
Im schnell wachsenden Bereich der digitalen Gesundheitsversorgung werden medizinische Chatbots zu einem wichtigen Werkzeug
zur Verbesserung der Patientenversorgung und zur schnellen und zuverlässigen Bereitstellung von Informationen. In diesem Artikel wird erläutert, wie Sie einen medizinischen Chatbot erstellen, der mehrere Vectorstores verwendet. Der Schwerpunkt liegt auf der Erstellung eines Chatbots, der von Benutzern hochgeladene medizinische Berichte verstehen und auf der Grundlage der Informationen in diesen Berichten Antworten geben kann.
Darüber hinaus nutzt dieser Chatbot einen weiteren Vectorstore, der mit Gesprächen zwischen Ärzten und Patienten über verschiedene medizinische Themen gefüllt ist. Dieser Ansatz ermöglicht es dem Chatbot, über ein breites Spektrum an medizinischem Wissen und Beispielen für Patienteninteraktionen zu verfügen und so personalisierte und relevante Antworten auf Benutzerfragen zu geben. Ziel dieses Artikels ist es, Entwicklern und Gesundheitsexperten einen klaren Leitfaden für die Entwicklung eines medizinischen Chatbots zu bieten, der eine hilfreiche Ressource für Patienten sein kann, die auf der Grundlage ihrer eigenen Gesundheitsberichte und Bedenken nach Informationen und Rat suchen.
Lernziele
- Erfahren Sie, wie Sie medizinische Open-Supply-Datensätze nutzen, um einen Chatbot für Arzt-Patienten-Gespräche zu trainieren.
- Erfahren Sie, wie Sie einen Vectorstore-Dienst für einen effizienten Datenabruf erstellen und implementieren.
- Erwerben Sie Fähigkeiten zur Integration große Sprachmodelle (LLMs) und Einbettungen zur Verbesserung der Chatbot-Leistung.
- Erfahren Sie, wie Sie mit LangChain, Milvus und Cohere einen Multi-Vektor-Chatbot für verbesserte KI-Konversationen erstellen.
- Verstehen Sie, wie Sie Vektorspeicher und Abrufmechanismen für kontextbezogene, effiziente Chatbot-Antworten integrieren.
Dieser Artikel wurde im Rahmen der veröffentlicht Information Science-Blogathon.
Erstellen eines Multi-Vektor-Chatbots mit LangChain, Milvus und Cohere
Der Aufbau eines medizinischen Chatbots, der in der Lage ist, Anfragen basierend auf medizinischen Berichten und Gesprächen zu verstehen und zu beantworten, erfordert eine sorgfältig geplante Pipeline. Diese Pipeline integriert verschiedene Dienste und Datenquellen, um Benutzeranfragen zu verarbeiten und genaue, kontextbezogene Antworten zu liefern. Im Folgenden skizzieren wir die Schritte zum Aufbau dieser ausgefeilten Chatbot-Pipeline.
Hinweis: Die Dienste wie Logger, Vektorspeicher, LLM und Einbettungen wurden aus anderen Modulen importiert. Sie können darauf zugreifen dieses Repository. Stellen Sie sicher, dass Sie alle API-Schlüssel und Vektorspeicher-URLs hinzufügen, bevor Sie das Pocket book ausführen.
Schritt 1: Erforderliche Bibliotheken und Module importieren
Wir beginnen mit dem Importieren der erforderlichen Daten Python-Bibliotheken und Module. Die dotenv-Bibliothek lädt Umgebungsvariablen, die für die sichere Verwaltung vertraulicher Informationen unerlässlich sind. Das Modul src.companies enthält benutzerdefinierte Klassen für die Interaktion mit verschiedenen Diensten wie Vektorspeichern, Einbettungen und Sprachmodellen. Die Ingestion-Klasse von src.ingest übernimmt die Aufnahme von Dokumenten in das System. Wir importieren verschiedene Komponenten aus LangChain und langchain_core, um das Abrufen von Informationen und die Generierung von Antworten basierend auf dem Speicher und dem Gesprächsverlauf des Chatbots zu erleichtern.
import pandas as pd
from dotenv import load_dotenv
from src.companies import LLMFactory, VectorStoreFactory, EmbeddingsFactory
from src.ingest import Ingestion
from langchain_core.prompts import (
ChatPromptTemplate,
)
from langchain.retrievers.ensemble import EnsembleRetriever
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.reminiscence import ConversationBufferWindowMemory, SQLChatMessageHistory
_ = load_dotenv()Schritt 2: Daten laden
Anschließend laden wir den Konversationsdatensatz aus dem Datenverzeichnis. Der Datensatz kann heruntergeladen werden unter diese URL. Dieser Datensatz ist wichtig, um dem LLM eine Wissensbasis zur Verfügung zu stellen, auf die er bei der Beantwortung von Benutzeranfragen zurückgreifen kann.
knowledge = pd.read_parquet("knowledge/medqa.parquet", engine="pyarrow")
knowledge.head()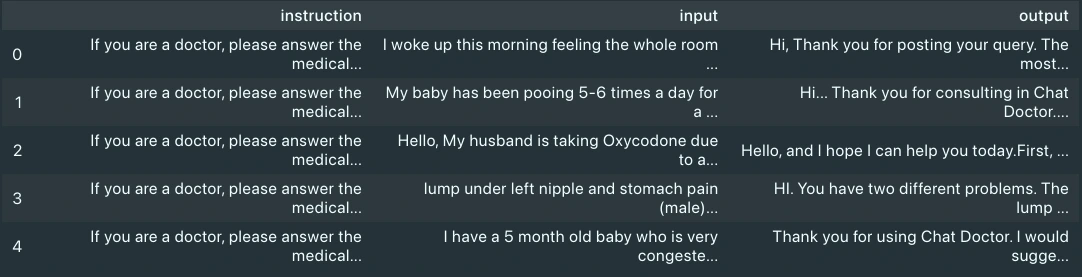
Wenn wir die Daten visualisieren, sehen wir, dass sie drei Spalten haben: Eingabe, Ausgabe und Anweisungen. Wir werden nur die Eingabe- und Ausgabespalten berücksichtigen, da es sich dabei um die Anfrage des Patienten bzw. die Antwort des Arztes handelt.
Schritt 3: Daten aufnehmen
Die Ingestion-Klasse wird mit spezifischen Diensten für Einbettungen und Vektorspeicherung instanziiert. Dieses Setup ist entscheidend für die Verarbeitung und Speicherung der medizinischen Daten auf eine Weise, die für den Chatbot zugänglich und nützlich ist. Wir erfassen zunächst den Konversationsdatensatz, da dies einige Zeit in Anspruch nimmt. Die Aufnahmepipeline wurde so abgestimmt, dass die Aufnahme großer Inhalte jede Minute stapelweise ausgeführt wird, um den Ratenbegrenzungsfehler von Einbettungsdiensten zu überwinden. Sie können die Logik im src-Verzeichnis ändern, um den gesamten Inhalt aufzunehmen, wenn Sie einen kostenpflichtigen Dienst zur Überwindung von Ratenbegrenzungsfehlern haben. Für dieses Beispiel verwenden wir einen on-line verfügbaren Patientenbericht. Den Bericht können Sie hier herunterladen Hier.
ingestion = Ingestion(
embeddings_service="cohere",
vectorstore_service="milvus",
)
ingestion.ingest_document(
file_path="knowledge/medqa.parquet",
class="medical",
sub_category="dialog",
exclude_columns=("instruction"),
)
ingestion.ingest_document(
file_path="knowledge/anxiety-patient.pdf",
class="medical",
sub_category="doc",
)Schritt 4: Dienste initialisieren
Die Klassen EmbeddingsFactory, VectorStoreFactory und LLMFactory werden zum Instanziieren der Einbettungs-, Vektorspeicher- und Sprachmodelldienste verwendet. Sie können diese Module aus dem am Anfang dieses Abschnitts genannten Repository herunterladen. Es verfügt über einen integrierten Logger zur Beobachtbarkeit und bietet Optionen zur Auswahl von Einbettungen, LLM und Vektorspeicherdiensten.
embeddings_instance = EmbeddingsFactory.get_embeddings(
embeddings_service="cohere",
)
vectorstore_instance = VectorStoreFactory.get_vectorstore(
vectorstore_service="milvus", embeddings=embeddings_instance
)
llm = LLMFactory.get_chat_model(llm_service="cohere")Schritt 5: Retriever erstellen
Mithilfe der Vector Retailer-Instanz erstellen wir zwei Retriever: einen für Gespräche (Arzt-Affected person-Interaktionen) und einen für Dokumente (medizinische Berichte). Wir konfigurieren diese Retriever für die Suche nach Informationen basierend auf Ähnlichkeit und verwenden Filter, um die Suche auf relevante Kategorien und Unterkategorien einzugrenzen. Anschließend verwenden wir diese Retriever, um einen Ensemble-Retriever zu erstellen.
conversation_retriever = vectorstore_instance.as_retriever(
search_type="similarity",
search_kwargs={
"ok": 6,
"fetch_k": 12,
"filter": {
"class": "medical",
"sub_category": "dialog",
},
},
)
document_retriever = vectorstore_instance.as_retriever(
search_type="similarity",
search_kwargs={
"ok": 6,
"fetch_k": 12,
"filter": {
"class": "medical",
"sub_category": "doc",
},
},
)
ensambled_retriever = EnsembleRetriever(
retrievers=(conversation_retriever, document_retriever),
weights=(0.4, 0.6),
)Schritt 6: Gesprächsverlauf verwalten
Wir haben ein SQL-basiertes System zum Speichern des Chat-Verlaufs eingerichtet, der für die Aufrechterhaltung des Kontexts während einer Konversation von entscheidender Bedeutung ist. Dieses Setup ermöglicht es dem Chatbot, auf frühere Interaktionen zu verweisen und so kohärente und kontextrelevante Antworten sicherzustellen.
historical past = SQLChatMessageHistory(
session_id="ghdcfhdxgfx",
connection_string="sqlite:///.cache/chat_history.db",
table_name="message_store",
session_id_field_name="session_id",
)
reminiscence = ConversationBufferWindowMemory(chat_memory=historical past)Schritt 7: Antworten generieren
Das ChatPromptTemplate wird verwendet, um die Struktur und Anweisungen für die Antworten des Chatbots zu definieren. Diese Vorlage leitet den Chatbot an, wie er die abgerufenen Informationen nutzen kann, um detaillierte und genaue Antworten auf Benutzeranfragen zu generieren.
immediate = ChatPromptTemplate.from_messages(
(
(
"system",
"""<INSTRUCTIONS FOR LLM>
{context}""",
),
("placeholder", "{chat_history}"),
("human", "{enter}"),
)
)Schritt 8: Erstellen einer historienbewussten RAG-Kette
Nachdem nun alle Komponenten fertig sind, nähen wir sie zu einer RAG-Kette zusammen.
question_answer_chain = create_stuff_documents_chain(llm, immediate)
history_aware_retriever = create_history_aware_retriever(
llm, ensambled_retriever, immediate
)
rag_chain = create_retrieval_chain(
history_aware_retriever, question_answer_chain,
)Jetzt ist die Pipeline bereit, Benutzeranfragen entgegenzunehmen. Der Chatbot verarbeitet diese Anfragen über eine Abrufkette, die das Abrufen relevanter Informationen und das Generieren einer Antwort basierend auf dem Sprachmodell und der bereitgestellten Eingabeaufforderungsvorlage umfasst. Probieren wir die Pipeline mit einigen Abfragen aus.
response = rag_chain.invoke({
"enter": "Give me a listing of main axiety problems with Ann.",
}
)
print(response("reply"))Das Modell konnte die Anfrage aus dem PDF-Dokument beantworten.
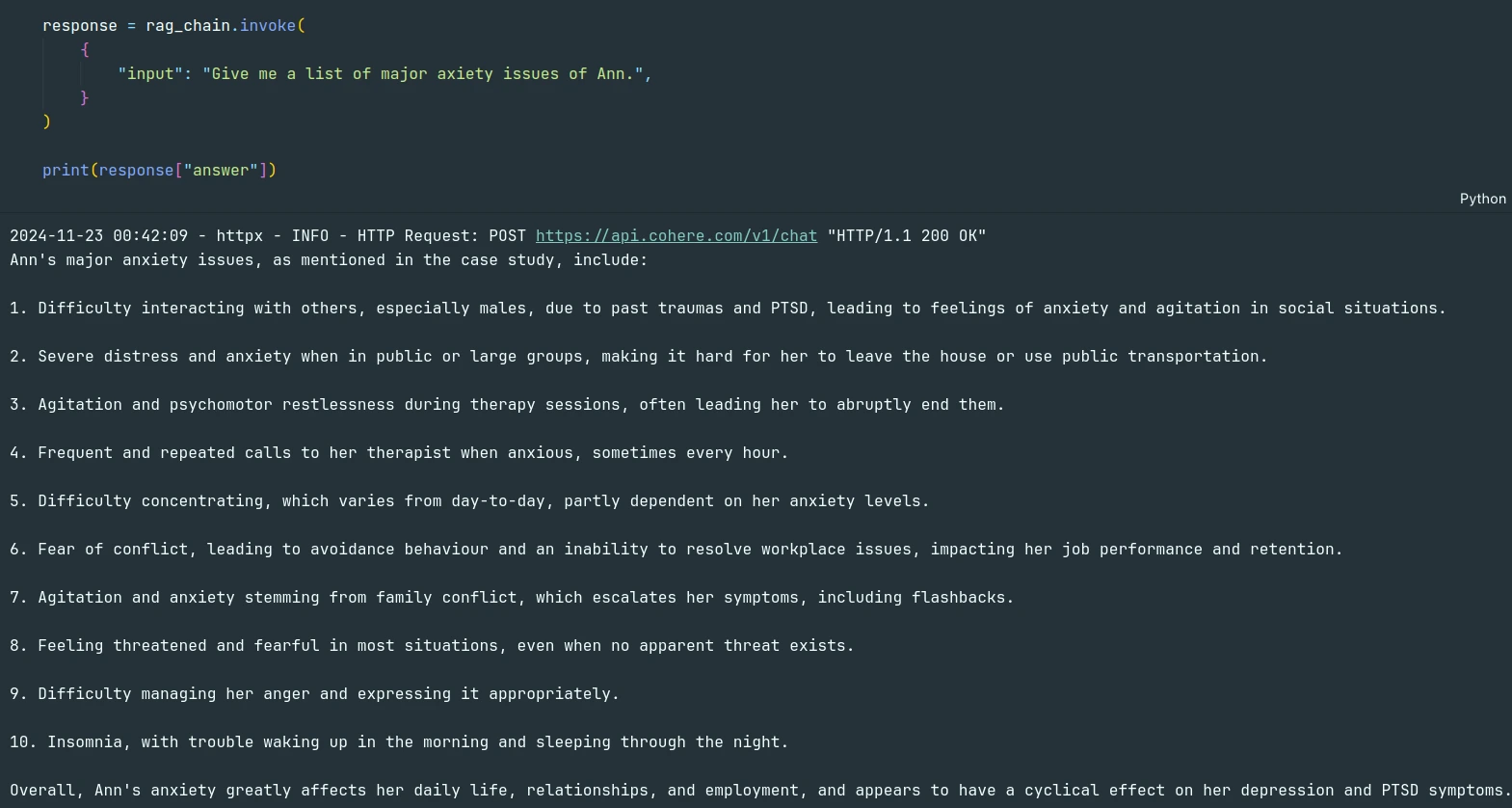
Das können wir anhand der Quellen überprüfen.

Als nächstes nutzen wir den Verlauf und die Konversationsdatenbank, die wir aufgenommen haben, und prüfen, ob das LLM sie verwendet, um etwas zu beantworten, das nicht im PDF erwähnt wird.
response = rag_chain.invoke({
"enter": "Ann appears to have insomnia. What can she do to repair it?",
}
)
print(response("reply"))Wenn wir die Antwort anhand der Quellen überprüfen, können wir sehen, dass LLM tatsächlich die Konversationsdatenbank verwendet, um auf die neue Anfrage zu antworten.


Abschluss
Der in diesem Leitfaden beschriebene Aufbau eines medizinischen Chatbots stellt einen bedeutenden Fortschritt bei der Anwendung von KI- und maschinellen Lerntechnologien im Gesundheitswesen dar. Durch die Nutzung von a
Mithilfe einer ausgefeilten Pipeline, die Vektorspeicher, Einbettungen und große Sprachmodelle integriert, können wir einen Chatbot erstellen, der in der Lage ist, komplexe medizinische Fragen mit hoher Genauigkeit und Relevanz zu verstehen und darauf zu antworten. Dieser Chatbot verbessert nicht nur den Zugang zu medizinischen Informationen für Patienten und Gesundheitssuchende, sondern zeigt auch das Potenzial von KI zur Unterstützung und Erweiterung von Gesundheitsdiensten. Die versatile und skalierbare Architektur der Pipeline stellt sicher, dass sie sich an zukünftige Anforderungen anpassen kann und neue Datenquellen, Modelle und Technologien einbezieht, sobald diese verfügbar sind.
Zusammenfassend lässt sich sagen, dass die Entwicklung dieser medizinischen Chatbot-Pipeline einen Schritt vorwärts auf diesem Weg darstellt
hin zu intelligenteren, zugänglicheren und unterstützenden Gesundheitstools. Es unterstreicht die Bedeutung der Integration fortschrittlicher Technologien, der effektiven Datenverwaltung und der Aufrechterhaltung des Gesprächskontexts, um eine Grundlage für zukünftige Innovationen auf diesem Gebiet zu schaffen.
Wichtige Erkenntnisse
- Entdecken Sie den Prozess der Erstellung eines Multi-Vektor-Chatbots mit LangChain, Milvus und Cohere für nahtlose Gespräche.
- Entdecken Sie die Integration von Vectorstores, um effiziente, kontextbezogene Antworten in einem Multi-Vector-Chatbot zu ermöglichen.
- Der Erfolg eines medizinischen Chatbots hängt von der genauen Verarbeitung medizinischer Daten und dem Coaching des Modells ab.
- Personalisierung und Skalierbarkeit sind der Schlüssel zur Schaffung eines nützlichen und anpassungsfähigen medizinischen Assistenten.
- Die Nutzung von Einbettungen und LLMs verbessert die Fähigkeit des Chatbots, genaue, kontextbezogene Antworten zu geben.
Häufig gestellte Fragen
A. Ein medizinischer Chatbot bietet Benutzern medizinische Beratung, Informationen und Unterstützung über Konversationsschnittstellen mit KI-Technologie.
A. Es verwendet große Sprachmodelle (LLMs) und eine strukturierte Datenbank, um medizinische Daten zu verarbeiten und Antworten auf Benutzeranfragen basierend auf geschultem Wissen zu generieren.
A. Vectorstores speichern Vektordarstellungen von Textdaten und ermöglichen so den effizienten Abruf relevanter Informationen für Chatbot-Antworten.
A. Bei der Personalisierung geht es darum, die Antworten des Chatbots auf der Grundlage benutzerspezifischer Daten wie Krankengeschichte oder Präferenzen anzupassen, um eine genauere und relevantere Unterstützung zu erhalten.
A. Ja, die Gewährleistung des Datenschutzes und der Sicherheit von Benutzerdaten ist von entscheidender Bedeutung, da medizinische Chatbots vertrauliche Informationen verarbeiten, die Vorschriften wie HIPAA entsprechen müssen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Ein Praktiker für maschinelles Lernen und Deep Studying mit einem Hintergrund in Informatik. Meine Arbeitsinteressen umfassen maschinelles Lernen, Deep Studying, Laptop Imaginative and prescient und NLP, mit Fachkenntnissen in generativer KI und Retrieval Augmented Technology.