
Erstellen KI-Agenten die mit der realen Welt interagieren können, ist ein großartiger Forschungs- und Entwicklungsbereich. Eine nützliche Anwendung ist die Erstellung von Agenten, die das Web durchsuchen können, um Informationen zu sammeln und Aufgaben zu erledigen. Dieser Blogbeitrag führt Sie durch den Prozess der Erstellung eines solchen Agenten mithilfe von LangChain, einem Framework für die Entwicklung von LLM-basierten Anwendungen, und Llama 3.3, einem hochmodernen großes Sprachmodell.
Lernziele
- Verstehen Sie, wie Sie einen KI-Agenten erstellen LangChain Und Lama 3.3 für Internet-Suchaufgaben.
- Erfahren Sie, wie Sie externe Wissensquellen wie ArXiv und Wikipedia in einen Internet-Suchagenten integrieren.
- Sammeln Sie praktische Erfahrungen beim Einrichten der Umgebung und der erforderlichen Instruments für die Entwicklung einer KI-gestützten Internet-App.
- Entdecken Sie die Rolle von Modularität und Fehlerbehandlung bei der Erstellung zuverlässiger KI-gesteuerter Anwendungen.
- Erfahren Sie, wie Sie Streamlit zum Erstellen von Benutzeroberflächen verwenden, die nahtlos mit KI-Agenten interagieren.
Dieser Artikel wurde im Rahmen der veröffentlicht Information Science-Blogathon.
Was ist Lama 3.3?
Llama 3.3 ist ein von Meta entwickeltes, auf Anweisungen abgestimmtes, großes Sprachmodell mit 70 Milliarden Parametern. Es ist für eine bessere Leistung bei textbasierten Aufgaben optimiert, einschließlich der Befolgung von Anweisungen, der Codierung und der mehrsprachigen Verarbeitung. Im Vergleich übertrifft es seine Vorgänger, darunter Llama 3.1 70B und Llama 3.2 90B. In einigen Bereichen kann es sogar mit größeren Modellen wie dem Llama 3.1 405B mithalten und spart gleichzeitig Kosten.
Funktionen von Lama 3.3
- Befehlsabstimmung: Llama 3.3 ist darauf abgestimmt, Anweisungen genau zu befolgen, was es äußerst effektiv für Aufgaben macht, die Präzision erfordern.
- Mehrsprachige Unterstützung: Das Modell unterstützt mehrere Sprachen, darunter Englisch, Spanisch, Französisch, Deutsch, Hindi, Portugiesisch, Italienisch und Thailändisch, und erhöht so seine Vielseitigkeit in verschiedenen sprachlichen Kontexten.
- Kosteneffizienz: Mit wettbewerbsfähigen Preisen kann Llama 3.3 eine erschwingliche Lösung für Entwickler sein, die leistungsstarke Sprachmodelle ohne übermäßige Kosten wünschen.
- Zugänglichkeit: Seine optimierte Architektur ermöglicht den Einsatz auf einer Vielzahl von Hardwarekonfigurationen, einschließlich CPUs, wodurch es für eine Vielzahl von Anwendungen zugänglich ist.
Was ist LangChain?
LangChain ist ein Open-Supply-Framework, das sich zum Erstellen von Anwendungen eignet, die auf großen Sprachmodellen (LLMs) basieren. Die Suite aus Instruments und Abstraktionen vereinfacht die Integration von LLMs in verschiedene Anwendungen und ermöglicht Entwicklern die einfache Erstellung anspruchsvoller KI-gesteuerter Lösungen.
Hauptmerkmale von LangChain
- Verkettbare Komponenten: LangChain ermöglicht Entwicklern die Erstellung komplexer Arbeitsabläufe durch die Verkettung verschiedener Komponenten oder Instruments und erleichtert so die Entwicklung komplexer Anwendungen.
- Software-Integration: Es unterstützt die Integration verschiedener Instruments und APIs und ermöglicht so die Entwicklung von Agenten, die problemlos mit externen Systemen interagieren können.
- Speicherverwaltung: LangChain bietet Mechanismen zur Verwaltung des Konversationskontexts und ermöglicht es Agenten, den Standing über Interaktionen hinweg aufrechtzuerhalten.
- Erweiterbarkeit: Das Framework nimmt nach Bedarf benutzerdefinierte Komponenten und Integrationen auf und ist somit leicht erweiterbar.
Kernkomponenten eines Internet-Suchagenten
Unser Internet-Suchagent besteht aus den folgenden Schlüsselkomponenten:
- LLM (Lama 3.3): Das Gehirn des Agenten, das dafür verantwortlich ist, Benutzeranfragen zu verstehen, Suchanfragen zu generieren und die Ergebnisse zu verarbeiten.
- Suchwerkzeug: Ein Software, mit dem der Agent Websuchen durchführen kann. Zu diesem Zweck verwenden wir eine Suchmaschinen-API.
- Eingabeaufforderungsvorlage: Eine Vorlage, die die für das LLM bereitgestellten Eingaben strukturiert und sicherstellt, dass es die erforderlichen Informationen im richtigen Format erhält.
- Agent-Ausführender: Die Komponente, die die Interaktion zwischen dem LLM und den Instruments orchestriert und die Aktionen des Agenten ausführt.
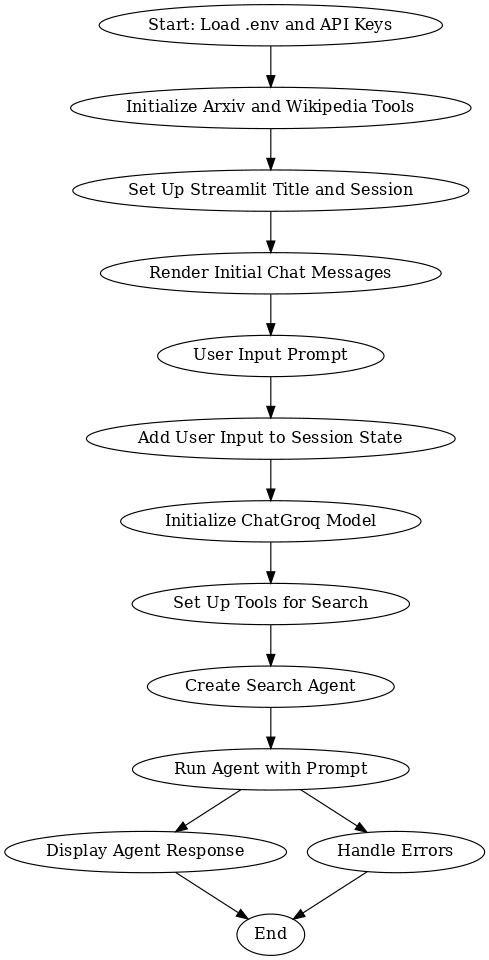
Flussdiagramm
Dieser Workflow beschreibt den Prozess der Integration mehrerer Instruments und Modelle zur Erstellung eines interaktiven Programs mit Arxiv, Wikipedia und ChatGroq, unterstützt von Streamlit. Zunächst werden die erforderlichen API-Schlüssel geladen und die erforderlichen Instruments eingerichtet. Der Benutzer wird dann aufgefordert, seine Abfrage einzugeben, die im Sitzungsstatus gespeichert wird. Das ChatGroq-Modell verarbeitet diese Eingaben, während Suchtools relevante Informationen von Arxiv und Wikipedia sammeln. Der Suchagent kombiniert die Antworten und zeigt dem Benutzer eine relevante Antwort an.
Der Prozess stellt eine nahtlose Benutzerinteraktion sicher, indem die Instruments initialisiert, Benutzereingaben verwaltet und genaue Antworten bereitgestellt werden. Im Falle von Fehlern behandelt das System diese ordnungsgemäß und sorgt so für ein reibungsloses Erlebnis. Insgesamt ermöglicht dieser Workflow dem Benutzer, effizient Antworten auf der Grundlage von Echtzeitdaten zu erhalten und dabei leistungsstarke Such- und KI-Modelle für eine umfassende und informative Konversation zu nutzen.
Einrichten der Foundation
Das Einrichten der Foundation ist der erste entscheidende Schritt bei der Vorbereitung Ihrer Umgebung auf eine effiziente Verarbeitung und Interaktion mit den für die Aufgabe erforderlichen Instruments und Modellen.
Umgebungseinrichtung
Die Einrichtung der Umgebung umfasst die Konfiguration der erforderlichen Instruments, API-Schlüssel und Einstellungen, um einen reibungslosen Arbeitsablauf für das Projekt sicherzustellen.
# Create a Surroundings
python -m venv env
# Activate it on Home windows
.envScriptsactivate
# Activate in MacOS/Linux
supply env/bin/activateInstallieren Sie die Datei „Necessities.txt“.
pip set up -r https://uncooked.githubusercontent.com/Gouravlohar/Search-Agent/refs/heads/grasp/necessities.txtAPI-Schlüssel-Setup
Machen Sie ein .env Legen Sie Ihr Projekt ab und besuchen Sie es Groq für API-Schlüssel.
Nachdem Sie Ihren API-Schlüssel erhalten haben, fügen Sie ihn in Ihr ein .env Datei
GROQ_API_KEY="Your API KEY PASTE HERE"Schritt 1: Notwendige Bibliotheken importieren
import streamlit as st
from langchain_groq import ChatGroq
from langchain_community.utilities import ArxivAPIWrapper, WikipediaAPIWrapper
from langchain_community.instruments import ArxivQueryRun, WikipediaQueryRun
from langchain.brokers import initialize_agent, AgentType
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler # Up to date import
import os
from dotenv import load_dotenvImportieren Sie Bibliotheken, um die Webanwendung zu erstellen, mit Llama 3.3 zu interagieren, ArXiv- und Wikipedia-Instruments abzufragen, Agenten zu initialisieren, Rückrufe zu verarbeiten und Umgebungsvariablen zu verwalten.
Schritt 2: Umgebungsvariablen laden
load_dotenv()
api_key = os.getenv("GROQ_API_KEY") - load_dotenv(): Umgebungsvariablen aus der .env-Datei im Projektverzeichnis abrufen. Dies ist eine sichere Möglichkeit, wise Daten zu verwalten.
- os.getenv(“GROQ_API_KEY”): Ruft den GROQ_API_KEY aus der Umgebung (.env-Datei) ab, der zur Authentifizierung von Anforderungen an Groq-APIs erforderlich ist.
Schritt 3: ArXiv- und Wikipedia-Instruments einrichten
arxiv_wrapper = ArxivAPIWrapper(top_k_results=1, doc_content_chars_max=200)
arxiv = ArxivQueryRun(api_wrapper=arxiv_wrapper)
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=200)
wiki = WikipediaQueryRun(api_wrapper=api_wrapper)- top_k_results=1: Gibt an, dass nur das oberste Ergebnis abgerufen werden soll.
- doc_content_chars_max=200: Dadurch wird die Länge des abgerufenen Dokumentinhalts für Zusammenfassungen auf 200 Zeichen begrenzt.
- ArxivQueryRun und WikipediaQueryRun: Verbinden Sie die Wrapper mit ihren jeweiligen Abfragemechanismen, sodass der Agent Suchvorgänge ausführen und Ergebnisse effizient abrufen kann.
Schritt 4: Festlegen des App-Titels
st.title("🔎Search Internet with Llama 3.3")Legen Sie einen benutzerfreundlichen Titel für die Internet-App fest, um ihren Zweck anzugeben.
Schritt 5: Sitzungsstatus initialisieren
if "messages" not in st.session_state:
st.session_state("messages") = (
{"function": "assistant", "content material": "Hello, I can search the online. How can I aid you?"}
)Richten Sie einen Sitzungsstatus ein, um Nachrichten zu speichern und sicherzustellen, dass der Chatverlauf während der gesamten Benutzersitzung bestehen bleibt.
Schritt 6: Chat-Nachrichten anzeigen
for msg in st.session_state.messages:
st.chat_message(msg("function")).write(msg('content material'))- st.chat_message(): Es zeigt Nachrichten in der Chat-Oberfläche an. Die msg („function“) bestimmt, ob die Nachricht vom „Benutzer“ oder vom „Assistenten“ stammt.
Schritt 7: Benutzereingaben verarbeiten
if immediate := st.chat_input(placeholder="Enter Your Query Right here"):
st.session_state.messages.append({"function": "consumer", "content material": immediate})
st.chat_message("consumer").write(immediate)- st.chat_input(): Erstellt ein Eingabefeld, in das der Benutzer seine Frage eingeben kann.
- Benutzernachrichten hinzufügen: Hängt die Fragen des Benutzers an den Sitzungsstatus an und zeigt ihn in der Chat-Oberfläche an.
Schritt 8: Initialisieren des Sprachmodells
llm = ChatGroq(groq_api_key=api_key, model_name="llama-3.3-70b-versatile", streaming=True)
instruments = (arxiv, wiki)- groq_api_key: Verwendet den API-Schlüssel zur Authentifizierung.
- Modellname: Gibt die zu verwendende Llama 3.3-Modellvariante an.
- Streaming=True: Ermöglicht die Generierung von Antworten in Echtzeit im Chat-Fenster.
- Werkzeuge: Enthält die Abfragetools ArXiv und Wikipedia und stellt sie dem Agenten zur Nutzung zur Verfügung.
Schritt 9: Initialisierung des Suchagenten
search_agent = initialize_agent(instruments, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors=True)Kombinieren Sie sowohl die Instruments als auch das Sprachmodell, um einen Zero-Shot-Agenten zu erstellen, der Websuchen durchführen und Antworten bereitstellen kann.
Schritt 10: Generieren der Antwort des Assistenten
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container(), expand_new_thoughts=False)
attempt:
response = search_agent.run(({"function": "consumer", "content material": immediate}), callbacks=(st_cb))
st.session_state.messages.append({'function': 'assistant', "content material": response})
st.write(response)
besides ValueError as e:
st.error(f"An error occurred: {e}")- st.chat_message(„Assistent“): Zeigt die Antwort des Assistenten in der Chat-Oberfläche an.
- StreamlitCallbackHandler: Verwaltet, wie Zwischenschritte oder Gedanken in Streamlit angezeigt werden.
- search_agent.run(): Führt die Überlegungen und Instruments des Agenten aus, um eine Antwort zu generieren.
- Eingang: Eine formatierte Liste mit der Eingabeaufforderung des Benutzers.
Stellt sicher, dass die App Probleme (z. B. ungültige Antworten) ordnungsgemäß behandelt und bei Bedarf eine Fehlermeldung anzeigt.
Ausgabe
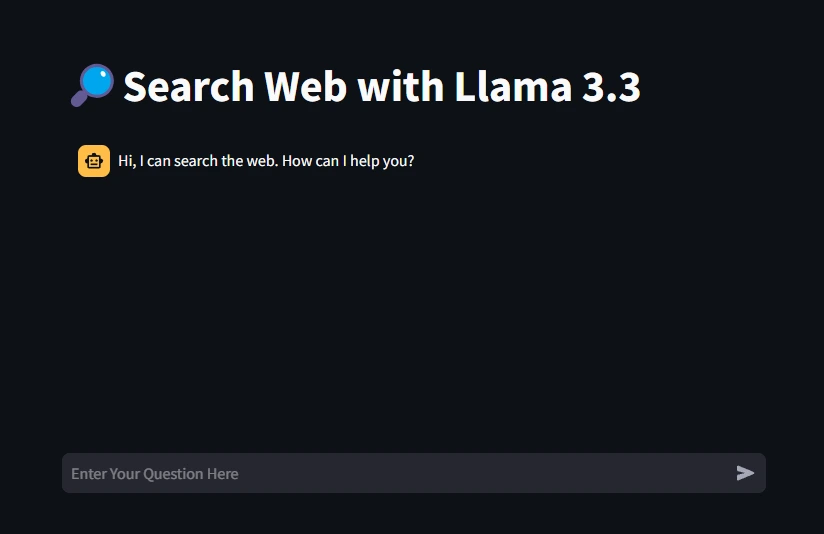
Testen der Webapp
- Eingang: Was ist ein Gradientenabstiegsalgorithmus?
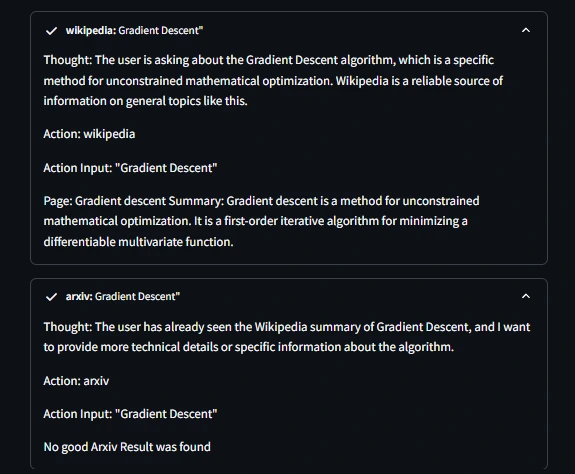

Der Agent stellt Gedankenausgaben zwischen beiden Instruments bereit
Holen Sie sich den vollständigen Code im GitHub Repo Hier
Abschluss
Der Aufbau eines Internet-Suchagenten mit LangChain und Llama 3.3 zeigt, wie die Kombination modernster KI mit externen Wissensquellen wie ArXiv und Wikipedia reale Anwendungen ermöglichen kann, die die Lücke zwischen Konversations-KI und realen Anwendungen schließen. Mit diesem Ansatz können Benutzer mühelos genaue, kontextbezogene Informationen abrufen. Das Projekt nutzt Instruments wie Streamlit für die Benutzerinteraktion und Umgebungsvariablen für die Sicherheit, um Benutzern ein nahtloses und sicheres Erlebnis zu bieten.
Der modulare Aufbau ermöglicht eine einfache Festlegung des Umfangs und die Anpassung des gesamten Programs an Domänen und sogar Anwendungsfälle. Durch diese Modularität, insbesondere bei unseren KI-gesteuerten Agenten wie diesem Beispiel, schaffen wir enorme Schritte hin zu intelligenteren Systemen, die die menschlichen Fähigkeiten für Fähigkeiten in Forschung und Bildung erweitern; tatsächlich sogar noch viel weiter. Diese Forschung dient als Basisplattform für die Entwicklung noch intelligenterer interaktiver Instruments, die das hohe Potenzial der KI bei der Wissenssuche nutzen.
Wichtige Erkenntnisse
- Dieses Projekt zeigt, wie man ein Sprachmodell wie Llama 3.3 mit Instruments wie ArXiv und Wikipedia kombiniert, um einen robusten Internet-Suchagenten zu erstellen.
- Streamlit bietet eine einfache Möglichkeit zum Erstellen und Bereitstellen interaktiver Internet-Apps und eignet sich daher preferrred für chatbasierte Instruments.
- Umgebungsvariablen schützen vertrauliche Anmeldeinformationen wie API-Schlüssel, indem sie die Offenlegung in der Codebasis verhindern.
- Es behandelt Parsing-Fehler in den KI-Agenten und sorgt so für eine bessere Zuverlässigkeit und Benutzererfahrung in der Anwendung.
- Dieser Ansatz gewährleistet Modularität durch Wrapper, Abfragetools und LangChain-Agenten und ermöglicht eine einfache Erweiterung mit zusätzlichen Instruments oder APIs.
Häufig gestellte Fragen
A. Llama 3.3 ist ein vielseitiges Sprachmodell, das komplexe Abfragen verarbeiten und verstehen kann. Es wird wegen seiner fortgeschrittenen Denkfähigkeiten und der Erzeugung natürlicher Sprache verwendet.
A. Diese Plattformen bieten Zugriff auf Forschungsarbeiten und Daten und eignen sich daher preferrred für wissensbasierte Websucher.
A. Streamlit bietet ein intuitives Framework zum Erstellen einer Chat-Schnittstelle, das eine nahtlose Interaktion zwischen dem Benutzer und dem KI-Agenten ermöglicht.
A. Dank der Modularität von LangChain können wir andere Instruments integrieren, um die Fähigkeiten des Agenten zu erweitern.
A. Wir verwalten Fehler mithilfe eines Attempt-Besides-Blocks und stellen so sicher, dass die App sinnvolles Suggestions liefert, anstatt abzustürzen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Hallo, ich bin Gourav, ein Information-Science-Fanatic mit mittleren Kenntnissen in statistischer Analyse, maschinellem Lernen und Datenvisualisierung. Meine Reise in die Welt der Daten begann mit der Neugier, Erkenntnisse aus Datensätzen zu gewinnen.