dass der Informationsverlust möglicherweise zu hoch ist, da wir jeden Vektor auf den Schwerpunkt seines Clusters abbilden. Das „Snap“ ist selten perfekt, daher gibt es immer einen Fehler zwischen der ursprünglichen Einbettung und dem nächsten Codebuch.
Die große Idee von Restvektorquantisierung ist, dass es nicht hört, nur ein Codebuch zu haben. Stattdessen versucht es mehrere Codebücher, um den Eingabevektor darzustellen.
- ErsteSie quantisieren den ursprünglichen Vektor mit dem ersten Codebuch.
- DannSie subtrahieren Sie diesen Schwerpunkt von Ihrem ursprünglichen Vektor. Was Sie übrig sind, ist das Relaxation – Der Fehler, der in der ersten Quantisierung nicht erfasst wurde.
- Nehmen Sie jetzt diesen Relaxation und Quantisieren Sie es erneut mit a Zweites Codebuch voller brandneuer Codevektoren– Noch einmal, indem Sie es zum nächsten Schwerpunkt schnappen.
- Subtrahieren Das Auch, und Sie bekommen einen kleineren Relaxation. Quantisieren Sie erneut mit einem dritten Codebuch… und Sie können dies für so viele Codebücher wie gewünscht fortsetzen.

Jeder Schritt wird hierarchisch ein wenig mehr Particulars erfassen, das in der vorherigen Runde übersehen wurde. Wenn Sie dies, beispielsweise n Codebücher, wiederholen, erhalten Sie eine Sammlung von n diskreten Token aus jeder Quantisierungsphase, um einen Audio -Rahmen darzustellen.
Das Coolste an RVQs ist, dass sie eine hohe induktive Tendenz zur Erfassung des wichtigsten Inhalts im allerersten Quantisierer haben. In den nachfolgenden Quantizern lernen sie immer mehr feinkörnige Merkmale.
Wenn Sie mit PCA vertraut sind, können Sie sich das erste Codebuch als die wichtigsten Hauptkomponenten vorstellen und die kritischsten Informationen erfassen. Die nachfolgenden Codebücher stellen Komponenten höherer Ordnung dar, die Informationen enthalten, die weitere Particulars hinzufügen.

Akustische gegen semantische Codebücher
Da Mimi durch die Aufgabe der Audiorekonstruktion trainiert wird, komprimiert der Encoder das Sign auf den diskretisierten latenten Raum, und der Decoder rekonstruiert es aus dem latenten Raum zurück. Bei der Optimierung für diese Aufgabe lernen die RVQ -Codebücher, den wesentlichen akustischen Inhalt des Eingabe -Audio im komprimierten latenten Raum zu erfassen.
Mimi trainiert auch separat ein einzelnes Codebuch (Vanilla VQ), das sich nur auf die Einbettung des semantischen Inhalts des Audios konzentriert. Deshalb Mimi wird als Cut up-RVQ-Tokenizer bezeichnet– Es unterteilt den Quantisierungsprozess in zwei unabhängige parallele Pfade: einen für semantische Informationen und eine für akustische Informationen.

Um semantische Darstellungen auszubilden, verwendete MIMI Wissensdestillation mit einem vorhandenen Sprachmodell namens WAVLM als semantischer Lehrer. Grundsätzlich führt Mimi eine zusätzliche Verlustfunktion ein, die den Kosinusabstand zwischen dem semantischen RVQ-Code und der WAVLM-generierten Einbettung verringert.
Audio -Decoder
Bei einer Konversation mit Textual content und Audio konvertieren wir sie zunächst in eine Abfolge von Token -Einbettungen mit den Textual content- und Audio -Tokenizern. Diese Token -Sequenz wird dann als Zeitreihe in ein Transformatormodell eingegeben. Im Weblog -Beitrag wird dieses Modell als autoregressiven Spine -Transformator bezeichnet. Seine Aufgabe ist es, diese Zeitreihe zu verarbeiten und das Codebuch -Token „Nuloth“ auszugeben.
Ein leichter Gewicht Transformator namens Audio Decoder rekonstruiert dann die nächsten Codebuch -Token, die auf diesen vom Spine -Transformator generierten Ningeoth -Code konditioniert sind. Beachten Sie, dass der Nuloth -Code bereits viele Informationen über die Geschichte der Konversation enthält, da der Spine -Transformator die gesamte vergangene Sequenz über die Sichtbarkeit verfügt. Der leichte Audiodecoder arbeitet nur am Nullen-Token und generiert das andere N-1Codes. Diese Codes werden unter Verwendung von n-1-unterschiedlichen linearen Schichten generiert, die die Wahrscheinlichkeit ausgeben, jeden Code aus ihren entsprechenden Codebüchern auszuwählen.
Sie können sich vorstellen, dass dieser Prozess einen Textual content-Token aus dem Wortschatz in einem LLM nur Textual content vorhersagt. Nur dass ein textbasiertes LLM ein einzelnes Vokabular hat, aber der RVQ-Tokenizer hat mehrere Vokabularien in Type der N-Codebücher, sodass Sie eine separate lineare Ebene trainieren müssen, um die Codes für jeden zu modellieren.

Nachdem die Codewörter alle generiert sind, werden sie schließlich zusammengefasst, um die kombinierte kontinuierliche Audioeinbettung zu bilden. Die letzte Aufgabe besteht darin, dieses Audio wieder in eine Wellenform umzuwandeln. Zu diesem Zweck wenden wir transponierte Faltungsschichten an, um die Einbettung von 12,5 Hz zurück zum KHz -Wellenform -Audio zu verbessern. Grundsätzlich Umkehrung der Transformationen, die wir ursprünglich während der Audiovorverarbeitung angewendet hatten.
Zusammenfassend
https://www.youtube.com/watch?v=thg9ebbmhp8
Hier ist additionally die Gesamtübersicht des Sesammodells in einigen Kugelpunkten.
- Sesam basiert auf einem multimodalen Gesprächssprachmodell oder einem CSM.
- Textual content und Audio werden zusammen tokenisiert, um eine Abfolge von Token zu bilden und in den Rückgrattransformator einzugeben, der die Sequenz autoregressiv verarbeitet.
- Während der Textual content wie jedes andere textbasierte LLM verarbeitet wird, wird das Audio direkt aus seiner Wellenformdarstellung verarbeitet. Sie verwenden den Mimi -Encoder, um die Wellenform mit einem geteilten RVQ -Tokenizer in latente Codes umzuwandeln.
- Die multimodalen Spine -Transformatoren konsumieren eine Sequenz von Token und prognostizieren das nächste Nullen -Codewort.
- Ein weiterer leichter Transformator namens Audio Decoder sagt die nächsten Codewors aus dem Nuloth Codewort voraus.
- Die endgültige Audio -Body -Darstellung erzeugt aus der Kombination aller erzeugten Codewors und upsplediert an die Wellenformdarstellung.
Danke fürs Lesen!
Referenzen und Should-Learn-Papiere
Schauen Sie sich meinen ML YouTube -Kanal an
Relevante Papiere:
Moshi: https://arxiv.org/abs/2410.00037
Soundstream: https://arxiv.org/abs/2107.03312
Hubert: https://arxiv.org/abs/2106.07447
Sprach -Tokenizer: https://arxiv.org/abs/2308.16692