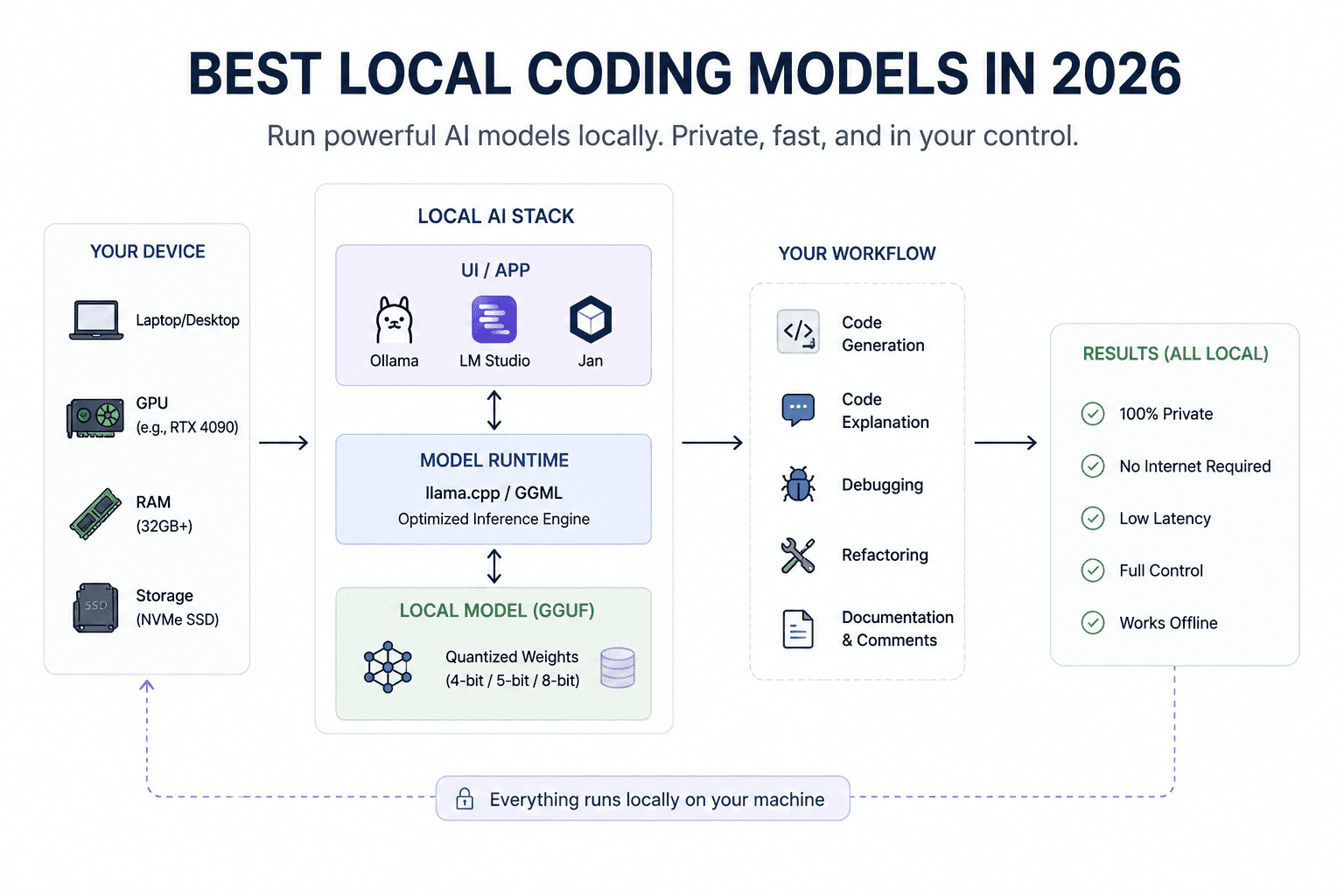
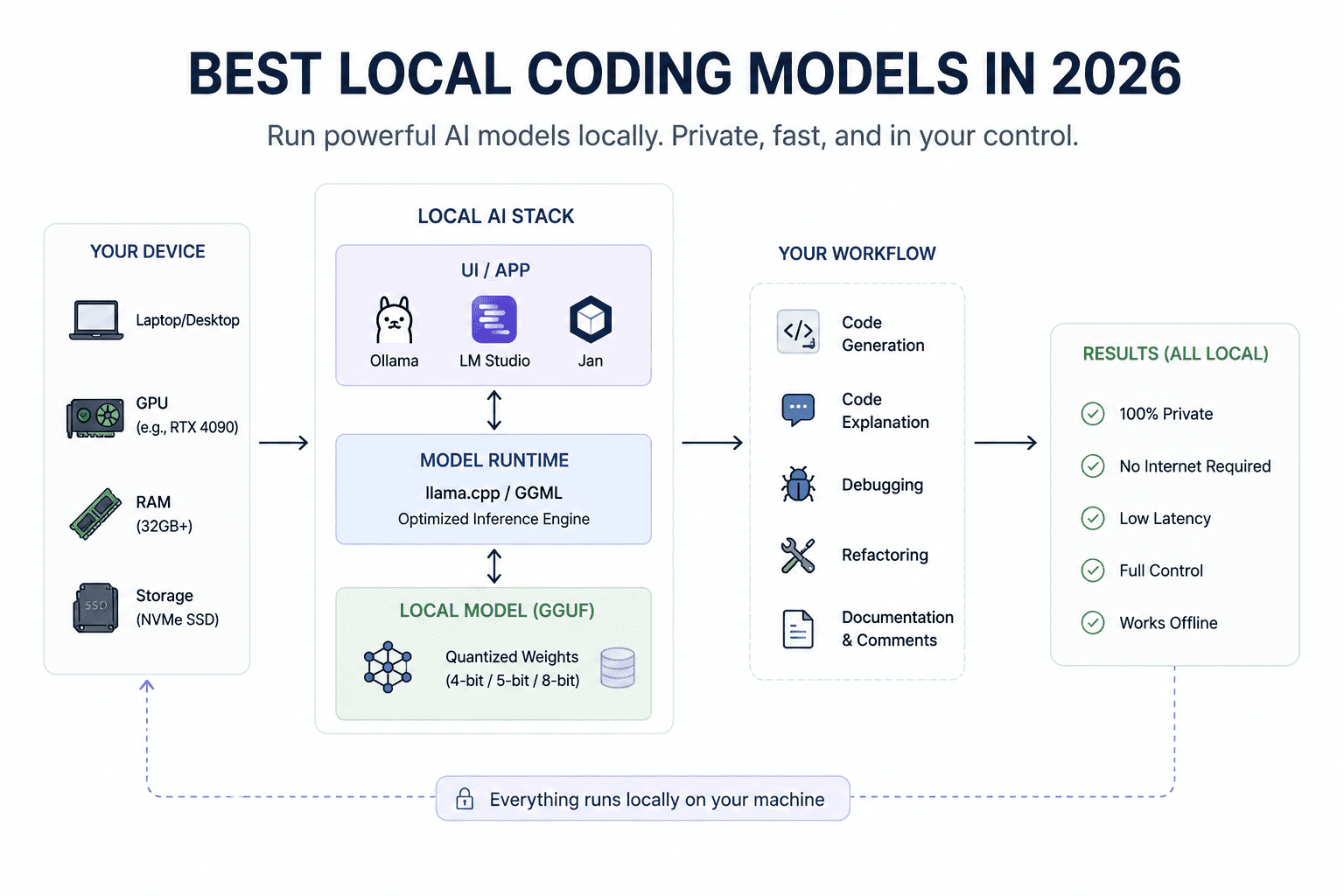
# Einführung
Lokale Codierungsmodelle nehmen endlich ernst. Ich bin ein großer Fan dieser neuen Welle lokaler Massive Language Fashions (LLMs), insbesondere der offenen Modelle und Neighborhood-GGML Common File (GGUF)-Releases, die ihre Ausführung auf Shopper-{Hardware} einfacher machen. Wir sind jetzt an einem Punkt angelangt, an dem einige dieser Modelle auf GPUs wie einer RTX 3090 laufen, schnell genug generieren können, um nützlich zu sein, und tatsächlich echte Codierungs- und Agentenprogrammierungsprobleme lösen können. Nicht nur Demos. Nicht nur Spielereien.
Wenn Sie eine vollständig lokale Codierungseinrichtung wünschen und über mindestens 16 GB Video Random Entry Reminiscence (VRAM) verfügen, können Ihnen diese Modelle dabei helfen, sich nicht nur darauf zu verlassen Claude Code, Zwillingeoder andere gehostete Codierungsassistenten. Sie sind schnell, leistungsfähig, privat und intestine genug für echte Entwicklungsworkflows.
Sie können diesen Wandel bereits in der gesamten lokalen KI-Neighborhood beobachten. Reddits r/LocalLLaMA ist voll von Entwicklern, die lokale Codierungsagenten ausführen, GGUF-Modelle testen, OpenAI-kompatible lokale Server erstellen und diese Modelle mit Editoren, Terminals und Codierungsassistenten verbinden.
# 1. Qwen3.6 27B MTP
Qwen3.6 27B MTP ist derzeit eindeutig eines meiner liebsten lokalen Codierungsmodelle. Ich habe es in verschiedenen Setups getestet, verwendet und erkundet, und es fühlt sich an, als ob es die beste Steadiness zwischen Größe, Geschwindigkeit und tatsächlichen Programmierfähigkeiten bietet.
Das Beste daran ist, dass Sie die GGUF-quantisierten Versionen auf Shopper-{Hardware} ausführen können, anstatt ein vollständiges Cloud-Setup zu benötigen. Selbst wenn Sie mit einer VRAM-GPU mit 16 GB bis 24 GB arbeiten, ist die lokale Verwendung mit den 4-Bit-Versionen viel realistischer.
Die r/LocalLLaMA-Neighborhood auf Reddit ist bereits voll von Leuten, die Qwen3.6 27B MTP auf lokale Agentencodierung, schnellere Inferenz, lama.cpp Setups und OpenAI-kompatible lokale Server. Und ehrlich gesagt macht der Hype Sinn.
Qwen-Modelle sind in der Regel intestine im Codieren, da sie Argumentation, Befolgung von Anweisungen, mehrsprachiges Verständnis, Werkzeugnutzung und Unterstützung für lange Kontexte kombinieren. Das macht Qwen3.6 27B MTP zu einem leistungsstarken, umfassenden lokalen Modell für Codierungsassistenten, Repo-Chat, Debugging, Shell-Befehle und Agenten-Workflows.
# 2. Gemma 4 31B IT QAT
Gemma 4 31B IT QAT ist ein weiteres Modell, das meiner Meinung nach einen ernstzunehmenden Platz in jedem lokalen Codierungs-Setup verdient. Die offenen Gemma-Modelle von Google waren schon immer intestine für Leute, die leistungsfähige Modelle lokal ausführen möchten, und diese GGUF-Model mit quantisierungsbewusstem Coaching (QAT) macht sie noch praktischer.
Sie erhalten ein großes 31B-Modell in einem quantisierten 4-Bit-Format, das sich viel einfacher auf Shopper-{Hardware} laden lässt und dennoch eine hohe Qualität bietet. Es ist auch nicht nur ein Hype. Ich habe über Gemma-Modelle geschrieben, sie verwendet, sie in verschiedenen Arbeitsabläufen getestet und sie fühlen sich der Qwen-Serie sehr nahe, wenn es um lokale Codierung und Argumentation geht.
Der Hauptgrund, warum sich Gemma 4 31B auszeichnet, ist, dass es sich nicht nur um ein Codierungsmodell handelt. Es ist außerdem multimodal, was bedeutet, dass es bei Screenshots, UI-Problemen, Diagrammen, Dokumentationsbildern und Net-App-Layouts helfen kann und gleichzeitig für die Codegenerierung, das Debuggen und die Planung nützlich ist.
Auch die offiziellen Benchmark-Zahlen machen es schwer, es zu ignorieren, mit starken Codierungsergebnissen bei LiveCodeBench und Codeforces. Wenn Sie ein lokales Modell suchen, das Codierungs- und visuelle Entwicklungsaufgaben bewältigen kann, ist Gemma 4 31B IT QAT eine der besten Optionen zum Ausprobieren.
# 3. DiffusionGemma 26B A4B
DiffusionGemma 26B A4B ist eines der neuesten und interessantesten Modelle auf dieser Liste. Es ist leistungsstark, experimentell und anders aufgebaut als die üblichen Token-für-Token-Sprachmodelle.
Anstatt Textual content auf die standardmäßige autoregressive Weise zu generieren, wird ein Blockdiffusionsansatz verwendet, der die Generierungsgeschwindigkeit durch paralleles Entrauschen von Tokenblöcken verbessern soll.
Aus diesem Grund ist dieses Modell für die lokale Codierung interessant: Es fühlt sich an wie die Artwork von Architektur, die lokale Assistenten viel schneller machen könnte, insbesondere bei der Codegenerierung, strukturierten Ausgaben und schnellen Argumentationsaufgaben.
Der Hauptvorteil liegt in der Effizienz. DiffusionGemma hat etwa 25 Milliarden Gesamtparameter, aber nur etwa 3,8 Milliarden aktive Parameter, sodass Sie von einem größeren Modell im Combination of Consultants (MoE)-Stil profitieren, ohne die vollen Inferenzkosten eines dichten 26B-Modells zu zahlen.
# 4. Nemotron Cascade 2 30B A3B
Nemotron Cascade 2 30B A3B ist ein weiteres Modell, das auf dem Papier seltsam aussieht, für die lokale Codierung jedoch sehr sinnvoll ist.
Es handelt sich um ein 30B-Modell im MoE-Stil, bei der Inferenz sind jedoch nur etwa 3B-Parameter aktiv. Sie zahlen additionally nicht jedes Mal die vollen Kosten eines dichten 30B-Modells. Das ist genau die Artwork von Modell, die ich für lokale Setups magazine: groß genug, um vernünftig zu argumentieren, aber dennoch effizient genug, um es tatsächlich auf Ihrem eigenen Laptop auszuführen und zu testen.
Das Spannende an diesem Modell ist, dass es sich eher wie ein Argumentationsmodell anfühlt als wie ein einfaches Modell zur automatischen Vervollständigung der Codierung. NVIDIA beschreibt es als stark für Denk- und Agentenaufgaben, mit Denk- und Unterrichtsmodi, und behauptet sogar, bei der Internationalen Mathematikolympiade (IMO) 2025 und der Internationalen Informatikolympiade (IOI) 2025 eine Leistung auf Goldmedaillenniveau zu erzielen.
Für Entwickler ist das wichtig, denn beim Codieren geht es nicht mehr nur darum, Funktionen zu schreiben. Sie möchten, dass das Modell Code debuggt, plant, überprüft, mehrstufige Probleme versteht und anhand von Implementierungsdetails Schlüsse zieht.
# 5. Qwen3.5 9B MTP
Qwen3.5 9B MTP ist das kleinere Modell in dieser Liste, aber unterschätzen Sie es nicht.
Für seine Gewichtsklasse schneidet es wirklich intestine ab und bietet Ihnen einen richtigen, modernen Codierungsassistenten im Qwen-Stil, ohne dass Sie eine riesige Workstation benötigen. Wenn Sie ein kleineres lokales Setup haben, ist dieses Modell ein Juwel. Es ist schnell, praktisch und viel einfacher zu bedienen als die Modelle 27B oder 31B.
Die GGUF-Model macht es für alltägliche Entwickler noch nützlicher. Sie benötigen keine komplizierte Einrichtung oder teure Cloud-Instanz, nur um es zu testen. Sie können es lokal ausführen, es mit Ihrem Editor oder Terminal-Workflow verbinden und es wie einen privaten Codierungsassistenten verwenden.
Bei komplexen Schlussfolgerungen wird es die größeren Modelle nicht schlagen, aber für tägliche Codierungsaufgaben ist es mehr als ausreichend. Sie können es für kleine Skripte, Debugging, Codeerklärungen, Shell-Befehle und schnelle lokale Assistenten-Workflows verwenden. Für Leute, die mit lokalen Codierungsmodellen beginnen, ist Qwen3.5 9B MTP wahrscheinlich eine der sichersten und praktischsten Optionen.
# 6. EXAONE 4.5 33B
EXAONE 4.5 33B ist ein weiteres Modell, das Entwickler meiner Meinung nach nicht ignorieren sollten, insbesondere wenn Ihre Arbeit mehr als nur einfachen Code umfasst.
Es handelt sich um das offene multimodale Modell von LG AI Analysis, was es wirklich nützlich für lokale Codierungsworkflows macht, bei denen Sie auch Screenshots, PDFs, Diagramme, Dokumentationen und UI-Layouts verstehen müssen.
Hier wird EXAONE interessant. Ein Großteil der Codierungsarbeit besteht mittlerweile nicht nur darin, Python-Funktionen zu schreiben. Sie lesen Dokumente, überprüfen Fehler anhand von Screenshots, verstehen Architekturdiagramme und arbeiten mit unübersichtlichen Projektdateien. Ein Modell, das sowohl Textual content- als auch visuelle Eingaben verarbeiten kann, wird viel nützlicher.
Wenn Sie ein lokales Modell für Code plus Dokumente, Screenshots und Workflows im Unternehmensstil wünschen, ist EXAONE 4.5 33B eine gute Possibility zum Ausprobieren.
# 7. North Mini Code 1.0
North Mini Code 1.0 ist eines der neuesten Modelle auf dieser Liste, und es ist schön zu sehen, dass Cohere endlich richtig in den Bereich der lokalen Codierungsmodelle einsteigt.
Dies ist kein allgemeiner Chatbot, der zufällig auch Code schreibt. Es ist für die Codegenerierung, das Agenten-Software program-Engineering und terminalbasierte Aufgaben konzipiert. Das macht es viel interessanter für Entwickler, die ein lokales Modell für Repo-Bearbeitungen, Befehlszeilenhilfe, Codeüberprüfung und Coding-Agent-Workflows wünschen.
Es handelt sich außerdem um ein 30B-A3B-Modell, was bedeutet, dass es 30B Gesamtparameter, aber nur etwa 3B aktive Parameter während der Inferenz hat. Sie erhalten additionally wieder eine gute Steadiness: stärkere Argumentation als kleine Modelle, aber immer noch effizienter als ein 30B-Modell mit voller Dichte.
Es ist möglicherweise nicht so umfassend wie Qwen3.6 27B oder Gemma 4 31B, aber für codierungsspezifische Arbeiten scheint North Mini Code 1.0 ein sehr praktisches Modell zum Ausprobieren zu sein.
# Letzte Gedanken
Diese Tabelle gibt Ihnen einen schnellen Überblick darüber, welches lokale Codierungsmodell Sie basierend auf Ihrer {Hardware}, Ihrem Workflow und Ihrem Codierungsanwendungsfall auswählen sollten.
| Modell | Größe / Typ | Bester Anwendungsfall | Warum es wählen? |
|---|---|---|---|
| Qwen3.6 27B MTP | 27B MTP | Starke lokale Codierung, Argumentation und Agenten-Workflows | Bestes umfassendes lokales Codierungsmodell |
| Gemma 4 31B IT QAT | 31B, 4-Bit-QAT, multimodal | Codierung plus Screenshots, UI-Bugs, Diagramme und Arbeiten mit langen Kontexten | Starke Codierungs-Benchmarks und multimodale Unterstützung |
| DiffusionGemma 26B A4B | 26B / ~4B aktiv | Schnelles, experimentelles lokales Codieren und Denken | Neue Architektur konzentriert sich auf effiziente Erzeugung |
| Nemotron Cascade 2 30B A3B | 30B / ~3B aktiv | Agentencodierung, Debugging, Planung und begründungsintensive Aufgaben | Fühlt sich eher wie ein Argumentationsagent als wie eine automatische Vervollständigung an |
| Qwen3.5 9B MTP | 9B MTP | Kleinere lokale Maschinen und tägliche Codierungshilfe | Schnell, praktisch und für seine Gewichtsklasse großartig |
| EXAONE 4.5 33B | 33B multimodal | Code, Dokumente, Screenshots, PDFs und Diagramme | Perfect für dokumentenintensive und visuelle Codierungsworkflows |
| North Mini Code 1.0 | 30B / ~3B aktives Codierungsmodell | Lokale Codierungsagenten, Repo-Bearbeitungen, Terminalaufgaben und Codeüberprüfung | Das codierungsspezifischste Modell in der Liste |
Lokale Codierungsmodelle sind mittlerweile so intestine, dass Sie sie tatsächlich für echte Entwicklungsarbeit verwenden können, nicht nur zum Testen oder Herumspielen. Wenn Sie eine gute GPU wie eine RTX 3090 oder 4090 haben, würde ich einfach empfehlen, mit Qwen3.6 27B MTP in 4-Bit zu beginnen. Es ist die beste Allround-Possibility für lokale Codierung, Argumentation und Agenten-Workflows. Ehrlich gesagt, probieren Sie das zuerst aus, bevor Sie Zeit damit verschwenden, zwischen zu vielen Modellen zu wechseln.
Wenn Sie die schnellste lokale Era auf ähnlicher {Hardware} wünschen, sollten Sie sich DiffusionGemma 26B A4B ansehen. Es ist neuer und experimenteller, aber die Architektur macht es wirklich interessant für Entwickler, denen Geschwindigkeit und effiziente Inferenz wichtig sind.
Wenn Sie multimodales Verständnis, besseres Denken und die Fähigkeit zum Arbeiten mit Code sowie Screenshots, UI-Layouts, Diagrammen und Dokumentation wünschen, ist Gemma 4 31B IT QAT eine gute Wahl. Es ist mehr als nur ein Codierungsmodell und daher für moderne Entwicklungsworkflows nützlich.
Und wenn Sie keine große GPU haben, ist Qwen3.5 9B MTP wahrscheinlich das beste Modell seiner Gewichtsklasse. Selbst mit einer einfacheren lokalen Einrichtung und genügend System-RAM kann es immer noch intestine als täglicher Codierungsassistent für Erklärungen, Debugging, Skripte, Shell-Befehle und allgemeine Workflow-Hilfe funktionieren.
Auch die restlichen Modelle sind je nach Interesse einen Check wert.
Nemotron Cascade 2 30B A3B eignet sich hervorragend, wenn Sie ein lokales Argumentationsmodell für Agentencodierung, Planung, Debugging und strukturierte Problemlösung benötigen.
EXAONE 4.5 33B ist nützlich, wenn Ihre Arbeit Dokumente, PDFs, Screenshots und Codierungsworkflows im Unternehmensstil umfasst.
North Mini Code 1.0 ist die am stärksten auf Codierung ausgerichtete Possibility und scheint für lokale Coding-Agenten, Repo-Bearbeitungen, Terminalaufgaben und Codeüberprüfung vielversprechend zu sein. Sie sind vielleicht nicht für jeden meine erste Wahl, aber jeder hat eine klare Daseinsberechtigung.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu maschinellem Lernen und Datenwissenschaftstechnologien. Abid verfügt über einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI-Produkt mithilfe eines graphischen neuronalen Netzwerks für Schüler mit psychischen Erkrankungen zu entwickeln.