
In unserem schnelllebigen digitalen Zeitalter ist der schnelle Zugriff auf die aktuellsten Informationen wichtiger denn je. Herkömmliche Quellen sind oft unzureichend, entweder weil sie veraltet sind oder einfach nicht verfügbar sind, wenn wir sie am meisten brauchen. Hier setzt das Konzept einer webbasierten Echtzeit-Agentic RAG-Anwendung an und bietet eine bahnbrechende Lösung. Durch die Nutzung der Fähigkeiten von LangChain Und LLMs für Sprachverständnis und Tavily Für die Integration von Webdaten in Echtzeit können Entwickler Anwendungen erstellen, die über die Einschränkungen statischer Datenbanken hinausgehen.
Dieser progressive Ansatz ermöglicht es der Anwendung, das Web nach den neuesten Informationen zu durchsuchen und sicherzustellen, dass Benutzer die relevantesten und aktuellsten Antworten auf ihre Fragen erhalten. Dabei handelt es sich um einen intelligenten Assistenten, der nicht nur mit vorinstallierten Informationen reagiert, sondern aktiv neue Daten in Echtzeit sucht und einbezieht. Dieser Artikel soll Sie durch die Entwicklung einer solchen Anwendung führen und potenzielle Herausforderungen wie die Wahrung der Genauigkeit und die Gewährleistung schneller Antworten ansprechen. Ziel ist es, den Zugang zu Informationen zu demokratisieren, sie so aktuell und zugänglich wie möglich zu machen und so die Barrieren für den Wissensschatz im Web zu beseitigen. Entdecken Sie gemeinsam mit uns, wie Sie einen KI-gestützten, webbasierten Agenten erstellen können RAG-Anwendung Damit haben Sie die Informationen der Welt immer zur Hand.

Lernziele
- Gewinnen Sie ein umfassendes Verständnis für den Aufbau eines hochmodernen Echtzeit-Agenten Retrieval-Augmented Era (RAG) Anwendung.
- Lernen Sie, fortschrittliche Technologien nahtlos in Ihre Anwendung zu integrieren.
Dieser Artikel wurde im Rahmen der veröffentlicht Information Science-Blogathon.
Was ist Agentic RAG und wie funktioniert es?
Agentic Retrieval-Augmented Era (RAG) ist ein fortschrittliches Framework, das mehrere Instruments zur Bewältigung komplexer Aufgaben koordiniert, indem es den Informationsabruf mit der Sprachgenerierung integriert. Dieses System verbessert die traditionelle RAG durch den Einsatz spezialisierter Instruments, die sich jeweils auf unterschiedliche Teilaufgaben konzentrieren, um genauere und kontextbezogenere Ergebnisse zu erzielen. Der Prozess beginnt mit der Zerlegung eines komplexen Issues in kleinere, überschaubare Teilaufgaben, wobei jedes Device einen bestimmten Aspekt der Aufgabe behandelt. Diese Instruments interagieren über einen gemeinsamen Speicher oder einen Nachrichtenübermittlungsmechanismus, sodass sie auf den Ergebnissen der anderen Instruments aufbauen und die Gesamtantwort verfeinern können.
Bestimmte Instruments sind mit Retrieval-Funktionen ausgestattet und ermöglichen den Zugriff auf externe Datenquellen wie Datenbanken oder das Web. Dadurch wird sichergestellt, dass die generierten Inhalte auf korrekten und aktuellen Informationen basieren. Nach der Bearbeitung ihrer jeweiligen Aufgaben kombinieren die Instruments ihre Ergebnisse, um eine kohärente und umfassende Endausgabe zu generieren, die sich mit der ursprünglichen Anfrage oder Aufgabe befasst.
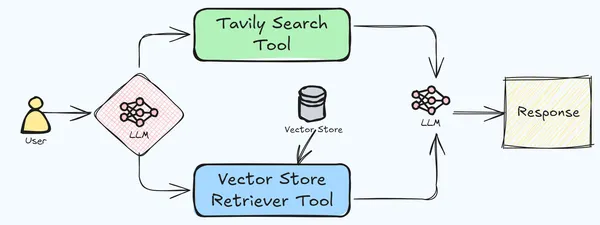
Dieser Ansatz bietet mehrere Vorteile, darunter Spezialisierungwobei jedes Werkzeug in einem bestimmten Bereich hervorragende Leistungen erbringt, was zu einer präziseren Bewältigung komplexer Aufgaben führt; Skalierbarkeitaufgrund der modularen Natur des Programs, die eine einfache Anpassung an verschiedene Anwendungen und Domänen ermöglicht; Und reduzierte Halluzinationda die Integration mehrerer Instruments mit Abruffunktionen eine gegenseitige Überprüfung von Informationen ermöglicht und so das Risiko der Generierung falscher oder erfundener Inhalte minimiert. In unserer aktuellen Anwendung werden wir die Tavily-Websuch- und Vektorspeicher-Abruftools verwenden, um eine erweiterte RAG-Pipeline zu erstellen.
Für die Umsetzung erforderliche Fähigkeiten
Das Wissen und die Fähigkeiten, die zur effektiven Umsetzung dieser Lösung erforderlich sind.
- Tavily-Such-API: Aus ihren Dokumenten geht hervor, Tavily Search API ist eine für LLMs optimierte Suchmaschine, die auf effiziente, schnelle und dauerhafte Suchergebnisse abzielt.‘ Mithilfe der Tavily-API können wir die Echtzeit-Websuche problemlos in LLM-basierte Anwendungen integrieren. LangChain verfügt über eine Integration der Tavily-API für die Echtzeit-Websuche, die basierend auf der Anfrage des Benutzers nach relevanten Informationen im Internet sucht. Die Tavily-API ist in der Lage, relevante Informationen aus mehreren Quellen abzurufen, darunter die URL, relevante Bilder und den Inhalt, alles in einem strukturierten JSON-Format. Diese abgerufenen Informationen werden dann als Kontext für LLM verwendet, um die Anfrage des Benutzers zu beantworten. Wir werden einen Agenten erstellen, der die Tavily-Integration von LangChain nutzt, der von der Pipeline verwendet wird, um Anfragen zu beantworten, wenn das LLM nicht in der Lage ist, anhand des bereitgestellten Dokuments zu antworten.
- OpenAI GPT-4 Turbo: Wir werden verwenden GPT 4 Turbo von OpenAI Modell für dieses Experiment, Sie können jedoch jedes beliebige Modell für diese Pipeline verwenden, einschließlich lokaler Modelle. Bitte verwenden Sie nicht das GPT 4o-Modell von OpenAI, da es bei Agentenanwendungen offenbar keine gute Leistung erbringt.
- Apples 10-Okay-Dokument 2023: Für dieses Experiment verwenden wir das Dokument „10.000 Jahresberichte“, Sie können aber auch jedes andere Dokument Ihrer Wahl verwenden.
- Deeplake Vector Retailer: Für diese Anwendung verwenden wir den Deeplake Vector Retailer. Es ist schnell und leichtgewichtig, was dazu beiträgt, die Latenz der Anwendung aufrechtzuerhalten.
- Einfacher SQL-Chat-Speicher (non-compulsory): Darüber hinaus werden wir ein grundlegendes SQL-basiertes Chat-Speichersystem implementieren, um den Kontext und die Kontinuität über interaktive Chat-Sitzungen hinweg aufrechtzuerhalten. Dies ist non-compulsory, aber die Beibehaltung in der Anwendung verbessert die Benutzererfahrung.
Implementierung der Agentic RAG-Anwendung
Jetzt gehen wir durch die Erstellung dieses einfachen, aber leistungsstarken Produkts Retrieval-Augmented Era (RAG) System, das darauf ausgelegt ist, Benutzeranfragen mit hoher Genauigkeit und Relevanz zu beantworten. Der unten beschriebene Code zeigt, wie diese Komponenten in eine zusammenhängende Anwendung integriert werden, die in der Lage ist, Informationen sowohl aus einem bestimmten Dokument als auch aus den umfangreichen Ressourcen des Webs abzurufen. Lassen Sie uns auf die Besonderheiten der Implementierung eingehen und untersuchen, wie jeder Teil des Codes zur Gesamtfunktionalität des Programs beiträgt.
Umgebung schaffen
Erstellen Sie zunächst eine Umgebung mit den unten genannten Paketen.
#set up dependencies
deeplake==3.9.27
ipykernel==6.29.5
ipython==8.29.0
jupyter_client==8.6.3
jupyter_core==5.7.2
langchain==0.3.7
langchain-community==0.3.5
langchain-core==0.3.15
langchain-experimental==0.3.3
langchain-openai
langchain-text-splitters==0.3.2
numpy==1.26.4
openai==1.54.4
pandas==2.2.3
pillow==10.4.0
PyMuPDF==1.24.13
tavily-python==0.5.0
tiktoken==0.8.0Umgebungseinrichtung und Erstkonfigurationen: Zunächst werden die erforderlichen Bibliotheken importiert. Dies bildet die Grundlage für die Interaktion der Anwendung mit verschiedenen Diensten und Funktionen.
Erstkonfigurationen
import os
from langchain_core.prompts import (
ChatPromptTemplate,
)
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.brokers import AgentExecutor, create_openai_tools_agent
from langchain.instruments.retriever import create_retriever_tool
from langchain.instruments.tavily_search import TavilySearchResults
from langchain.vectorstores.deeplake import DeepLake
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.reminiscence import ConversationBufferWindowMemory, SQLChatMessageHistoryKonfiguration des Tavily-Suchtools
Konfiguration des Tavily-Suchtools: Als Nächstes wird das TavilySearchResults-Device für Websuchen konfiguriert und Parameter wie max_results und search_ Depth festgelegt. Zuerst exportieren wir den Tavily-API-Schlüssel als Betriebssystemumgebung. Sie können Ihren eigenen Tavily-API-Schlüssel von erhalten Hierindem ein neues generiert wird.
os.environ("TAVILY_API_KEY") = "tavily_api_key"
search_tool = TavilySearchResults(
title="tavily_search_engine",
description="A search engine optimized for retrieving info from net primarily based on person question.",
max_results=5,
search_depth="superior",
include_answer=True,
include_raw_content=True,
include_images=True,
verbose=False,
)Chat OpenAI-Konfiguration
Chat OpenAI-Konfiguration: Das Chat OpenAI-Modell wird mit den GPT-4-Modelldetails und API-Schlüsseln konfiguriert. Beachten Sie, dass für diesen Anwendungsfall jedes Chat-Modell verwendet werden kann. Sehen Sie sich die LangChain-Dokumentation für das Modell an, das Sie verwenden möchten, und ändern Sie den Code entsprechend.
llm = ChatOpenAI(
mannequin="gpt-4",
temperature=0.3,
api_key="openai_api_key",
)Definieren der Eingabeaufforderungsvorlage
Definieren der Eingabeaufforderungsvorlage: Eine ChatPromptTemplate wird definiert, um die Interaktion des Chatbots mit Benutzern zu steuern, wobei der Schwerpunkt auf der Verwendung von Dokumentkontext und Websuche liegt.
immediate = ChatPromptTemplate((
("system",
f"""You're a useful chatbot. You could reply the person's queries in
element from the doc context. You've entry to 2 instruments:
deeplake_vectorstore_retriever and tavily_search_engine.
At all times use the deeplake_vectorstore_retriever software first to retrieve
the context and reply the query. If the context doesn't comprise related
reply for the person's question, use the tavily_search_engine to fetch net search
outcomes to reply them. NEVER give an incomplete reply. At all times attempt your finest
to seek out reply by way of net search if reply shouldn't be discovered from context."""),
("human", "{user_input}"),
("placeholder", "{messages}"),
("placeholder", "{agent_scratchpad}"),
))Vorverarbeitung und Aufnahme von Dokumenten
Vorverarbeitung und Aufnahme des Dokuments: Das Dokument wird geladen, in Blöcke aufgeteilt und diese Blöcke werden verarbeitet, um Einbettungen zu erstellen, die dann in einem DeepLake-Vektorspeicher gespeichert werden.
information = "Apple 10k 2023.pdf"
loader = PyMuPDFLoader(file_path=information)
text_splitter = CharacterTextSplitter(separator="n", chunk_size=1000, chunk_overlap=200)
docs = loader.load_and_split(text_splitter=text_splitter)
embeddings = OpenAIEmbeddings(api_key="openai_api_key",)
vectorstore = DeepLake(dataset_path="dataset", embedding=embeddings,)
_ = vectorstore.add_documents(paperwork=docs)Erstellen des Retrieval-Instruments
Erstellen des Retrieval-Instruments: Aus dem Vektorspeicher wird ein Retrieval-Device erstellt, um die Dokumentensuche zu erleichtern.
retriever_tool = create_retriever_tool(
retriever=vectorstore.as_retriever(
search_type="similarity",
search_kwargs={
"okay": 6,
"fetch_k": 12,
},
),
title="deeplake_vectorstore_retriever",
description="Searches and returns contents from uploaded Apple SEC doc primarily based on person question.",
)
instruments = (
retriever_tool,
search_tool,
)Implementierung eines einfachen Chat-Verlaufs/Speichers (non-compulsory): Zur Pflege des Kontexts wird ein SQL-basierter Chat-Speicher konfiguriert. Es wird eine SQLite-Datenbank erstellt und die Chat-Konversationen darin gespeichert.
historical past = SQLChatMessageHistory(
session_id="ghdcfhdxgfx",
connection_string="sqlite:///chat_history.db",
table_name="message_store",
session_id_field_name="session_id",
)
reminiscence = ConversationBufferWindowMemory(chat_memory=historical past)Initialisierung des Agenten und Agent Executors
Initialisierung des Agenten und des Agent-Executors: Ein Agent wird erstellt und ausgeführt, um Benutzeranfragen zu verarbeiten und Antworten basierend auf den konfigurierten Instruments und dem Speicher zu generieren.
agent = create_openai_tools_agent(llm, instruments, immediate)
agent_executor = AgentExecutor(
instruments=instruments,
agent=agent,
verbose=False,
max_iterations=8,
early_stopping_method="power",
reminiscence=reminiscence,
)Testen der Pipeline an einigen Beispielen: Damit haben wir unsere RAG mit Echtzeit-Suchpipeline fertig. Lassen Sie uns die Anwendung mit einigen Abfragen testen.
end result = agent_executor.invoke({
"user_input": "What's the fiscal 12 months highlights of Apple inc. for 2nd quarter of 2024?",
},)
print(end result("output"))Ausgabe
The doc doesn't comprise particular details about the fiscal 12 months
highlights of Apple Inc. for the 2nd quarter of 2024. The most recent info
contains:Whole Web Gross sales and Web Revenue: Apple's whole internet gross sales had been $383.3 billion,
and internet earnings was $97.6 billion throughout 2023.Gross sales Efficiency: There was a 3% lower in whole internet gross sales in comparison with
2022, amounting to an $11.0 billion discount. This lower was attributed
to foreign money trade headwinds and weaker client demand.Product Bulletins: Important product bulletins throughout fiscal 12 months
2023 included:First Quarter: iPad and iPad Professional, Subsequent-generation Apple TV 4K, and MLS Season
Cross (a Main League Soccer subscription streaming service).
Second Quarter: MacBook Professional 14", MacBook Professional 16", and Mac mini; Second-
technology HomePod.
Third Quarter: MacBook Air 15", Mac Studio and Mac Professional; Apple Imaginative and prescient Professional™
(the corporate's first spatial laptop that includes its new visionOS).
Fourth Quarter: iPhone 15 sequence (iPhone 15, iPhone 15 Plus, iPhone 15 Professional,
and iPhone 15 Professional Max); Apple Watch Collection 9 and Apple Watch Extremely 2.
Share Repurchase Program: In Could 2024, Apple introduced a brand new share repurchase
program of as much as $90 billion and raised its quarterly dividend.For the precise particulars relating to the 2nd quarter of 2024, it might be
essential to seek the advice of Apple's official publications or monetary studies.
Die von uns gestellte Anfrage bezog sich auf das Jahr 2024, worauf das Modell antwortete, dass der Kontext keine Informationen für die Highlights von 2024 enthält und die Particulars für 2023 angibt, die es aus dem Vektorspeicher erhält. Versuchen wir als Nächstes, dieselbe Frage zu stellen, jedoch für Nvidia.
end result = agent_executor.invoke({
"user_input": "What's the fiscal 12 months highlights of Nvidia inc. for 2nd quarter of 2024?",
},)
print(end result("output"))Ausgabe
The textual content from the picture is:For the 2nd quarter of the fiscal 12 months 2024, Nvidia Inc. reported distinctive
development, notably pushed by its Information Heart section. Listed here are the
highlights:Whole Revenues: Nvidia's whole income noticed a major enhance, up 101%
year-over-year (YOY) to $13.51 billion, which was above the outlook.Information Heart Income: The Information Heart section skilled a outstanding development
of 171% YOY, reaching $10.32 billion. This development underscores the robust
demand for AI-related computing options.Gaming Income: The Gaming section additionally noticed development, up 22% YOY to $2.49
billion.Document Information Heart Income: Nvidia achieved a file in Information Heart income,
highlighting the robust demand for its services and products.These outcomes mirror Nvidia's robust place out there, notably in
areas associated to accelerated computing and AI platforms. The corporate
continues to profit from traits in synthetic intelligence and machine
studying.For extra detailed info, you possibly can discuss with Nvidia's official press
launch relating to their monetary outcomes for the second quarter of fiscal
12 months 2024.
Lesen Sie auch: RAG vs. Agentic RAG: Ein umfassender Leitfaden
Wichtige Erkenntnisse
- Integration fortschrittlicher Technologien: Kombiniert Instruments wie LangChain, Azure OpenAI, Tavily-Suche API und DeepLake-Vektorspeicher, um ein robustes System für den Informationsabruf und NLP zu schaffen.
- Retrieval-Augmented Era (RAG): Kombiniert Echtzeit-Websuche, Dokumentenabruf und Konversations-KI, um genaue und kontextbezogene Antworten zu liefern.
- Effizientes Dokumentenmanagement: Verwendet DeepLake-Vektorspeicher zum schnellen Abrufen relevanter Dokumentabschnitte und optimiert so die Handhabung großer Dokumente.
- Azure OpenAI-Sprachmodellierung: Hebelwirkungen GPT-4 für kohärente, menschenähnliche und kontextbezogene Antworten.
- Dynamische Websuche: Die Tavily Search API bereichert Antworten mit Echtzeit-Webinformationen für umfassende Antworten.
- Kontext- und Speicherverwaltung: SQL-basierter Chat-Speicher sorgt für kohärente, kontextbezogene Interaktionen über Sitzungen hinweg.
- Versatile, skalierbare Architektur: Modulares und konfigurierbares Design unterstützt die einfache Erweiterung mit zusätzlichen Modellen, Informationsquellen oder Funktionen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Abschluss
In diesem Artikel haben wir die Erstellung einer Echtzeit-Agentic-RAG-Anwendung mit LangChain, Tavily und OpenAI GPT-4 untersucht. Diese leistungsstarke Integration von Technologien ermöglicht es der Anwendung, durch die Kombination von Dokumentenabruf, Echtzeit-Websuche und Konversationsgedächtnis genaue, kontextrelevante Antworten bereitzustellen. Unser Leitfaden stellt einen flexiblen und skalierbaren Ansatz vor, der an verschiedene Modelle, Datenquellen und Funktionalitäten anpassbar ist. Durch die Befolgung dieser Schritte können Entwickler fortschrittliche KI-gestützte Lösungen entwickeln, die den heutigen Bedarf an aktueller und umfassender Informationszugänglichkeit erfüllen.
Wenn Sie on-line nach einem RAG-Kurs suchen, dann erkunden Sie: RAG Systemt Necessities.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Häufig gestellte Fragen
Antwort. Der Hauptzweck der Agentic RAG-Anwendung besteht darin, durch die Kombination von Dokumentenabruf, Echtzeit-Websuche und Sprachgenerierung genaue Antworten in Echtzeit bereitzustellen. Es nutzt spezielle Instruments für Teilaufgaben und gewährleistet so präzise und kontextrelevante Antworten.
Antwort. Die Tavily Search API integriert die Echtzeit-Websuche in das System und ruft aktuelle, relevante Informationen in einem strukturierten JSON-Format ab. Es bietet zusätzlichen Kontext für Abfragen, die nicht allein durch vorinstallierte Dokumentdaten beantwortet werden können.
Antwort. DeepLake dient als Vektorspeicher zum Speichern von Dokumenteinbettungen. Es ermöglicht einen effizienten Abruf relevanter Dokumentblöcke auf der Grundlage einer Ähnlichkeitssuche und stellt sicher, dass die Anwendung schnell auf die erforderlichen Informationen zugreifen und diese nutzen kann.
Ein vielseitig begabter Programmierer, dessen Hauptarbeitsgebiet und Interesse in der Softwareentwicklung, Datenwissenschaft und maschinellem Lernen liegt. Eine proaktive und detailorientierte Particular person, die das Geschichtenerzählen von Daten liebt und neugierig und leidenschaftlich daran interessiert ist, komplexe wertorientierte Geschäftsprobleme mit Information Science und maschinellem Lernen zu lösen, um robuste Pipelines für maschinelles Lernen bereitzustellen, die maximale Wirkung gewährleisten.
In meiner Freizeit konzentriere ich mich auf die Erstellung von Information Science- und AI/ML-Inhalten, die Bereitstellung von 1:1-Mentoren, Berufsberatung und Tipps zur Vorbereitung auf Vorstellungsgespräche, wobei ich mich ausschließlich darauf konzentriere, komplexe Themen einfacher zu vermitteln, um Menschen bei einem erfolgreichen Karriereübergang zu helfen zu Information Science mit den richtigen Fähigkeiten!