

Bild vom Autor
Gute Python- und SQL-Kenntnisse sind für viele Datenexperten unverzichtbar. Als Datenexperte sind Sie wahrscheinlich mit der Python-Programmierung vertraut – so intestine, dass Ihnen das Schreiben von Python-Code ganz natürlich vorkommt. Aber befolgen Sie die Finest Practices, wenn Sie mit Python an Information-Science-Projekten arbeiten?
Obwohl es einfach ist, Python zu lernen und damit Information Science-Anwendungen zu erstellen, ist es vielleicht einfacher, Code zu schreiben, der schwer zu warten ist. Um Ihnen beim Schreiben besseren Codes zu helfen, untersucht dieses Tutorial einige bewährte Methoden für die Python-Codierung, die bei der Abhängigkeitsverwaltung und Wartbarkeit helfen, wie zum Beispiel:
- Einrichten dedizierter virtueller Umgebungen für die lokale Arbeit an Information-Science-Projekten
- Verbessern der Wartbarkeit durch Typhinweise
- Modellieren und Validieren von Daten mit Pydantic
- Profilierungscode
- Verwenden Sie nach Möglichkeit vektorisierte Operationen
Additionally, fangen wir an zu programmieren!
1. Verwenden Sie virtuelle Umgebungen für jedes Projekt
Virtuelle Umgebungen stellen sicher, dass Projektabhängigkeiten isoliert sind, wodurch Konflikte zwischen verschiedenen Projekten vermieden werden. In der Datenwissenschaft, wo Projekte oft unterschiedliche Bibliotheken und Versionen umfassen, sind virtuelle Umgebungen besonders nützlich, um die Reproduzierbarkeit aufrechtzuerhalten und Abhängigkeiten effektiv zu verwalten.
Darüber hinaus erleichtern virtuelle Umgebungen den Mitarbeitern das Einrichten derselben Projektumgebung, ohne sich um widersprüchliche Abhängigkeiten sorgen zu müssen.
Sie können Instruments wie Poetry verwenden, um virtuelle Umgebungen zu erstellen und zu verwalten. Die Verwendung von Poetry bietet viele Vorteile. Wenn Sie jedoch nur virtuelle Umgebungen für Ihre Projekte erstellen möchten, können Sie auch das integriertes Venv-Modul.
Wenn Sie einen Linux-Rechner (oder einen Mac) verwenden, können Sie virtuelle Umgebungen wie folgt erstellen und aktivieren:
# Create a digital surroundings for the venture
python -m venv my_project_env
# Activate the digital surroundings
supply my_project_env/bin/activate
Wenn Sie ein Home windows-Benutzer sind, können Sie Überprüfen Sie die Dokumente Informationen zum Aktivieren der virtuellen Umgebung. Die Verwendung virtueller Umgebungen für jedes Projekt ist daher hilfreich, um Abhängigkeiten isoliert und konsistent zu halten.
2. Fügen Sie Typhinweise zur Wartbarkeit hinzu
Da Python eine dynamisch typisierte Sprache ist, müssen Sie den Datentyp für die Variablen, die Sie erstellen, nicht angeben. Sie können jedoch Typhinweise hinzufügen, die den erwarteten Datentyp angeben, um Ihren Code wartungsfreundlicher zu gestalten.
Betrachten wir als Beispiel eine Funktion, die den Mittelwert eines numerischen Merkmals in einem Datensatz mit entsprechenden Typanmerkungen berechnet:
from typing import Checklist
def calculate_mean(characteristic: Checklist(float)) -> float:
# Calculate imply of the characteristic
mean_value = sum(characteristic) / len(characteristic)
return mean_value
Hier informieren die Typhinweise den Benutzer darüber, dass calcuate_mean Die Funktion nimmt eine Liste von Gleitkommazahlen auf und gibt einen Gleitkommawert zurück.
Denken Sie daran, dass Python zur Laufzeit keine Typen erzwingt. Sie können jedoch mypy oder ähnliches verwenden, um Fehler für ungültige Typen zu melden.
3. Modellieren Sie Ihre Daten mit Pydantic
Zuvor haben wir über das Hinzufügen von Typhinweisen gesprochen, um den Code wartungsfreundlicher zu machen. Dies funktioniert intestine für Python-Funktionen. Wenn Sie jedoch mit Daten aus externen Quellen arbeiten, ist es oft hilfreich, die Daten zu modellieren, indem Sie Klassen und Felder mit dem erwarteten Datentyp definieren.
Sie können integrierte Datenklassen in Python verwenden, aber Sie erhalten keine standardmäßige Unterstützung für die Datenvalidierung. Mit Pydantic können Sie Ihre Daten modellieren und auch die integrierten Datenvalidierungsfunktionen verwenden. Um Pydantic zu verwenden, können Sie es zusammen mit dem E-Mail-Validator mithilfe von pip installieren:
$ pip set up pydantic(email-validator)Hier ist ein Beispiel für die Modellierung von Kundendaten mit Pydantic. Sie können eine Modellklasse erstellen, die erbt von BaseModel und definieren Sie die verschiedenen Felder und Attribute:
from pydantic import BaseModel, EmailStr
class Buyer(BaseModel):
customer_id: int
identify: str
e mail: EmailStr
cellphone: str
deal with: str
# Pattern knowledge
customer_data = {
'customer_id': 1,
'identify': 'John Doe',
'e mail': 'john.doe@instance.com',
'cellphone': '123-456-7890',
'deal with': '123 Fundamental St, Metropolis, Nation'
}
# Create a buyer object
buyer = Buyer(**customer_data)
print(buyer)
Sie können dies noch weiter ausbauen, indem Sie eine Validierung hinzufügen, um zu prüfen, ob alle Felder gültige Werte haben. Wenn Sie ein Tutorial zur Verwendung von Pydantic benötigen – zum Definieren von Modellen und Validieren von Daten – lesen Sie Pydantic-Tutorial: Datenvalidierung in Python leicht gemacht.
4. Profilieren Sie den Code, um Leistungsengpässe zu identifizieren
Die Profilerstellung für Code ist hilfreich, wenn Sie die Leistung Ihrer Anwendung optimieren möchten. In Information Science-Projekten können Sie je nach Kontext die Speichernutzung und Ausführungszeiten profilieren.
Angenommen, Sie arbeiten an einem Machine-Studying-Projekt, bei dem die Vorverarbeitung eines großen Datensatzes ein entscheidender Schritt vor dem Trainieren Ihres Modells ist. Lassen Sie uns eine Funktion profilieren, die gängige Vorverarbeitungsschritte wie die Standardisierung anwendet:
import numpy as np
import cProfile
def preprocess_data(knowledge):
# Carry out preprocessing steps: scaling and normalization
scaled_data = (knowledge - np.imply(knowledge)) / np.std(knowledge)
return scaled_data
# Generate pattern knowledge
knowledge = np.random.rand(100)
# Profile preprocessing operate
cProfile.run('preprocess_data(knowledge)')
Wenn Sie das Skript ausführen, sollten Sie eine ähnliche Ausgabe sehen:
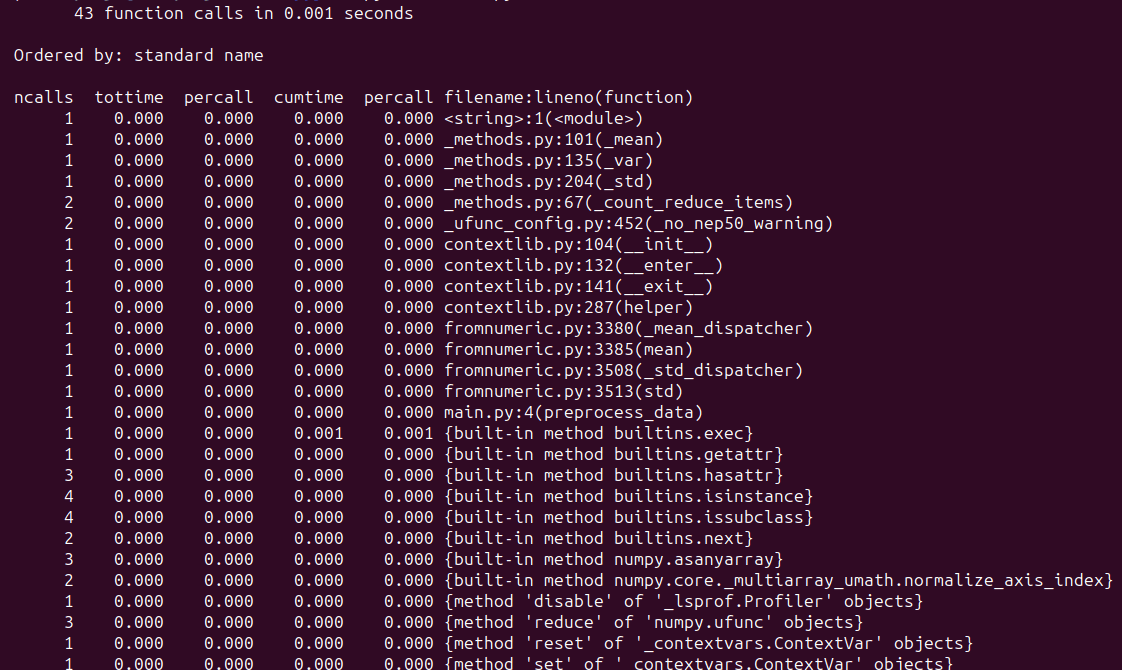
In diesem Beispiel profilieren wir die preprocess_data() Funktion, die Beispieldaten vorverarbeitet. Profiling hilft im Allgemeinen dabei, mögliche Engpässe zu identifizieren und Optimierungen zur Leistungssteigerung durchzuführen. Hier sind Tutorials zum Profiling in Python, die Sie vielleicht hilfreich finden:
5. Verwenden Sie die vektorisierten Operationen von NumPy
Für jede Datenverarbeitungsaufgabe können Sie jederzeit eine Python-Implementierung von Grund auf neu schreiben. Aber wenn Sie mit großen Zahlen-Arrays arbeiten, möchten Sie das vielleicht nicht tun. Für die meisten gängigen Operationen, die Sie ausführen müssen – die als Operationen an Vektoren formuliert werden können – können Sie NumPy verwenden, um sie effizienter auszuführen.
Betrachten wir das folgende Beispiel einer elementweisen Multiplikation:
import numpy as np
import timeit
# Set seed for reproducibility
np.random.seed(42)
# Array with 1 million random integers
array1 = np.random.randint(1, 10, measurement=1000000)
array2 = np.random.randint(1, 10, measurement=1000000)
Hier sind die reinen Python- und NumPy-Implementierungen:
# NumPy vectorized implementation for element-wise multiplication
def elementwise_multiply_numpy(array1, array2):
return array1 * array2
# Pattern operation utilizing Python to carry out element-wise multiplication
def elementwise_multiply_python(array1, array2):
consequence = ()
for x, y in zip(array1, array2):
consequence.append(x * y)
return consequence
Nutzen wir die timeit Funktion aus dem timeit Modul zum Messen der Ausführungszeiten für die obigen Implementierungen:
# Measure execution time for NumPy implementation
numpy_execution_time = timeit.timeit(lambda: elementwise_multiply_numpy(array1, array2), quantity=10) / 10
numpy_execution_time = spherical(numpy_execution_time, 6)
# Measure execution time for Python implementation
python_execution_time = timeit.timeit(lambda: elementwise_multiply_python(array1, array2), quantity=10) / 10
python_execution_time = spherical(python_execution_time, 6)
# Evaluate execution instances
print("NumPy Execution Time:", numpy_execution_time, "seconds")
print("Python Execution Time:", python_execution_time, "seconds")
Wir sehen, dass die NumPy-Implementierung etwa 100-mal schneller ist:
Output >>>
NumPy Execution Time: 0.00251 seconds
Python Execution Time: 0.216055 seconds
Einpacken
In diesem Tutorial haben wir einige bewährte Methoden für die Python-Codierung im Bereich Information Science untersucht. Ich hoffe, Sie fanden sie hilfreich.
Wenn Sie Python für die Datenwissenschaft lernen möchten, schauen Sie sich an 5 kostenlose Kurse Grasp Python für Information Science. Viel Spaß beim Lernen!
Bala Priya C ist Entwicklerin und technische Redakteurin aus Indien. Sie arbeitet gerne an der Schnittstelle zwischen Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Ihre Interessens- und Fachgebiete umfassen DevOps, Datenwissenschaft und Verarbeitung natürlicher Sprache. Sie liest, schreibt, programmiert und trinkt gerne Kaffee! Derzeit arbeitet sie daran, ihr Wissen zu lernen und mit der Entwickler-Group zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst. Bala erstellt auch ansprechende Ressourcenübersichten und Programmier-Tutorials.