
Die meisten Suchagenten versuchen, zu viele Aufträge auf einmal abzuwickeln. Sie generieren neue Suchanfragen, merken sich, was sie bereits erforscht haben, sammeln Beweise und entscheiden, was related ist, während die Suche immer weiter zunimmt. Das kann den gesamten Prozess chaotisch, teuer und schwer kontrollierbar machen.
Harness-1 verfolgt einen einfacheren Ansatz. Es wurde gemeinsam mit Forschern von UIUC, UC Berkeley und Chroma entwickelt und trennt die Arbeit, Suchbegriffe zu finden, von der Arbeit, den Suchfortschritt zu verfolgen. Das Ergebnis ist ein kompakter Retrieval-Agent, über den man leichter nachdenken kann und dessen Leistung weit über dem liegt, was seine Größe vermuten lässt.
In diesem Artikel werfen wir einen genaueren Blick darauf Geschirr-1 und warum sein Ansatz gegenüber Retrieval-Agenten wichtig ist.
Warum das bestehende Search Brokers Plateau?
Die meisten Retrieval-Agenten sind ausgebildet Ende bis Ende. Das Modell erzeugt Abfragen, liest Blöcke, entscheidet, worauf es ankommt, und speichert den gesamten Kontext in einem wachsenden Transkript. Die Richtlinie lernt alles, Suchstrategie, Beweisverfolgung, Deduplizierung und auch die Stoppbedingungen.
Das Drawback besteht darin, dass Reinforcement Studying versucht, all dies auf einmal zu verbessern. Semantische Suchentscheidungen, etwa ob ich nach „Fusionsdatum“ oder „Akquisitionsjahr“ suchen soll, geraten in Konflikt mit der Buchführung auf niedrigerer Ebene. Habe ich diesen Brocken schon einmal gesehen? RL optimiert am Ende beide, und ehrlich gesagt teilen sie nicht die gleiche Lerndynamik. Es wird additionally etwas chaotisch.
Die Forscher nennen dies Kernfehler im Design. Ihre Lösung ist sauber: Verschieben Sie die Zustandsverwaltung aus dem Modell in einen Kabelbaum.
Was macht das Geschirr eigentlich?
Der wichtigste Durchbruch ist der Stateful Harness. Der Kabelbaum betreibt das Modell als Zustandsmaschine. Diese vier dauerhaften Strukturen bleiben in jeder Episode erhalten:
- Ein Kandidatenpool besteht aus allen komprimierten, deduplizierten Dokumenten aller Kandidatensuchen.
- Ein kuratierter Satz ist die endgültige Ausgabe mit bis zu 30 Dokumenten, die mit Wichtigkeitsmarkierungen gekennzeichnet sind (
very_high,excessive,truthful,low). - Ein Volltextspeicher enthält alle abgerufenen Daten und wird außerhalb der Maschineneingabeaufforderung gespeichert.
- Ein Beweisdiagramm ist eine Sammlung automatisch extrahierter Entitäten, ihrer Brückendokumente und Singleton-Leads.
Der Proof-Graph-Teil dieser Struktur ist ziemlich intelligent. Der Regex-Extraktor durchsucht jedes abgerufene Datenelement nach Eigennamen, Jahren und Datumsangaben. Bridge-Dokumente, die zwei oder mehr Entitäten enthalten, die häufig zusammen vorkommen, werden als sehr hohe Priorität gekennzeichnet. Singletons kennzeichnen potenzielle Folgesuchen. Bei jeder Spielrunde präsentiert das Geschirr diese Informationen auf effiziente und kompakte Weise.
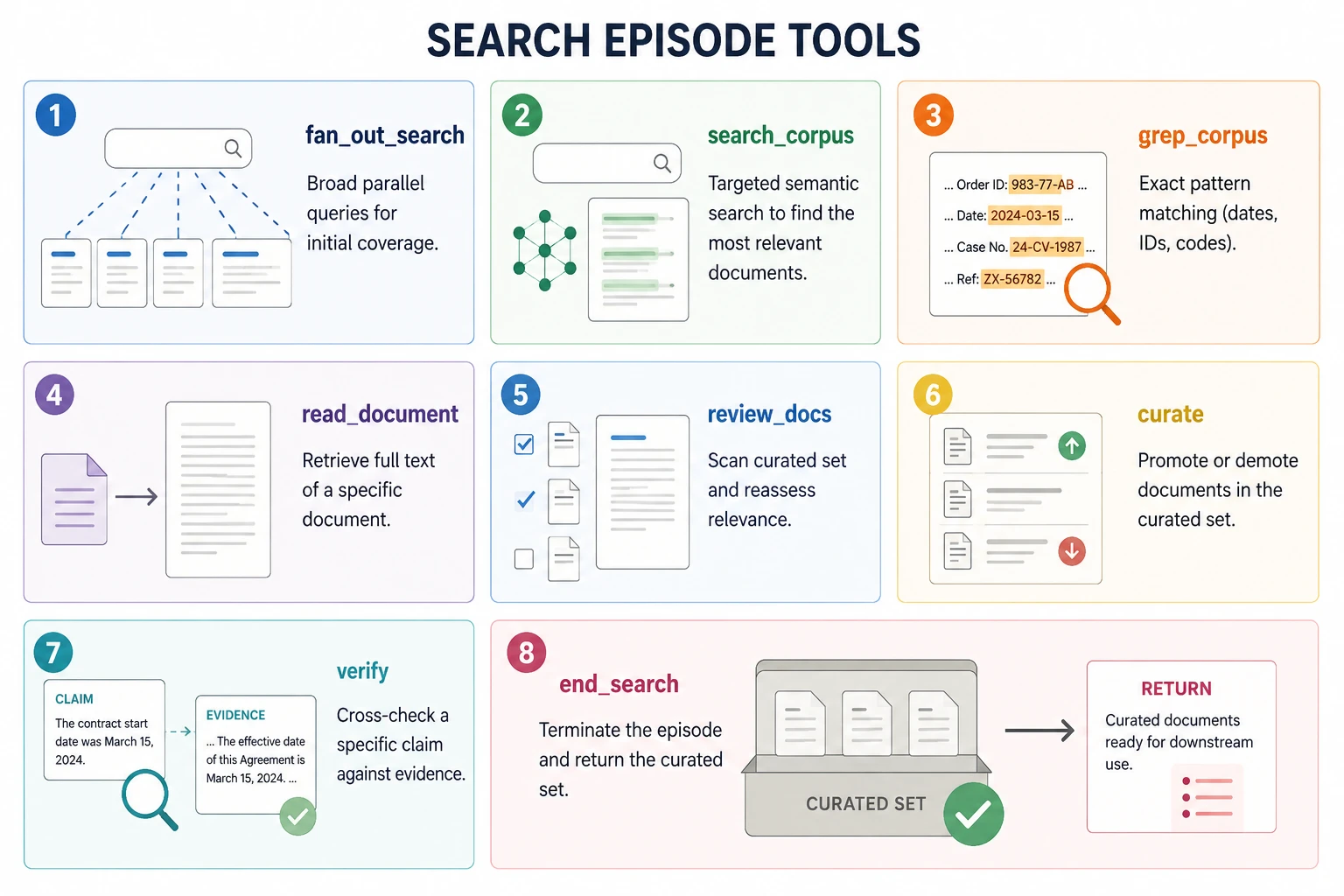
Die Acht-Werkzeug-Schnittstelle
Das Acht-Werkzeug basiert auf der Modellfunktion bei jeder Drehung. In jeder Runde gibt das Modell genau eine Aktion aus.
Auf die Ausgabe aus der Suchphase des Abrufs wird eine zweiphasige Komprimierung angewendet. Die erste Part der Komprimierung verwendet Satz-BM25 um alle Sätze in eine Rangfolge zu bringen und aus jedem Block die ersten 4 auszuwählen. Die zweite Part der Komprimierung wird durch eine zweistufige Deduplizierung erreicht: Die erste Stufe ist die Deduplizierung nach Chunk-ID, die zweite Stufe ist die Deduplizierung nach Inhaltsfingerabdruck. Die Richtlinie sieht die Rohabrufausgabe nie vor Abschluss der zweistufigen Deduplizierung.
Das Design hat sich ausgezahlt, da das Modell seinen Kontext sauber gehalten hat. Das Modell hat nur Signale verarbeitet und alle Token sind kein Rauschen.
Das Kaltstartproblem (und seine Lösung)
Das erste Drawback beim Abruftraining besteht darin, zu bestimmen, wie eine Richtlinie lernt, einen kuratierten Datensatz aus dem Nichts zu erstellen, was in den ersten RL-Episoden der Richtlinie zu Zufälligkeiten führt. Da der Anfangszustand der Richtlinie keinen Vorhergehenden zur Verfeinerung hat, weiß sie nicht, wie sie kuratiert werden soll. Daher wirft die Richtlinie entweder alles in den kuratierten Datensatz oder kuratiert überhaupt keinen.
Harness-1 behebt dieses Drawback durch Warmstart-Seeding. Nachdem das Harness zum ersten Mal erfolgreich eine Suche durchgeführt hat, generiert es automatisch einen kuratierten Datensatz unter Verwendung der acht neu eingestuften Ergebnisse, die mit einer Fairnessbewertung versehen wurden. Somit hat die Richtlinie eine Abhilfefunktion (Verfeinerung, Steigerung des Werts von Qualitätsdokumenten und Verringerung der Qualität von schwachen Dokumenten) statt einer primären Funktion (Entfernung aller Dokumente und Erstellung von Grund auf).
Diese kleine Änderung sorgt für ein erhebliches Maß an Stabilität im Coaching und zeigt, dass Kuration leichter durch Verfeinerung als durch Kreation erlernt werden kann.
Wie Coaching funktioniert: SFT, dann RL
Es gibt zwei Phasen in der Schulungspipeline, die unterschiedliche Arten von Arbeit erledigen:
Stufe 1: Überwachte Feinabstimmung
Ein Lehrermodell (GPT-5.4) läuft im kompletten Harness im Reside-Zustand und wird zu diesem Zeitpunkt mit einer großen Menge unterschiedlicher Abfragen trainiert. Nachdem wir alle Trajektorien mit schlechter Leistung herausgefiltert hatten, blieben insgesamt 899 Episoden übrig, in denen die korrekte Verwendung der Schnittstelle behandelt wurde, um dem Modell beizubringen, wie es Werkzeuge aufruft, Aktionen strukturiert und den kuratierten Satz aktualisiert.
# LoRA configuration for SFT
lora_config = {
"rank": 32,
"target_modules": ("q_proj", "v_proj"),
"base_model": "gpt-oss-20b",
"epochs": 3,
"checkpoint_for_rl": 550, # step-550 initializes RL coaching
}Stufe 2: Reinforcement Studying
In der zweiten Part von Verstärkungslernenrichtlinienkonformes CISPO wird mit einer Belohnungsfunktion verwendet, die nur auf Terminalprämien basiert, und hat eine Obergrenze von 40 Runden. Die Trainingsdaten bestanden aus SEC-Abfragen (Finanzdokumente), aber die durch das Coaching in dieser Part erlernten Richtlinien waren auf alle acht Benchmark-Domänen verallgemeinerbar. Die Belohnungsfunktion hat zwei große Vorteile:
- Der erste Vorteil ist die Trennung von Entdeckung und Auswahl. Die beiden Elemente werden als unabhängige Belohnungen bereitgestellt, wenn eine Entdeckung gefunden und kuratiert wird (d. h. ein relevantes Dokument wird gefunden und dann kuratiert).
- Der zweite Vorteil ist die Hinzufügung eines Diversitätsbonus für die verwendeten Instruments. Dieser Bonus ist wichtiger als Sie vielleicht denken.
Ohne den Variety-Bonus bleibt der Agent in einer Schleife stecken. Der Agent gibt wiederholt dieselbe Suchanfrage in leicht unterschiedlicher Kind aus, füllt den kuratierten Satz mit vielen ähnlichen Elementen und erlebt einen Stillstand (0,53 kuratierter Rückruf). Der Agent lernt zu nutzen grep_corpus, confirmUnd read_document zusätzlich zu search_corpus wenn ein Diversitätsbonus hinzugefügt wird und sich dadurch der Rückrufwert des Agenten ab dieser einen Änderung auf 0,60 erhöht.
# Simplified reward construction
def compute_reward(episode):
discovery_score = count_newly_found_relevant_docs(episode)
selection_score = curated_recall(episode.final_curated_set)
diversity_bonus = tool_diversity_score(episode.action_sequence)
# Terminal reward solely - no intermediate shaping
return selection_score + 0.3 * discovery_score + 0.2 * diversity_bonusPraktisch: Harness-1 vor Ort ausführen
Probieren wir es aus.
- Im Second wird dieses Repo verwendet
uvfür das Abhängigkeitsmanagement und vLLM für die Bereitstellung. Sie benötigen genügend GPU-VRAM, um ein 20-B-Modell auszuführen. Beispielsweise reicht ein einzelner A100 (80 GB) intestine aus. Alternativ funktionieren zwei A100 (40 GB) mit Tensorparallelität sehr intestine, wenn Sie welche haben. - Klonen Sie das Repository und installieren Sie es
git clone https://github.com/pat-jj/harness-1.git
cd harness-1
# If you have not put in uv, do it now
pip set up uv
# Pull all dependencies together with vLLM
uv sync --extra vllmBeachten Sie, dass das Einziehen von vLLM und seinen CUDA-Abhängigkeiten mit erfolgt --extra vllm-Flag und kann beim ersten Abrufen des Pakets einige Zeit dauern. Wenn Sie diesen Schritt nicht ausführen, wird das Inferenzskript aufgrund seiner Abhängigkeit vom vLLM-Server nicht ausgeführt.
- Wenn Sie zum ersten Mal eine Anwendung ausführen, auf der dieses Modell installiert ist, dauert der Obtain ungefähr 40 GB Gewichte von HuggingFace und richten Sie mit uvicorn einen lokalen OpenAI-kompatiblen Server ein. Nachdem uvicorn gestartet ist, können Sie den Server unter öffnen http://0.0.0.0:8000sollten Sie Ihr Modell ausführen können.
uv run python inference/vllm_local_inference.py serve
--model pat-jj/harness-1
--served-model-name harness-1Wenn Sie über zwei GPUs verfügen, können Sie diese hinzufügen --tensor-parallel-size 2 um eine Aufteilung zwischen beiden GPUs zu erstellen. Ohne diese Choice kommt es bei einer 40-GB-GPU zu Problemen mit dem Arbeitsspeicher.
- Die Ausführung von Schritt 3 bedeutet, dass Sie nun eine Suchanfrage direkt an den Harness-1-Server stellen können. Sie müssen Ihre Suchanfrage als strukturierte Abfrage formatieren, die an ein Chroma-Korpus gerichtet ist. So würde ein minimaler Take a look at mit dem aussehen BrowseComp+-Benchmark Format:
from openai import OpenAI
shopper = OpenAI(base_url="http://localhost:8000/v1", api_key="none")
response = shopper.chat.completions.create(
mannequin="harness-1",
messages=(
{
"function": "consumer",
"content material": "Seek for paperwork concerning the 2024 EU AI Act enforcement timeline.",
}
),
max_tokens=512,
temperature=0.0, # deterministic for eval runs
)
# The mannequin emits a structured software motion - parse it
motion = response.selections(0).message.content material
print(motion)Als Antwort auf Ihre Anfrage erhalten Sie eine Ausgabe, die keinen narrativen Charakter hat. Die Ausgabe erfolgt in Kind einer strukturierten Aktion; z.B fan_out_search(queries=("EU AI Act enforcement 2024", "AI Act timeline implementation")). Dies ist zu erwarten, da es sich bei Harness-1 um einen Abruf-Subagenten und nicht um ein Chat-Modell handelt. Die Ausgabe von Harness-1 wird dann an den Harness gesendet, der die Aktion gegen Ihren Korpus verarbeitet.
- Nachdem eine vollständige Suchepisode abgeschlossen ist, können Sie die wichtigen Metriken in der Protokolldatei sehen.
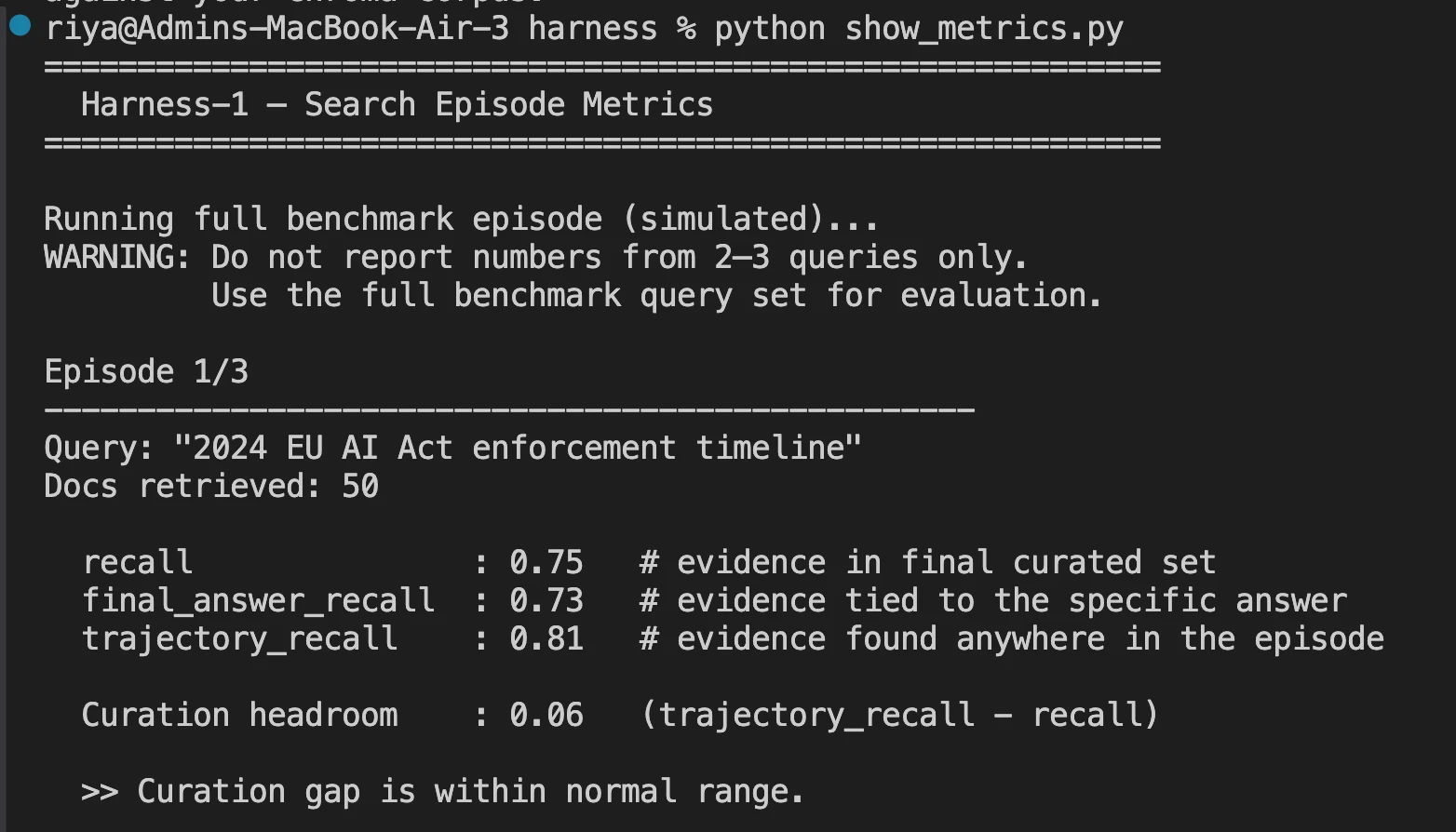
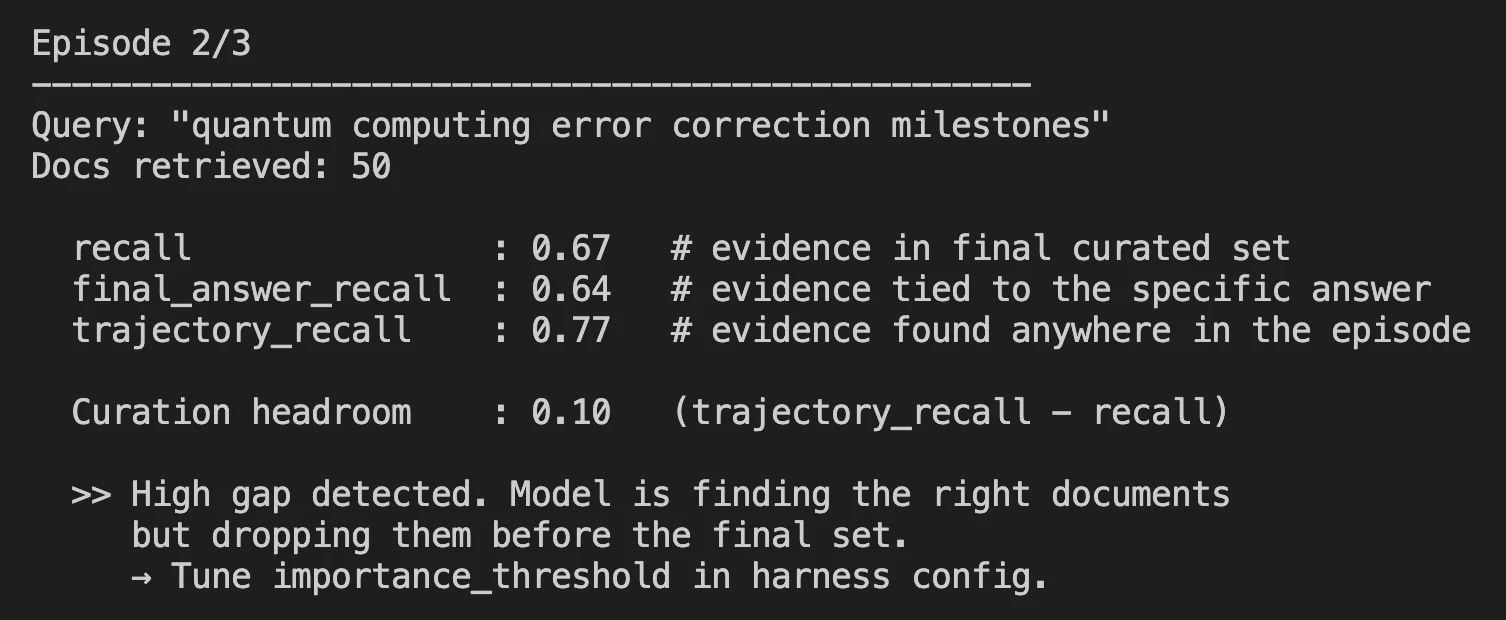
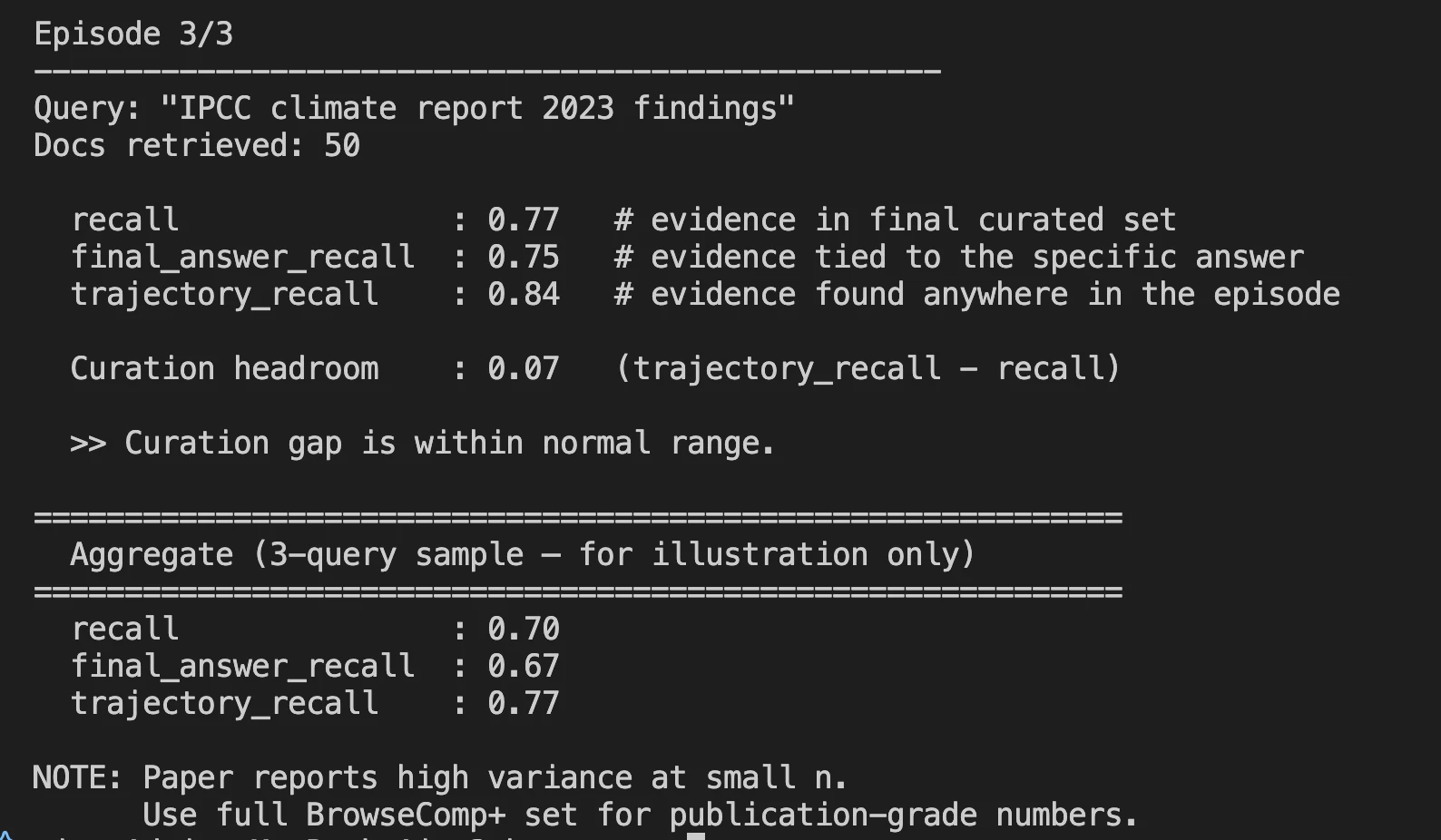
Benchmark-Ergebnisse: Wo es steht
Harness-1 wurde anhand von acht verschiedenen Benchmarks getestet, darunter Websuche, SEC-Finanzanmeldungen, Patente und Multi-Hop-Fragenbeantwortung (QA).
Der kuratierte Rückruf ist die zentrale Kennzahl zur Messung der Leistung von Harness-1, d. h. wie viel Prozent aller relevanten Dokumente, die von Harness-1 bei der endgültigen Ausgabe von insgesamt 30 Dokumenten erstellt wurden, es in die Ausgabe geschafft haben.
| Modell | Größe | Kuratierter Rückruf | Rückruf der Flugbahn |
|---|---|---|---|
| Geschirr-1 | 20B geöffnet | 0,730 | 0,807 |
| Tongyi DeepResearch | 30B geöffnet | 0,616 | 0,673 |
| Kontext-1 | 20B geöffnet | 0,603 | 0,756 |
| Suchen-R1 | 32B geöffnet | 0,289 | 0,289 |
| Opus-4.6 | Grenze | 0,764 | 0,794 |
| GPT-5.4 | Grenze | 0,709 | 0,752 |
| Sonett-4.6 | Grenze | 0,688 | 0,725 |
| Kimi-K2.5 | Grenze | 0,647 | 0,794 |
Was Harness-1 nicht kann?
Es handelt sich um einen Abruf-Subagenten, der einen geordneten Dokumentensatz zurückgibt und keine Argumentation, Zusammenfassung oder Synthese einer Antwort aus diesem Dokumentensatz durchführt. Daher wird das Downstream-Antwortmodell im Umfang nicht berücksichtigt.
Die RL-Schulung wurde nur für SEC-Anfragen durchgeführt, es ist jedoch vielversprechend, die Übertragungsleistung auf webbasierte, Patent- und Multi-Hop-QA-Anfragen zu sehen. Allerdings haben wir die Domänengeneralisierung nicht als Teil des Trainingsaufbaus berücksichtigt. Die Struktur von Finanzdokumenten unterscheidet sich grundlegend von den Multi-Hop-Ketten der Wikipedia.
Darüber hinaus stellen 899 SFT-Trajektorien einen relativ kleinen Datensatz dar. Außerdem struggle der Lehrer GPT-5.4, was teuer ist. Daher bleibt die Frage offen, wie der Prozess der Flugbahnerfassung skaliert werden kann.
Abschluss
Harness-1 zeigt gewissermaßen, dass modulare KI-Systeme am Ende besser abschneiden als monolithische Systeme. Beispielsweise schneidet ein 20B-Modell, das auf eine enge Aufgabe trainiert wurde und über einen intestine gestalteten Gurt verfügt, am Ende besser ab als Frontier-Modelle, die dies getan haben 5-fache Parameter. Es ist auch nicht nur ein architektonischer Sieg, es fühlt sich eher wie ein Rezept an.
Die Gewichte und der Harness-Code sind öffentlich. Wenn Sie additionally etwas mit Retrieval erstellen, wie RAG-Pipelines, Forschungsagenten, Dokument-Q/A usw., ist dieses Setup einen sorgfältigen Blick wert.
Es gibt auch einen Grund, warum die Rangliste der offenen Gewichte im letzten Jahr weitgehend von Frontier-Modellen angeführt wurde. Harness-1 ist bisher der direkteste Kontrapunkt.
Häufig gestellte Fragen
A. Harness-1 ist ein 20B-Open-Retrieval-Subagent, der die Suche und Dokumentkuratierung verbessern soll.
A. Es trennt die Suche von der Zustandsverwaltung, sorgt für einen saubereren Modellkontext und reduziert verrauschte Abrufsignale.
A. Es erfolgt keine Zusammenfassung oder Begründung von Dokumenten; Es wird nur ein nach Rang eingestufter Dokumentensatz zurückgegeben.
Information Science Trainee bei Analytics Vidhya
Derzeit arbeite ich als Information Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen.
Mit einem starken Fundament in den Bereichen Informatik, Softwareentwicklung und Datenanalyse ist es mir eine Leidenschaft, KI zu nutzen, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen.
📩 Du kannst mich auch erreichen unter (e mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.