

# Einführung
Die meisten Groups stellen fest, dass sie eine benötigen Characteristic-Retailer auf die harte Tour. Ein Betrugsmodell arbeitet im Pocket book und bringt nonetheless und leise die Produktion zum Erliegen. Ein Supportmitarbeiter gibt eine allgemeine Antwort, da er keine Ahnung hat, wer der Benutzer ist. Eine Empfehlungspipeline dupliziert dieselbe Berechnung der „30-Tage-Ausgaben“ für drei Jobs, und zwei davon sind anderer Meinung.
Ein Characteristic Retailer ist das Teil davon Infrastruktur das behebt diese Probleme. Es definiert Funktionen einmal, speichert sie in zwei Formen (eine zum Coaching, eine zum Servieren) und hält beide synchron. Wir werden ein Minimalmodell von Grund auf neu bauen Pythonverwenden DuckDB, Parkett, RedisUnd FastAPI. Dann schauen wir uns an, wie KI-Anwendungen das verändern, wofür wir sie tatsächlich nutzen.
Der vollständige Code ist kurz genug, dass wir jede Komponente durchgehen können.
# Was ein Characteristic Retailer tatsächlich löst
Der klassische Pitch ist der Trainings-Serving-Skew: Das SQL, das Ihren Trainingssatz erstellt hat, ist nicht derselbe Codepfad, der bei der Inferenz ausgeführt wird, sodass die Werte abweichen. Dieses Downside ist actual und die Trennung von Offline und On-line ist die Standardlösung.
Das moderne Spielfeld ist breiter. Giant Language Mannequin (LLM)-Agenten und Retrieval-Augmented Era (RAG)-Pipelines benötigen einen strukturierten Benutzerkontext zur Inferenzzeit, bei jeder Anfrage, in weniger als 10 ms. Ein LLM hat keine Erinnerung daran, wer der Benutzer ist. Wenn wir eine personalisierte Ausgabe wünschen, müssen wir die Planstufe des Benutzers, die letzte Aktivität und den Kontostatus in die Eingabeaufforderung einfügen, und wir brauchen ein System, das diese Werte schnell und konsistent zurückgeben kann. Genau das bieten uns der On-line-Store und die Abruf-API eines Characteristic-Shops.
Deshalb bauen wir für beides. Die gleichen fünf Komponenten behandeln den Anwendungsfall des prädiktiven maschinellen Lernens und den LLM-Kontext-Anwendungsfall.
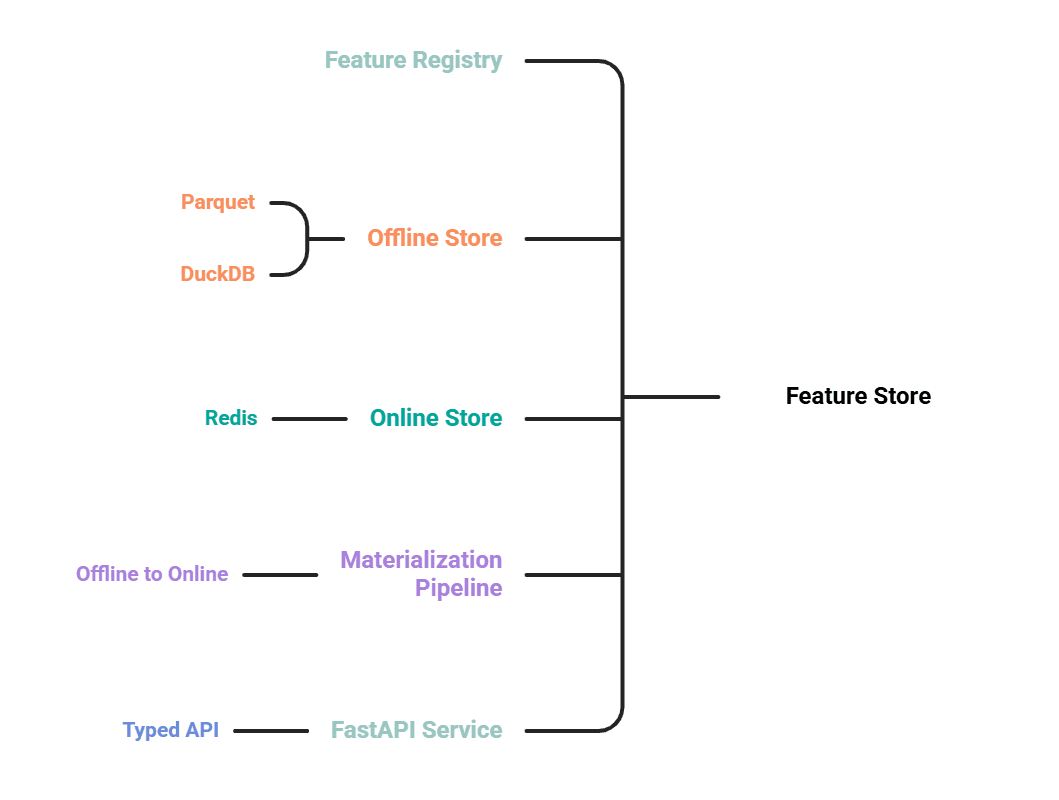
# Die fünf Komponenten
- Eine Characteristic-Registrierung, die Options als Code definiert.
- Ein Offline-Store auf Parquet, abgefragt mit DuckDB, für Schulungen und Auffüllungen.
- Ein On-line-Store auf Redis für Nachschlagevorgänge mit geringer Latenz.
- Eine Materialisierungspipeline, die die neuesten Werte von offline nach on-line überträgt.
- Ein FastAPI-Dienst, der eine typisierte Abruf-API verfügbar macht.
# Laufbeispiel: Ein personalisierter LLM-Empfehler
Wir betreiben einen Streamingdienst. Wenn ein Benutzer die App öffnet, generiert ein LLM eine kurze, personalisierte Nachricht „Was Sie als Nächstes ansehen sollten“. Das LLM benötigt drei Dinge über den Benutzer:
| Besonderheit | Typ | Frische |
|---|---|---|
user_segment |
Zeichenfolge | täglich |
watch_count_30d |
int | stündlich |
last_genre |
Zeichenfolge | professional Veranstaltung |
Das Wesen ist user_id. Wir werden diese drei Funktionen registrieren, materialisieren und sie dem LLM auf Anfrage zur Verfügung stellen.
// 1. Definieren der Characteristic Registry
Eine Registrierung ist lediglich ein Ort, an dem Options einmalig mit ihrer Entität, ihrem Dtype und ihrer Quelle deklariert werden. Wir verwenden eine Datenklasse.
from dataclasses import dataclass
from typing import Literal
@dataclass(frozen=True)
class Characteristic:
title: str
entity: str
dtype: Literal("int", "float", "str")
supply: str # path to a Parquet file or a SQL view
REGISTRY: dict(str, Characteristic) = {
"user_segment": Characteristic("user_segment", "user_id", "str", "information/user_segment.parquet"),
"watch_count_30d": Characteristic("watch_count_30d", "user_id", "int", "information/watch_count_30d.parquet"),
"last_genre": Characteristic("last_genre", "user_id", "str", "information/last_genre.parquet"),
}Den vollständigen Code finden Sie hier Hier.
Wenn Sie es ausführen, wird in der Ausgabe Folgendes angezeigt:
Registered options:
user_segment entity=user_id dtype=str supply=information/user_segment.parquet
watch_count_30d entity=user_id dtype=int supply=information/watch_count_30d.parquet
last_genre entity=user_id dtype=str supply=information/last_genre.parquetDas ist der Vertrag. Jede andere Komponente liest aus REGISTRYsodass das Umbenennen eines Options, das Ändern seines D-Typs oder das Verweisen auf eine neue Quelle an einer Stelle erfolgt. In Produktionssystemen wäre dies der Fall YAML oder ein in ein Git-Repository eingechecktes Python-Modul mit Codeüberprüfung bei jeder Änderung.
// 2. Aufbau des Offline-Retailers mit DuckDB und Parquet
Der Offline-Store speichert den vollständigen Verlauf jedes Merkmalswerts. Wir verwenden Parquet-Dateien als Speicherschicht und DuckDB als Abfrage-Engine. DuckDB liest Parquet direkt, was bedeutet, dass keine separate Datenbank ausgeführt werden muss.
Hier ist ein Beispiel des Codes:
import duckdb
import pandas as pd
def get_historical_features(
entity_df: pd.DataFrame, options: record(str)
) -> pd.DataFrame:
con = duckdb.join()
con.register("entities", entity_df)
base = "SELECT * FROM entities"
for fname in options:
f = REGISTRY(fname)
src = f.supply.change("'", "''")
con.execute(f"CREATE VIEW {fname}_src AS SELECT * FROM '{src}'")
base = f"""
SELECT t.*, s.{fname}
FROM ({base}) t
ASOF LEFT JOIN {fname}_src s
ON t.user_id = s.user_id
AND t.event_timestamp >= s.event_timestamp
"""
return con.execute(base).df()Den vollständigen Code finden Sie hier Hier.
Wenn Sie es ausführen, wird in der Ausgabe Folgendes angezeigt:
| Benutzer-ID | event_timestamp | user_segment | watch_count_30d | last_genre |
|---|---|---|---|---|
| 8a2f | 05.05.2026 12:00:00 | lässig | 22 | NaN |
| b13c | 07.05.2026 20:00:00 | lässig | 5 | Thriller |
| 8a2f | 07.05.2026 22:00:00 | power_user | 47 | Dokumentarfilm |
Der AsOf beitreten ist der Level-in-Time-Be part of. Für jede Entitätszeile wird der aktuellste Featurewert ausgewählt, bei dem der Zeitstempel des Options beim oder vor dem Ereigniszeitstempel liegt. Dadurch wird Leckage verhindert – wenn eine Trainingszeile mit einem Merkmalswert erstellt wird, der zu dem Zeitpunkt, für den wir die Vorhersage treffen, noch nicht vorhanden conflict.
Level-in-Time-Joins sind immer noch die richtige Antwort für jedes Modell, das wir trainieren oder verfeinern möchten. Für einen reinen Inferenzzeit-LLM-Anwendungsfall rufen wir diese Funktion möglicherweise nie auf. Wir wollen weiterhin den Offline-Retailer, da dort Backfills, Bewertungsdatensätze und Audits herkommen.
// 3. Einrichten des On-line-Retailers auf Redis
Der On-line-Store speichert nur den neuesten Wert professional Entität. Redis ist die Standardwahl, da Hash-Suchvorgänge weniger als eine Millisekunde dauern.
import json
import fakeredis # use redis.Redis() in opposition to an actual server in manufacturing
r = fakeredis.FakeRedis(decode_responses=True)
def write_online(entity: str, entity_id: str, values: dict) -> None:
r.hset(
f"{entity}:{entity_id}",
mapping={okay: json.dumps(v) for okay, v in values.gadgets()},
)
def read_online(entity: str, entity_id: str, options: record(str)) -> dict:
uncooked = r.hmget(f"{entity}:{entity_id}", options)
return {f: json.masses(v) if v else None for f, v in zip(options, uncooked)}Den vollständigen Code finden Sie hier Hier.
Wenn Sie es ausführen, wird in der Ausgabe Folgendes angezeigt:
read_online -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
lacking key -> {'user_segment': None}Die Schlüsselform ist entity:entity_id. Der Wert ist ein Hash mit einem Feld professional Characteristic. Eine Single HMGET gibt alle von uns gewünschten Funktionen in einem Rundlauf zurück. Auf einer lokalen Redis-Instanz mit drei Funktionen ist dies in deutlich unter 1 ms erledigt.
// 4. Ausführen der Materialisierungspipeline
Durch die Materialisierung werden Werte von offline nach on-line verschoben. In einem realen System läuft dies nach einem Zeitplan (Airflow, Cron, ein Streaming-Job). Hier ist es eine Funktion.
def materialize(options: record(str)) -> None:
by_entity: dict(str, dict) = {}
for fname in options:
f = REGISTRY(fname)
src = f.supply.change("'", "''")
df = duckdb.sql(f"""
SELECT {f.entity}, {fname}
FROM '{src}'
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {f.entity}
ORDER BY event_timestamp DESC
) = 1
""").df()
for _, row in df.iterrows():
by_entity.setdefault(row(f.entity), {})(fname) = row(fname)
for entity_id, values in by_entity.gadgets():
write_online("user_id", entity_id, values)Den vollständigen Code finden Sie hier Hier.
Wenn Sie es ausführen, wird in der Ausgabe Folgendes angezeigt:
user_id:8a2f -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
user_id:b13c -> {'user_segment': 'informal', 'watch_count_30d': 5, 'last_genre': 'thriller'}Der QUALIFY Die Klausel behält die neueste Zeile professional Entität bei. Wir gruppieren alle Funktionen für denselben Benutzer in einem Redis-Schreibvorgang, um Roundtrips zu vermeiden. Führen Sie dies mit der Kadenz aus, die jede Funktion benötigt: stündlich für watch_count_30dnahezu in Echtzeit für last_genretäglich für user_segment. Die Registrierung ist der richtige Ort, um diesen Rhythmus in einer realen Implementierung zu kodieren.
// 5. Offenlegung des FastAPI Retrieval Service
Der Abrufdienst ist die Produktionsfläche. Es ist das, was die LLM-Anwendung aufruft.
f = resp.json()("options")
print("nPrompt the LLM would obtain:")
print(
f" System: You advocate reveals for a streaming service.n"
f" Person context: section={f('user_segment')}, "
f"watched {f('watch_count_30d')} titles in final 30 days, "
f"final style watched: {f('last_genre')}.n"
f" Activity: recommend 3 titles in a pleasant, brief message."
)Den vollständigen Code finden Sie hier Hier.
Wenn Sie es ausführen, wird in der Ausgabe Folgendes angezeigt:
POST /get-online-features -> 200
physique: {'user_id': '8a2f', 'options': {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}}
Immediate the LLM would obtain:
System: You advocate reveals for a streaming service.
Person context: section=power_user, watched 47 titles in final 30 days, final style watched: documentary.
Activity: recommend 3 titles in a pleasant, brief message.Der Characteristic Retailer ist der Teil, der „Benutzer 8a2f“ in einen strukturierten Kontext umwandelt, den das LLM verwenden kann.
# Wo der Characteristic Retailer endet und die Vektordatenbank beginnt
Eine Vektordatenbank (Tannenzapfen, Weben, pgvector) ist kein Characteristic Retailer, auch wenn beide bei der Schlussfolgerung vor einem Modell stehen. Sie lösen verschiedene Retrieval-Probleme.
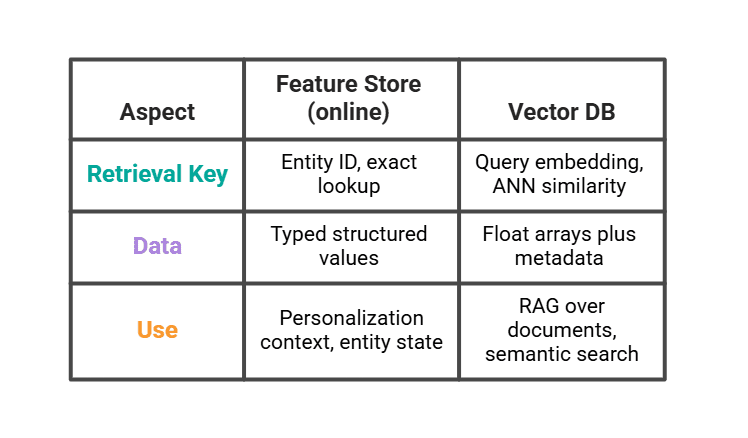
Ein echter LLM-Stack nutzt beides. Die Vektordatenbank gibt die drei ähnlichsten vergangenen Betrachtungssitzungen zurück. Der Characteristic Retailer gibt das Phase des Benutzers und die letzten Zählungen zurück. Die Eingabeaufforderung kombiniert sie.
# Gängige Anti-Patterns
Einige Muster, die wir immer wieder beobachten, scheitern:
- Rechenfunktionen innerhalb des Modelldienstes. Die gleiche Logik landet im Trainingsnotizbuch und in der API, und die beiden Definitionen weichen innerhalb eines Quartals voneinander ab.
- Den On-line-Store als Quelle der Wahrheit betrachten. Redis verliert Daten bei einem fehlerhaften Neustart. Der Offline-Store ist kanonisch; Der On-line-Store ist ein Cache.
- Überspringen der Registrierung. Drei Groups definieren unabhängig voneinander
active_userund die Dashboards stimmen nicht mehr mit dem Modell überein. - Eine Vektordatenbank als Characteristic Retailer bezeichnen. Es können keine strukturierten Suchvorgänge mit Entitätsschlüssel durchgeführt werden, und eine Eingabeaufforderung, die beides benötigt, wird ohnehin mit zwei Systemen verbunden sein.
- Auffüllen ohne Level-in-Time-Joins. Das Trainingsset sieht großartig aus, das Serienmodell sieht kaputt aus und die Lücke ist das Leck.
# Vergleich mit Feast, Tecton und Databricks
Unsere ca. 200 Linien erledigen die gleiche Aufgabe im Miniaturformat.
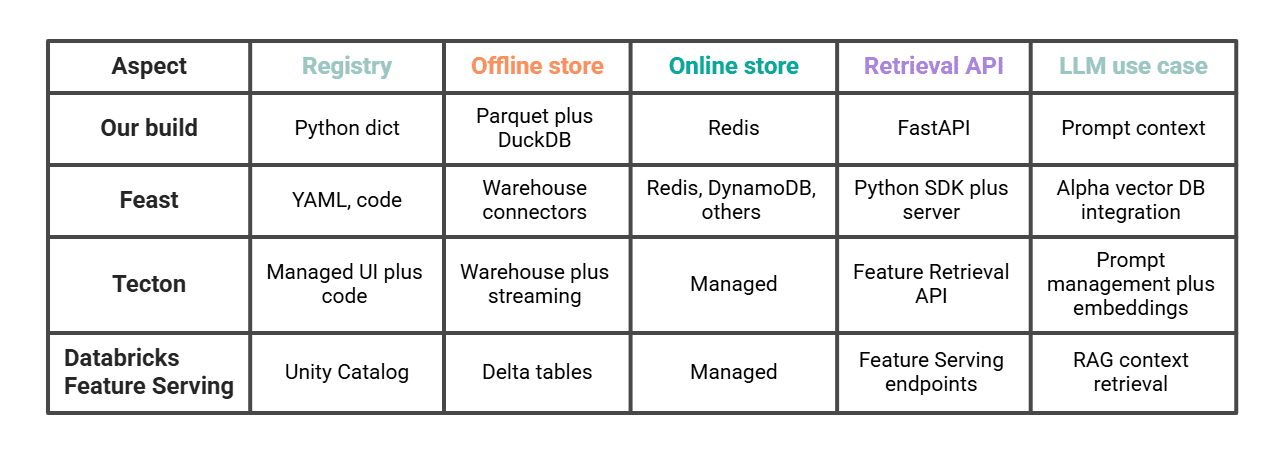
Fest ist der naheliegendste Vergleich, wenn wir nach dem gleichen Muster weitergehen wollen: selbst gehostet. Tecton Und Datenbausteine sind die verwalteten Pfade und verfügen über explizite LLM-Funktionen (Tectons Characteristic Retrieval API für LLMs, Databricks Characteristic Serving für zusammengesetzte generative KI-Systeme). Die Wahl zwischen ihnen hängt hauptsächlich davon ab, wie viel wir selbst betreiben möchten und ob der Relaxation unseres Stacks bereits in Databricks lebt.
# Abschluss
Ein funktionierender Characteristic Retailer besteht aus fünf Komponenten: einer Registrierung, einem Offline-Retailer, einem On-line-Retailer, einem Materialisierungsschritt und einer Abruf-API. Wenn wir es einmal bauen, erfahren wir, warum die Produktionssysteme so aussehen, wie sie aussehen. Es zeigt auch, wo sich das Design für KI ändert: Der On-line-Abrufpfad ist die Oberfläche, auf die das LLM trifft, Level-in-Time-Joins sind wichtig, wenn wir trainieren oder auswerten, und die Vektordatenbank befindet sich neben dem Characteristic Retailer und nicht darin.
Sobald wir diese Teile haben, ist der Austausch unserer Minimalversion gegen Feast, Tecton oder Databricks größtenteils eine Migration der Registrierung. Die Kind des Methods bleibt gleich.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von High-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Developments auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.